

搭建了一款GIF动图生成器,其中使用的是OpenCV
电子说
描述
编者按:今天的介绍的教程轻松有趣,作者Adrian Rosebrock搭建了一款GIF动图生成器,其中使用的是OpenCV,这一过程中会提到以下几点技术:
如何用基于深度学习的方法进行人脸检测
如何用dlib库进行人脸标记检测并提取眼睛部分(因为动图会在眼睛区域添加眼镜)
如何计算旋转角度,让动图眼镜调整到合适位置
最后,如何用OpenCV生成动态GIF
想了解更多细节,就继续读下去吧!
准备工作和依赖环境
OpenCV和dlib
OpenCV是常用的人脸识别和基础图像处理工具,论智君此前也介绍过OpenCV,感兴趣的同学可以阅读:
当Node.js遇上OpenCV深度神经网络;
用OpenCV实现八种不同的目标跟踪算法
此外,Dlib是用来检测面部标志的工具,可以让我们定位眼睛在脸部的位置,并且让“眼镜”的图标下降到这一位置。dlib的安装教程:www.pyimagesearch.com/2018/01/22/install-dlib-easy-complete-guide/
ImageMagick
ImageMagick是一个跨平台的、基于命令行的工具,能提供多种图片处理功能,例如只用一行指令就能将PNG/JPG图像转换成PDF;多张图片可以集合在一份PDF中;还可以绘制多边形、线条或其他形状。利用ImageMagick,我们还可以用一系列输入图像生成GIF图片。
在Ununtu(或Raspbian)上用apt安装ImageMagick的指令如下:
$ sudo apt-get install imagemagick
如果你用的是macOS,可能会用到HomeBrew:
$ brew install imagemagick
