

SOLO X™:兼容 WebRTC 标准的抗丢包语音编码器
电子说
描述
本文分享了声网Agora 首席音频工匠高泽华在 RTC 2018 实时互联网大会上,以《SOLO X™:兼容 WebRTC 标准的抗丢包语音编码器》为题的演讲。主要介绍了声网推出的抗丢包语音编码器 Agora SOLO™ 的算法特点,以及第二代编解码器 Agora SOLO X™ 的新特性与测试效果。以下为演讲实录。
去年,我们在 RTC 大会上分享了自主研发的抗丢包编解码方案 Agora SOLO™ ,主要是面向抗丢包网络,解决实时通信传输 last mile 的问题。
1
关于Agora SOLO™
有时,大家对丢包问题会有一些误解。很多人认为随着 4G 的普及和 5G 的建设,是不是丢包问题变得不重要了?我认为并不是这样,因为在现有网络条件下,不论是 server 到 server,还是 sever 到 last mile 都存在着大量的丢包问题。
我们谈到丢包就涉及到丢包的概念,到底什么叫做丢包?其实任何没有按时到达的包都是丢包。如果把一个包的延时拉到足够大,一般来说,我们可以通过无数次重传来解决丢包问题。如果这个包没有在规定的时间到达,都算丢包。而且,丢包也不一定是网络原因导致,有时候是由于系统的调度等原因造成。
举个例子。通常,Android 系统上播放线程、解码线程和收包线程都可以不是一个线程。Android 并不是特别实时的操作系统。一旦系统比较忙的时候,就容易产生收包线程和解码线程的冲突,导致丢包产生。而这种丢包是由于系统产生的。甚至在解码时,解码器完成解码后交给播放器播放,其中的 buffer 也会导致卡顿。
丢包也与带宽限制相关。如果带宽足够大,可以通过无数次重传来实现抗丢包效果。但如果带宽很有限,就不能完全依靠无限制的重传来实现抗丢包效果。
比如说,曾经联通做过这样的事情,流量包月,但每个月的带宽只能在 128kbps,满足你对网页和音视频的基本需求。在这种服务下,如果你开一些高性能或者大码率的信源通讯的时候就会产生带宽拥塞,带宽拥塞首先导致延时增加,下一步就会产生丢包。所以,实际上带宽和丢包也相关。
由于我们声网在全球布网,非洲、东南亚、中东和印度的网络状况与中国的网络状况相差还比较远。即使在中国的网络环境下,上海和偏远地区的网络状况也是不一样的。所以,并不是以后上了 5G 就不存在丢包问题了,相反,我认为随着网络的差异化会导致丢包的问题变得越来越普遍。
举一个例子,描述一下什么情况会产生丢包?如上图所示为典型的丢包模型,device 1 与 device 2、device 3、device 4 进行通信。比如,device 1,把 packet 1、packet 2、packet 3 一起发给 device 2,packet 1、packet 2、packet 3 丢了一个包是 packet 2。在这个时间窗口计算丢包率时,当前的丢包率是 33%。此时 device 2 会给 device 1 发回一个回传控制,即 loss info,loss info 带上丢包率是 33% 的信息。根据这个信息,device 1 会重新对 device 2 进行抗丢包的处理,发两个 packet 4 和两个 packet 5。那么,当丢了一个 packet 4 时,还有一个 packet 4 可以起到抗丢包的效果。也就是说,在整个系统中,在第一个时间窗口,packet 1、packet 2、packet 3,在这 3 个包内算丢包率,再把丢包率回传到 device 1,由 device 1 根据丢包率的信息,去发送抗丢包的冗余。
