

如何实现自动识别并提取图片中的文本内容
电子说
描述
【导读】提到 Dropbox,大家可能都知道这是一个文件同步、备份、共享的云存储软件。其实 Dropbox 可以实现的功能远不止这些。今天就为大家介绍 Dropbox 一个非常强大又实用的功能——自动识别并提取图片中的文本内容,包含 PDF 文档中的图片。比如,当用户搜索其中某个文件中出现的一段文本时(英文文本),在搜索结果中就会显示出这个文件。下面我们就为大家介绍这样的功能是如何实现的。
前言
自动识别图片中的文字功能有很多好处,最显著的提升是能够让 Dropbox 用户搜索从前无法搜索的内容。Dropbox 用户上传的图片和 PDF 文档总数已经超过了两百亿,这其中有超过百分之十的文件真正的内容都是文本,但格式是图片,比如说手机拍摄的小票或者白板的照片。这些就是我们要进行文字识别的对象了。PDF 文件中有 25% 左右是文档的扫描件,这些也属于我们想实现自动文字识别的对象。
对用户来说,文档和文档的扫描件好像差不太多,但对计算机来说区别可就大了。文档可以进行索引并搜索,而图片说白了只是一些像素点罢了。像 TXT、DOCX 和 html 格式的文件一般来说都可以进行索引,而像 JPEG、PNG 和 GIF 这些图片格式一般来说是不能直接进行索引的。对 PDF 文件来说要分情况,比如 PDF 里的图片也是不能够索引的。图像文本自动识别功能可以智能地区分所有的文档和文档中包含哪类数据。
分析
讲如何实现之前我们先要对这个问题进行一些初步的分析,具体来说就是回答下面三个问题:
什么文件需要进行文字识别
如何判断文件是否包含有文字
对于 PDF 文件是否所有页都需要全部识别?识别多少是有用的?
需要进行识别的主要是当前没有可用索引文本内容的文件,包括图片格式和还有一部分 PDF 文档,但其实这部分文件只占所有文件的很小一部分,所以解决这个问题很重要的一个步骤就是建立一个机器学习模型来判断文件是否包含可识别的文字。比如说某文档的照片我们就需要进行识别,但如果只是自拍拍到了衣服上的字,这时候识别恐怕就没有什么意义了。这里我们使用了一个卷积神经网络来进行二元分类。
我们经过统计发现 JPEG 这一最常见的图片格式中有大约 9% 可能包含文字。PDF 文件的每一页则可能属于下面三种情形之一:
非图片,只有可索引的文字
含有文字的图片
完全没有文字内容的图片
这三类中我们感兴趣的其实只有第二类。我们发现第二类情况在三种情况之中约占 28%。PDF文件的数量虽然只有 JPEG 图片数量的一半,但每个 PDF 文件平均有 8.8 页。所以综合看来要处理的 PDF 文件个数超过 JPEG 图片量十多倍。不过用下面这个很简单的办法就能大大降低需要处理的 PDF 文件数目。
文件总页数
有些 PDF 文件页数很多,可能好几千页的都有。如果我们没头没脑的通通识别会很占时间和资源。我们统计了一下 PDF 文件的页数,发现超过一半的文件都只有一页,超过十页的文件大约只占 PDF 文件总数的 10%。所以我们设定了一个标准,不管文件有多长只识别前面十页。
这样算下来 90% 的 PDF 文档我们都能实现完全索引。较长的文档我们虽然没有完全实现识别和索引,但能搜十页也比完全搜索不到好的多了。
