

语音合成技术简介,深度学习技术对合成技术发展的影响
电子说
描述
CSDN 出品的《2018-2019 中国人工智能产业路线图》V2.0 版即将重磅面世!
V1.0 版发布以来,我们有幸得到了诸多读者朋友及行业专家的鼎力支持,在此表示由衷感谢。此次 V2.0 版路线图将进行新一轮大升级,内容包括 3 大 AI 前沿产业趋势分析,10 位 AI 特邀专家的深度技术分析,15 家一线互联网企业的 AI 实力大巡展,以及 20 个 AI 优秀应用案例,力求为读者呈现更全面的中国人工智能产业发展概况和趋势判断。
V2.0 版将于 11 月 8 日举办的 2018 AI 开发者大会上正式发布,在此之前,我们将不间断公布精要内容,以飨读者。此为 V2.0 版中深度技术分析系列稿件第 2 篇,作者为 CSDN 特邀 AI 专家标贝科技联合创始人&CTO 李秀林。
作者简介:李秀林,中国科学院博士,15 年语音相关技术研发和学术研究,申请专利三十余项,在国内外语音界有很高的知名度;曾带领团队获得百度百万美元大奖。2006 年—2013 年,松下研发中心高级研发经理;2013 年—2016 年,百度语音合成技术负责人;2016 年—2018 年,滴滴研究院语音团队负责人&首席算法工程师;2018 年3 月加盟标贝科技,作为联合创始人兼CTO。
▌一、语音合成技术简介
语音,在人类的发展过程中,起到了巨大的作用。语音是语言的外部形式,是最直接地记录人的思维活动的符号体系,也是人类赖以生存发展和从事各种社会活动最基本、最重要的交流方式之一。而让机器开口说话,则是人类千百年来的梦想。语音合成(Text To Speech),是人类不断探索、实现这一梦想的科学实践,也是受到这一梦想不断推动、不断提升的技术领域。
在漫长的探索过程中,真正产生实用意义的合成系统,产生于 20 世纪 70 年代。受益于计算机技术和信号处理技术的发展,第一代参数合成系统--共振峰合成系统诞生了。它利用不同发音的共振峰信息,可以实现可懂的语音合成效果,但整体音质方面,还难以满足商用的要求。
进入 90 年代,存储技术得到了长足发展,从而诞生了拼接合成系统。拼接合成系统,利用 PSOLA 算法,将存储的原始发音片段进行调整后拼接起来,从而实现了相较于共振峰参数合成效果更好的音质。
之后,语音合成技术不断向前发展,参数合成、拼接合成两条主要的技术路线都取得了长足进展,相互竞争、相互促进,使得合成语音的质量大幅提升,语音合成技术在众多场景中得以应用。整体上看,主要包括如下几个方面:
从规则驱动转向数据驱动:在早期的系统中,大多需要大量的专家知识,对发音或者声学参数进行调整,不但费时费力,而且难以满足对不同上下文的覆盖,也在一定程度上影响技术的实施。随着技术的发展,越来越多的数据得以应用到系统中,以语音合成音库为例,从最初的几百句话,发展到后来的几千、几万句规模,使得发音样本数量大大增加,基于统计模型的技术得以广泛应用。从最初的树模型、隐马尔可夫模型、高斯混合模型,到近几年的神经网络模型,大大提升了语音合成系统对语音的描述能力。
不断提升的可懂且舒适的合成效果:语音合成系统的合成效果评价,一般是通过主观评测实验,利用多个参试人员对多个语音样本进行打分。如果语音样本来自不同的系统,则称为对比评测。为了提升语音的音质,参数合成系统中先后采用过 LPC 合成器、STRAIGHT 合成器、以 wavenet 为代表的神经网络声码器等;拼接合成系统中则采用不断扩大音库规模、改善上下文覆盖的策略,都取得了明显的效果。在理想情况下,用户希望语音合成的语音,能够以假乱真,达到真人发音水平。随着技术的不断发展,这一目标已经越来越近。在一种极端情况下,一组样本来自合成系统,一组样本来自真人发音,那么所做的对比评测,即可视为语音合成系统的图灵测试。如果用户无法准确分辨哪些语音样本是机器生成的,哪些是人类产生的,那么就可以认为这一合成系统通过了图灵测试。
