

Keras实现:用部分卷积补全图像不规则缺损
电子说
描述
编者按:图像补全是一个热门研究领域,今年4月,NVIDIA发表了一篇精彩的论文: Image Inpainting for Irregular Holes Using Partial Convolutions。文章指出,以往图像补全技术都是用残缺位置周边的有效像素统计信息填充目标区域,这种做法虽然结果平滑,但存在效果不逼真、有伪像,且后期处理代价昂贵的缺点。因此他们用大量不规则掩膜图像训练了一个深度神经网络,它能为图像生成合理掩膜,再结合仅以有效像素为条件的部分卷积(Partial Convolutions),最终模型的图像补全效果远超前人的成果。
而近日,有网友复现了这篇论文,并在GitHub上公开了他的Keras实现,感兴趣的读者前去一看:github.com/MathiasGruber/PConv-Keras
NVIDIA论文
环境
Python 3.6
Keras 2.2.0
Tensorflow 1.8
如何使用这个repo
repo中包含的PConv2D keras实现可以在libs/pconv_layer.py和libs/pconv_model.py中找到。除此之外,作者还提供了四个jupyter NoteBook,详细介绍了实现网络时经历的几个步骤,即:
step 1:创建随机不规则掩膜
step 2:实现和测试PConv2D层
step 3:实现和测试采用UNet架构的PConv2D层
step 4:在ImageNet上训练和测试最终模型
实现细节
在设计图像补全算法时,研究人员首先要考虑两个因素:从哪里找到可利用的信息;怎么评判整体补全效果。无论是天然破损的图像,还是被人为打上马赛克的图像,这之中都涉及图像语义上的预测。
这篇论文发表之前,学界在图像补全上的最先进方法之一是利用剩余图像的像素统计信息来填充残缺部分,这利用了同一幅图像素间的连接性,但缺点是只反映了统计上的联系,无法真正实现语义上的估计。后来也有人引入深度学习的方法,训练了一个深度神经网络,以端到端的方式学习语义先验和有意义的隐藏表示,但它仍局限于初始值,而且使用的是固定的替换值,效果依然不佳。
NVIDIA在论文中提出了一种新技巧:添加部分卷积层(Partial Convolutional Layer),并在这一层之后加上一个掩膜更新步骤。部分卷积层包含生成掩膜和重新归一化,它类似图像语义分割任务中的segmentation-aware convolutional(分段感知卷积),能在不改变输入掩膜的情况下分割图像信息。
简而言之,给定给定一个二元掩膜,部分卷积层的卷积结果只取决于每一层的非残缺区域。相比segmentation-aware convolutional,NVIDIA的创新之处是自动掩膜更新步骤,它可以消除部分卷积能够在非掩膜值上操作的任何掩膜。
具体设计过程可以阅读论文查看,下面我们只总结一些细节。
生成掩膜
为了训练能生成不规则掩模的深度神经网络,论文研究人员截取视频中的两个连续帧,用遮挡/解除遮挡创建了大量不规则掩膜,虽然他们在论文中称将公开这个数据集,但现在我们还找不到相关资源。
在这个Keras实现中,作者简单创建了一个遮挡生成函数,用OpenCV绘制一些随机的不规则形状,以此作为掩膜数据,效果目前看来还不错。
部分卷积层