自动文字识别系统
▌图片的渲染
对于 PDF 文件中图片的渲染由两种可行的方式:一个是将页面中的图片一张张提取出来,另一个是将一页文件当一整张图片来处理。这两种方法我们都测试了,不过 Dropbox 的文件预览功能已经有了完善的 PDF 渲染能力,所以最终我们选择了第二个方法。这样处理的话,像 PowerPoint 或者 Post Script 这样的文件格式,只要能支持预览,我们就能进行识别,而且词与词、段与段之间的顺序不会被打乱。
我们的渲染功能是基于谷歌的 PDFium 开发的。这其实也是 Chrome 浏览器所使用的 PDF 渲染引擎。渲染的过程中我们使用了并行处理来降低延迟。
▌文件图像分类
模型方面我们先用了 GoogLeNet 来进行特征提取,然后用了一个线性分类器来实现有无文字的分类。训练所用的图片有些是网上公开的,有些是用户和 Dropbox 员工提供的,一共有几千张。
我们发现一开始训练模型的时候准确率略低,模型把天际线、光溜溜的墙和开放水域这类图片都判断为有文字了。其实我们人眼都不太容易看出这些图片有什么共同点,不过模型认为只要是背景比较均一,有横线的就是有文字。最后是通过人工标记和给训练集中加入这类图片才克服了这个问题,从而把准确率提上来了。
▌识别图片的四个角
用户上传的图片因为拍照角度的原因,一般来说都不是我们想要的矩形和直角,所以必须进行矫正。要矫正的话,就要取得图片中文件四个角的坐标,这个功能我们也是用卷积神经网络来实现的。具体地说,就是把 Densenet-121 的输出换成了四个角的坐标。
训练这个模型用了几百张图。标记数据集的过程,需要一张一张地把文件的四个边找出来。这项工作我们是在亚马逊上众包完成的。有的图某个角可能压根没拍着,那这个角的坐标就跑到图片外面去了,这时候就只能靠人工脑补了。
为了加快速度,训练模型的时候用的图片分辨率比实际的图片分辨率低,所以输出的坐标也是低分辨率图片上的坐标。为了提高精度,我们在四个角附近,用高分辨率的图片把模型重跑了一遍。这样既提升了训练的速度,又能得到高精度图片上四个角的坐标。
▌单词提取
这一部分以矫正过的图片作为输入,输出的则是单词的内容和定界框。单词就按照识别出的顺序一一加入索引。如果文件超过一页,则继续建立索引一直达到 10 页的限制就停。
上面讲的的这几个部分组合起来看是这样的:
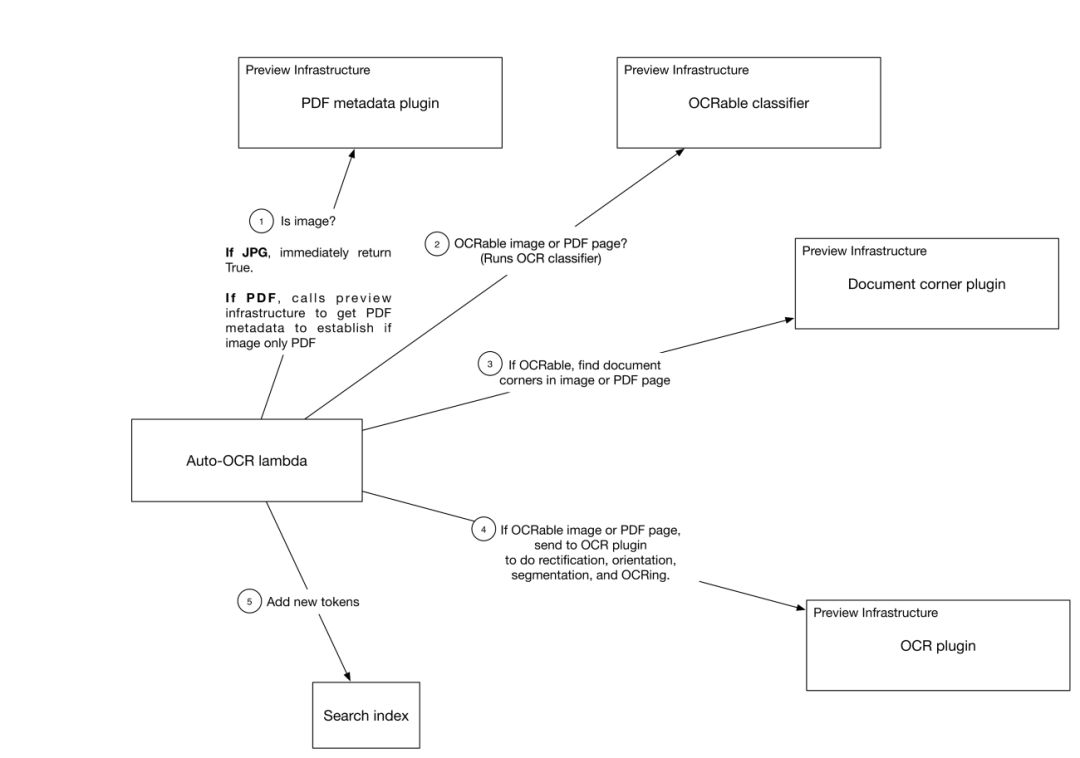
图中标出的步骤我们来分别介绍一下:
通过检查文件格式判断是否含有图片;判断用户权限
判断图片或 PDF 文件是否含有可识别的文字
判断图片的四个角以便进行矫正
提取单词
加入索引
图中有一个我们之前没有介绍过的 Auto-OCR lambda 模块,这其实是一个 Cape 微服务。Cape 是 Dropbox 在 16 年底推出的一个异步事件流处理框架,Dropbox 很多功能都用到了Cape。有了这个 Cape 微服务,当用户对文件进行增改的时候文字识别功能就能自动触发了,也就是图中列出来的步骤 1 到 5。
