

蚂蚁集团CoREB如何重新定义代码检索评测基准
描述
本文由蚂蚁集团出品。
CoREB(Code Retrieval Embedding Benchmark)是蚂蚁集团围绕"代码语义检索"方向所打造的开放式评测基准。我们希望为整个社区提供一套干净、严格、不可作弊、贴近真实工程场景的代码嵌入模型测试集——让"代码模型到底好不好"这件事,从主观感受走向可量化、可复现、可追踪的实证科学。
一、为什么我们还需要一个新的代码检索基准?
过去两三年,代码嵌入模型的发展节奏明显加快。从通用方向的 Qwen3-Embedding、jina-embeddings-v4、embeddinggemma,到专注代码的 jina-code-embeddings、C2LLM、F2LLM,参数量从 0.5B 一路飙升到 8B;训练数据动辄上百亿 token,对比学习的负例池也越铺越大。模型卡上的指标越刷越漂亮,论文里的折线图越画越陡峭,看起来"代码检索"这件事仿佛已经被解决了。
然而当我们把这些 SOTA 模型搬进真实的"竞赛级"代码检索场景里测试时,却发现一个令人尴尬的事实:
现有基准要么太简单(同一份代码改个变量名都能命中),要么太"作弊"(测试问题早被模型在预训练里见过)。
具体而言,社区现有的代码检索评测面临三个深层痛点:
痛点一:数据泄漏几乎不可避免。 主流模型在预训练时都接触过 GitHub、LeetCode、Codeforces 等公共代码源,许多"老牌"基准的题目早就被模型背在了"参数记忆"里。这种情况下,模型在评测上的高分,到底是真的学会了语义检索,还是单纯做了记忆复现?没人说得清。
痛点二:硬负例其实并不"硬"。 不少基准号称用了 hard negative mining,但仔细看就会发现,所谓"硬负例"往往只是来自完全无关问题的随机抽样。这种"假困难"——主题不同、词汇分布不同、变量命名风格也不同——对任何一个稍微合格的嵌入模型都不构成挑战。真正考验模型的,是那些长得像、读起来像、关键词都一致、但功能上彻底错误的代码与文本。一个能在这种"语义陷阱"里站稳脚跟的模型,才有资格被叫作"理解代码"。
痛点三:评测粒度过粗,掩盖了真实的能力差距。 多数榜单只给出一个"平均分",把多个子任务的得分粗暴加权。结果就是:一些模型在简单任务上拿满分,在难任务上接近 0 分,但平均下来居然能进前三。这种榜单不仅误导研究方向,也误导工程师在真实业务里的选型决策。
CoREB 就是为同时解决这三个痛点而生。我们的设计哲学可以用一句话概括:
让"看起来能做对"的模型在 CoREB 上下不来台,让"真的能做对"的模型在 CoREB 上拿到应得的分数。
CoREB 建立在 LiveCodeBench 最新发布的题库之上,覆盖 175 道竞赛真题、5 种主流编程语言(Python / C++ / Java / Go / Ruby)、上千条由强模型(Claude Sonnet 4.5、Gemini 3 Flash 等)实测验证过的高质量查询-代码对。
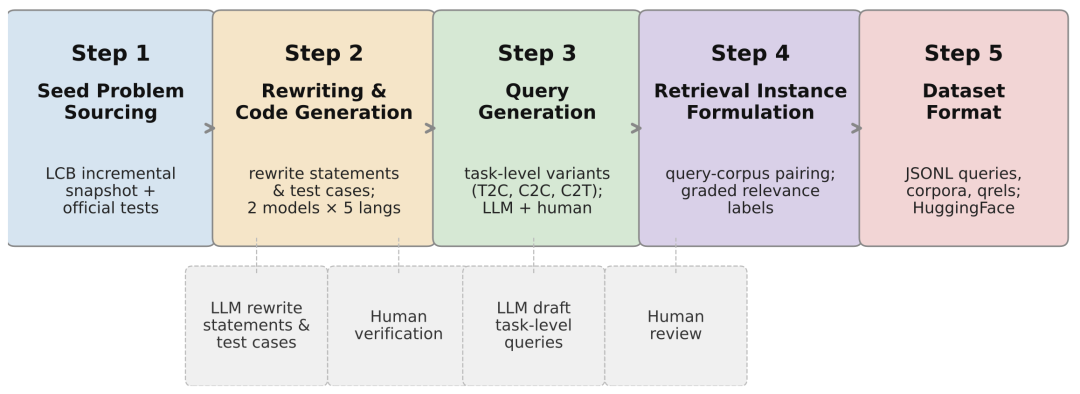 CoREB 数据集构建管线
CoREB 数据集构建管线
整个数据集严格按照"竞赛发布时间窗"切分训练与测试,v202602 与 v202603 两个 release 在题目层面完全互不重叠——前者覆盖 2024 年 9 月至 2025 年 1 月的题目,后者覆盖 2025 年 1 月至 4 月。这意味着任何在我们 reranker 训练集上看到过的题目,都绝对不会出现在测试集里。这一时间切分方案,从根源上排除了"在训练集上微调出测试集表现"的泄漏风险。
二、数据集一览:规模、语言、模型一目了然
 CoREB 数据集组成
CoREB 数据集组成  语料库与查询的分布
语料库与查询的分布
v202603 释出版本核心数字:
| 项目 | 规模 | 说明 |
|---|---|---|
