

基于强化学习的MADDPG算法原理及实现
电子说
描述
之前接触的强化学习算法都是单个智能体的强化学习算法,但是也有很多重要的应用场景牵涉到多个智能体之间的交互,比如说,多个机器人的控制,语言的交流,多玩家的游戏等等。本文,就带你简单了解一下Open-AI的MADDPG(Multi-Agent Deep Deterministic Policy Gradient)算法,来共同体验一下多智能体强化学习的魅力。
1、引言
强化学习中很多场景涉及多个智能体的交互,比如多个机器人的控制,语言的交流,多玩家的游戏等等。不过传统的RL方法,比如Q-Learning或者policy gradient都不适用于多智能体环境。主要的问题是,在训练过程中,每个智能体的策略都在变化,因此从每个智能体的角度来看,环境变得十分不稳定(其他智能体的行动带来环境变化)。对DQN来说,经验重放的方法变的不再适用(如果不知道其他智能体的状态,那么不同情况下自身的状态转移会不同),而对PG的方法来说,环境的不断变化导致了学习的方差进一步增大。
因此,本文提出了MADDPG(Multi-Agent Deep Deterministic Policy Gradient)方法。为什么要使用DDPG方法作为基准模型呢?主要是集中训练和分散执行的策略。
本文提出的方法框架是集中训练,分散执行的。我们先回顾一下DDPG的方式,DDPG本质上是一个AC方法。训练时,Actor根据当前的state选择一个action,然后Critic可以根据state-action计算一个Q值,作为对Actor动作的反馈。Critic根据估计的Q值和实际的Q值来进行训练,Actor根据Critic的反馈来更新策略。测试时,我们只需要Actor就可以完成,此时不需要Critic的反馈。因此,在训练时,我们可以在Critic阶段加上一些额外的信息来得到更准确的Q值,比如其他智能体的状态和动作等,这也就是集中训练的意思,即每个智能体不仅仅根据自身的情况,还根据其他智能体的行为来评估当前动作的价值。分散执行指的是,当每个Agent都训练充分之后,每个Actor就可以自己根据状态采取合适的动作,此时是不需要其他智能体的状态或者动作的。DQN不适合这么做,因为DQN训练和预测是同一个网络,二者的输入信息必须保持一致,我们不能只在训练阶段加入其他智能体的信息。
2、DDPG算法的简单回顾
什么是DDPG什么是DDPG呢?一句话描述,它是Actor-Critic 和 DQN 算法的结合体。
DDPG的全称是Deep Deterministic Policy Gradient。
我们首先来看Deep,正如Q-learning加上一个Deep就变成了DQN一样,这里的Deep即同样使用DQN中的经验池和双网络结构来促进神经网络能够有效学习。
再来看Deterministic,即我们的Actor不再输出每个动作的概率,而是一个具体的动作,这更有助于我们连续动作空间中进行学习。
DDPG的网络结构盗用莫烦老师的一张图片来形象的表示DDPG的网络结构,同图片里一样,我们称Actor里面的两个网络分别是动作估计网络和动作现实网络,我们称Critic中的两个网络分别是状态现实网络和状态估计网络:
我们采用了类似DQN的双网络结构,而且Actor和Critic都有target-net和eval-net。我们需要强调一点的事,我们只需要训练动作估计网络和状态估计网络的参数,而动作现实网络和状态现实网络的参数是由前面两个网络每隔一定的时间复制过去的。
我们先来说说Critic这边,Critic这边的学习过程跟DQN类似,我们都知道DQN根据下面的损失函数来进行网络学习,即现实的Q值和估计的Q值的平方损失:
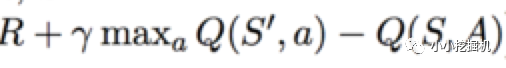
上面式子中Q(S,A)是根据状态估计网络得到的,A是动作估计网络传过来的动作。而前面部分R + gamma * maxQ(S',A')是现实的Q值,这里不一样的是,我们计算现实的Q值,不在使用贪心算法,来选择动作A',而是动作现实网络得到这里的A'。总的来说,Critic的状态估计网络的训练还是基于现实的Q值和估计的Q值的平方损失,估计的Q值根据当前的状态S和动作估计网络输出的动作A输入状态估计网络得到,而现实的Q值根据现实的奖励R,以及将下一时刻的状态S'和动作现实网络得到的动作A' 输入到状态现实网络 而得到的Q值的折现值加和得到(这里运用的是贝尔曼方程)。
我们再来说一下Actor这边,论文中,我们基于下面的式子进行动作估计网络的参数:
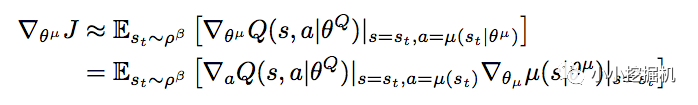
这个式子看上去很吓人,但是其实理解起来很简单。假如对同一个状态,我们输出了两个不同的动作a1和a2,从状态估计网络得到了两个反馈的Q值,分别是Q1和Q2,假设Q1>Q2,即采取动作1可以得到更多的奖励,那么Policy gradient的思想是什么呢,就是增加a1的概率,降低a2的概率,也就是说,Actor想要尽可能的得到更大的Q值。所以我们的Actor的损失可以简单的理解为得到的反馈Q值越大损失越小,得到的反馈Q值越小损失越大,因此只要对状态估计网络返回的Q值取个负号就好啦。是不是很简单。
DDPG学习中的小trick
与传统的DQN不同的是,传统的DQN采用的是一种被称为'hard'模式的target-net网络参数更新,即每隔一定的步数就将eval-net中的网络参数赋值过去,而在DDPG中,采用的是一种'soft'模式的target-net网络参数更新,即每一步都对target-net网络中的参数更新一点点,这种参数更新方式经过试验表明可以大大的提高学习的稳定性。'soft'模式到底是如何更新网络的?我们可以通过代码更好的理解。
论文中提到的另一个小trick是对采取的动作增加一定的噪声:

DDPG的完整流程
介绍了这么多,我们也就能顺利理解原文中的DDPG算法的流程:
3、MADDPG算法简介
算法流程
理解了DDPG的算法过程,那么MADDPG的过程也是不难理解的,我们一起来看一下吧。