得益于 Dropbox 预览功能所提供的基础设施,这一系列从读取文件,判断类型,矫正到最后识别操作的效率很高,而且这套系统对文件的操作(比如渲染)是进行了缓存的,所以当用户上传同一个文件不会造成系统资源的二次开销。增加支持的文件类型和操作也是非常容易,只要为新的文件类型开发一个预览插件就行了。现在对 PDF 文件的识别也是通过插件来实现的。
为了提供系统的稳定性,我们在插件的调用过程中使用了指数补偿算法并加入了随机值。拿第一步调用的插件来说,重试之后失败率降低了 88%。
性能优化
刚开始测试的时候我们发现所使用的机器学习模型所占的资源和带来的延迟完全在我们能接受的范围之外,所以必须进行优化。我们决定先从配置参数着手,因为我们发现如果模型的性能遭遇瓶颈,很多时候简单地改变配置参数就能收到很好的效果。下面我们就来举几个例子说明一下。
我们的第一个改动是关闭了 TensorFlow 的多核支持。Dropbox 系统并行是在 CPU 层面实现的。每个核只运行一个单线程的程序,这样可以避免对数据的损坏也能降低恶意软件入侵的风险。然而,TensorFlow 默认是开启多核支持的。这样相当于每一个核又在跑多线程了,由此引起的上下文切换使得系统吞吐量损失了约 2/3。
关闭多核支持后性能还是不够好。所以我们又换成了支持 AVX2 指令集的 TensorFlow 并将模型和环境用 TensorFlow XLA 提前编译成一个 C++ 库。此外我们还调整了一些隐藏层的节点数量。
图像四个角坐标和文本方向的判断我们所采用的模型架构是 Densenet-121。相比之前用过的 Inception-Resnet-v2 来说速度大概快了一倍,坐标识别的准确率只是稍逊,而且是可以忽略不计的程度。
其实我们所作的这些工作都是为了加深对文件结构和内容的理解,让用户使用 Dropbox 时可以有更好的体验。
-
AI提取图片里包含的文字信息-解决文字无法复制的痛点2023-07-07 3549
-
如何实现串口的自动识别2012-03-23 5093
-
求助帖 labview自动识别2013-04-19 2566
-
请问USB自动识别芯片RH7901是怎样自动识别充电设备的?2018-05-22 2844
-
NLPIR在文本信息提取方面的优势介绍2019-09-12 1317
-
车辆自动识别称重系统的工作原理2021-03-01 2798
-
如何利用SPD实现内存自动识别和配置?2021-04-27 2027
-
基于AI通用文字识别能力,检测和识别文档翻拍、街景翻拍等图片中的文字2021-08-27 1764
-
如何实现系统自动识别并切断电池供电的呢?2022-01-26 992
-
基于SAW技术的车辆自动识别系统的实现2010-07-16 668
-
基于机器学习的日志自动识别2017-11-23 1003
-
RFID技术如何实现车证自动识别2020-03-01 3648
-
使用MATLAB编程软件和机器视觉实现汽车车牌自动识别2020-08-28 1499
-
图片文字识别:揭开数字世界的神秘面纱2023-05-11 1558
-
水位自动识别摄像机2024-07-31 1117
全部0条评论

快来发表一下你的评论吧 !
