

如何利用K8S全面拥抱微服务架构?
描述
K8S是第一个将“一切以服务为中心,一切围绕服务运转”作为指导思想的创新型产品,它的功能和架构设计自始至终都遵循了这一指导思想,构建在K8S上的系统不仅可以独立运行在物理机、虚拟机集群或者企业私有云上,也可以被托管在公有云中。
微服务架构的核心是将一个巨大的单体应用拆分为很多小的互相连接的微服务,一个微服务背后可能有多个实例副本在支撑。单体应用微服务化以后,服务之间必然会有依赖关系,在发布时,若每个服务都单独启动会非常痛苦,简单地说包括一些登录服务、支付服务,若想一次全部启动,此时必不可少要用到编排的动作。
K8S完美地解决了调度,负载均衡,集群管理、有状态数据的管理等微服务面临的问题,成为企业微服务容器化的首选解决方案。使用K8S就是在全面拥抱微服务架构。
在社区不久前的线上活动交流中,围绕金融行业基于K8S的容器云的微服务解决方案、金融行业微服务架构设计、容器云整体设计架构等方面的问题进行了充分的讨论,得到了多位社区专家的支持。大家针对K8S容器云和微服务结合相关的问题,体现出了高度的参与热情。在此,对大家关注的问题以及针对这些问题各位专家的观点总结如下:
一、K8S容器云部署实践篇
Q1:现阶段容器云部署框架是什么?
A1:
• 在DMZ和内网分别部署彼此独立的2套Openshift,分别为内网和DMZ区两个网段,两套环境彼此隔离。
• DMZ区的Openshift部署对外发布的应用,负责处理外网的访问
• 内网的Openshift部署针对内网的应用,仅负责处理内网的访问
-权限管理
对于企业级的应用平台来说,会有来自企业内外不同角色的用户,所以灵活的、细粒度的、可扩展的权限管理是必不可少的。OCP从设计初期就考虑到企业级用户的需求,所以在平台内部集成了标准化的认证服务器,并且定义了详细的权限策略和角色。
1. 认证:
OCP平台的用户是基于对OCP API的调用权限来定义的,由于OCP所有的操作都是基于API的,也就说用户可以是一个开发人员或者管理员,可以和OCP进行交互。OCP内置了一个基于OAuth的通用身份认证规范的服务器。这个OAuth服务器可以通过多种不同类型的认证源对用户进行认证。
2. 鉴权:
权策略决定了一个用户是否具有对某个对象的操作权限。管理员可以设置不同规则和角色,可以对用户或者用户组赋予一定的角色,角色包含了一系列的操作规则。
除了传统的认证和鉴权功能,OCP还提供了针对pod的细粒度权限控SCC(security context constraints),可以限制pod具备何种类型的权限,比如容器是否可以运行在特权模式下、是否可以挂在宿主机的目录、是否可以使用宿主机的端口、是否可以以root用户运行等。
-多租户管理
租户是指多组不同的应用或者用户同时运行在一个基础资源池之上,实现软件、硬件资源的共享,为了安全需求,平台需要提供资源隔离的能力。
在OCP中,project是一个进行租户隔离的概念,它来源于kubernetes的namespace,并对其进行了功能的扩展。利用Project,OCP平台从多个层面提供了多租户的支持。
1. 权限控制。通过OCP平台细粒度的权限管理机制,管理员可以对不同的用户和组设置不同project的权限,不同用户登录以后只能操作和管理特定的project
2. 网络隔离。OCP平台使用openvswitch来管理内部的容器网络,提供两种类型的网络模式,一种是集群范围内互通的平面网络,另一种是project级别隔离的网络。每个project都有一个虚拟网络ID(VNID),不同VNID的流量被openvswitch自动隔离。所以不同项目之间的服务在网络层不能互通。
3. Router隔离。Router是OCP平台一个重要软件资源,它提供了外部请求导入OCP集群内部的能力。OCP提供了Router分组的功能,不同的project可以使用独立的Router,不互相干扰,这样就避免了由于某些应用流量过大时对其他应用造成干扰。
物理资源池隔离。在多租户的环境中,为了提高资源的利用率一般情况下物理资源池是共享的,但是有些用户也会提供独占资源池的需求。针对这种类型的需求,OCP平台利用nodeSelector的功能可以将基础设施资源池划分给特定的project独享,实现从物理层面的隔离。
-日志和监控
(1)传统应用日志
有别于当前流行的容器应用,的传统应用同时一个中间件会运行多个应用,且应用通过log4j等机制保存在文件中方便查看和排错。因为容器运行的特性,对于这部分的日志我们需要持久化到外置存储中。
日志的分类如下:
• 中间件日志
• dump文件
• 应用日志
日志保存在计算节点上挂载的NFS存储。为了规范和方便查找。日志将会按OCP平台中的namespace建立目录,进行划分。
(2)新应用日志
应对分布式环境下日志分散的解决办法是收集日志,将其集中到一个地方。收集到的海量日志需要经过结构化处理,进而交给需要的人员分析,挖掘日志的价值信息。同时不同的人员对日志的需求是不一样的,运营人员关注访问日志,运维人员关注系统日志,开发人员关注应用日志。这样就需要有一种足够开放、灵活的方法让所有关心日志的人在日志收集过程中对其定义、分割、过滤、索引、查询。
OpenShift使用EFK来实现日志管理平台。该管理平台具备以下能力:
¡ö 日志采集,将日志集中在一起
¡ö 索引日志内容,快速返回查询结果
¡ö 具有伸缩性,在各个环节都能够扩容
强大的图形查询工具、报表产出工具
EFK是Elasticsearch(以下简写为ES)+ Fluentd+Kibana的简称。ES负责数据的存储和索引,Fluentd负责数据的调整、过滤、传输,Kibana负责数据的展示。
Fluentd无论在性能上,还是在功能上都表现突出,尤其在收集容器日志领域更是独树一帜,成为众多PAAS平台日志收集的标准方案。
(3)监控
PaaS平台的监控包括系统监控、容器监控等。监控流程由信息收集、信息汇总和信息展示等几个部分组成。
在Openshift中默认使用kubenetes的监控信息收集机制,在每个节点上部署cadvisor的代理,负责收集容器级别的监控信息。然后将所有信息汇总到heapster,heapster后台的数据持久化平台是Cassandra。最后由hawkular从Cassandra获取信息进行统一的展示。
