

基于深度学习模型的点云目标检测及ROS实现
电子说
描述
近年来,随着深度学习在图像视觉领域的发展,一类基于单纯的深度学习模型的点云目标检测方法被提出和应用,本文将详细介绍其中一种模型——SqueezeSeg,并且使用ROS实现该模型的实时目标检测。
传统方法VS深度学习方法
实际上,在深度学习方法出现之前,基于点云的目标检测已经有一套比较成熟的处理流程:分割地面->点云聚类->特征提取->分类,典型的方法可以参考Velodyne的这篇论文:LIDAR-based 3D Object Perception
▌那么传统方法存在哪些问题呢?
1.第一步的地面分割通常依赖于人为设计的特征和规则,如设置一些阈值、表面法线等,泛化能力差;
2.多阶段的处理流程意味着可能产生复合型错误——聚类和分类并没有建立在一定的上下文基础上,目标周围的环境信息缺失;
3.这类方法对于单帧激光雷达扫描的计算时间和精度是不稳定的,这和自动驾驶场景下的安全性要求(稳定,小方差)相悖。
因此,近年来不少基于深度学习的点云目标检测方法被提出,本文介绍的SqueezeSeg就是其中一种,这类方法使用深度神经网络提取点云特征,以接近于端到端的处理流程实现点云中的目标检测。
论文:SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud,
https://arxiv.org/pdf/1710.07368.pdf
SqueezeSeg理论部分
▌概括
SqueezeSeg使用的是CNN(卷积神经网络)+CRF(Conditional Random Field,条件随机场)这样的结构。
其中,CNN采用的是Forrest提出的SqueezeNet网络(详情见论文:“SqueezeNet: Alexnet-level accuracy with 50x fewer
parameters and < 0.5mb model size”, https://arxiv.org/pdf/1602.07360.pdf ), 该网络使用远少于AlexNet的参数数量便达到了等同于AlexNet的精度,极少的参数意味着更快的运算速度和小的内存消耗,这是符合车载场景需求的。
被预处理过的点云数据(二维化)将被以张量的形式输入到这个CNN中,CNN输出一个同等宽高的标签映射(label map),实际上就是对每一个像素进行了分类,然而单纯的CNN逐像素分类结果会出现边界模糊的问题,为解决该问题,CNN输出的标签映射被输入到一个CRF中,这个CRF的形式为一个RNN,其作用是进一步的矫正CNN输出的标签映射。最终的检测结果论文中使用了DBSCAN算法进行了一次聚类,从而得到检测的目标实体。
下面我们从预处理出发,首先理解这一点云目标检测方法。
▌点云预处理
传统的CNN设计多用于二维的图像模式识别(宽 × imes× 高 × imes× 通道数),三维的点云数据格式不符合该模式,而且点云数据稀疏无规律,这对特征提取都是不利的,因此,在将数据输入到CNN之前,首先对数据进行球面投影,从而到一个稠密的、二维的数据,球面投影示意图如下:
其中,ϕ和θ分别表示点的方位角(azimuth)和顶角(altitude),这两个角如下图所示:
通常来说,方位角是相对于正北方向的夹角,但是,在我们Lidar的坐标系下,方位角为相对于x方向(车辆正前方)的夹角,ϕ和θ的计算公式为:
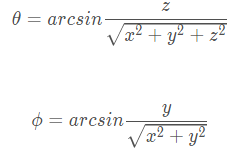
其中,(x,y,z) 为三维点云中每一个点的坐标。所以对于点云中的每一个点都可以通过其 (x,y,z) 计算其 (θ,ϕ) ,也就是说我们将三维空间坐标系中的点都投射到了一个球面坐标系,这个球面坐标系实则已经是一个二维坐标系了,但是,为了便于理解,我们对其角度进行微分化从而得到一个二维的直角坐标系:

那么,球面坐标系下的每一个点都可以使用一个直角坐标系中的点表示,如下:
通过这么一层变换,我们就将三维空间中任意一点的位置(x,y,z) 投射到了2维坐标系下的一个点的位置 (i,j) 我们提取点云中每一个点的5个特征: (x,y,z,intensity,range) 放入对应的二维坐标 (i,j) 内。从而得到一个尺寸为 (H,W,C) 张量(其中C=5),由于论文使用的是Kitti的64线激光雷达,所以 H=64,水平方向上,受Kitti数据集标注范围的限制,原论文仅使用了正前方90度的Lidar扫描,使用512个网格对它们进行了划分(即水平上采样512个点)。所以,点云数据在输入到CNN中之前,数据被预处理成了一个尺寸为 (64×512×5) 的张量。
▌CNN结构
SqueezeSeg的CNN部分几乎完全采用的SqueezeNet网络结构,SqueezeNet是一个参数量极少但是能够达到AlexNet精度的CNN网络,在对实时性有要求的点云分割应用场景中采用颇有意义。其网络结构如下:
该网络最大的特色为两个结构,被称为 fireModules 和 fireDeconvs,这两种网络层的具体结构如下:
由于输入的张量的高度(64)要小于其宽度(512),该网络主要对宽度进行降维,通过添加最大池化层(Max Pooling)降低数据的宽度。到Fire9输出的是降维后的特征映射。为了得到一个完整的映射标签,还需要对特征映射进行还原(即还原到原尺寸),conv14层的输出即对每个点的分类概率映射。输出最后被输入到一个条件随机场中进行进一步的矫正。
SqueezeSeg中采用的CRF
在深度学习技术不断进步的同时,概率图形模型已被开发为用于提高像素级标记任务准确性的有效方法。马尔可夫随机场(Markov Random Fields, MRF)及其变体——条件随机场(Conditional Random Fields, CRF)已经成为计算机视觉中最成功的概率图模型之一。
由于CNN网络的下采样层(如最大池化层)的存在,使得数据的一些底层细节在CNN被抛弃,近而造成CNN输出的预测分类存在边界模糊的问题。高精度的逐像素分类不仅依赖于高层特征,也受到底层细节信息的影响,细节信息对于标签分类的一致性至关重要。打个比方,如果点云中两个点相近,同时具有类似的强度值(intensity),那么它们就有可能属于同一个目标(即具有一样的分类)。
CRF推理应用于语义标记的关键思想是将标签分配(对于像素分割来说就是像素标签分配)问题表达为包含类似像素之间具有一定标签协议的假设的概率推理问题。CRF推理能够改进像素级标签预测,以产生清晰的边界和细粒度的分割。因此,CRF可用于克服利用CNN进行像素级标记任务的缺点。为了弥补下采样过程中细节信息的损失,SqueezeSeg在最后使用RNN实现一个CRF推理,以对label map进行进一步精炼,这里作者参考了论文: Conditional Random Fields as Recurrent Neural Networks ,该论文提出了mean-field 近似推理,以带有高斯pairwise的势函数的密集CRF作为RNN,在前向过程中对CNN粗糙的输出精细化,同时在训练时将误差返回给CNN。结合了CNN与RNN的模型可以正常的利用反向传播来端对端的训练。SqueezeSeg的CRF部分结构如下图所示:
我们将CNN的输出结果作为CRF的输入,根据原始点云计算高斯滤波器,其有两个高斯核,如下所示:
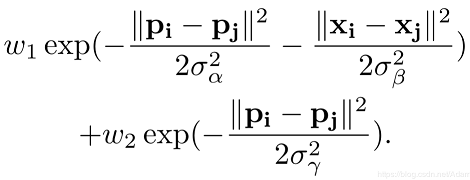
其中x为点的三维坐标 (x,y,z) ,p为点经过球面投影得到的方位角和顶角 (θ,ϕ),其他参数为经验性阈值。该高斯核衡量了两点之间特征的差异,两点之间差异越大( x xx 和 p pp 相差越多),高斯核的值就越小,两点之间的相关性也就越小。在输入图像使用该高斯滤波器的过程称为message passing,可以初步聚合邻域点的概率。接着,通过1x1大小的卷积核去微调每一个点的概率分布权重,这一个过程称为re-weighting and compatibilty transformation,卷积核的值是通过学习得到。最后,以残差方式将最初的便签映射加到re-weighting的输出结果并用softmax归一化。在实际操作中,整个CRF以RNN层重复循环三次,并得到最终精炼后的标签映射。
使用SqueezeSeg实现一个ROS节点进行点云目标识别与分割
SqueezeSeg的模型训练代码在本文中不在赘述,感兴趣的同学可以直接去看作者的开源代码:
SqueezeSeg作者开源的模型训练代码:
https://github.com/BichenWuUCB/SqueezeSeg
上面的代码为TensorFlow实现,基于上述仓库,我们实现一个ROS节点,调用一个已经训练好的SqueezeSeg模型,对输入的点云进行目标识别和分割。所以在运行下述实例代码之前,需要自行安装好TensorFlow-GPU版本(CPU版本亦可,但是运行速度相对要慢一些),本文假定大家已经安装好TensorFlow环境,我们来继续关注基于SqueezeSeg的ROS应用开发,我们采用论文作者公开的数据(来源于Kitti,采集自HDL-64雷达,同时已经完成了前向90度的切割,并且被保存成了npy文件)。
数据下载地址:
https://www.dropbox.com/s/pnzgcitvppmwfuf/lidar_2d.tgz?dl=0
国内读者如无法访问,可以使用此地址下载:
https://pan.baidu.com/s/1kxZxrjGHDmTt-9QRMd_kOA
将数据下载好以后解压到ROS package的 script/data/ 目录下,解压以后的目录结构为:
squeezeseg_ros/script/data/lidar_2d/