在其中,我们会发现几个问题。第一是时间窗口问题。如果按照 3 个时间窗口来算,丢包率是 33%。如果按照 4 个时间窗口算,丢包率是 25%。如果按照 2 个时间窗口算,丢包率是 50%。这就产生一个问题,即丢包率算的其实没有那么准。
第二,device 2 接收到 device 1 发送的包之后,会回传一个 loss info 给 device 1。一般来讲,loss info 中会加入一些 FEC 的控制,保证它不会被丢。但实际上 loss info 的包仍可能会丢失。
我们假设上述情况中 loss info 没有丢包,device 1 发送冗余的包给 device 2,譬如发送两个 packet 4 和两个 packet 5。由于此时的丢包率是 33%。那么 packet 4 丢掉之后,对于 packet 4 来说,起到了抗丢包的效果,但是对于 packet 5 来说,发的两个 packet 5 并没有起到抗丢包的效果,这对网络带宽是浪费的。
再假设前面窗口也取准了,loss info 也没有丢,packet 4、packet 5 也都取得了抗丢包的效果,还是会存在一个问题。在回传的信道中已经有很长的 RTT 在里面,发过去一个包,device 2 进行估算,估算后,再发送一个 loss info 回到 device 1。如果 RTT 太长,发包的过程中还是会不断出现丢包。也就是在长 RTT 的情况下,这种抗丢包方案的效果是比较有限,或者可以说存在一些缺陷。
我们还可以假设以上问题都不存在。在多人通话中,每个设备接收端的网络环境不同,假设 device 1 与 device 2 之间是 3G 或有损的 Wi-Fi 环境,而 device 3、device 4 分别使用 4G、5G。那么,device 1 在处理 loss info 时应该采取什么策略呢?如果都加入 FEC 的话,就意味着浪费了 device 3 和 device 4 的带宽,但如果不想浪费带宽,没有 FEC ,就意味着无法实现对 device 2 的抗丢包效果。
所以在多人环境下,网络带宽的差异化是做网络策略时要考虑的重要因素。同时,还有一些人为或成本因素需要我们在做网络策略时进行综合考虑。例如,在中国与印度之间进行实时通信时,其中一个 server 在印度当地,可以直接与中国的 server 进行连接。但印度的通信成本较高,会产生一定的资费。这时我们可以选择通过新加坡的 server 绕个远,但这个过程又会产生一些丢包问题。
2
Agora SOLO™ 的优势在哪儿?
在多人环境下,传统的抗丢包策略无法很好解决这类问题,所以声网在去年 10 月份推出了一个新的编码器叫 Agora SOLO™。
一段音频信号通过 Agora SOLO™ 处理后,会生成两个成对的包 packet 1 和 packet 2 ,它们为同一帧,并且互补。即我收到一个 packet 1 的时候,我可以解码出一个 8kbps 的窄带音频信号,如果我收到一个 packet 2,也可以解码出一个 8kbps 的窄带音频信号,但如果我同时收到一个 packet 1 和一个 packet 2,我就可以恢复出一个 16kbps 的宽带高质量音频信号。
一定程度上讲,这个编解码器可以解决刚才提到的 FEC 遇到的所有抗丢包的策略问题。
通常,编解码器做的事情是压缩、去冗余,而抗丢包从一定程度上讲是信道处理的扩大化。抗丢包是一种纠错算法的扩展,通过加冗余实现抗丢包。而对于 Agora SOLO™ 来说,是把去冗余和加冗余进行结合,对重点信息加冗余,对非重点信息则更多的去冗余,以达到在信道和信源的联合编码的效果。