imutils
Imutils是一些列基础图像处理功能,包括转换、旋转、缩放等等。安装指令:
$ pip install imutils
项目架构
我们的项目分为两个目录:
images/:也就是想要对其处理的原始图像。
assets/:这一文件夹包含了我们的人脸探测器、面部标志检测器和所有图像以及相关掩码。利用这些工具,我们会将“墨镜”和“Deal With It”的文字添加到输入图像中。
由于配置参数较多,我决定创建一个JSON配置文件,不仅能在编辑参数时更容易,命令行的参数也更少。在这一任务中我们所需的所有配置参数都包含在config.json中。
用OpenCV生成GIFs
了解JSON配置文件
首先,我们从JSON配置文件开始。打开config.json,插入以下命令:
第2行和第3行是OpenCV深度学习人脸探测器的模型文件,第四行是dlib的面部标志探测器的路径。
接下来我们打开一些图片文件路径:
5—8行是“墨镜”和文字“Deal With It”以及相关掩码的路径,如下所示:
墨镜
墨镜的掩码
文字
文字的掩码
掩码的作用是在照片上覆盖对应的图像。现在我们要对这个GIF生成器设置参数:
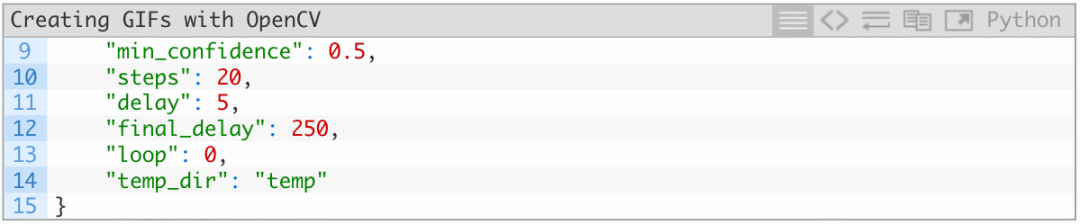
min_confidence表示人脸识别结果为正的最低概率。
steps表示生成的GIF所需要的帧数。每一个step我们都会将墨镜从上至下逐帧移动,直到达到目标位置(眼睛)。
delay表示各帧之间的时间延迟。
final_delay表示最后一针的时间延迟。
loop表示GIF是否循环播放。
temp_dir表示临时输出的目录,每一帧都会先存储在这个文件夹中,再创建最终的GIF图像。
开始创建