完整代码见文末github仓库。
采用作者开源的数据的一个很重要的原因在于手头没有64线的激光雷达,首先我们看看launch文件内容:
npy_path参数即为我们的数据的目录,我们将其放在package的script/data目录下,npy_file_list是个文本文件的路径,它记录了验证集的文件名,pub_topic指定我们最后发布出去的结果的点云topic名称,checkpoint参数指定我们预先训练好的SqueezeSeg模型的目录,它是一个TensorFlow 的checkpoint文件,gpu参数指定使用主机的那一快GPU(即指定GPU的ID),通常我们只有一块GPU,所以这里设置为0,如果主机没有安装GPU(当然TensorFlow-gpu也就无法工作),则会使用CPU。squeezeseg_ros_node.py即为我们调用模型的接口,最后我们在启动Rviz,加载设定好的Rviz配置文件,即可将模型的识别结果可视化出来。
具体到squeezeseg_ros_node.py中,首先加载参数并且配置checkpoint路径:
rospy.init_node('squeezeseg_ros_node') npy_path = rospy.get_param('npy_path') npy_file_list = rospy.get_param('npy_file_list') pub_topic = rospy.get_param('pub_topic') checkpoint = rospy.get_param('checkpoint') gpu = rospy.get_param('gpu') FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_string( 'checkpoint', checkpoint, """Path to the model paramter file.""") tf.app.flags.DEFINE_string('gpu', gpu, """gpu id.""") npy_tensorflow_to_ros = NPY_TENSORFLOW_TO_ROS(pub_topic=pub_topic, FLAGS=FLAGS, npy_path=npy_path, npy_file_list=npy_file_list)
循环读取npy数据文件,读取文件的代码如下:
# Read all .npy data from lidar_2d folder def get_npy_from_lidar_2d(self, npy_path, npy_file_list): self.npy_path = npy_path self.npy_file_list = open(npy_file_list, 'r').read().split(' ') self.npy_files = [] for i in range(len(self.npy_file_list)): self.npy_files.append( self.npy_path + self.npy_file_list[i] + '.npy') self.len_files = len(self.npy_files)
调用深度学习模型对点云进行分割和目标检测识别,并将检测出来的结果以PointCloud2的msg格式发到指定的topic上:
# Read all .npy data from lidar_2d folder def get_npy_from_lidar_2d(self, npy_path, npy_file_list): self.npy_path = npy_path self.npy_file_list = open(npy_file_list, 'r').read().split(' ') self.npy_files = [] for i in range(len(self.npy_file_list)): self.npy_files.append( self.npy_path + self.npy_file_list[i] + '.npy') self.len_files = len(self.npy_files) def prediction_publish(self, idx): clock = Clock() record = np.load(os.path.join(self.npy_path, self.npy_files[idx])) lidar = record[:, :, :5] # to perform prediction lidar_mask = np.reshape( (lidar[:, :, 4] > 