文本处理能力不断增强:人类在朗读文本时,实际上是有一个理解的过程。要想让机器也能较好地朗读,这个理解过程必不可少。在语音合成系统中,一般会包括一个文本处理的前端,对输入文本进行数字、符号的处理,分词断句,以及多音字处理等一系列环节。通过利用海量的文本数据和统计模型技术,合成系统中文本处理的水平已经可以满足大多数场景下的商业应用要求。更进一步地,自然语言理解技术,还可以用于预测句子的焦点、情绪、语气语调等,但由于这部分受上下文的影响很大,而这类数据又相对较少,所以目前这部分情感相关的技术还不够成熟。
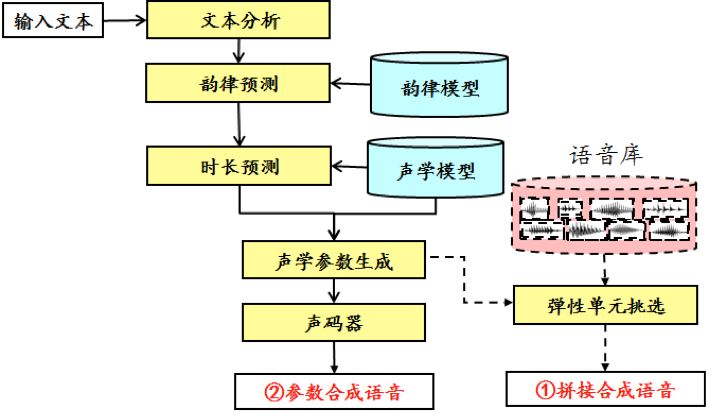
图 1. 语音合成系统框图
以上,是语音合成技术的发展概况。接下来,我们来探讨一下最近几年深度学习技术对合成技术发展的影响。
▌二、深度学习与语音合成
深度学习技术,对语音合成的影响,主要分为两个阶段:
第一阶段:锦上添花。从 2012 年开始,深度学习技术在语音领域逐渐开始受到关注并得以应用。这一阶段,深度学习技术的主要作用,是替换原有的统计模型,提升模型的刻画能力。比如用 DNN 替代时长模型,用 RNN 替代声学参数模型等。语音的生成部分,仍然是利用拼接合成或者声码器合成的方式,与此前的系统没有本质差异。对比两种系统发现,在仔细对比的情况下,替代后的系统的效果略好于原系统,但整体感觉差异不大,未能产生质的飞跃。
第二阶段:另辟蹊径。这一阶段的很多研究工作,都具有开创性,是对语音合成的重大创新。2016 年,一篇具有标志性的文章发表,提出了 WaveNet 方案。2017 年初,另一篇标志性的文章发表,提出了端到端的 Tacotron 方案。2018 年初,Tacotron2 将两者进行了融合,形成了目前语音合成领域的标杆性系统。在此过程中,也有 DeepVoice,SampleRNN, Char2Wav 等很多有价值的研究文献陆续发表,大大促进了语音合成技术的发展,吸引了越来越多的研究者参与其中。
图 2. WaveNet 中的带洞卷积结构
WaveNet 是受到 PixelRNN 的启发,将自回归模型应用于时域波形生成的成功尝试。利用 WaveNet 生成的语音,在音质上大大超越了之前的参数合成效果,甚至合成的某些句子,能够到达以假乱真的水平,引起了巨大的轰动。其中,所采用的带洞卷积(dilated convolution)大大提升了感受野,以满足对高采样率的音频时域信号建模的要求。WaveNet 的优点非常明显,但由于其利用前 N-1 个样本预测第 N 个样本,所以效率非常低,这也是 WaveNet 的一个明显缺点。后来提出的 Parallel WaveNet 和 ClariNet,都是为了解决这个问题,思路是利用神经网络提炼技术,用预先训练好的 WaveNet 模型(teacher)来训练可并行计算的 IAF 模型(student),从而实现实时合成,同时保持近乎自然语音的高音质。
Tacotron 是端到端语音合成系统的代表,与以往的合成系统不同,端到端合成系统,可以直接利用录音文本和对应的语音数据对,进行模型训练,而无需过多的专家知识和专业处理能力,大大降低了进入语音合成领域的门槛,为语音合成的快速发展提供了新的催化剂。
图 3. Tacotron 的端到端网络结构
Tacotron 把文本符号作为输入,把幅度谱作为输出,然后通过 Griffin-Lim 进行信号重建,输出高质量的语音。Tacotron 的核心结构是带有注意力机制的 encoder-decoder 模型,是一种典型的 seq2seq 结构。这种结构,不再需要对语音和文本的局部对应关系进行单独处理,极大地降低了对训练数据的处理难度。由于 Tacotron 模型比较复杂,可以充分利用模型的参数和注意力机制,对序列进行更精细地刻画,以提升合成语音的表现力。相较于 WaveNet 模型的逐采样点建模,Tacotron 模型是逐帧建模,合成效率得以大幅提升,有一定的产品化潜力,但合成音质比 WaveNet 有所降低。
Tacotron2是基于 Tacotron 和 WaveNet 进行融合的自然结果,既充分利用了端到端的合成框架,又利用了高音质的语音生成算法。在这一框架中,采用与 Tacotron 类似的结构,用于生成 Mel 谱,作为 WaveNet 的输入,而 WaveNet 则退化成神经网络声码器,两者共同组成了一个端到端的高音质系统。