1. 组件说明
Openshift的监控组件,用于对pod运行状态的CPU、内存、网络进行实时监控,和Kubernetes使用的监控技术栈一样,包括三个部分:
HEAPSTER
用于监控数据的采集
https://github.com/kubernetes/heapster
HAWKULAR METRICS
属于开源监控解决方案Hawkular,基于JSON格式管理、展示监控数据
http://www.hawkular.org/
CASSANDRA
Apache Cassandra是一个开源的分布式数据库,专门用于处理大数据量业务
http://cassandra.apache.org/
-DMZ区计算节点
在DMZ区应用部署遵循以下策略:
• 已有应用迁移至容器云平台时的资源申请按现有配置设置,申请的服务器将仅供该使用
• 如果需要横向扩展,也仅在已分配的计算节点上,如果资源不足,应用项目组可再申请新的计算资源
• 本期项目中,XXX部署在DMZ区平台上,使用2个计算节点;XXX部署在内网平台上,使用2个计算节点
• 在实施时需要为相应的计算节点标记标签,使应用部署时部署到指定的计算节点上。
例如在DMZ网段对XXX应用所使用的2台计算节点打上标签
在部署XXX应用使,nodeSelector需要指明使用的节点的标签为XXX=XXX。
-传统应用访问策略
• Openshift产品推荐通过NodePort类型的Service为某个应用对外暴露一个服务端口。NodePort类型的Service会在集群中的所有节点上监听一个特定的端口,访问任意一个计算机节点的端口,即可访问内部容器中的服务。在集群的所有节点的这个端口都会预留给该应用所用。
• 在F5 VS的Pool Member中配置所有节点,通过Keepalived来实现HA
• 应用系统和用户不用改变现有的访问方式
-应用访问及防火墙
内网计算节点可以直接访问数据库
DMZ区计算节点访问数据库有2种方案:
• 计算节点直接通过内网防火墙访问该应用数据库
内网防火墙仅开通应用所在节点访问内部数据库的端口,例如本期项目,xxx应用仅使用2个节点,则防火墙仅开通这2个节点访问xxx数据库的权限
• 计算节点经Outbound 路由通过内网防火墙访问内网数据o
这oOutbound路由在Openshift中称之为Egress Routero
因此,内网防火墙仅开通应用所在节点访问内部数据库的端口,例如,应用A仅通过路由节点A和B访问内部数据库,则防火墙仅开通这2个节点访问A数据库的权限
Q2: 容器平台建设过程中,如何利用好已有云平台,从技术、架构等层次,需要注意哪些事项?
A2:
容器跑在物理机上,还是跑在云平台虚机上,这是个值得讨论的话题。
对于公有云而言,毫无疑问,肯定是跑在云主机上的。那么,有的客户在上线容器微服务之前,已经有了自己的私有云平台,那么这个时候是购买一堆物理机来另起炉灶,还是基于已有云平台快速部署,这就值得斟酌了。
其实也没什么好纠结的,无非就是一个问题:性能!
跑在物理机上,性能肯定是最佳的,但是你真的需要所谓的性能吗?测过没有,是否真的只有物理机才能满足你的容器微服务应用,根据我的经验,以金融行业来说,大部分用户物理机资源常年处于低负荷状态!以性能为借口,恶意拉动GDP,就是耍流氓啊!
如果你决定跑在已有云平台上,那么,你要考虑的问题如下:
1、充分利用LaC(Infrastructure as Code)实现自动化编排部署,这是云平台最大的优势(比如openstack中的heat),也是裸机集群最大的劣势;
2、网络性能。在IaaS层上面跑容器,网络是个需要认真考虑的问题,calico最佳,但是基础设施改动大,不是所有客户都能接收,flannel+hostgw是个不做选择,原则就是尽量防止二次封装叠加,致使网络性能下降过多。
3、架构上具备后续扩展性,这里指的不仅仅是scale-out扩展,更是功能上的向后扩展,比如随着微服务不多扩大,网络负载不断增加,后续你可能会打算使用service mesh,那么前期就靠考虑清楚兼容性问题
4、最后,也是最朴素的一点,简单、好用、高可用原则,不要为了高大上而“高大上”,搞得自己完全hold不住,得不偿失,一个好的平台选型就是成功的80%
除此之外
1.需要看已有云平台提供了哪些功能或接口可以供 容器平台使用,比如CMDB、比如权限管理、比如应用或者中间件配置等
2.应用 以 容器方式和传统方式 的部署方式和流程 看是否可以抽象统一化,不管是升级回滚扩容等,在运维层面行为一致就能利用已有平台但是自己要实现底层与编排系统的对接
Q3: K8S集群如何实现集群安全?双向认证or简单认证?
A3:
Kubernets系统提供了三种认证方式:CA认证、Token认证和Base认证。安全功能是一把双刃剑,它保护系统不被攻击,但是也带来额外的性能损耗。集群内的各组件访问API Server时,由于它们与API Server同时处于同一局域网内,所以建议用非安全的方式访问API Server,效率更高。
-双向认证配置
双向认证方式是最为严格和安全的集群安全配置方式,主要配置流程如下:
1)生成根证书、API Server服务端证书、服务端私钥、各个组件所用的客户端证书和客户端私钥。
2)修改Kubernetts各个服务进程的启动参数,启用双向认证模式。
-简单认证配置
除了双向认证方式,Kubernets也提供了基于Token和HTTP Base的简单认证方式。通信方仍然采用HTTPS,但不使用数字证书。
采用基于Token和HTTP Base的简单认证方式时,API Server对外暴露HTTPS端口,客户端提供Token或用户名、密码来完成认证过程。
不仅仅是API层面,还有每个节点kubelet和应用运行时的安全,可以看下这里
https://kubernetes.io/docs/tasks/administer-cluster/securing-a-cluster/
K8S的认证相对来说还是个比较复杂的过程,如下这篇文章,详细介绍了K8S中的认证及其原理:
https://www.kubernetes.org.cn/4061.html
Q4: K8S在容器云上的负载均衡策略和总体思想是什么?