0), [self._mc.ZENITH_LEVEL, self._mc.AZIMUTH_LEVEL, 1] ) norm_lidar = (lidar - self._mc.INPUT_MEAN) / self._mc.INPUT_STD pred_cls = self._session.run( self._model.pred_cls, feed_dict={ self._model.lidar_input: [norm_lidar], self._model.keep_prob: 1.0, self._model.lidar_mask: [lidar_mask] } ) label = pred_cls[0] # point cloud for SqueezeSeg segments x = lidar[:, :, 0].reshape(-1) y = lidar[:, :, 1].reshape(-1) z = lidar[:, :, 2].reshape(-1) i = lidar[:, :, 3].reshape(-1) label = label.reshape(-1) cloud = np.stack((x, y, z, i, label)) header = Header() header.stamp = rospy.Time().now() header.frame_id = "velodyne_link" # point cloud segments msg_segment = self.create_cloud_xyzil32(header, cloud.T) # publish self._pub.publish(msg_segment) rospy.loginfo("Point cloud processed. Took %.6f ms.", clock.takeRealTime())
不同于一般的PointCloud2 msg,这里的每一个点除了包含x,y,z,intensity字段以外,还包含一个label字段(即分类的结果),构建5字段的PointCloud2 msg的代码如下:
# create pc2_msg with 5 fields def create_cloud_xyzil32(self, header, points): fields = [PointField('x', 0, PointField.FLOAT32, 1), PointField('y', 4, PointField.FLOAT32, 1), PointField('z', 8, PointField.FLOAT32, 1), PointField('intensity', 12, PointField.FLOAT32, 1), PointField('label', 16, PointField.FLOAT32, 1)] return pc2.create_cloud(header, fields, points)
使用launch文件启动节点:
roslaunch squeezeseg_ros squeeze_seg_ros.launch
弹出Rviz界面,识别分割如下:
在我的 CPU:i7-8700 + GPU:GTX1070的环境下,处理一帧数据的耗时大约在50ms以内,如下:
对于semantic segmentationz这类任务而言,其速度已经比较可观了,通常雷达频率约为10HZ,该速度基本达到要求。
-
AI模型部署边缘设备的奇妙之旅:目标检测模型2024-12-19 0
-
华为云深度学习服务,让企业智能从此不求人2018-08-02 0
-
全网唯一一套labview深度学习教程:tensorflow+目标检测:龙哥教你学视觉—LabVIEW深度学习教程2020-08-10 0
-
【HarmonyOS HiSpark AI Camera】基于深度学习的目标检测系统设计2020-09-25 0
-
深度学习模型是如何创建的?2021-10-27 0
-
一种新的目标分类特征深度学习模型2018-03-20 1079
-
如何使用深度学习进行视频行人目标检测2018-11-19 1510
-
基于深度学习的目标检测研究综述2022-01-06 2309
-
深度学习在目标检测中的应用2022-10-31 2064
-
简述深度学习的基准目标检测及其衍生算法2023-02-27 1485
-
基于深度学习的点云分割的方法介绍2023-07-20 385
-
如何基于深度学习模型训练实现圆检测与圆心位置预测2023-12-21 2455
-
如何基于深度学习模型训练实现工件切割点位置预测2023-12-22 919
-
深度学习检测小目标常用方法2024-03-18 892
-
基于深度学习的小目标检测2024-07-04 1356
全部0条评论

快来发表一下你的评论吧 !
