

UC Berkeley大学的研究人员们利用深度姿态估计和深度学习技术
电子说
描述
UC Berkeley大学的研究人员们利用深度姿态估计和深度学习技术,让智能体从单一视频中学习人物动作,并生成近乎相同的结果。更重要的是,智能体还能将所学到的技能应用于不同环境中。以下是论智对其博文的编译。
不论是像洗手这样日常的动作,还是表演杂技,人类都可以通过观察学习一系列技能。随着网络上越来越多视频资源的出现,想找到自己感兴趣的视频比之前更容易了。在YouTube,每分钟都有300小时的视频上传成功。但是,对于机器来说,从如此大量的视觉数据中学习技能仍然困难。大多数动作模仿的学习方法都需要有简洁地表示,例如从动作捕捉获取的记录。但想得到动作捕捉的数据可能也非常麻烦,需要大量设备。另外,动作捕捉系统也仅限于遮挡较少的室内环境,所以有很多无法记录的动作技能。那么,如果智能体可以通过观看视频片段来学习技能,不是很好吗?
在这一项目中,我们提出了一种可以从视频中学习技能的框架,通过结合计算机视觉和强化学习中出现的先进技术,该框架能让智能体学会视频中出现的全部技能。例如给定一段单目视频,其中一个人在做侧手翻或后空翻,该系统的智能体就可以学习这些动作,并重现出一样的行为,无需人类对动作进行标注。
从视频中学习身体动作的技能最近得到很多人的关注,此前的技术大多依靠人们手动调整框架结构,对生成的行为有很多限制。所以,这些方法也仅在有限的几种情境下使用,生成的动作看起来也不太自然。最近,深度学习在视觉模拟领域表现出了良好的前景,例如能玩雅达利游戏,机器人任务
框架
我们提出的框架包含三个阶段:姿态估计、动作重建和动作模拟。在第一阶段,框架首先对输入的视频进行处理,在每一帧预测人物动作。第二步,动作重建阶段会将预测出的动作合并成参考动作,并对动作预测生成的人工痕迹做出修正。最后,参考动作被传递到动作模拟阶段,其中的模拟人物经过训练,可以用强化学习模仿动作。
动作估计
给定一段视频,我们用基于视觉的动作估计器预测每一帧演员的动作qt。该动作预测器是建立在人类网格复原这一工作之上的(akanazawa.github.io/hmr/),它用弱监督对抗的方法训练动作估计器,从单目图像中预测动作。虽然在训练该估计器的时候需要标注动作,不过一旦训练完成,估计器在应用到新图片上时就无需再次训练了。
用于估计人物动作的姿态估计器
动作重建
姿态估计给视频中的每一帧都做出了单独的动作预测,但两帧之间的预测可能会出现抖动伪影。另外,虽然近些年基于是觉得姿态估计器得到了很大进步,但有时它们也可能会出现较大失误。所以,这一步的动作重建就是减少出现的伪影,从而生成更逼真的参考动作,能让智能体更轻易地模拟。为了实现这一点,我们对参考动作进行了优化Q={q0,q1,…,qt},以满足以下目标:
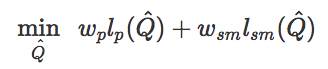
其中lp(Q^)是为了让参考动作和原始动作预测更接近,lsm(Q^)是为了让相邻的帧之间的动作更相近,从而生成更流畅的动作。另外,wp和wsm是不同损失的权重。
这一过程可以显著提高参考动作的质量,并且修正一些人工生成的痕迹。
动作模拟
有了参考动作{q^0,q^1,…,q^t}之后,我们就可以训练智能体模仿这些动作了。这一阶段用到的强化学习方法和之前我们为模拟动作捕捉数据而提出的方法相似,奖励函数仅仅是为了让智能体的动作和重建后的参考动作之间的差异最小化。
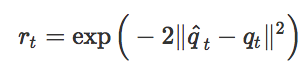
这一方法表现得很好,我们的智能体可以学习很多杂技动作,每个动作只需要一段视频就能学会。
结果
最终我们的智能体从YouTube上的视频中学习了20多种不同的技能。
尽管智能体的形态有时和视频中的人物不太一样,但这一框架仍然能逼真地重现很多动作。除此之外,研究人员还用模拟的Atlas机器人模仿视频动作。
使用模拟人物(智能体)的好处之一就是,在新环境下可以用模拟对象生成相应的动作。这里,我们训练智能体在不规则平面上采取不同动作,而它所对应的原始视频是在平地上运动的。
虽然和原始视频中的环境大不相同,学习算法仍然能生成相对可靠的策略来应对不同路面情况。
总的来说,我们的框架采用的都是视频模仿问题中常见的方法,关键是要将问题分解成更加易处理的组合部分,针对每个部分采取正确的方法,然后高效地把它们组合在一起。但是模拟视频中的动作仍然是非常有挑战性的工作,目前还有很多我们无法复现的视频片段:
这种江南style的舞步,智能体就难以模仿
但是看到目前我们实现的成果,还是很振奋人心。未来我们还有很多需要改进的地方,希望这项工作能作为基础,为智能体在未来处理大量视频数据的能力奠定了基础。
-
2017全国深度学习技术应用大会2017-03-22 0
-
基于深度学习的异常检测的研究方法2021-07-12 0
-
讨论纹理分析在图像分类中的重要性及其在深度学习中使用纹理分析2022-10-26 0
-
研究人员们提出了一系列新的点云处理模块2019-08-02 3060
-
谷歌发明自主学习机器人 结合了深度学习和强化学习两种类型的技术2020-03-17 1491
-
研究人员推出了一种新的基于深度学习的策略2020-03-26 2608
-
研究人员开发了一种基于深度学习的智能算法2020-09-10 2265
-
(KAIST)研究人员提供了一种深度学习供电的单应变电子皮肤传感器2020-09-22 2009
-
研究人员开发出深度学习算法用于患者的诊断2020-11-16 1835
-
基于深度学习的二维人体姿态估计方法2021-03-22 865
-
基于深度学习的二维人体姿态估计算法2021-04-27 765
-
研究人员提出将深度学习技术引入细胞成像和分析中2021-05-06 2275
-
AI深度相机-人体姿态估计应用2023-07-31 1013
-
深度解析深度学习下的语义SLAM2024-04-23 1291
全部0条评论

快来发表一下你的评论吧 !