A4:
高可用主要分为如下几个:
-外部镜像仓库高可用
外部镜像仓库独立于OCP平台之外,用于存储平台构建过程中所使用的系统组件镜像。因为外部无法直接访问OCP平台的内部镜像仓库,所以由QA环境CD推送到生产环境的镜像也是先复制到外部镜像仓库,再由平台导入至内部镜像仓库。
为了保证外部镜像仓库的高可用, 使用了2台服务器,前端使用F5进行负载均衡,所有的请求均发至F5的虚拟地址,由F5进行转发。后端镜像仓库通过挂载NFS共享存储。
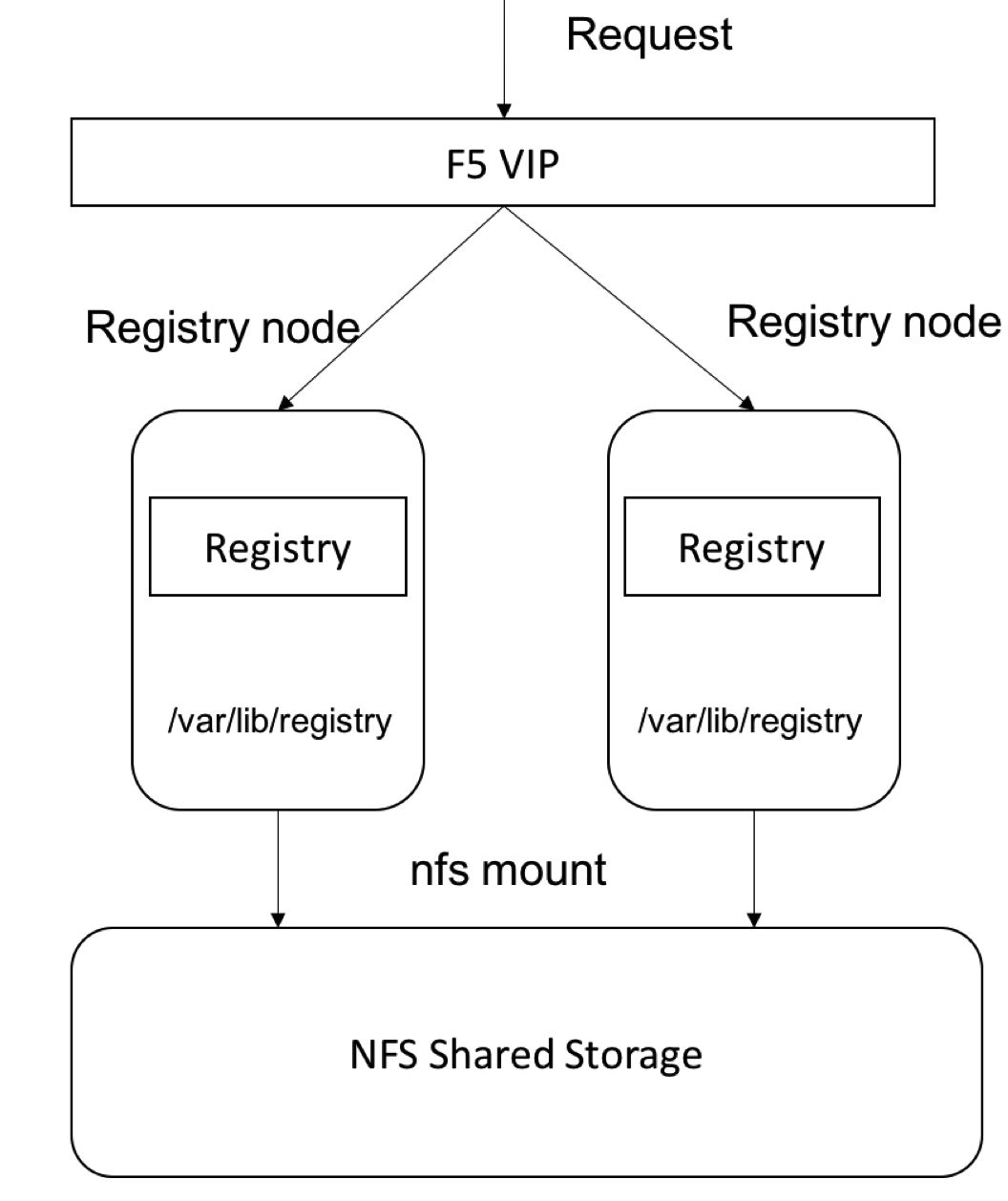
-master主控节点高可用
Openshift的Master主控节点承担了集群的管理工作
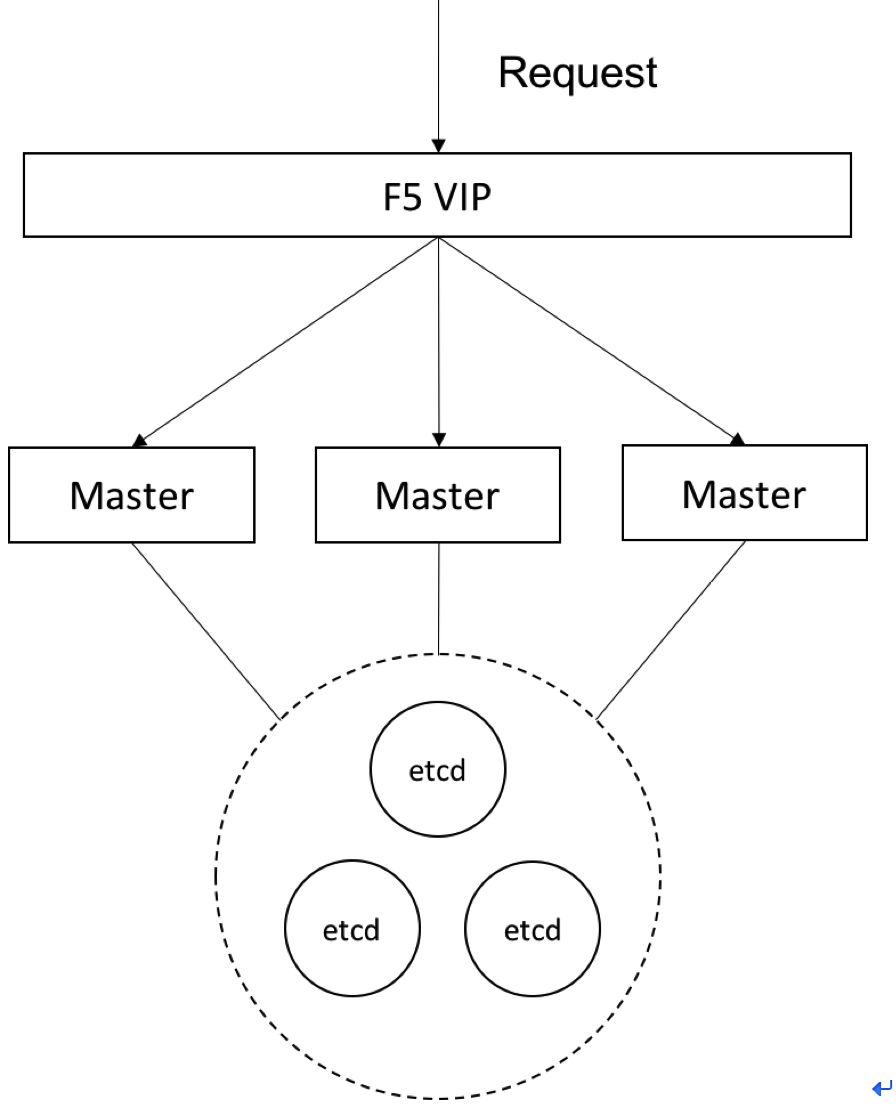
-计算节点(容器应用)高可用
计算节点高可用指计算节点上运行的容器应用的高可用。一个计算节点异常停机后,其上的容器将会被逐步迁移到其他节点上,从而保证了高可用。
同时可以通过标签的方式来管理计算节点,在不同的计算节点划分为不同的可用区或组。在部署应用时,使用节点选择器将应用部署至带有指定标签的目标计算节点上。为了保证高可用,标签组合的目标计算节点数要大于1。这样可以避免一台目标节点宕机后,调度器还能找到满足条件的计算节点进行容器部署。
-应用高可用
基于软件(HAproxy)负载均衡服务,容器服务弹性伸缩时无需人工对负载均衡设备进行配置干预,即可保证容器化应用的持续、正常访问;可通过图形界面自定义负载均衡会话保持策略。
由于平台内部通过软件定义网络为每个应用容器分配了IP地址,而此地址是内网地址,因此外部客户无法直接访问到该地址,所以平台使用路由器转发外部的流量到集群内部具体的应用容器上,如果应用有多个容器实例,路由器也可实现负载均衡的功能。路由器会动态的检测平台的元数据仓库,当有新的应用部署或者应用实例发生变化时,路由器会自动根据变化更新路由信息,从而实现动态负载均衡的能力。
简单一点来说,就是内部服务的动态发现、负载均衡、高可用和外部访问的路由;
通过service,解耦动态变化的IP地址,POD可以随意关停,IP可以任意变,只要DNS正常,服务访问不受影响,但是这里面你的随时保证有个可用的POD,这个时候你就得需要LB了,或者说LB干的就是这个事情。
内部服务之间访问通过service解决了,那么外部访问集群内服务,则通过router即是解决,外网访问要不要负载均衡,大规模高并发情况下是肯定的,当然,外部负载均衡通常需要用户自己搞定了,F5或者开源的HAproxy都行!
Q5: 多租户在kubernets/openshift的实现和管理?
A5:
租户是指多组不同的应用或者用户同时运行在一个基础资源池之上,实现软件、硬件资源的共享,为了安全需求,平台需要提供资源隔离的能力。
