用Python制作编程语言的关系网络图
电子说
描述
本文会介绍简单的网络知识,即便你没有相关背景知识也能轻松学会。今天要教大家制作一张编程语言的关系网络图。
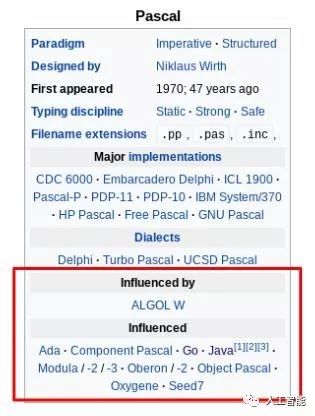
我们可以在这里看到从过去到现在的250多种编程语言之间的“设计影响”的关系,下面是该演示的截图:
接下来,就让我们一起来学做这个关系网络图吧!
在当今的超连接世界,网络在现代生活中无处不在。举个栗子,文摘菌的周末这样开启——通过北京的交通网络进城,然后去最喜欢的咖啡店的一家分店,并将笔记本连上他们的Wi-Fi。接下来,登录各种常用的社交网站。
众所周知,在过去几十年来最有影响力的公司中,有一部分是因为网络的力量而获得成功。
Facebook、Twitter、Instagram、LinkedIn以及一些其他的社交媒体平台都依赖社交网络的小世界特性。这使他们能有效地将用户彼此(以及和广告商)之间连接起来。
谷歌目前的成功主要归因于他们早期在搜索引擎市场上的主导地位——部分原因是他们有能力通过他们的Page Rank网络算法来返回相关的结果。
亚马逊的高效配送网络使他们能够在一些主要城市提供当天发货。
网络算法在人工智能和机器学习等领域也是非常重要的。神经网络领域的研究非常热门。计算机视觉中许多必不可少的特征检测算法,在很大程度上也是依赖于使用网络来对图像的不同部分进行建模。
网络模型也可以解释大量的科学现象,包括有量子力学、生化途径以及生态和社会经济系统等。
那么,鉴于它们不可否认的重要性,我们应该如何更好地理解网络及其属性呢?
网络的数学研究被称为“图论”,是数学中较易理解的分支之一。 本文会介绍简单的网络知识,即便你没有相关背景知识也能轻松学会。
此外,我们将使用Python 3.x和一款非常棒的开源软件Gephi,通过关系网络将过去和现在的一系列编程语言的网络可视化联系起来。
首先,究竟什么是网络呢?
其实上面文摘菌举的栗子已经给了一些线索。交通网络由目的和路径的连接组成。社交网络通过个人和个人之间的关系进行连接。Google的搜索引擎算法通过查看有哪些页面链接到其他页面,来评估不同网页的“顺序”。
更一般地说,网络是可以用节点和边描述的任何系统,或者通俗来讲,就是我们所说的“点和线”。
边连接节点(语言)的例子(该网络表示了编程语言相互影响的关系)
有些系统以这种方式建立网络比较容易。社交网络也许是最明显的例子。计算机文件系统则是另一种方式——文件夹和文件通过其“父”和“子”关系创建连接。
但是,网络的真正威力其实在于,许多系统都可以从网络的角度来建模,即使这起初并不明显。
代表网络
我们应该如何将点和线的图片转换成我们可以压缩的数字信号呢?
其中有一个解决方案是绘制一个邻接矩阵来表示我们的网络。
如果你不熟悉矩阵这个概念,这听起来可能有点吓人,但不要害怕。 把它们想象成可以一次执行许多计算的数字网格就好。下面是一个简单的例子:

在这个矩阵中,每个行和列的交集都是0或1,这取决于各个语言是否被链接。你也可以根据上面的插图观察到!
对于要解决的大多数问题而言,矩阵是以数学方式表示网络的好方法。然而从计算的角度来看,它有时可能会有点麻烦。
例如,即使节点数量相对较少(比如说有1000个),矩阵中的元素数目也会大得多(例如,1000^2 = 1,000,000)。
许多现实世界的系统会产生稀疏网络,在这些网络中,大多数节点只能连接其他所有节点中的一小部分。
如果我们将计算机内存中1000个节点的稀疏网络表示为邻接矩阵,那么我们将在RAM中存储1,000,000个字节的数据。大多数将会是零。这里有一个更为有效的方法可以解决这个问题。
这种方法是使用边列表来代替邻接矩阵。这些正是他们所说的,它们只是一个节点对相互链接的列表。
表示网络的另一种手段是邻接表,它列出了每个节点后面与它进行链接的节点。例如:

收集数据,建立连接
任何网络模型以及可视化的表现都取决于构建网络本身所用的数据质量好坏。除了确保数据是准确和完整的同时,我们也需要一种推断节点之间边的合理方法。
这是相当关键的一步,随后对网络进行的任何分析和推断都取决于“关联标准”的合理性。
例如,在社交网络分析中,你可能会根据人们是否在社交媒体上相互关联来创建人与人之间的联系。在分子生物学中,你可能会基于基因的共同表达建立连接。
通常,我们还可以给边分配权重,从而体现关系的“强度”。
例如,对于网上零售的情况,可以根据产品被同时购买的频率来计算权重。用高权重的边连接经常被同时购买的产品,用低权重的边连接偶尔被同时购买的产品。和偶尔被同时购买的产品相比,那些不会被同时购买的产品根本就不会被网络连接。
正如你想的那样,将节点彼此连接的方法有可能很复杂。
但是对于本教程,我们将使用更简单的方式连接编程语言。我们要依靠维基百科。
维基百科所取得的的成功证明了它的可靠性。文章写作的开源合作方法也应该保证一定程度的客观性。
而且,它的页面结构相对一致,使其成为试用网页抓取技术的便利场所。
另一个便利工具是覆盖面广泛的、有据可查的维基百科API,这使得信息检索更容易。接下来让我们一起开始吧。
第一步:安装Gephi
Gephi可在Linux、Mac和Windows的环境下进行安装。
对于这个项目,我使用了Lubuntu。如果你使用的是Ubuntu / Debian,那么你可以按照下面的步骤来启动和运行Gephi。如果不是,那么安装过程也不会差太多。
下载最新版本的Gephi到你的系统(在撰写本文时是v.0.9.1)。准备就绪后,你需要提取文件。

你可能需要检查你的Java JRE版本。Gephi需要最新版本。在我刚刚安装的Lubuntu上,我只安装了default-jre,下面的一切将建立在此基础上。

在你准备好进行安装之前还有一步。为了将图表导出到Web,你可以使用Gephi的Sigma.js插件。
从Gephi的菜单栏中选择“工具”选项,然后选择“插件”。
点击“可用插件”标签并选择“SigmaExporter”(我也安装了JSON导出器,因为它是另一个有用的插件)。
点击“安装”按钮,你将完成整个安装过程。安装结束后,你需要重新启动Gephi。
第二步:编写Python脚本
本教程将使用python 3.x以及一些模块来进行简化。使用pip模块安装程序,需运行一下命令:

现在,在一个新的目录中,创建一个名为script.py的文件,并在你最喜欢的代码编辑器/ IDE中打开它。以下是主要逻辑的大纲:
首先,你需要有一个编程语言的列表。
接下来,通过该列表并检索维基百科相关文章的HTML。
从中提取出每种语言所影响的编程语言列表。这是我们连接节点的粗略标准。
同时,我们可以抓取一些关于每种语言的元数据。
最后,将收集的所有数据写入一个.csv文件。
完整的脚本在这里:
(https://gist.github.com/anonymous/2a6c841fe04ebc6d55acc259b4ac4f72)。
导入模块
在script.py中,首先导入一些模块。

准备好后——从创建一个节点的列表开始。这是Wikipedia模块派上用场的地方。它使得访问维基百科API非常容易。
添加下面的代码:

保存并运行上面的脚本,将看到打印出“List of programming languages”维基百科文章中的所有链接。
另外,还需要手动检查自动收集的数据。快速浏览后我们可以发现,除了许多实际的编程语言之外,该脚本还提供了一些额外的链接。
如:可能会看到“List of markup languages”,“Comparison of programming languages”等。
虽然Gephi允许你移除不想包含的节点,但为了节省时间,还是让我们先进行一轮数据清洗。