图 4. Tacotron 2 的网络结构
▌三、语音合成的应用
语音合成技术,已经成功应用在很多领域,包括语音导航、信息播报等。对于语音合成的应用前景,标贝科技有着自己的看法。因为标贝科技既是语音数据服务商,同时也是语音合成整体解决方案提供商,所以对于语音合成的应用前景,也做过很多思考。目前语音合成的声音,从合成效果上,已经可以满足大多数用户的需求,但是从音色选择上,还不够丰富;从发音方式上,还是偏单调。针对这种情况,标贝科技推出了“声音超市」,为合作伙伴提供了一个可供选择的,所听即所得的声音平台。我们认为,语音合成会以更贴近场景需求的合成效果,在如下的三大场景中得以广泛应用:语音交互、阅读&教育、泛娱乐。
语音交互
近年来,随着人工智能概念的推广,语音交互成为了一个热点,智能助手、智能客服等应用层出不穷。语音交互中,主要有三个关键技术,语音识别、语音合成和语义理解,语音合成在其中的作用显而易见。受限于语义理解的技术发展水平,目前的应用主要是聚焦于不同的垂直领域,用于解决某些特定领域的问题,还存在一定的局限性。
阅读&教育
阅读是一个长期且广泛的需求,我们每天都需要通过阅读获取大量的信息,既有碎片化的信息获取,也有深度阅读;既包括新闻、朋友圈、博文,也包括小说、名著;有的是为了与社会同步,有的是消磨时光,有的是为了提升自我修养。在这种多维度的信息需求当中,语音合成技术提供了一种「简单」的方式,一种可以「并行」输入的方式,同时也是一种「廉价」的方式。相较于传统的阅读,自有其优势。在开车时、散步时、锻炼时,都可以轻松获取信息。
在教育方面,尤其是语言教育方面,模仿与交互是必不可少的锻炼方式。目前的教育方式中,想学到标准的发音,是需要大量的成本的,比如各种课外班,甚至一对一教育。随着语音合成技术的不断进步,以假乱真的合成效果,一方面可以大大增加有声教育素材,另一方面,甚至可以部分取代真人对话的教育内容。
泛娱乐
泛娱乐是之前与语音合成交叉较少的场景,但我们认为这恰恰是一个巨大的有待开发的市场。我们已经拥有丰富的声音 IP 资源,并且可以通过声音超市进行展示,供大家选购自己喜欢的声音。这些都是为了将语音合成技术广泛应用到泛娱乐领域所做的准备。以配音领域为例,利用语音合成技术,可以大大降低配音的成本和周期;以目前火爆的短视频为例,利用语音合成技术可以非常容易地为自己的视频配上有趣的声音来展现内容;以虚拟主持人为例,利用语音合成技术,可以提升信息的时效性,同时大大缓解主持人的工作压力,降低其工作强度。
总之,随着语音合成技术的快速发展,所生成的语音会越来越自然生动,也会越来越有情感表现力。我们坚信,技术的进步,会不断冲破原有的障碍,满足越来越多的用户需求,使得更好的应用不断涌现,实现用声音改变生活的美好愿景!
-
CAN总线的语音合成模块研制技术2013-09-14 0
-
语音合成芯片,求讨论~2013-12-03 0
-
基于语音合成技术的车载终端系统该怎样去设计?2021-05-12 0
-
苹果Siri深度学习语音合成技术揭秘2018-05-26 3361
-
语音合成技术是如何应用在我们生活中的2023-04-24 2534
-
TTS语音合成技术及其应用2023-06-24 1204
-
语音合成数据的重要性:打造自然流畅的语音合成体验2023-06-24 587
-
TTS语音合成技术的挑战和未来发展2023-06-24 1140
-
语音合成技术与语音合成数据,赋予声音新的可能性2023-06-28 578
-
语音合成技术的简介与未来发展2023-09-15 2081
-
语音合成技术的应用与挑战2023-09-16 1317
-
基于深度学习的语音合成技术的进展与未来趋势2023-09-16 1069
-
语音合成技术在智能驾驶中的应用与展望2024-02-01 516
-
语音合成技术在智能驾驶中的创新与应用2024-02-01 635
全部0条评论

快来发表一下你的评论吧 !