在OCP中,project是一个进行租户隔离的概念,它来源于kubernetes的namespace,并对其进行了功能的扩展。利用Project,OCP平台从多个层面提供了多租户的支持。
1. 权限控制。通过OCP平台细粒度的权限管理机制,管理员可以对不同的用户和组设置不同project的权限,不同用户登录以后只能操作和管理特定的project
2. 网络隔离。OCP平台使用openvswitch来管理内部的容器网络,提供两种类型的网络模式,一种是集群范围内互通的平面网络,另一种是project级别隔离的网络。每个project都有一个虚拟网络ID(VNID),不同VNID的流量被openvswitch自动隔离。所以不同项目之间的服务在网络层不能互通。
3. Router隔离。Router是OCP平台一个重要软件资源,它提供了外部请求导入OCP集群内部的能力。OCP提供了Router分组的功能,不同的project可以使用独立的Router,不互相干扰,这样就避免了由于某些应用流量过大时对其他应用造成干扰。
物理资源池隔离。在多租户的环境中,为了提高资源的利用率一般情况下物理资源池是共享的,但是有些用户也会提供独占资源池的需求。针对这种类型的需求,OCP平台利用nodeSelector的功能可以将基础设施资源池划分给特定的project独享,实现从物理层面的隔离。
openshift里面对多租户问题有比较好的解决方案,openshift默认使用OVS来实现SDN,高级安装里面默认使用ovs-subnet SDN插件,网络实现类似于flat网络,因此要实现多租户可以在安装过程中设置参数:
os_sdn_network_plugin_name='redhat/openshift-ovs-multitenant'
这样openshift将使用ovs-multitenant多租户插件,实现租户之间的安全隔离,另外,在openshift的多租户和容器中心化日志实现中,每个租户都只能查看属于自己项目的日志,这个确实有亮点的!
除了OVS插件,openshift是完全支持CNI标准的,因此,是要是符合CNI标准的三方SDN插件,都是可以在openshift中使用的,目前支持的SDN插件有:
1、Cisco Contiv;
2、Juniper Contrail;
3、Nokia Nuage;
4、Tigera Calico ;
5、VMware NSX-T ;
另外,openshift是支持部署在物理机、虚拟机、公有云和私有云上的,可能有些用户会利用已有的公有云或私有云来部署。这个时候,如果使用OVS插件,你OpenShift中的SDN可能出现overlay on overlay的情况,此借助三方SDN插件是个不错的选择,比如flannel+hostgw在性能上肯定就优于默认的ovs-multitenant。
Q6: elasticsearch在K8S中部署?