这个实现中最关键的部分就是论文的重点“部分卷积层”。基本上,给定卷积filter W和相应的偏差b,部分卷积的形式是:
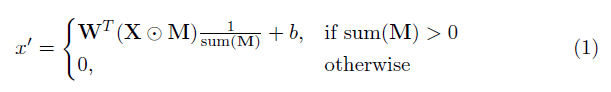
其中⊙表示点乘,即每个矩阵元素对应相乘,M是由0和1构成的二进制掩码。在每次完成部分卷积操作后,掩膜要进行一轮更新。这意味着如果卷积能够在至少一个有效输入上调节其输出,则在该位置移除掩码:
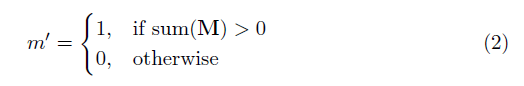
这样做的结果是,在网络够深的情况下,最终掩码将全部为0(消失)。
UNet架构
下图是论文中提供的PConv整体架构,它类似UNet,只不过其中所有正常的卷积层都被部分卷积层代替,使图像+掩膜无论何时都能一起通过网络
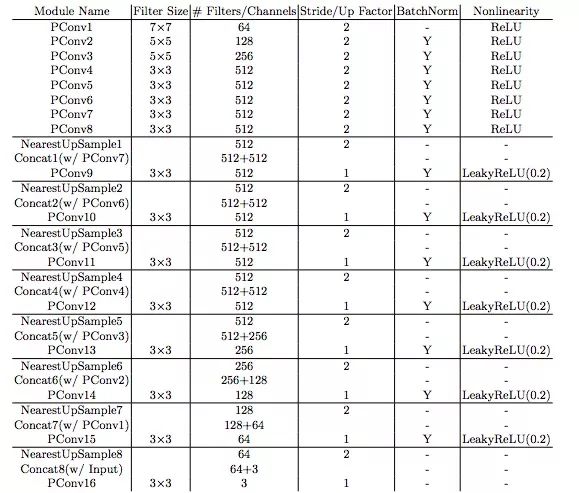
PConv整体架构
PConv彩色图解
损失函数
论文涉及的损失非常多样,简而言之,它包括:
掩膜区(Lhole)和非掩膜区(Lvalid)的每个像素损失
基于ImageNet预训练的VGG-16(pool1, pool2 and pool3 layers)的感知损失(Lperceptual)
VGG-16在预测图像(Lstyleout)和计算图像(Lstylecomp)上的风格损失(以非残缺区像素为真实值)
残缺区域每个像素扩张的总变差损失(Ltv),也就是1像素扩张区域的平滑惩罚
以上损失的权重如下:
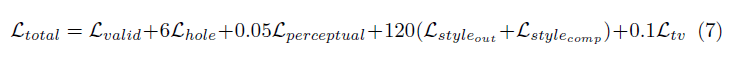
论文补全效果
下图是论文中呈现的图像补全效果,其中第一列是输入图像,第二列是GntIpt算法的输出,第三列是NVIDIA论文的结果,第四列是真实完整图像。可以发现,无论图像缺失区域有多不规则,PConv的补全效果在颜色、纹理、形状上都更逼真,也更平滑流畅。
小结
最后一点,也是最重要的一点,如果是在单个1080Ti上训练模型,batch size为4,模型训练总用时大约在10天左右,这是个符合论文所述的数据。所以如果有读者想上手实践,记得提前做好硬件和时间上的准备。
-
教你设计不规则形状的PCB2016-02-16 6508
-
创建不规则窗体和控件2009-03-04 3650
-
用示波器去测量不规则波形2012-11-27 3879
-
labview前面板部分透明,不规则界面2015-08-12 22586
-
利用Keras实现四种卷积神经网络(CNN)可视化2019-07-12 3936
-
不规则pcb怎么拼板2019-10-23 5281
-
不规则PCB封装编辑2013-09-05 938
-
不规则变换循环LED闪烁电路2016-11-02 1163
-
一种基于距离变换的不规则区域匹配算法2017-11-28 671
-
一种新的对不规则珠宝图像的自动检测方法2017-12-11 964
-
线积分卷积技术的详细资料说明2020-07-03 2121
-
基于密集卷积生成对抗网络的图像修复方法2021-05-13 980
-
基于生成式对抗网络的图像补全方法2021-05-19 1051
-
OpenCV初学者如何提取这些不规则的ROI区域2023-10-31 1590
-
基于差分卷积神经网络的低照度车牌图像增强网络2024-11-11 1289
全部0条评论

快来发表一下你的评论吧 !