| 代码语料库 | 1,744 条 | claude-sonnet-4-5 × 875 + gemini-3-flash × 869 |
| 文本语料库 | 875 条 | 175 条原始题目描述 + 700 条 LLM 噪声样本 |
| 查询总数 | 2,483 | T2C 1,117 / C2T 1,200 / C2C 166 |
| qrel 标注总数 | 10,877 | 含 4,257 正例 + 6,620 硬负例(v2 graded) |
| 覆盖语言 | 5 | Python / C++ / Java / Go / Ruby |
| 覆盖模型 | 2 | Claude Sonnet 4.5 + Gemini 3 Flash |
每个语言约 350 条代码、每个生成模型约 875 条,分布均衡而干净。所有代码都已通过 LiveCodeBench 的测试用例真实执行过,每条标注都附带 pass/fail 信息——这是我们后续构建"硬负例"的基石。
更重要的是,CoREB 的所有数据 100% 来自竞赛题目的新发布窗口,没有混入任何 Stack Overflow、GitHub 代码片段、教程示例等来源易污染的语料。这是我们能宣称"不可作弊"的核心保证之一。
三、三大任务:覆盖代码语义映射的三个维度
CoREB 的核心结构由三大任务组成,每个任务针对代码-语义映射中的一个独立维度:
| 任务 | 简称 | 输入 → 输出 | 难度 | 真实场景 |
|---|---|---|---|---|
| 文本到代码 | T2C | 自然语言描述 → 代码解 | 自然语言代码搜索、需求→代码生成检索 | |
| 代码到代码 | C2C | 一种语言的解 → 另一种语言的等价解 | 跨语言代码迁移、多语言代码库统一检索 | |
| 代码到文本 | C2T | 代码片段 → 对应题目描述 | 代码注释生成、文档对齐、可解释性 |
T2C:最具挑战的"凭描述找代码"
T2C 是 CoREB 中最有挑战、也最贴近真实工程需求的任务。它进一步拆解为三个子任务,对应不同的工程语境:
• canonical_retro:查询是规范化、抽象化后的题目意图,类似"内部技术文档检索"
• full_retro:查询包含完整题目背景(含示例、约束、边界条件),类似"用户在搜索框输入完整需求"
• search:查询本身在语料库里没有完全对应的题目,要求模型纯靠语义泛化,类似"探索性代码搜索"
search 子任务的结果尤其值得反复琢磨:
 T2C search 子任务上所有模型 nDCG 都接近零
T2C search 子任务上所有模型 nDCG 都接近零
所有 11 个被测模型的 nDCG@10 都接近 0(范围 0.0008–0.023)。这不是模型坏了,而是说明当我们抽掉"必须有完全匹配项"这条隐含拐杖之后,纯语义检索的能力距离我们想象中的"理解代码"还有非常远的距离。
这一发现对工业界尤其重要:在真实业务场景里,用户输入的搜索词与代码库内的解几乎从来不会字面对齐。如果一个模型只会做"精确题目匹配",那它能解决的也只是一小部分理想化场景。CoREB 的 search 子任务,就是为了把这个潜在缺陷显式量化出来。
T2C 的语言偏置:被忽视的真实问题
不同目标语言下,模型表现的差异也相当显著:
 T2C 不同语言难度梯度
T2C 不同语言难度梯度
any(不限语言)一致最高,python 大多排第二,ruby 与 go 则是大多数模型的最痛点。从 C2LLM-7B 的数据可以清晰看到:"any" 子任务能跑到 0.756,但 java 只剩 0.418——同一个模型、同一类查询,仅因目标语言不同就能拉开近一倍的差距。
这种语言偏置在工程上意味着什么?意味着你不能假设一个在 Python 上表现优异的模型,到 Go 或 Ruby 上还能保持同样水平。多语言代码业务的同学,必须按语言单独评测后再做选型。