每个Agent的训练同单个DDPG算法的训练过程类似,不同的地方主要体现在Critic的输入上:在单个Agent的DDPG算法中,Critic的输入是一个state-action对信息,但是在MADDPG中,每个Agent的Critic输入除自身的state-action信息外,还可以有额外的信息,比如其他Agent的动作。
多Agent之间的关系形式
不同的Agent之间的关系大体可以分为三种,合作型,对抗性,半合作半对抗型。我们可以根据不同的合作关系来设计我们的奖励函数。
4、模型实验
文章中设置了多组实验环境,有合作型的,有对抗型的也有半合作半对抗型的。如下图所示:
这里只重点讲我们后面代码中实现的实验。
实验的名称为Predator-prey。其英文解释为Good agents (green) are faster and want to avoid being hit by adversaries (red). Adversaries are slower and want to hit good agents. Obstacles (large black circles) block the way.
不过我们在代码中只实现了三个Adversaries,而Good agents处于随机游走状态。
在合作交流的环境下,论文中将MADDPG与传统的算法进行了对比,得到的结果如下:
可以看到,MADDPG与传统的RL算法相比,在多智能体的环境下,能够取得更加突出的效果。
5、MADDPG算法的简单实现
本文实践了Predator-prey这一环境,如下图所示:
绿色的球为目标,在二维空间中随机游走,躲避红色的球的攻击。三个红色的球是我们定义的Agent,它们处在互相对抗的环境中,想要击中绿色的球,从而获得奖励。黑色的地方时障碍。
本文的github地址为:https://github.com/princewen/tensorflow_practice/tree/master/RL/Basic-MADDPG-Demo
实验环境安装
下载https://github.com/openai/multiagent-particle-envs中的代码。
进入到代码主路径中,执行命令安装所需的环境
pip install -e .
代码结构本项目的代码结构如下:
model_agent_maddpg.py:该文件定义了单个Agent的DDPG结构,及一些函数replay_buffer.py:定义了两种不同的经验池,一种是普通的经验池,一种是优先采样经验池segment_tree.py :只有在使用优先采样经验池的时候才用到。定义一种树结构根据经验的优先级进行采样test_three_agent_maddpg.py:对训练好的模型进行测试three_agent_maddpg.py:模型训练的主代码
DDPG-Actor实现我们首先来实现单个的DDPG结构Actor的输入是一个具体的状态,经过两层的全链接网络输出选择的Action。
def actor_network(name): with tf.variable_scope(name) as scope: x = state_input x = tf.layers.dense(x, 64) if self.layer_norm: x = tc.layers.layer_norm(x, center=True, scale=True) x = tf.nn.relu(x) x = tf.layers.dense(x, 64) if self.layer_norm: x = tc.layers.layer_norm(x, center=True, scale=True) x = tf.nn.relu(x) x = tf.layers.dense(x, self.nb_actions, kernel_initializer=tf.random_uniform_initializer(minval=-3e-3, maxval=3e-3)) x = tf.nn.tanh(x) return x
DDPG-Critic实现
Critic的输入是state,以及所有Agent当前的action信息:
def critic_network(name, action_input, reuse=False): with tf.variable_scope(name) as scope: if reuse: scope.reuse_variables() x = state_input x = tf.layers.dense(x, 64) if self.layer_norm: x = tc.layers.layer_norm(x, center=True, scale=True) x = tf.nn.relu(x) x = tf.concat([x, action_input], axis=-1) x = tf.layers.dense(x, 64) if self.layer_norm: x = tc.layers.layer_norm(x, center=True, scale=True) x = tf.nn.relu(x) x = tf.layers.dense(x, 1, kernel_initializer=tf.random_uniform_initializer(minval=-3e-3, maxval=3e-3)) return x
训练Actor和Critic
Actor的训练目标是Q值的最大化,而Critic的训练目标是最小化Q估计值和Q实际值之间的差距:
self.actor_optimizer = tf.train.AdamOptimizer(1e-4)self.critic_optimizer = tf.train.AdamOptimizer(1e-3)# 最大化Q值self.actor_loss = -tf.reduce_mean( critic_network(name + '_critic', action_input=tf.concat([self.action_output, other_action_input], axis=1), reuse=True))self.actor_train = self.actor_optimizer.minimize(self.actor_loss)self.target_Q = tf.placeholder(shape=[None, 1], dtype=tf.float32)self.critic_loss = tf.reduce_mean(tf.square(self.target_Q - self.critic_output))self.critic_train = self.critic_optimizer.minimize(self.critic_loss)