我们强调了在编码器上加一定的冗余去抗丢包,实际上就会带来一些编码效率的降低。但这种情况下,我们可以通过增加一些新的算法,减少编码效率的降低。并且,和原始的 codec 编码效率相比,从结果上看还要更好一些。
上图是我们用 ITU NTT 的中文测试序列跑的测试结果。稍微介绍一下,ITU 的 NTT 是标准的编解码器测试序列,里面有 26 国语言,这里只拿出了中文部分的测试结果。那么横坐标内的 PESQ 是窄带编码器的客观测试标准,最后一列,PESQ-WB 是宽带编解码的客观测试标准,满分是 5 分,通常打到 4 分就是完美了。后面有我们这个编码器与一些传统编码器在 PESQ 分数的对比。
我们可以看到,是只收到 8kbps 的 packet 1, PESQ 的 MOS 分是 3.52 分。如果只收到 packet 2,MOS 分是 3.51 分。如果 packet 1 和 packet 2 都收到,在16kbps 时,MOS 分是 3.95 分。以上是窄带的分数。宽带下的 PESQ 的 MOS 分是 3.582 分。
用新的编码器后,我们再看一下它的效果。此时就不需要再考虑是否加 loss info,我们可以直接从 device 1 给所有的 device 2、device 3、device 4 发 packet 1、packet 1’、packet 2、packet 2’、packet 3、packet 3’的包。
为什么可以这样做?因为实际上,如果 packet 1 或者 packet 1’ 丢包,不会有太大影响,你仍然可以恢复出一个有限的 8kbps 质量的音频数据。如果没有丢包,收到了 packet 1、packet 1',就可以恢复出 16kbps 的音频数据,其中并没有任何的冗余信息。这种算法不像原来的 FEC,两个包完全相等,或者一大一小,那会造成带宽浪费。这种算法不会造成带宽浪费,那么你就无需考虑以下问题:
第一,延时问题;
第二,回传 loss info 的丢包问题;
第三,多人通信中,每个网络带宽不一致的问题。
总体来说,这个编码器被我称为接近完美的抗丢包编解码,因为没有完美的编解码器。
Agora SOLO™ 有如下四个特点:
第一,更低延时。无需回传信道丢包信息,默认发送多倍数据;
第二,更高质量。收到一个包质量可达到普通编解码器水平,收到两个包质量即可达到高质量编解码的水平;
第三,面向多人环境;
第四,简化策略。无需策略调整,不担心策略颗粒度问题。
所以从抗丢包的四种方法(FEC、PLC、ARC、ARQ)来看,需要想尽各种办法去做 balance。但有了这种方法后,你无需考虑太多,直接调用即可。另外在有限的成本下,如果同时使用一条高质量的高成本的服务器的带宽和一条低成本相对有丢包下的带宽时,你可以发两条流,分别是 packet 1 和 packet 1’,这样可以起到更好的效果。
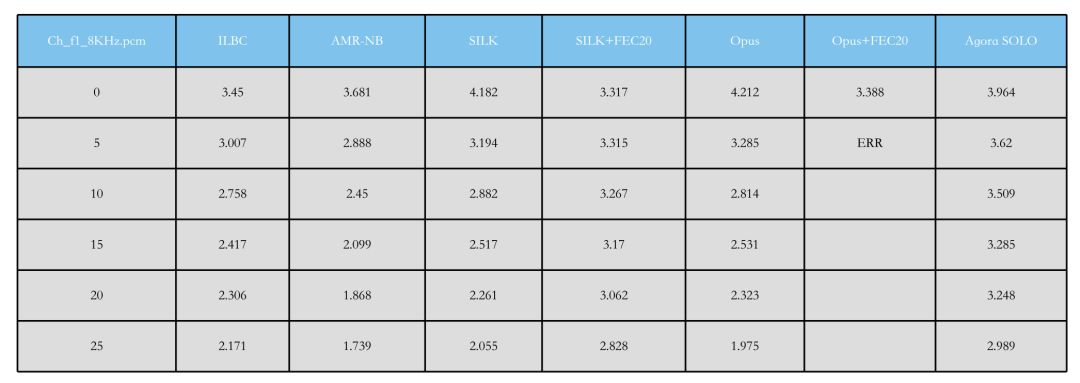
如上图所示,是我们做的 Agora SOLO™ 和其他编码器的对比。从图中我们可以很快发现 ILBC 和 AMR-NB 的 MOS 分比较低,这是由于它们俩是上个时代的编码器,因此属于正常现象。
SILK 和 Opus 的 MOS 分比较高,但我们会发现 SILK+FEC20 时,基础 MOS 分会下降得非常厉害,因为拿一部分带宽去做冗余就会导致基础 MOS 分下降。
而 Opus+FEC20 时,实际上编不出在丢包 5% 时的码率,因为码率控制的设计相对比较保守。但我们可以看到它加 FEC20 后,基础 MOS 分在下降。