C2C:跨语言"功能等价"的判定
C2C 任务要求模型把一份 Python 代码与其 Java/Go/C++/Ruby 版本对应起来,它考察的是模型能否抽象出"算法意图"这一层语义,而非被表面语法迷惑:
 C2C 跨语言检索热力图
C2C 跨语言检索热力图
C2C 还揭示了一个非常有意思的现象:所有模型在 nDCG@1 上都会拿到 0 分——因为查询自身的代码也在语料库里(这是真实跨语言搜索场景的还原),且总是被排在第一位。
这并不是模型失败,而是基准设计本身的"诚实"反映:在真实的跨语言检索里,"找到自己"是一种与"找到翻译"截然不同的行为,是预期之内的。我们用 nDCG@10 这种更宽容的指标来评测 C2C,正是为了避免这种结构性"零分"扭曲整体判断。
C2T:相对简单但暗藏陷阱
C2T 表面上是最简单的——给一段代码,找回它的题目描述。但 v2 版本在语料库里加入了 LLM 生成的同题噪声文本作为 rel=1 硬负例。这些噪声文本由 gemini-2.5-flash 生成、经过 gpt-4o 二次清洗,主题贴合、句式自然、术语正确,唯独"不是真正的题目描述"。
结果显示,即便是最好的模型(Gemini-Embedding-2-preview, 0.7841)也距离"完美命中"还有相当差距——这正是噪声文本在悄悄拉低分数。这种"功能性区分"恰恰是 CoREB 的核心评测哲学:让模型证明自己不是被表面相似性误导,而是真的看懂了语义。
四、三级分级标注:让"硬负例"成为评测的灵魂
传统检索基准只有"相关 / 不相关"二元判定。CoREB 引入了三级分级 qrel 方案,让每一条标注都承载更多语义信息:
| 级别 | 标签 | 含义(按任务) |
|---|---|---|
| rel=2 | 正例 | T2C: 同题且通过全部测试的代码;C2T: 该题真正的描述文本;C2C: 正确的跨语言翻译 |
| rel=1 | 硬负例 | T2C: 同题但未通过测试的相似代码;C2T: LLM 生成的同题/近题噪声文本;C2C: 失败的翻译或被子任务排除的解 |
| 缺席 | 易负例 | 与查询无关;仅在训练 reranker 时随机抽样 |
这个设计的关键点在于:rel=1 的条目仍然留在语料库中,它们不是被"剔除"的,而是被"标记"的。在评测时设 relevance_level=2,rel=1 条目就成了高度迷惑性的"语料库内陷阱"——它们与查询主题完全一致、词汇高度重合,一旦被模型排到正例前面就会立刻拖低 nDCG。
 硬负例引入后对评测指标的"通胀压缩"效应
硬负例引入后对评测指标的"通胀压缩"效应
上图清晰展示了 v2 graded qrel 对评测分数的"通胀压缩"效应——从 v1 二元方案到 v2 三级方案,几乎所有模型的 nDCG@10 都下降了 10–15 个百分点,这正是"假困难"被替换成"真困难"后该有的结果。压缩后的分数,才更贴近模型在工业场景下的真实战斗力。
v202603_v2 qrel 规模:
| 任务 | 正例 (rel=2) | 硬负例 (rel=1) | 合计 |
|---|---|---|---|
| T2C | 2,814 | 3,136 | 5,950 |
| C2T | 820 | 2,650 | 3,470 |
| C2C | 623 | 834 | 1,457 |
| 总计 | 4,257 | 6,620 | 10,877 |
也就是说,硬负例的数量与正例相当甚至更多。这种设计让 CoREB 真正反映模型区分"语义近似但功能错误"的能力——这恰好是工业代码搜索最在乎的一点。一个能在 CoREB 上拿高分的模型,必须真正理解"这段代码在做对的事",而不只是"这段代码在谈对的话题"。
五、最新评测榜单:来自 11 个主流模型的故事
我们在 v202603_v2 上完成了 11 个主流嵌入模型的完整评测,每一个数字都对应一份开放的 result JSON:
 模型总体对比