定义三个Agent
随后,我们分别建立三个Agent,每个Agent对应两个DDPG结构,一个是eval-net,一个是target-net:
agent1_ddpg = MADDPG('agent1')agent1_ddpg_target = MADDPG('agent1_target')agent2_ddpg = MADDPG('agent2')agent2_ddpg_target = MADDPG('agent2_target')agent3_ddpg = MADDPG('agent3')agent3_ddpg_target = MADDPG('agent3_target')
模型训练
在训练过程中,假设当前的状态是o_n,我们首先通过Actor得到每个Agent的动作,这里我们将动作定义为一个二维的向量,不过根据OpenAi的环境设置,我们需要将动作展开成一个五维的向量,同时绿色的球也需要定义动作,因此一共将四组动作输入到我们的环境中,可以得到奖励及下一个时刻的状态o_n_next以及当前的奖励r_n:
agent1_action, agent2_action, agent3_action = get_agents_action(o_n, sess, noise_rate=0.2)#三个agent的行动a = [[0, i[0][0], 0, i[0][1], 0] for i in [agent1_action, agent2_action, agent3_action]]#绿球的行动a.append([0, np.random.rand() * 2 - 1, 0, np.random.rand() * 2 - 1, 0])o_n_next, r_n, d_n, i_n = env.step(a)
随后,我们需要将经验存放到经验池中,供Critic反馈和训练:
agent1_memory.add(np.vstack([o_n[0], o_n[1], o_n[2]]), np.vstack([agent1_action[0], agent2_action[0], agent3_action[0]]), r_n[0], np.vstack([o_n_next[0], o_n_next[1], o_n_next[2]]), False)agent2_memory.add(np.vstack([o_n[1], o_n[2], o_n[0]]), np.vstack([agent2_action[0], agent3_action[0], agent1_action[0]]), r_n[1], np.vstack([o_n_next[1], o_n_next[2], o_n_next[0]]), False)agent3_memory.add(np.vstack([o_n[2], o_n[0], o_n[1]]), np.vstack([agent3_action[0], agent1_action[0], agent2_action[0]]), r_n[2], np.vstack([o_n_next[2], o_n_next[0], o_n_next[1]]), False)
当经验池中存储了一定的经验之后,我们就可以根据前文介绍过的双网络结构和损失函数来训练每个Agent的Actor和Critic:
train_agent(agent1_ddpg, agent1_ddpg_target, agent1_memory, agent1_actor_target_update, agent1_critic_target_update, sess, [agent2_ddpg_target, agent3_ddpg_target])train_agent(agent2_ddpg, agent2_ddpg_target, agent2_memory, agent2_actor_target_update, agent2_critic_target_update, sess, [agent3_ddpg_target, agent1_ddpg_target])train_agent(agent3_ddpg, agent3_ddpg_target, agent3_memory, agent3_actor_target_update, agent3_critic_target_update, sess, [agent1_ddpg_target, agent2_ddpg_target])
-
18个常用的强化学习算法整理:从基础方法到高级模型的理论技术与代码实现2025-04-23 1391
-
如何使用 PyTorch 进行强化学习2024-11-05 1480
-
基于强化学习的目标检测算法案例2023-07-19 921
-
什么是深度强化学习?深度强化学习算法应用分析2023-07-01 2104
-
彻底改变算法交易:强化学习的力量2023-06-09 914
-
7个流行的强化学习算法及代码实现2023-02-03 1734
-
强化学习的基础知识和6种基本算法解释2022-12-20 1645
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 1213
-
深度强化学习实战2021-01-10 2795
-
基于PPO强化学习算法的AI应用案例2020-07-29 3394
-
反向强化学习的思路2019-04-03 2370
-
如何构建强化学习模型来训练无人车算法2018-11-12 5421
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28665
全部0条评论

快来发表一下你的评论吧 !