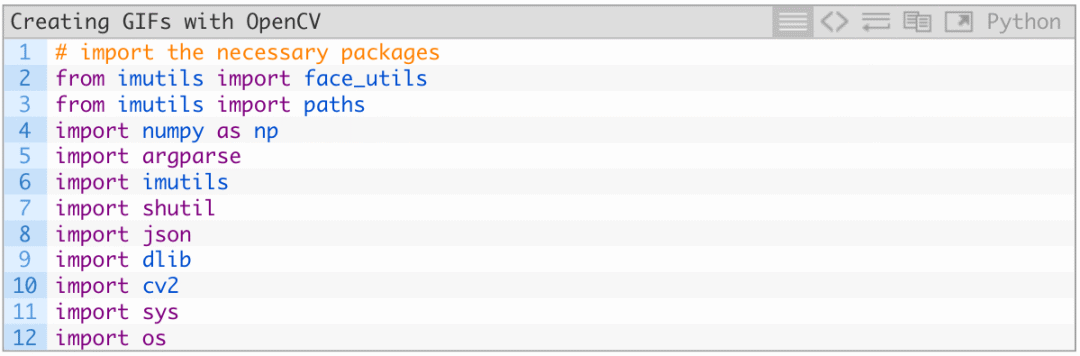
创建一个新文件夹,将其命名为create_gif.py,插入以下代码,载入imutils、dlib、OpenCV:
接着,定义overlay_image函数:
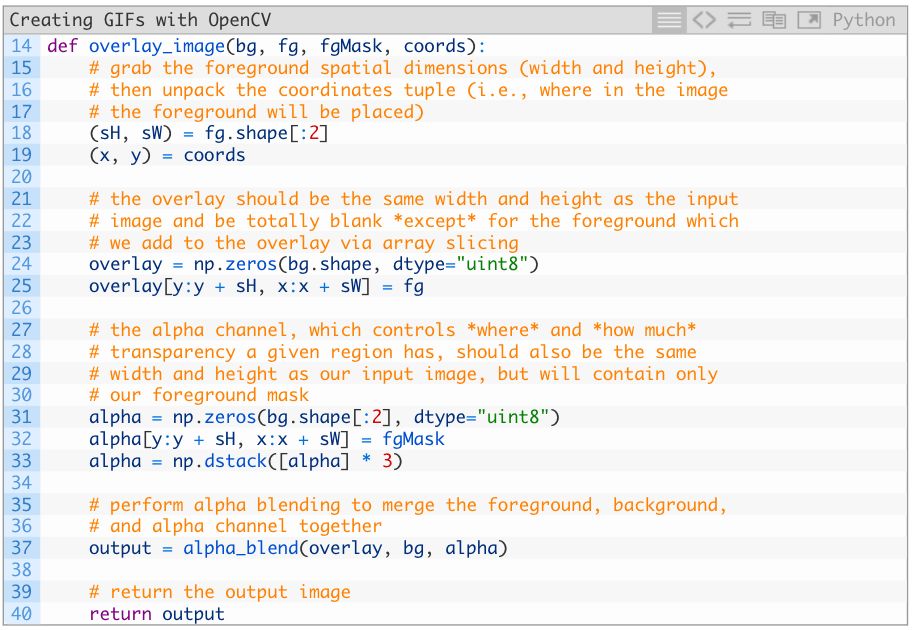
overlay_image函数是将前景图像(fg)覆盖在背景图像(bg)上,坐标coords通过(x, y)的坐标点表示。
之后,进行alpha合成完成重叠结果:
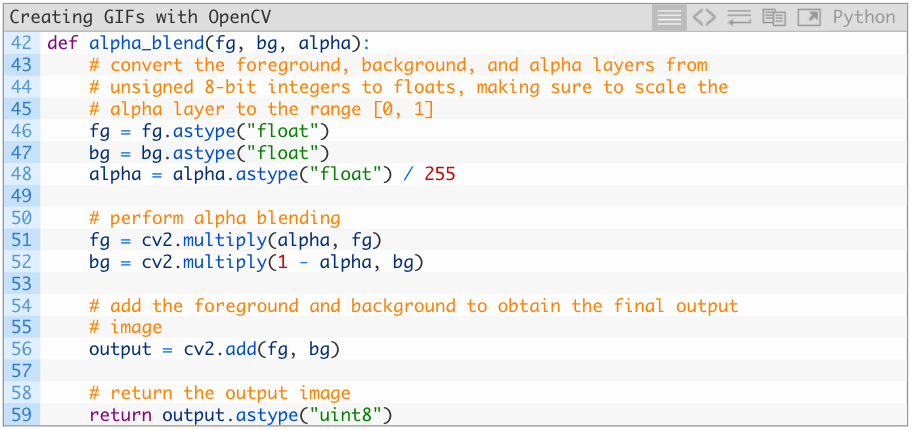
46—48行中,我们将前景、背景和alpha层转换为[0,1]之间的浮点。接着,我们在51和52行执行alpha合成。最后,添加前景和背景,得出输出,返回函数(37—40行)。
接着创建一个帮助函数,可以用ImageMagick从一系列图片路径中生成一个GIF:
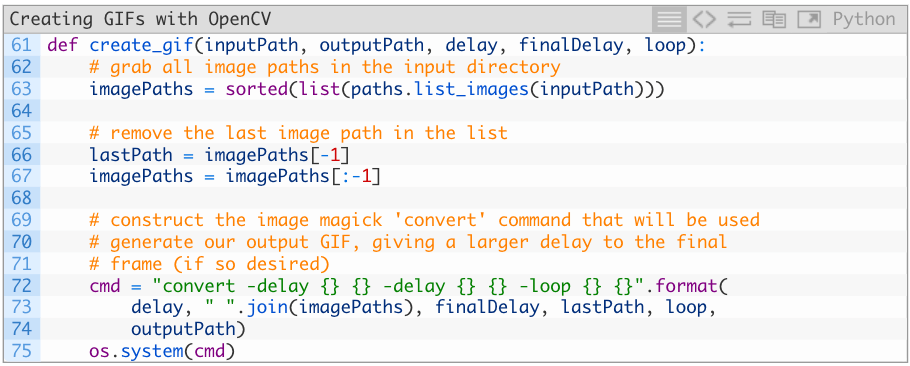
create_gif函数可以处理一系列图片,将它们组合成一张GIF动图,并且还能在帧和帧之间设置一定的延迟或循环。具体来说,在这一函数中我们可以:
提取imagePaths(63行)
提取最后一张图像的路径,因为可能有分离的延迟(66行)
重新分配imagePaths,删除最后一张图片的路径(67行)
组合命令行,开始执行convert创建GIF(72—75行)
创建自己脚本的命令行参数:

下载配置文件和“墨镜”及其掩码:
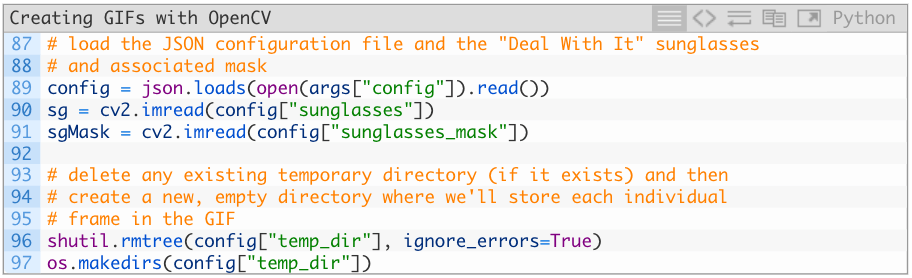
将OpenCV深度学习人脸检测器载入内存中:

为了下载OpenCV的深度学习人脸检测,我们会调用cv2.dnn.readNetFromCaffe(101和102行)。dnn模块只能在OpenCV3.3及之后的版本中使用。人脸识别器会呈现出如下结果:
在103行,我们下载了dlib的人脸标志预测器,可以定位脸部以及各器官,例如眼睛、眉毛、鼻子、嘴巴、下巴等等:
接着,让我们开始检测脸部:
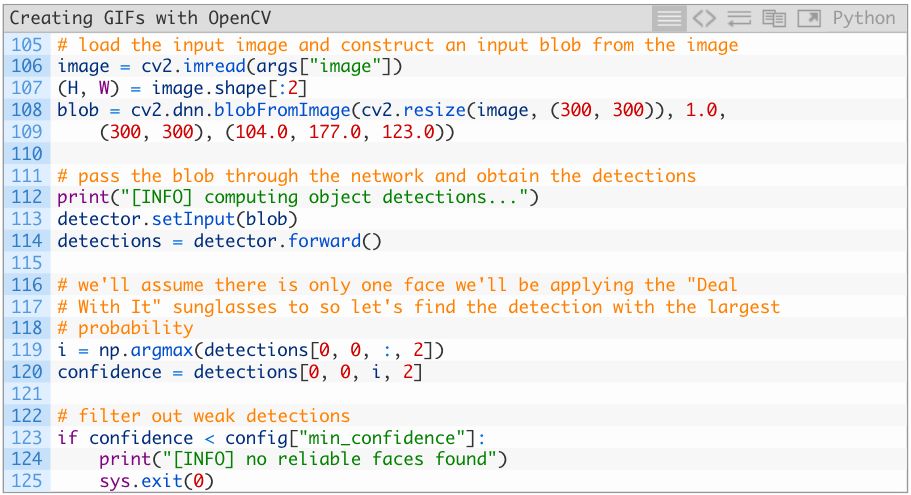
在这一部分,我们会:
下载输入的照片image(106行)
创建一个blob,输入进人脸检测神经网络(108和109行)
执行人脸检测(113和114行)
确定人脸检测的概率,检查置信区间(119—124行)。如果标准不符合,我们就简单地推出脚本(125行),反之则继续。
提取面部并计算人脸的标记:

得到眼睛的坐标后,我们就能计算将“墨镜”放置在哪里、应该怎样放置:
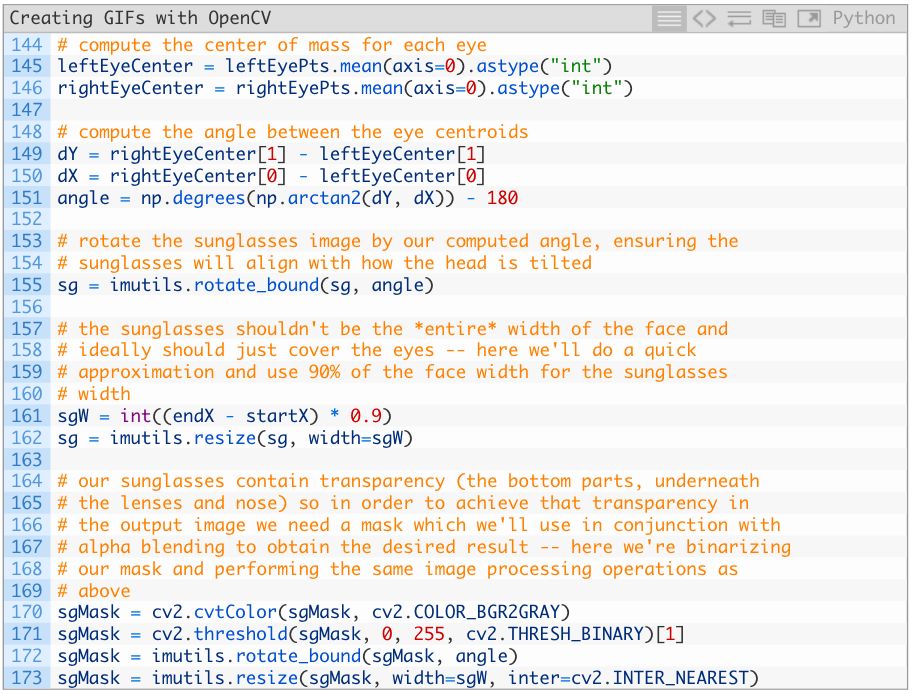
首先,计算每只眼睛的中心以及二者之间的角度(145—151行)。之后对“墨镜”进行旋转(155行)和尺寸缩放(161和162行)。
之后,还要对掩码进行移动,但是首先,我们需要将掩码转换成灰度并进行二值化运算(170和171行)。之后在进行旋转和缩放(172和173行)。
创建GIF的帧:
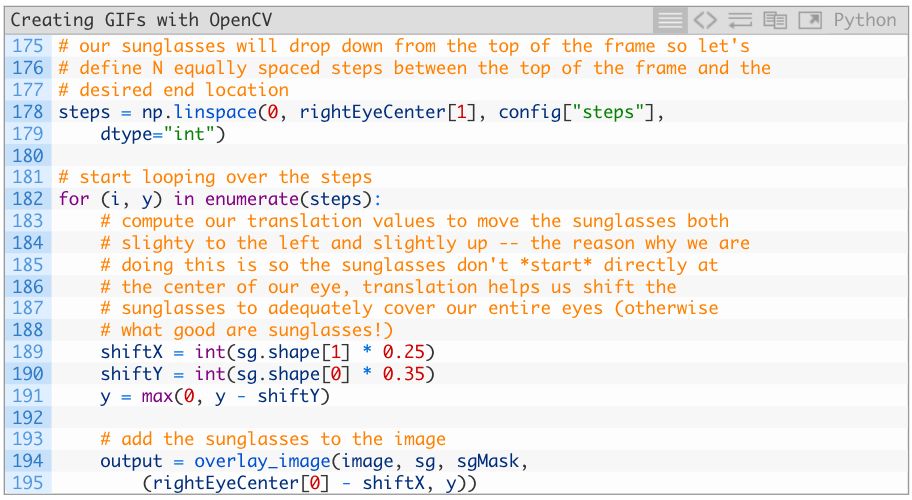
动图中,“墨镜”会从上至下落到图片中,所以每一帧都呈现的是墨镜逐渐靠近人脸的过程。利用JSON配置变量steps对墨镜位置进行调整。
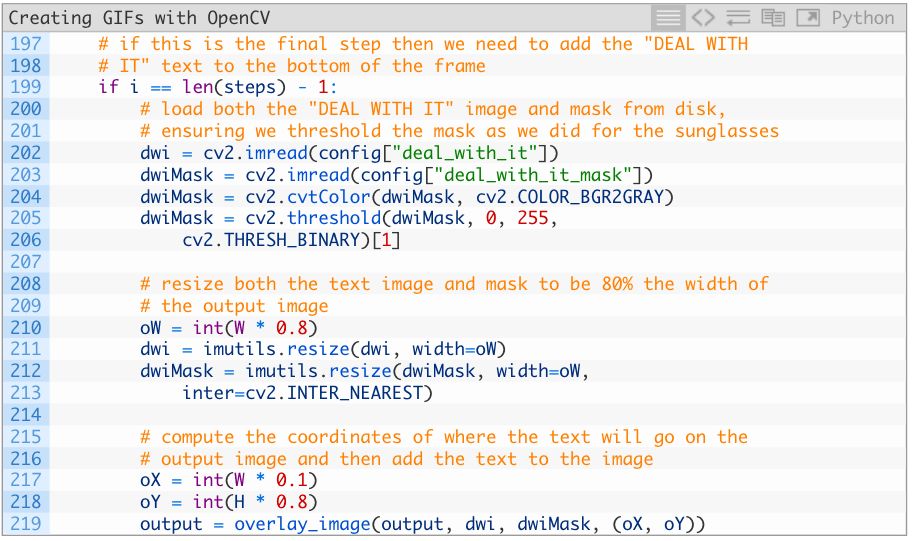
最后一步是添加“DEAL WITH IT”的文字,这需要用另一个掩码逐帧操作:
生成结果
