

自然语言处理的ELMO使用
电子说
描述
1、概述
word embedding 是现在自然语言处理中最常用的 word representation 的方法,常用的word embedding 是word2vec的方法,然而word2vec本质上是一个静态模型,也就是说利用word2vec训练完每个词之后,词的表示就固定了,之后使用的时候,无论新句子上下文的信息是什么,这个词的word embedding 都不会跟随上下文的场景发生变化,这种情况对于多义词是非常不友好的。例如英文中的 Bank这个单词,既有河岸的意思,又有银行的意思,但是在利用word2vec进行word embedding 预训练的时候会获得一个混合多种语义的固定向量表示。即使在根据上下文的信息能明显知道是“银行”的情况下,它对应的word embedding的内容也不会发生改变。
ELMO的提出就是为了解决这种语境问题,动态的去更新词的word embedding。ELMO的本质思想是:事先用语言模型在一个大的语料库上学习好词的word embedding,但此时的多义词仍然无法区分,不过没关系,我们接着用我们的训练数据(去除标签)来fine-tuning 预训练好的ELMO 模型。作者将这种称为domain transfer。这样利用我们训练数据的上下文信息就可以获得词在当前语境下的word embedding。作者给出了ELMO 和Glove的对比
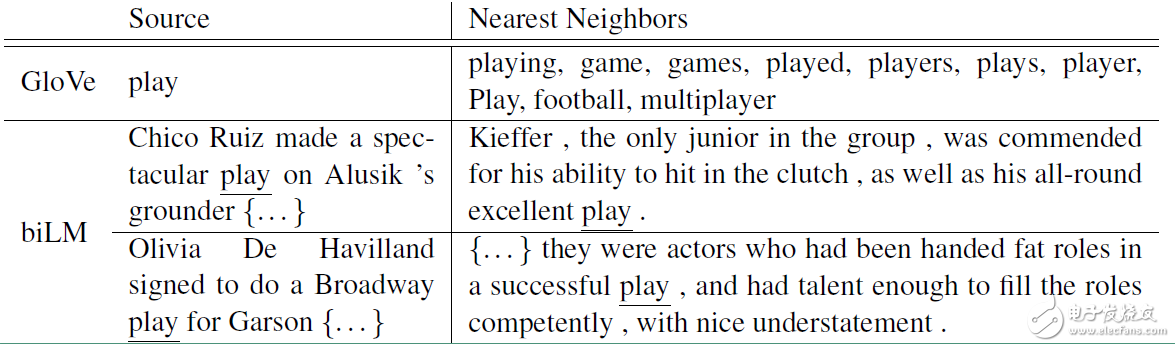
对于Glove训练出来的word embedding来说,多义词play,根据他的embedding 找出的最接近的其他单词大多数几种在体育领域,这主要是因为训练数据中包含play的句子大多数来源于体育领域,之后在其他语境下,play的embedding依然是和体育相关的。而使用ELMO,根据上下文动态调整后的embedding不仅能够找出对应的“表演”相同的句子,还能保证找出的句子中的play对应的词性也是相同的。接下来看看ELMO是怎么实现这样的结果的。
2、模型结构
ELMO 基于语言模型的,确切的来说是一个 Bidirectional language models,也是一个 Bidirectional LSTM结构。我们要做的是给定一个含有N个tokens的序列
t1 , t2 , ... , tN
其前向表示为:
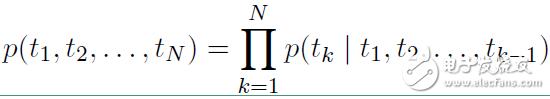
反向表示为:
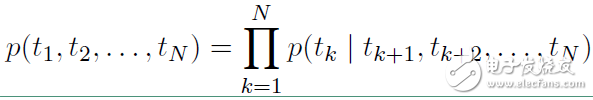
从上面的联合概率来看是一个典型的语言模型,前向利用上文来预测下文,后向利用下文来预测上文。假设输入的token是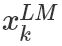 ,在每一个位置 k ,每一层LSTM 上都输出相应的context-dependent的表征
,在每一个位置 k ,每一层LSTM 上都输出相应的context-dependent的表征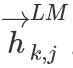 。
。