而 Agora SOLO™ 的基础 MOS 分和 SILK、Opus 几乎一样,下降在 0.2 之内。而它在抗丢包时,一旦发生丢包,几乎没有 MOS 分下降。在丢包 5%、10%、15%、20% 时,它的 MOS 分维持在一个相对稳定的情况,和竞品比有时候可以达到 1 分的差距。
做过通信 MOS 分竞品比较的人应该知道,高 0.3-0.5 分已经是非常困难,高 1 分几乎是不可能。以 20% 为例,Agora SOLO™ 的 MOS 分是 3.2,而 SILK 却只有 2.2 和 2.3,虽然加上 FEC20 后是 3.0,但加上 FEC 后 SILK 的基础 MOS 分会比较低。
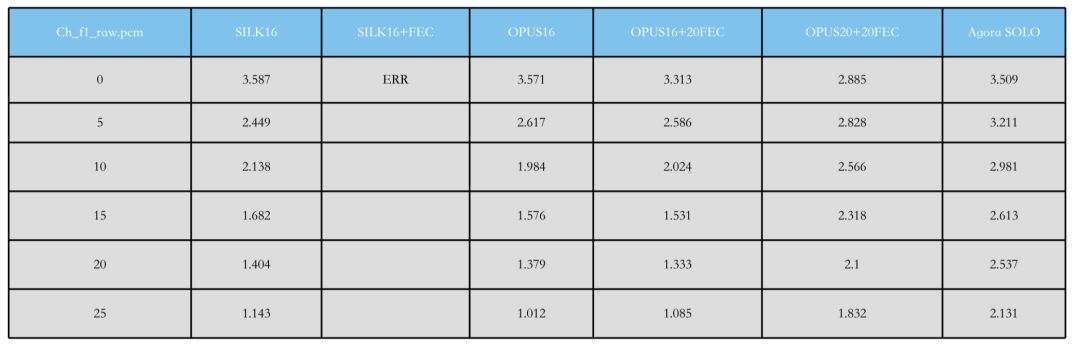
这是 ITU NTT 的中文测试第一条序列——女声。女声相对来说比较难编,因为中国人说话有四声问题,比其他语言更复杂。女声的高频信息比男声更丰富,所以编起来也会更难。
由图可知,SILK16 的 MOS 分是 3.5,SILK16+FEC 编不出来,Opus16 的 MOS 分是 3.5,Opus16+20FEC 的 MOS 分是 3.3,Opus20+20FEC 的 MOS 分是 2.8。虽然码率更高了,但由于带宽原因,给 FEC 的码率更高,它的内核码率反而更低,所以它的基础 MOS 分变得很低。
而 Agora SOLO™ 的 基础 MOS 分是 3.5,在不丢包的情况下它和 Opus16 和 SILK16 的 MOS 分基本一致。在丢包的情况下,以 20% 为例,它的 MOS 分是 2.5,比其他都高,这就是 Agora SOLO™。
3
Agora SOLO™ 的模拟测试结果
我们不仅做了线下 ITU 的网损测试,还做了线上的模拟测试。如上图所示,我们用两台 iPhone 去做模拟丢包的测试,device A 经过 Wi-Fi、内网 VOS 和 Wi-Fi,去和 device B 通信。
这是我们的测试结果。红色是丢包率,绿色是丢帧率。从图中我们可以看到,丢包率原本是 50% 左右,经过 Agora SOLO™ 之后,它的丢帧率只剩 20%。NOVA 是我们的另一个编码器,它的丢包率和丢帧率都是 50%,没有做任何的 FEC。
当采用一包两帧策略做抗丢包的时候,在 20% 的丢包率下,Agora SOLO™ 基本没有丢帧的产生。而传统的编码器下,丢帧率还是有一定的损失。
4
兼容 WebRTC 标准的抗丢包语音编码器SOLO X™
过去一年里,我们把 Agora SOLO™ 编码器的抗丢包部分移植到了 OPUS 上,我们给这个技术起了一个新的名字叫分组谱互补技术,并开发了一个新的编码器叫 SOLO X™。
SOLO X™ 算法和 SOLO™ 是一样的,那我们直接看结果上的差异。
16kbps 时,我们可以看到 SOLO X™ 的 MOS 分会下降到 3.2。它的抗丢包的效果在 20% 的时候是 2.4,和 Agora SOLO™ 差不多,比 Opus20 和 Opus16 都要好。
如果是 20kbps 时,它的 MOS 分是 3.46。在丢包 20% 时,它的 MOS 分是 2.6 ,还是比 Opus16+20FEC、Opus20+20FEC 的效果好,基础 MOS 分也高。
它的优势主要是和 OPUS 结合后,可以与 OPUS 互相兼容。用声网 Native 的 SDK 和 WebRTC 的 SDK 进行互通时,如果它支持 SOLO X™ 编码器,它就可以解出两条更高质量的流。而为了做到兼容,会有一些质量损失,导致 SOLO X™ 在 16kbps 的 MOS 分比 SOLO™ 要下降一些,这也是我们后期优化的主要方向。
对于 8kHz 来看,为了起到兼容的效果,它的基础 MOS 分也有下降,但是它的抗丢包效果没有明显下降。