模型总体对比  三任务 nDCG@10 横向对比
三任务 nDCG@10 横向对比
| Rank | 模型 | 参数量 | Avg | T2C | C2C | C2T |
|---|---|---|---|---|---|---|
| 1 | gemini-embedding-2-preview | API | 0.6385 | 0.4336 | 0.6979 | 0.7841 |
| 2 | C2LLM-7B | 7B | 0.6225 | 0.4432 | 0.6587 | 0.7658 |
| 3 | jina-code-embeddings-1.5b | 1.5B | 0.6069 | 0.4140 | 0.6713 | 0.7354 |
| 4 | C2LLM-0.5B | 0.5B | 0.6040 | 0.4301 | 0.6565 | 0.7254 |
| 5 | jina-code-embeddings-0.5b | 0.5B | 0.5962 | 0.3861 | 0.6774 | 0.7252 |
| 6 | F2LLM-4B | 4B | 0.5472 | 0.4069 | 0.4999 | 0.7348 |
| 7 | Qwen3-Embedding-4B | 4B | 0.4952 | 0.3900 | 0.3917 | 0.7039 |
| 8 | F2LLM-1.7B | 1.7B | 0.4853 | 0.3833 | 0.3826 | 0.6899 |
| 9 | Qwen3-Embedding-0.6B | 0.6B | 0.4431 | 0.3491 | 0.3836 | 0.5966 |
| 10 | F2LLM-0.6B | 0.6B | 0.4393 | 0.3437 | 0.3335 | 0.6409 |
| 11 | Qwen3-Embedding-8B | 8B | 0.4277 | 0.3281 | 0.3204 | 0.6347 |
从这张表里,我们能读出若干反直觉的故事。每一个都对应一条值得社区认真讨论的研究方向。
发现 1:通用大模型未必赢——代码这件事有它自己的语义结构
榜首 Gemini-Embedding-2-preview 平均成绩最高,但它在 T2C 上反而被参数量小得多的 C2LLM-7B 超越(0.4432 vs 0.4336)。考虑到 Gemini-Embedding 背后是 Google 顶级的预训练模型与海量训练数据,这一结果说明:
"代码这件事"仍然有它独立的语义结构,不是用更大的通用语料就能完全覆盖。
针对代码场景做专门的对比学习目标、加入功能正确性约束、用执行结果做监督信号——这些专门设计的价值,目前看仍然大于"无脑堆参数"。
发现 2:小模型用代码专精换性能——参数效率新范式
 参数效率:性能 vs 参数量
参数效率:性能 vs 参数量
jina-code-embeddings-0.5B(0.5962)力压 Qwen3-Embedding-8B(0.4277),16 倍参数差距下反而领先 17 个百分点。这是给所有在意延迟、显存与部署成本的工程团队的一个强烈信号:针对代码场景做专门训练,胜过盲目堆参数。
对一线工程师来说,这条发现意味着:
• 部署 0.5B 的代码专用模型,延迟可能只有 8B 通用模型的 1/10,效果却更好
• 在 GPU 资源紧张的边缘场景,代码专精方向是显著划算的
• 选型时不要被"参数量"或"通用 leaderboard 排名"带偏,必须用与你业务场景同构的基准做实测
发现 3:Qwen3 的"中段塌陷"——尺度律并非万能
Qwen3 系列展现了非常诡异的非单调缩放:
• Qwen3-0.6B:C2C nDCG@10 = 0.3836
• Qwen3-4B:C2C nDCG@10 = 0.3917(仅微涨)
• Qwen3-8B:C2C nDCG@10 = 0.3204(反向下跌)
