

一种基于深度神经网络的迭代6D姿态匹配的新方法
电子说
描述
基于图像信息对目标进行三维空间定位具有十分重要的作用。例如,在机器人操作中,抓握和运动规划等任务就需要对物体的6D姿态(3D位置和3D方向)信息进行准确的估计;在虚拟现实应用中,人与物体之间的友好流畅的虚拟交互需要对目标进行准确的6D姿态估计。
虽然最新的技术已经在使用深度相机进行物体姿态估计,但这种相机在帧速率、视场、分辨率和深度范围等方面还存在相当大的局限性,一些小的、薄的、透明的或快速移动的物体检测起来还非常困难。目前,基于RGB的6D目标姿态估计问题仍然具有挑战,因为图像中目标的表观会受到一系列因素的影响,如光照、姿态变化、遮挡等。此外,鲁棒的6D姿态估计方法还需要能处理有纹理和无纹理的目标。
传统方法往往通过将2D图像中提取的局部特征与待检测目标3D模型中的特征相匹配来求解6D姿态估计问题,也就是基于2D-3D对应关系求解PnP问题。但是,这种方法对局部特征依赖性太强,不能很好地处理无纹理目标。为了处理无纹理目标,目前的文献中有两类方法:一类是,学习估计输入图像中的目标关键点或像素的3D模型坐标;还有一类是,通过离散化姿态空间将6D姿态估计问题转化为姿态分类问题,或转化为姿态回归问题。
这些方法虽然能够处理无纹理目标,但是精度不够高。为了提高精度,往往还需要进一步的姿态优化:给定初始姿态估计,对合成RGB图像进行渲染来和目标输入图像进行匹配,然后再计算出新的更准的姿态估计。现有的姿态优化方法通常使用手工制作的图像特征或匹配得分函数。
在本文工作中,作者提出了DeepIM——一种基于深度神经网络的迭代6D姿态匹配的新方法。给定测试图像中目标的初始6D姿态估计,DeepIM能够给出相对SE(3)变换符合目标渲染视图与观测图像之间的匹配关系。提高精度后的姿态估计迭代地对目标重新渲染,使得网络的两个输入图像会变得越来越相似,从而网络能够输出越来越精确的姿势估计。上图展示了作者提出网络用于姿态优化的迭代匹配过程。
这项工作主要有以下贡献:
首先,将深度网络引入到基于图像的迭代姿态优化问题,而无需任何手工制作的图像特征,其能够自动学习内部优化机制;
其次,提出了一种旋转和平移解耦的SE(3)变换表示方法,能够实现精确的姿态估计,并且能使提出的方法适用于目标不在训练集时的姿态估计问题。
最后,作者在LINEMOD和Occlusion数据集上进行了大量实验,以评估DeepIM的准确性和各种性能。
两个数据集上的实验结果表明,作者提出的方法都比当前最先进的基于RGB的方法性能提高了很多。此外,初步的实验表明,DeepIM还能够在对一些训练集中未出现的物体的姿态进行准确估计。
下面让我们看看一些算法流程的细节。如上图所示,作者为了获得足够的信息进行姿态匹配,对观测图像进行放大,并在输入网络前进行渲染。要注意的是,在每次迭代过程中,都会根据上一次得到的姿态估计来重新渲染,这样才能够通过迭代来增加姿态估计的准确度。DeepIM的网络结构图如下图所示,输入观测图像、渲染图像以及对应的掩膜。使用FlowNetSimple网络第11个卷积层输出的特征图作为输入,然后连接两个全连接层FC256,最后旋转和平移的估计分别用两个全连接层FC3和FC4作为输入。
通常目标从初始位置到新位置的旋转与平移变换关系如上显示。