A6
不论是IaaS还是PaaS,手工部署ELK都是不推荐的,通过ansible可以自动实现,至于如何实现,可以参考redhat文档:
https://docs.openshift.org/3.9/install_config/aggregate_logging.html
至于说分布式存储、本地存储还是集中存储,这个没有既定答案,都是可以参考行业实现,比如Redhat就是参考对象
不建议elasticsearch采用分布式存储,日志亮大情况下如果是分布式存储es写会是瓶颈。
根据你的描述,应该是有两个方面的问题:
1)es的后端存储的选择
2)Pod的创建
问题一:
分布式,本地,集中存储不管是在传统环境,还是在容器的环境中,都有使用。目前对于数据库应用,我们看到还是传统存储-集中存储,占了绝大多数的市场。
分布式存储,随着云计算的兴起,诞生的一种存储架构。它的优势很明显,无中心节点,弹性伸缩,适合云应用,等等。传统的厂商,netapp,emc,ibm,hp都有分布式存储,都是基于其传统的技术;新兴的开源分布式存储ceph,已经成为分布式存储的领军技术,有redhat,suse,xsky,联想,华三等。
分布式存储的劣势主要是,还处于发展阶段,技术有待成熟,有待市场的接受。本地存储,一般使用的应该比较少。主要是数据复制同步方面的问题。
集中存储,目前用的最多的,不管是FCSAN还是IPSAN,其稳定性和安全性都是能够满足要求的。但是,在性价比,可扩展性方面都存在很大的问题。
问题二:
K8S的所有的流程都不是手动完成的,都是基于自动化完成。可以使用chef/ansible/puppt等工具完成。
Q7: K8S集群中的各受管节点以及其中的容器如何做监控?
A7:
kubernetes已成为各大公司亲睐的容器编排工具,各种私有云公有云平台基于它构建,其监控解决方案目前有三种:
(1)heapster+influxDB
(2)heapster+hawkular
(3)prometheus
prometheus作为一个时间序列数据收集,处理,存储的服务,能够监控的对象必须直接或间接提供prometheus认可的数据模型,通过http api的形式发出来。我们知道cAdvisor支持prometheus,同样,包含了cAdivisor的kubelet也支持prometheus。每个节点都提供了供prometheus调用的api。
prometheus支持k8s
prometheus获取监控端点的方式有很多,其中就包括k8s,prometheu会通过调用master的apiserver获取到节点信息,然后去调取每个节点的数据。
k8s节点的kubelet服务自带cadvisor用来收集各节点容器相关监控信息,然后通过heapster收集,这样在dashboard上可以看到容器使用CPU和Memory。
为了长期监控,可以采用prometheus监控方案nodeExporter收集主机监控信息cadvisor收集容器监控信息
k8s中需要给kubelet配合kube-reserved和system-reserved相关参数给系统预留内存
监控领域,无非就是E*K,heapster、influxDB、heapster、hawkular、prometheus、grafana这些东西了,就目前来看,prometheus应该是最具前景的监控工具,在openshift 3.12里面,heapster将由prometheus替换,未来应该是prometheus的天下吧!
二、微服务部署piapian
Q1: 微服务架构按照什么细粒度拆分?
A1:
既然理解微服务是用来重构业务应用的,这个问题就很简单,以业务应用为核心,构建业务服务。忘掉,重构!
业务服务需要数据服务、计算服务、搜索服务、算法服务……以及基本的日志、监控、配置、注册发现、网关、任务调度等组件。
至于数据服务怎么实现,看你团队能力。这才涉及数据分拆,模型重构。
服务通信可以考虑事件驱动机制,也是后期业务数据处理,态势感知,智能风控,智能营销,智能运维等的基础。
感觉这是个没有标准答案的问题,如何拆?按什么套路来拆?问答这两个问题的基础一定要十分熟悉你的业务逻辑才行。微服务这东西,尤其是那种已经运行多年的老系统,一不小心就能拆出问题。
如果对云计算,对OpenStack有了解,建议以OpenStack中的Kolla项目为微服务入门学习对象,Kolla干的事情就是把OpenStack服务拆分成微服务的形式跑在容器中,OpenStack号称全球最大开源Python项目,由几十个开源子项目组成,如果能把这样复杂的集群项目都拆分成微服务,那么一定会得到很多别人给不了的心得体会。
这里以OpenStack为例,Kolla这个项目对OpenStack的拆分,大概如下:
1、先按服务功能划分,得到粗粒度,如计算服务、网络服务、存储服务,这些租粒度模块通常会共享同一个base镜像,这个base镜像中预置了服务模块的共性依赖;
2、基于服务模块的“原子性”拆分,如把计算服务Nova拆分为noav-api、nova-scheduler、nova-compoute、nova-libvirt等等,所谓原子性拆分,就是拆分到不能再往下拆为止,原子拆分后通常就是彼此独立的单进程了,也可以把他们称为是叶子节点了,他们的镜像都是针对自己依赖的“个人”镜像,不能被其他进程共享了。
如果从镜像的角度来看,大概是这样:
父镜像:centos-base
一级子镜像:centos-openstack-base
二级子镜像:centos-nova-base
叶子节点镜像:centos-nova-api
这几个镜像的继承关系是这样的:centos-base->centos-openstack-base->centos-nova-base->centos-nova-api
以上只是举个例子供参考,建议深入了解下Kolla这个项目,对于微服务的拆分就会更有底气些!
先将系统模块化 解耦,别的微服务还是一体都只是部署的问题。 常见的耦合方式有 逻辑耦合 功能耦合 时间耦合等, 感觉从码农的角度来分析解决耦合是基于微服务还是soa化的最大区别。 soa化的系统更多的是业务系统,领域模型级别的。 在分布式系统中远远不够需要考虑性能,安全,事务等,最起码的cap原则还是要把控的。 码农解耦的角度有 接口化,动静分离(查询和修改等),元数据抽取等等,更多的是代码上,设计模式上的真功夫 。 很多架构的估计没这个水平, 只看大象不看大腿。需要明确:
1、充分分析拆分的目的是什么,需要解决什么问题。
2、是否具备微服务技术能力,是否已选型好相应的技术框架,技术变化对企业有什么影响。
3、是否有完善的运维设施保障,比如快速配置、基础监控、快速部署等能力。
Q2: svn环境下实现CI/CD?
