

瑞芯微(EASY EAI)RV1126B RKLLM大模型介绍
描述
1. RKLLM简介
1.1 RKLLM工具链介绍
1.1.1 RKLLM-Toolkit功能介绍
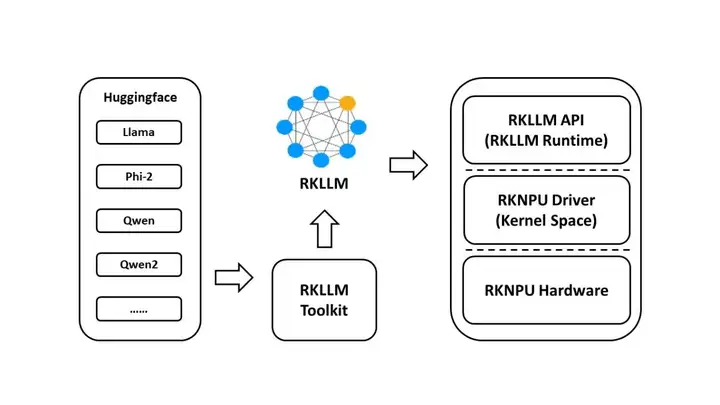
RKLLM-Toolkit 是为用户提供在计算机上进行大语言模型的量化、转换的开发套件。通过该 工具提供的 Python 接口可以便捷地完成以下功能:
(1)模型转换:支持将 Hugging Face 和 GGUF 格式的大语言模型(Large Language Model, LLM)转换为 RKLLM 模型,目前支持的模型包括 LLaMA, Qwen, Qwen2, Qwen3, Phi-2, Phi-3, ChatGLM3, Gemma, Gemma2, Gemma3, Gemma3n, InternLM2, TeleChat2, MiniCPM-S, MiniCPM 和 MiniCPM3, MiniCPM4,转换后的 RKLLM 模型能够在 Rockchip NPU 平台上加载使用。
(2)量化功能:支持将浮点模型量化为定点模型,目前支持的量化类型包括
a. w4a16;
b. w4a16 分组量化(支持的分组数为 32, 64, 128);
c. w8a8;
d. w8a8 分组量化(支持的分组数为 128, 256, 512);
1.1.2 RKLLM Runtime功能介绍
RKLLM Runtime 主要负责加载 RKLLM-Toolkit 转换得到的 RKLLM 模型,并在板端通过调 用 NPU 驱动在 Rockchip NPU 上加速 RKLLM 模型的推理。在推理 RKLLM 模型时,用户可以自 行定义 RKLLM 模型的推理参数设置,定义不同的文本生成方式,并通过预先定义的回调函数不断获得模型的推理结果。
1.2 RKLLM开发流程介绍
RKLLM 的整体开发步骤主要分为 2 个部分:模型转换和板端部署运行。
(1)模型转换:
在这一阶段,用户提供的 Hugging Face 格式的大语言模型将会被转换为 RKLLM 格式, 以便在 Rockchip NPU 平台上进行高效的推理。这一步骤包括:
a. 获取原始模型:1、开源的 Hugging Face 格式的大语言模型;2、自行训练得到的大语 言模型,要求模型保存的结构与 Hugging Face 平台上的模型结构一致;3、GGUF 模型,目前仅支持 q4_0 和 fp16 类型模型;
b. 模型 加载 :通 过 rkllm.load_huggingface()函数 加载 huggingface 格式 模型 ,通过rkllm.load_gguf()函数加载 GGUF 模型;
c. 模型量化配置:通过 rkllm.build() 函数构建 RKLLM 模型,在构建过程中可选择是否 进行模型量化来提高模型部署在硬件上的性能,以及选择不同的优化等级和量化类型。
d. 模型导出:通过 rkllm.export_rkllm() 函数将 RKLLM 模型导出为一个.rkllm 格式文件,用于后续的部署。
(2)板端部署运行:
这个阶段涵盖了模型的实际部署和运行。它通常包括以下步骤:
a. 模型初始化:加载 RKLLM 模型到 Rockchip NPU 平台,进行相应的模型参数设置来 定义所需的文本生成方式,并提前定义用于接受实时推理结果的回调函数,进行推理前准备。
b. 模型推理:执行推理操作,将输入数据传递给模型并运行模型推理,用户可以通过预 先定义的回调函数不断获取推理结果。
c. 模型释放:在完成推理流程后,释放模型资源,以便其他任务继续使用 NPU 的计算
资源。
以上这两个步骤构成了完整的 RKLLM 开发流程,确保大语言模型能够成功转换、调试,并 最终在 Rockchip NPU 上实现高效部署。
1.3 资料下载
模型文件、模型转换与部署代码的百度网盘下载链接(比较大,可以选择来下载):
https://pan.baidu.com/s/1-2cDEEH-Ljsnj8cyBFrCZg?pwd=1234(提取码:1234 )。
- 相关推荐
- 热点推荐
- 人工智能
- 开发板
- 瑞芯微
- EASY-EAI灵眸科技
- RV1126B
-
瑞芯微(EASY EAI)RV1126B 音频输入2025-12-18 2780
-
瑞芯微(EASY EAI)RV1126B 音频输出2026-04-01 8813
-
瑞芯微RV1126B开发板(EASY-EAI-PI2) 主板简介2026-06-01 4319
-
【EASY EAI Nano-TB(RV1126B)开发板试用】介绍、系统安装2025-12-23 1119
-
【EASY-EAI-PI2(RV1126B)开发板试用体验】整理开发板的资料2026-06-11 55
-
【EASY-EAI-PI2(RV1126B)开发板试用体验】--环境搭建2026-06-12 142
-
【EASY-EAI-PI2(RV1126B)开发板试用体验】开箱测试2026-06-13 209
-
【免费试用】EASY EAI Nano-TB(RV1126B)开发套件评测2025-09-23 1461
-
瑞芯微RV1126B特性概述2025-10-09 2512
-
瑞芯微(EASY EAI)RV1126B rknn-toolkit-lite2使用方法2026-04-22 1201
-
瑞芯微(EASY EAI)RV1126B yolov11训练部署教程2026-05-09 1026
-
瑞芯微RV1126B 方案特性2026-05-11 2464
-
瑞芯微(EASY EAI)RV1126B ubuntu系统SDK源码获取2026-05-23 223
-
瑞芯微(EASY EAI)RV1126B kernel2026-05-25 254
-
新品发布!新一代RV1126B开发套件EASY-EAI-PI2正式上线2026-06-08 811
全部0条评论

快来发表一下你的评论吧 !