这些代码定义了要从数据中移除的子字符串列表。运行该脚本时遍历数据,移除所有包含不需要的子字符串的元素。
在Python语言中,完成这些只需要一行代码!
其他辅助函数
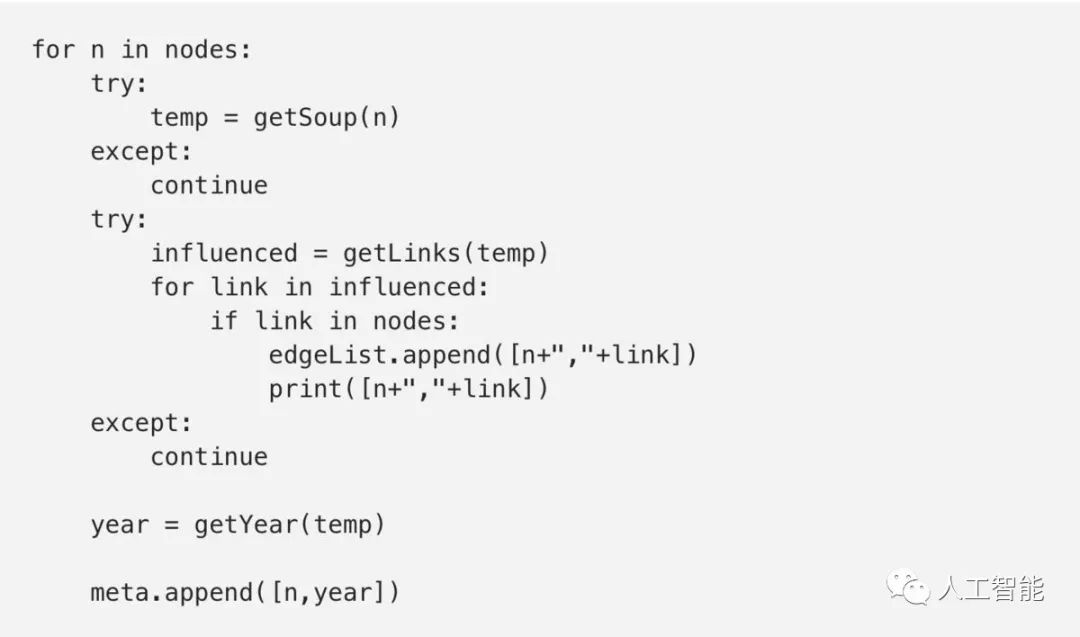
现在我们可以开始从wikipedia抓取数据并建立一个边列表(并收集所有元数据)。为了更简便,让我们首先定义一些函数。
抓取HTML
第一个函数使用BeautifulSoup模块来获取每种语言的Wikipedia页面的HTML。
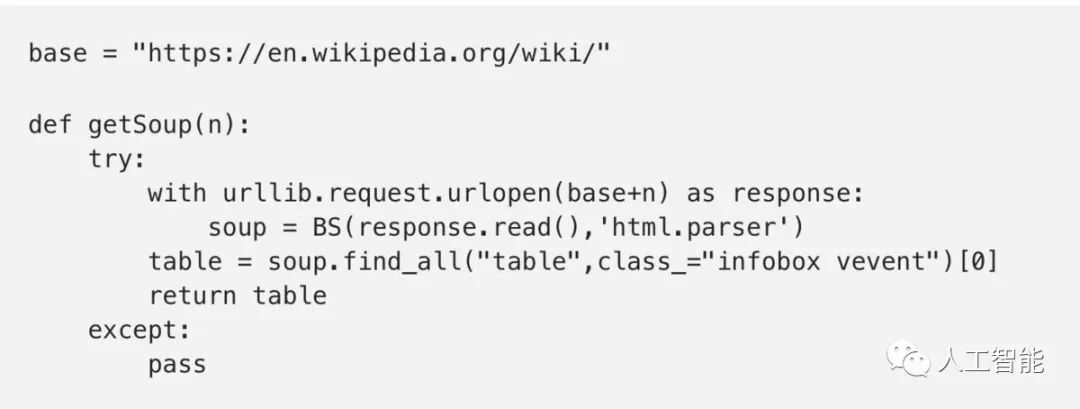
这个函数使用urllib.request模块来获取“https://en.wikipedia.org/wiki/”+“编程语言”页面的HTML。
然后传给BeautifulSoup,它将读取HTML并解析为一个可以用来搜索信息的对象。
接下来,使用find_all()方法抓取感兴趣的HTML元素。
下面,是每种编程语言文章顶部的汇总表。该如何识别呢?
最简单的方法是访问其中一个编程语言页面。在这里,可以简单地使用浏览器的开发工具来检查感兴趣的元素。汇总表有HTML标记