一般来说旋转变换会影响最后的平移变换,即两者是耦合在一起的。如果将旋转中心从相机坐标系的原点转移到目标中心,就能解耦旋转和平移。但这样就需要能够识别每个目标并单独存储对应的坐标系,这会使得训练变得复杂且不能对未知目标进行姿态匹配。
在本文的工作中,作者让坐标轴平行于当前相机坐标轴,这样可以算得相对旋转,后续实验证明这样效果更好。剩下的还要解决相对平移估计问题,一般的方法是直接在三维空间中计算原位置与新位置的xyz距离,但是这种方式既不利于网络训练,也不利于处理大小不一、表观相似的目标或未经训练的新目标。
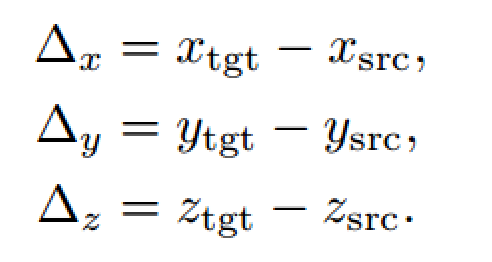
本文作者采用在二维图像空间中进行回归估计平移变换,vx和vy分别是图像水平方向和垂直方向上像素移动的距离,vz表示目标尺度变化。其中,fx和fy是相机焦距,由于是常数,在实际训练中作者将其设为1。
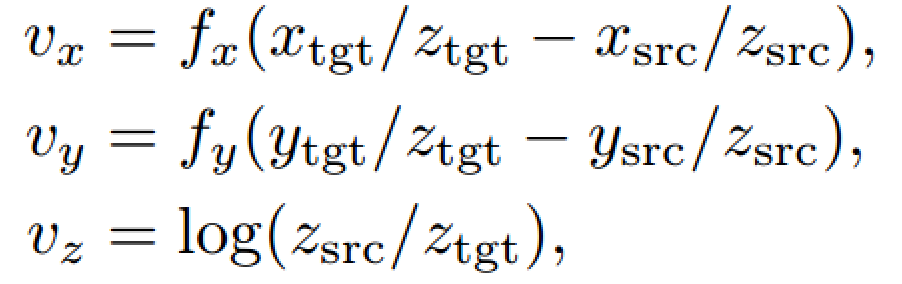
这样一来,旋转和平移解耦了,这种表示方法不需要目标的任何先验知识,并且能处理一些特殊情况,比如两个外观相似的物体,唯一的区别就是大小不一样。
关于模型训练的损失函数,通常直接的方法是将旋转和平移分开计算,比如用角度距离表示旋转误差,L1距离表示平移误差,但这种分离的方法很容易让旋转和平移两种损失在训练时失衡。本文作者提出了一种同时计算旋转和平移的Point Matching Loss函数,来表达姿态真值和估计值之间的损失。其中,xj表示目标模型上的三维点,n是总共用来计算损失函数的点个数,本文中n=3000。
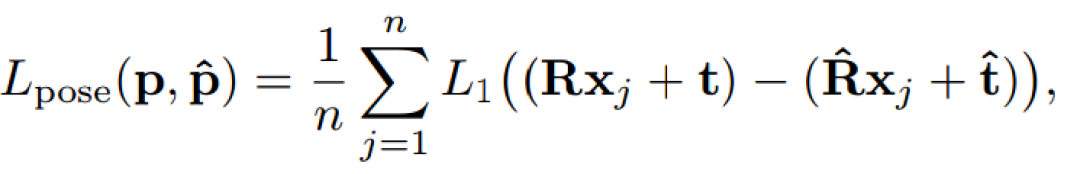
最后总的损失函数由L=αLpose +βLflow+γLmask组成,其中(α,β,γ)分别为(0.1,0.25,0.03)
实验部分,作者主要使用了LINEMOD和OCCLUSION数据集。如下表显示,在LINEMOD数据集上作者分别用PoseCNN和Faster R-CNN初始化DeepIM网络,发现即便两个网络性能差异很大,但是经过DeepIM之后仍能得到差不多的结果。
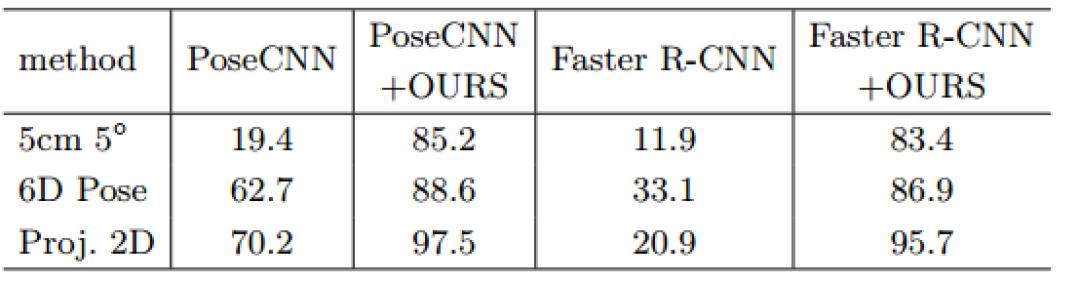
LINEMOD数据集上的方法对比结果如下表显示,作者提出的方法是最好的。
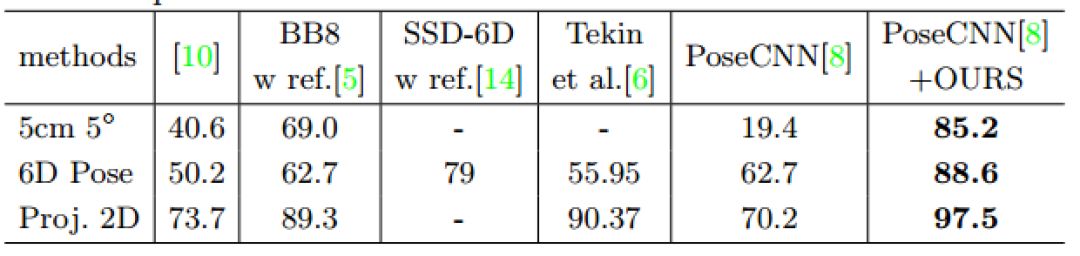
在目标有遮挡的数据集上的实验,本文提出的方法效果也相当不错哦。
除此之外,本文方法在ModelNet数据集上的表现也相当惊艳,要注意的是,这些物体都不曾出现在训练集中哦。
利用这种方法实现6D位姿估计是十分有效的,希望能为小伙伴们的研究应用带来启发和帮助~
-
一种基于MCU的神经网络模型灵活更新方案之先行篇2023-10-17 1080
-
浅析深度神经网络压缩与加速技术2023-10-11 1885
-
卷积神经网络和深度神经网络的优缺点 卷积神经网络和深度神经网络的区别2023-08-21 5021
-
深度神经网络是什么2021-07-12 1967
-
一种改进的深度神经网络结构搜索方法2021-03-16 1054
-
一种复制和粘贴URL的新方法2020-12-21 4680
-
人工神经网络实现方法有哪些?2019-08-01 3422
-
DENSER是一种用进化算法自动设计人工神经网络(ANNs)的新方法2018-01-10 7756
-
一种改进的基于卷积神经网络的行人检测方法2017-12-01 1326
-
一种基于深度神经网络的基音检测算法2017-01-07 918
-
基于GA优化T_S模糊神经网络的小电流接地故障选线新方法_王磊2016-12-31 768
-
一种标定陀螺仪的新方法2016-08-17 4092
-
基于LabVIEW8.2提取ECG特征点的新方法2012-11-30 6612
-
传感器故障检测的Powell神经网络方法2009-07-07 489
全部0条评论

快来发表一下你的评论吧 !