8B 模型在跨语言代码检索上比 0.6B 还差——这种"中段塌陷"在通用文本检索任务里几乎不会出现,但在代码任务里却频繁可见。可能的原因包括:训练数据中代码占比下降、对比学习温度参数与负例池规模的微妙不匹配、或是模型容量过剩导致的过拟合。这是一个值得整个社区深入研究的现象。
发现 4:子任务粒度才是真相——总分会撒谎
 子任务级别细粒度对比
子任务级别细粒度对比
总分掩盖了许多细节。从子任务级别可以看到,不同模型的强项分布迥异——有的擅长 retro 重检索,有的擅长 search 泛化,有的在 cross-lang 跨语言任务上一骑绝尘,有的则在 match 子任务上表现稳定。
没有真正的"全能选手"。 这就是为什么 CoREB 坚持发布所有子任务的细粒度结果——我们希望让工程师在选型时,能精准对位自己的业务场景,而不是被"平均分"误导。
发现 5:reranker 不是万能补丁
我们额外测试了 reranker 在 4 个代表性模型上的效果:
 Reranker 对三任务带来的 nDCG 增量
Reranker 对三任务带来的 nDCG 增量
• C2T 任务上 reranker 持续拖累性能(−0.042 到 −0.079)。原因是 C2T 的语料库较小(仅 875 条),cross-encoder 反而容易被噪声文本"过度评分"
• C2C 任务上 reranker 大多有帮助(+0.005 到 +0.046)。cross-encoder 在跨语言细粒度区分上确实更强
• T2C 任务上 reranker 几乎不动(−0.009 到 +0.015)。任务难度过高,单层 reranker 难以撬动
这个结果对工业系统设计有直接启示:
"加个 reranker"并不是免费午餐。它在某些任务上确实能涨点,但在另一些任务上反而会成为系统的拖累。设计前必须做完整的端到端基准测试。
发现 6:任务难度排序高度一致
C2T (0.59–0.78) > C2C (0.32–0.70) > T2C (0.33–0.44)
这个顺序在所有 11 个模型上无一例外。T2C 的天花板远低于另外两个任务,意味着"从自然语言到代码"的检索仍是当前嵌入技术最薄弱的环节,也是潜在收益最大的研究方向之一。
六、Reranker 训练与评测:严格的 train-on-v2、test-on-v3 协议
我们不只发布数据集,也提供了完整的 reranker 训练/评测管线,希望帮助社区在统一协议下推进 cross-encoder 这一方向的研究:
| 步骤 | 来源 | 输出 | 规模 |
|---|---|---|---|
| 训练集构建 | v202602_v2 qrels | v202602_v2_reranker_train/ | 3,803 条 |
| 测试集构建 | v202603_v2 qrels | v202603_v2_reranker_test/ | 3,692 条 |
每条训练样本带有 1 个正例 + 3 个硬负例 + 约 29 个易负例,覆盖 T2C / C2T / C2C 三个任务。我们刻意保留了硬负例与易负例的混合比例,让 reranker 既能学到细粒度区分,也能保持对全局语义结构的稳健性。
每条记录的 schema 简洁清晰:
{
"query_id": "q_t2c_canonical_retro_any_0001",
"task": "text2code",
"subtask": "t2c_canonical_retro_any",
"query": "...",
"pos": [{"id": "code_v202601_00009", "text": "..."}],
"hard_neg": [{"id": "...", "text": "..."}, ...],
"easy_neg": [{"id": "...", "text": "..."}, ...]