图:SOLO X™ 在 ITU NTT 的跑分结果
和 WebRTC 做兼容后,我们对 WebRTC 的互通做了测试。 googDecodingPLC 的意义是加了网损后,当外边没有收到包时,会调用 googDecodingPLC 函数去解码,做后端的抗丢包补偿。图中右侧纵轴的单位是帧,即这段时间内补偿了多少帧来做抗丢包。如果我们实现了抗丢包的效果,则不用调大量后端 PLC 做补偿。
从上图数据可以看到,在只使用 OPUS 编码器时,在 20% 和 40% 的丢包模拟下,可以看到 5 分钟以内补偿帧数分别在 6 千次和 11 千次左右。用 SOLO X™ 时,20% 丢包的情况下,补偿帧只有 1K 多一点。40% 丢包时,丢包补偿帧只有 4K 左右,可以看到明显下降,这意味着已经有更多的包到达解码端,不需要调用 PLC 做补偿。
5
SOLO X™ 和 WebRTC 互通中的数据表现
如上图所示,是我们在兼容模式和非兼容模式下的 PESQ-MOS 分。前面给的数据都是兼容 Opus 编码器的 MOS 分,而非兼容模式下 PESQ-MOS 分可以做的更高。
实际上这张图也是 PESQ-WB 的 MOS 分,理论上,我们应该用 POLQA 去比分,那么在 48kHz,48kbps 和 32kHz,32kps 去比,MOS 分的差异和影响对比会更大。因为对高频的权重越高,一旦有损失就会导致分比较低。这也是为什么几乎相同的对比策略和解码输出, PESQ-WB 的分比 PESQ 的分要低的原因。
在非兼容模式下,它的 MOS 分会远远高于兼容模式。后期我们会针对兼容模式进行优化,我觉得是有机会达到接近非兼容模式时的效果的。
6
Agora SOLO™ 的下一步
2017 年,我们花了两年时间把 SOLO™ 的编码器做了出来,今年做 SOLO X™ 目的是与 OPUS 互通,目前主要做 Voice 这一块,计划 2019 年推出针对音乐的编码器,相信效果会更突出,因为音乐在实际产生中都是使用 128k 或者 196K 的码率,这种码率下做 FEC 的代价会非常非常高。
最后我想说,对创业公司来说花大力气做编解码是很吃亏的事情。因为做编码器很累,也很苦,普通公司通常不会去做。所以我很感谢声网给我这个机会,也感谢 Tony 的鼓励。坦白讲,无数的不眠之夜,整夜整夜的失眠才做出了 Agora SOLO™ 和 SOLO X™。
-
磁编码器接口定义及标准接线方法2026-03-12 985
-
编码器故障排查:海绵泡沫切割机丢步、定位不准的解决方法2025-07-18 1667
-
编码器分辨率是什么意思 编码器分辨率和脉冲数的关系2024-02-21 8388
-
伺服电机编码器分类2023-08-25 4843
-
伺服电机编码器2023-06-26 2526
-
使用FPGA实现MELP语音压缩编码器的详细资料说明2021-01-22 1454
-
伺服电机编码器原理_伺服电机编码器种类2019-11-07 11693
-
Sin/Cos编码器与Sitara AM437x的连接工业接口2018-12-19 2989
-
伺服电机自带编码器为什么还要外加编码器?2018-02-03 64050
-
伺服电机编码器原理(伺服电机编码器几根线以及接线图)2017-11-10 138237
-
旋转编码器抗抖动接口电路设计2013-09-26 1236
-
编码器,编码器是什么意思2010-03-08 3470
-
什么是编码器 什么叫编码器 编码器什么意思2007-12-18 16688
全部0条评论

快来发表一下你的评论吧 !