A2:
svn可以使用hook(post commit)的方式来实现,但是需要编写hook脚本,灵活度存在问题;
这在svn-repo的粒度较细的情况下还可行,如何一个大的repo,管理起来较复杂,不建议使用;
建议使用jenkins 轮询scm的方式触发pipeline/job
能不能实现CI/CD与SVN无关,关键是你如何构建pipeline,微服务理念下大致这样:
gitlab/svn->Jenkins->build images->push images->docker-registry->pull images->containers
Q3: K8S DNS服务配置如何实现微服务的发布?
A3:
配置k8s dns
DNS (domain name system),提供域名解析服务,解决了难于记忆的IP地址问题,以更人性可读可记忆可标识的方式映射对应IP地址。
Cluster DNS扩展插件用于支持k8s集群系统中各服务之间发现与调用。
组件:
•SkyDNS 提供DNS解析服务
•Etcd 存储DNS信息
•Kube2sky 监听kubernetes,当有Service创建时,生成相应的记录到SkyDNS。
如访问外部DNS,可以设置external_dns 到configmap实现
Q4: 请问在K8S中部署数据库现在有好的解决方案了么?
A4:
银联搞了一个基于容器的DBaaS,是供应商做的,这里是ppt可以参考,主要点:SAN 和 SR-IOV
Q5: K8S目前是否有可视化的服务编排组件
A5:
K8S目前最大的弊端,有点类似OpenStack的早期,使用起来太复杂了,一款好的产品如果仅是功能强大,但是不便于使用,对用户而言,他就不是真正意义上的好产品。目前,K8S中好像也没什么可视化编排组件,满世界的YAML让人眼花缭乱。我的理解,单纯的K8S使用是很难构建一套平台出来的,要构建一套自动化编排平台,应该是以K8S为kernel,集成外围诸多生态圈软件,这样才能实现满足终端用户要求的自动化调度、编排、CI/CD平台。这就好比单纯使用Linux内核来自己构建系统的,都是极为熟悉内核的大牛一样,如果内核外面没有很多tools、utilities供你使用,普通用户是没法使用Linux系统的。从这个角度来看,Openshift就是容器微服务时代的“Linux”。K8S可以去研究,但是如果是拿来使用的话,还是OpenShift吧!
可以根据应用类型指定对应的yaml模板,通过制作前端页面调用k8s api动态更新资源描述并使其生效,至于拖拽组合功能在前端做设计(招专业前端啊)对应到后端需要调用哪些api
类似于是想要一个类似于openstack 的heat工具,或者vmware的blueprint的工具。目前,为了适应快速的业务需求,微服务架构已经逐渐成为主流,微服务架构的应用需要有非常好的服务编排支持,k8s中的核心要素Service便提供了一套简化的服务代理和发现机制,天然适应微服务架构,任何应用都可以非常轻易地运行在k8s中而无须对架构进行改动;
k8s分配给Service一个固定IP,这是一个虚拟IP(也称为ClusterIP),并不是一个真实存在的IP,而是由k8s虚拟出来的。虚拟IP的范围通过k8s API Server的启动参数 --service-cluster-ip-range=19.254.0.0/16配置;虚拟IP属于k8s内部的虚拟网络,外部是寻址不到的。在k8s系统中,实际上是由k8s Proxy组件负责实现虚拟IP路由和转发的,所以k8s Node中都必须运行了k8s Proxy,从而在容器覆盖网络之上又实现了k8s层级的虚拟转发网络。
服务代理:
在逻辑层面上,Service被认为是真实应用的抽象,每一个Service关联着一系列的Pod。在物理层面上,Service有事真实应用的代理服务器,对外表现为一个单一访问入口,通过k8s Proxy转发请求到Service关联的Pod。
Service同样是根据Label Selector来刷选Pod进行关联的,实际上k8s在Service和Pod之间通过Endpoint衔接,Endpoints同Service关联的Pod;相对应,可以认为是Service的服务代理后端,k8s会根据Service关联到Pod的PodIP信息组合成一个Endpoints。
Service不仅可以代理Pod,还可以代理任意其他后端,比如运行在k8s外部的服务。加速现在要使用一个Service代理外部MySQL服务,不用设置Service的Label Selector。
微服务化应用的每一个组件都以Service进行抽象,组件与组件之间只需要访问Service即可以互相通信,而无须感知组件的集群变化。这就是服务发现;
--service发布
k8s提供了NodePort Service、 LoadBalancer Service和Ingress可以发布Service;
NodePort Service
NodePort Service是类型为NodePort的Service, k8s除了会分配给NodePort Service一个内部的虚拟IP,另外会在每一个Node上暴露端口NodePort,外部网络可以通过[NodeIP]:[NodePort]访问到Service。
LoadBalancer Service (需要底层云平台支持创建负载均衡器,比如GCE)
LoadBalancer Service是类型为LoadBalancer的Service,它是建立在NodePort Service集群基础上的,k8s会分配给LoadBalancer;Service一个内部的虚拟IP,并且暴露NodePort。除此之外,k8s请求底层云平台创建一个负载均衡器,将每个Node作为后端,负载均衡器将转发请求到[NodeIP]:[NodePort]。
Q6: service mesh和spring cloud的优缺点
A6
2018年以前,扛起微服务大旗的,可能是Spring Cloud。Service Mesh作为一种非侵入式API的框架。比侵入式的Spring Cloud,虽然还在处于成长期,但是应该更有前景。
关于service mesh的定义,通常以Buoyant 公司的 CEO Willian Morgan 在其文章 WHAT’S A SERVICE MESH? AND WHY DO I NEED ONE? 中对 Service Mesh的定义为参考:
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
就行业而言,Docker和Kubernetes解决的了服务部署的问题,但是运行时的问题还未解决,而这正是Service Mesh的用武之地。Service Mesh的核心是提供统一的、全局的方法来控制和测量应用程序或服务之间的所有请求流量(用数据中心的话说,就是“east-west”流量)。对于采用了微服务的公司来说,这种请求流量在运行时行为中扮演着关键角色。因为服务通过响应传入请求和发出传出请求来工作,所以请求流成为应用程序在运行时行为的关键决定因素。因此,标准化流量管理成为标准化应用程序运行时的工具。
通过提供api来分析和操作此流量,Service Mesh为跨组织的运行时操作提供了标准化的机制——包括确保可靠性、安全性和可见性的方法。与任何好的基础架构层一样,Service Mesh采用的是独立于服务的构建方式。
请参考:https://developers.redhat.com/blog/2016/12/09/spring-cloud-for-microservices-compared-to-kubernetes/
Q7: dubbo,zookeeper环境下,K8S的问题?