这里 j = 1 , 2 , ... , L ,L 表示LSTM的层数。顶层的LSTM 输出,通过softmax层来预测下一个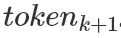 。
。
对数似然函数表示如下:
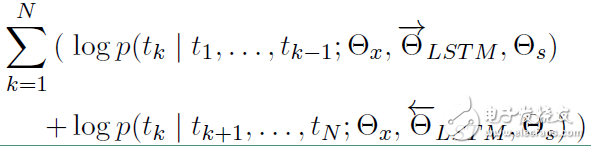
模型的结构图如下:
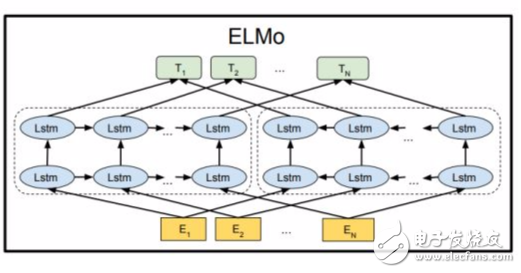
ELMO 模型不同于之前的其他模型只用最后一层的输出值来作为word embedding的值,而是用所有层的输出值的线性组合来表示word embedding的值。
对于每个token,一个L层的 biLM要计算出 2L + 1 个表征:
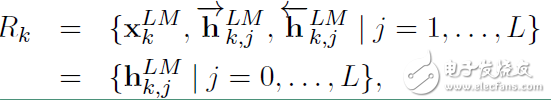
在上面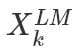 等于
等于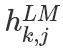 ,表示的是token层的值。
,表示的是token层的值。
在下游任务中会把 Rk 压缩成一个向量:
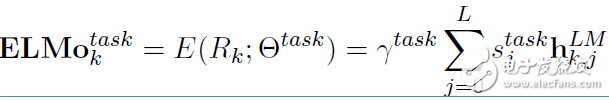
其中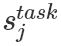 是softmax标准化权重,γtask 是缩放系数,允许任务模型去缩放整个ELMO向量。
是softmax标准化权重,γtask 是缩放系数,允许任务模型去缩放整个ELMO向量。
ELMO的使用主要有三步:
1)在大的语料库上预训练 biLM 模型。模型由两层bi-LSTM 组成,模型之间用residual connection 连接起来。而且作者认为低层的bi-LSTM层能提取语料中的句法信息,高层的bi-LSTM能提取语料中的语义信息。
2)在我们的训练语料(去除标签),fine-tuning 预训练好的biLM 模型。这一步可以看作是biLM的domain transfer。
3)利用ELMO 产生的word embedding来作为任务的输入,有时也可以即在输入时加入,也在输出时加入。
ELMO 在六项任务上取得了the state of the art ,包括问答,情感分析等任务。总的来说,ELMO提供了词级别的动态表示,能有效的捕捉语境信息,解决多义词的问题。
-
自然语言处理与机器学习的关系 自然语言处理的基本概念及步骤2024-12-05 2891
-
自然语言处理包括哪些内容2024-07-03 2949
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 2795
-
什么是自然语言处理2021-09-08 2721
-
自然语言处理——总结、习题2020-06-19 2479
-
求自然语言处理笔记2020-06-04 2840
-
自然语言处理的词性标注方法2020-04-21 2250
-
自然语言处理的语言模型2020-04-16 2763
-
自然语言处理的分词方法2020-03-19 1473
-
【推荐体验】腾讯云自然语言处理2019-10-09 2907
-
python自然语言2018-05-02 6392
-
自然语言处理常用模型解析2017-12-28 6535
全部0条评论

快来发表一下你的评论吧 !