}
最关键的是:v202602 与 v202603 在 source_problem_id 层面完全不重叠。两个 release 覆盖互不相交的竞赛时间窗(Sep 2024–Jan 2025 vs Jan 2025–Apr 2025),从根本上杜绝了"在训练集上微调出测试集表现"的数据泄漏风险。
我们也观察到:用 v202602_v2 训练得到的 reranker,在 v202603_v2 测试集上的 T2C / C2C 提升均能稳定保持——这恰恰说明 CoREB 的训练信号是可迁移、可泛化的,而不是简单的题目记忆。
七、面向社区开放:一行代码即可使用
CoREB 的全部数据已在 HuggingFace 完全开源:
from datasets import load_dataset
# 加载代码语料库
corpus = load_dataset("hq-bench/coreb", "code_corpus", split="release_v2603")
# 加载 T2C 任务
queries = load_dataset("hq-bench/coreb", "text2code_queries", split="release_v2603")
qrels = load_dataset("hq-bench/coreb", "text2code_qrels", split="release_v2603")
# 也可以切换到 v202602 release(适合用于训练)
old_corpus = load_dataset("hq-bench/coreb", "code_corpus", split="release_v2602")
old_qrels = load_dataset("hq-bench/coreb", "text2code_qrels", split="release_v2602")
8 个 config(code/text 语料库 + 三任务的 queries/qrels)× 2 个 release 切片,覆盖从语料库、查询到 qrel 的全部内容。所有数据均为标准 parquet 格式,元数据字段(如 source_problem_id、language、model、solution_key)一应俱全,方便做任意维度的切片分析。
八、给研究者和工程师的话
如果你正在做这些事情,CoREB 都能立刻为你带来价值:
• 嵌入模型训练:CoREB 提供高质量的三级标注,可直接作为 hard negative 来源;正负例都经过测试用例真实验证,不需要担心"标签噪声"
• 代码搜索产品:T2C 的 search 子任务模拟了真实"无完美匹配"的检索场景,是评估候选模型上线前的最佳压力测试
• Reranker 研究:我们公开了完整的 train/test 协议、3,803 条训练样本与 3,692 条测试样本,开箱即用
• 多语言代码理解:C2C 任务覆盖 5 种语言 × 175 道题,是研究跨语言代码语义对齐的天然数据源
• 可解释性研究:C2T 上 LLM 生成的近似噪声文本,可作为研究"模型如何区分功能性描述与表面相似描述"的探针
• 模型选型:在你的业务上线前,先用 CoREB 对几个候选模型做端到端对比——别让 leaderboard 的平均分蒙蔽你
九、我们相信的事
评测从来不是终点,而是研究方法论的起点。一个好的基准应该做到三件事:
1. 暴露当前 SOTA 的真实短板——而不是让所有模型都看起来"差不多"
2. 划出清晰的研究方向——告诉社区接下来该把精力投向哪里
3. 抵御作弊与污染——让数字本身值得信任
CoREB 的目标正是这三件事的合一。我们不希望它成为又一个"看起来很热闹"的榜单,而是希望它成为代码语义检索领域接下来几年的事实标准之一——一个让大家在同一个客观、严格、不可作弊的舞台上比较模型的公共基础设施。
蚂蚁集团一直以来都在大规模代码检索、代码理解、代码生成的真实业务场景里持续投入。CoREB 是我们把这些场景中沉淀下来的方法论、痛点、与解决思路反哺社区的一个具体动作。我们也希望以此为起点,与社区一同推动代码语义理解的研究前沿——从"看起来很好"推到"真的好用"。
如果你在阅读中产生了任何想法、质疑、或建议,欢迎在 HuggingFace 仓库的 issue 区与我们交流。每一个真诚的反馈,都会让 CoREB 变得更好。
出品方:蚂蚁集团
数据集:hq-bench/coreb on HuggingFace
论文与最新榜单:持续更新中
欢迎在 issue 中提出问题、提出新任务、或加入更多模型的对比评测
-
通过高压创新重新定义电源管理2016-11-16 1389
-
求助:PIC引脚重新定义2013-11-18 3327
-
28335头文件中变量提示重新定义,怎么解决?2014-12-24 4344
-
请教大神怎样去重新定义 _write函数呢2021-12-01 1799
-
请问AD21版本如何重新定义板子形状?2022-02-07 3409
-
蚂蚁集团基础设施委员会主席何征宇:开源是核心技术战略2022-08-17 2091
-
Altium利用云功能重新定义pcb设计2020-10-27 3517
-
重新定义ADC在无线领域的角色2021-05-26 791
-
AD学习问题记录(三):AD21版本如何重新定义板子形状2021-12-04 4143
-
通过高压创新 重新定义电源管理2022-11-02 764
-
重新定义零售体验——RF技术的四大机遇2022-12-26 1878
-
边缘计算如何重新定义 IIoT 应用程序2023-01-03 1803
-
AI2.0时代,工业视觉正被重新定义2023-04-12 2115
-
重新定义连接-物联网卡流量池解决方案2023-09-22 1469
-
物联网如何重新定义智慧城市的未来生活 智慧照明2024-12-03 1294
全部0条评论

快来发表一下你的评论吧 !