A7:
遇到过的问题
1.如果k8s上的应用仅仅是consumer,应该是没问题的,不管provider是在k8s集群内部还是外部
2.如果k8s上的应用是provider,注册到zk时是容器地址,这时如果consumer如果在集群内部容器方式运行是能访问到provider的,如果consumer在集群外部,那就访问不到,也就是你说的情况吧。
这个时候需要做一些路由策略: 设置consumer所在网段到k8s内部网段下一跳为k8s集群内部某一个节点即可,我们在腾讯云和阿里云上就是这么做的,VPC内非K8S节点也可以直通K8S集群内部overlay网络IP地址
通过api gateway来暴露需要对外的API。gateway不仅可以打通网络,还可以隐藏内部api,方便api治理
三、金融行业容器云微服务实践篇
Q1: 金融行业的微服务架构一般是怎样的,案例有哪些?
A1:
-微服务(Microservices Architecture)是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。微服务是指开发一个单个 小型的但有业务功能的服务,每个服务都有自己的处理和轻量通讯机制,可以部署在单个或多个服务器上。微服务也指一种种松耦合的、有一定的有界上下文的面向服务架构。也就是说,如果每个服务都要同时修改,那么它们就不是微服务,因为它们紧耦合在一起;如果你需要掌握一个服务太多的上下文场景使用条件,那么它就是一个有上下文边界的服务。
-微服务架构的优点:
每个微服务都很小,这样能聚焦一个指定的业务功能或业务需求。
微服务能够被小团队单独开发,这个小团队是2到5人的开发人员组成。
微服务是松耦合的,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的。
微服务能使用不同的语言开发。
微服务易于被一个开发人员理解,修改和维护,这样小团队能够更关注自己的工作成果。无需通过合作才能体现价值。
微服务允许你利用融合最新技术。
微服务只是业务逻辑的代码,不会和HTML,CSS 或其他界面组件混合。
-微服务架构的缺点:
微服务架构可能带来过多的操作。
需要DevOps技巧。
可能双倍的努力。
分布式系统可能复杂难以管理。
因为分布部署跟踪问题难。
当服务数量增加,管理复杂性增加。
-微服务适合哪种情况:
当需要支持桌面,web,移动智能电视,可穿戴时都是可以的。
甚至将来可能不知道但需要支持的某种环境。
未来的规划,将以产业链延伸、客户导向及互联网+为战略发展方向,需要BI分析、业务动态扩展、以及敏捷的产品与服务对接和装配的能力支撑,基于以上的技术要求,优化建设支撑企业业务及应用运营的基础设施,结合基础资源现状,建立云计算技术能力,形成快速响应,可持续发展的下一代数据中心。
对比传统方案,容器云的方案,将在对微服务架构的支持、业务弹性扩容、自动化部署、产品快速上线、敏捷/迭代、全面系统监控等方面对IT部门带来全方位的提升。
目前金融行业案例:
银行:中国银联,工商银行,浦发银行、梅州客商银行等;
保险:太平洋保险,平安保险、中国人寿、大地保险、众安保险;
证券:海通证券
Q2: 部署在K8S上的微服务,如何实现有状态和无状态服务对于存储的要求?
A2:
容器的特性决定了容器本身是非持久化的,容器被删除,其上的数据也一并删除。而其上承载的应用分为有状态和无状态。容器更倾向于无状态化应用,可水平扩展的,但并不意味所有的应用都是无状态的,特别是银行的应用,一些服务的状态需要保存比如日志等相关信息,因此需要持久化存储。容器存储大致有三种存储方案:
(1)原生云存储方案:按照纯粹的原生云的设计模式,持久化数据并不是存储在容器中,而是作为后端服务,例如对象存储和数据库即服务。这个方案可以确保容器和它们的数据持久化支持服务松耦合,同时也不需要那些会限制扩展的依赖。
(2)把容器作为虚拟机:利用容器带来的便携性的优点,一些用户将容器作为轻量虚拟机来使用。如果便携性是迁移到容器的原因之一,那么采用容器替代虚拟机来安装遗留应用是这种便携性的反模式。由于大卷中存储数据是紧耦合在容器上,便携性难以实现。
(3)容器持久化数据卷:在容器中运行的应用,应用真正需要保存的数据,可以写入持久化的Volume数据卷。在这个方案中,持久层产生价值,不是通过弹性,而是通过灵活可编程,例如通过设计的API来扩展存储。这个方案结合了持久层和或纯云原生设计模式。
Docker发布了容器卷插件规范,允许第三方厂商的数据卷在Docker引擎中提供数据服务。这种机制意味着外置存储可以超过容器的生命周期而独立存在。而且各种存储设备只要满足接口API标准,就可接入Docker容器的运行平台中。现有的各种存储可以通过简单的驱动程序封装,从而实现和Docker容器的对接。可以说,驱动程序实现了和容器引擎的北向接口,底层则调用后端存储的功能完成数据存取等任务。目前已经实现的Docker Volume Plugin中,后端存储包括常见的NFS,GlusterFS和块设备等。
K8S中的持久性存储主要还是通过PV、PVC和StorageClass来实现。
对于无状态服务,存储可能是不必要的,但是对于由状态服务,需要各种类型的存储来保持状态。在K8S中,PV提供存储资源,PVC使用存储资源,二者是供应者和消费者的关系,那么服务是如何把数据存储到PV上的呢?