现在可以看看我们的表情包生成器结果怎样了,保证你已经下载了源代码(原文地址见文末),打开终端,执行以下命令:
$ python create_gif.py --config config.json --image images/adrian.jpg
--output adrian_out.gif
[INFO] loading models...
[INFO] computing object detections...
[INFO] creating GIF...
[INFO] cleaning up...
可以看到,生成器能在不同角度检测到眼睛的位置,结果比较理想!
-
82 Gi Hub上一款宝藏开源项目----美女生成器小凡 2022-08-28
-
懒人C51代码生成器2013-11-30 0
-
AllJoyn C++代码生成器2018-09-19 0
-
为什么我无法从ip core向导生成器生成我的项目中使用的原理图?2019-11-07 0
-
推荐一款:【灵生】单片机代码自动生成器(自动编程工具)2020-12-21 0
-
介绍一下ABOV提供的代码生成器2021-11-19 0
-
python生成器2022-02-24 0
-
自制酸奶生成器2009-04-23 936
-
c语言流程图生成器下载2012-05-10 1296
-
C语言流程图生成器2015-07-06 585
-
代码生成器的应用2016-01-14 815
-
python生成器是什么2022-02-24 3679
-
Arduino赞美生成器2022-11-09 606
-
通用RFID生成器2023-02-10 406
-
Versal GTY/GTYP:使用PRBS生成器和检查器2023-07-10 1138
全部0条评论

快来发表一下你的评论吧 !