我们知道K8S中服务运行在POD中,因此在POD的YAML定义文件中,就需要定义PVC,并指定要关联的PVC名称,然后PVC会根据自身的YAML文件定义绑定合适的PV,流程就是:POD->PVC->PV,当然,这是静态供给方式,静态供给的特定就是先有PV再有PVC。
对于动态供给方式,就需要定义storageclass,并在存储类的YAML文件中声明存储卷供应者,如aws-ebs、ceph-rbd和cinder等,当POD需要存储的时候,再动态创建PV,其特点就是先PVC再PV;
当然,存储这块本身有很多需要考虑的地方,最佳答案还是官网
https://kubernetes.io/docs/concepts/storage/persistent-volumes/
这里有两个扩阅读,关于容器原生存储:
https://www.linuxfoundation.org/press-release/opensds-aruba-release-unifies-sds-control-for-kubernetes-and-openstack/
https://github.com/openebs/openebs
Q3: kubernets如何Devops实现持续部署发布测试全流程?
A3:
使用原生kubernets实现CI/CD最大的弊端,就是你需要自己搞定Jenkins、Registry,以及外围的ELK监控、grafana等等东西,单是部署这些都要花费大量时间。
Openshift已经集成Jenkins,自带内部registry,支持pipeline,用户需要做的就是搭建自己的Gitlab或者SVN用以存放自己的源代码,Openshift社区在Jenkins中实现了很多openshift插件,使得你在Jenkins和openshift之间可以实现互动关联操作,同时openshift提供了私有镜像仓库,可以将编译后的docker镜像存储在openshift内部registry中,然后在开发、测试和生产环境都可从这个registry中抓取镜像部署,开发、测试和生产环境之间在Jenkins中通过openshift插件进行触发,完美解决构建pipeline实现CI/CD。所以,完全没别要自己搞k8s+Jenkins,openshift已经提供了一站式解决方案。还是那句话,与其闷头搞K8S,不如直接上openshift!
kubernetes需要整合Jenkins、Harbor、Gitlab还有日志管理、监控管理等等的其他组件,看需要,来实现持续部署持续发布的全流程。
GitLab主要负责开发代码的存放管理。
Jenkins是一个持续集成持续发布引擎,使用jenkins感觉它太重了,不太适合容器,当然也可以选择其他的。
Harbor就是私有镜像仓库了,新版Harbor提供了镜像安全扫描等功能,当然也可以使用其他的,如registry。
完成DevOps的话需要整合这些进行一些平台化的开发,这样才会有比较好的交互体验。也可以直接使用Jenkins
Q4:微服务的编排K8S提供了很多yaml文件,但这其实用户体验并不好,有什么图形编排的解决思路么?以及怎样用微服务的理念打造企业中台(SOA)?
A4:
SOA面向服务架构,它可以根据需求通过网络对松散耦合的粗粒度应用组件进行分布式部署、组合和使用。服务层是SOA的基础,可以直接被应用调用,从而有效控制系统中与软件代理交互的人为依赖性。
大多数初次接触YAML的人都会觉得这类文档模板体验极差,感觉太反人类了,各种对齐、格式,一不小心就语法报错,通常又不能准确定位错误点,对新手来说,这种YAML文本确实很头疼,但是又没法,K8S里面尽是YAML,奈何????
即使真有图形编排解决思路,感觉也是换汤不换药。
解决问题的根本办法,通常就是釜底抽薪。目前,已有大牛发起noYAML运动,虽然还未成气候,但是至少说明确实有很多人不喜欢YAML,而且在使用实际行动来不喜欢。
细数YAML“十宗罪”:
https://arp242.net/weblog/yaml_probably_not_so_great_after_all.html
https://news.ycombinator.com/item?id=17358103
如果希望在K8S上运行微服务,那么有必要了解一些云原生编程语言,如:
Pulumi(https://www.pulumi.com/)
Ballerina(https://ballerina.io/)
对于终端用户而言,或许平台才是你最终需要的。设想你有一个平台引擎,这个平台引擎集成了Docker及其调度引擎K8S,然后你只需要编写业务逻辑代码,然后镜像封装、容器部署调度全部交由平台处理,当然这个过程中各种YAML文件也由平台自动生成,何乐而不为?
那问题就是:有没有这样的平台?
以前就有,但是确实不怎么好用,但是OpenShift V3出来之后,个人认为它就是我们要找的平台。作为终端用户,我个人并不建议直接搞K8S,对K8S有些概念术语上的理解,就可直接上OpenShift V3。K8s和Docker仅是Openshift的kernel,除此之外,OpenShift还集成了很多应用程序编译、部署、交付和生命周期管理的生态圈软件,因此,比起硬上K8S,OpenShift也许才是很多人需要寻找的东西!
-
全面提升,阿里云Docker/Kubernetes(K8S) 日志解决方案与选型对比2018-02-28 0
-
全面提升,阿里云Docker/Kubernetes(K8S) 日志解决方案与选型对比2018-02-28 0
-
微服务架构和CQRS架构基本概念介绍2019-05-22 0
-
微服务优势_微服务架构的好处与不足2018-02-23 4464
-
OpenStack与K8s结合的两种方案的详细介绍和比较2018-10-14 27524
-
容错性好、易于管理和便于观察:浅谈如何利用K8s全面拥抱微服务架构2019-03-08 581
-
K8S集群内Debug微服务的最佳实践2021-02-02 2535
-
Docker不香吗为什么还要用K8s2021-06-02 3557
-
简单说明k8s和Docker之间的关系2021-06-24 3556
-
K8S集群服务访问失败怎么办 K8S故障处理集锦2021-09-01 15945
-
K8S(kubernetes)学习指南2022-06-29 653
-
k8s是什么意思?kubeadm部署k8s集群(k8s部署)|PetaExpres2023-07-19 1211
-
什么是K3s和K8s?K3s和K8s有什么区别?2023-08-03 7945
-
混合云部署k8s集群方法有哪些?2024-11-07 324
-
k8s微服务架构就是云原生吗?两者是什么关系2024-11-25 335
全部0条评论

快来发表一下你的评论吧 !
