

索尼发布新的方法,在ImageNet数据集上224秒内成功训练了ResNet-50
电子说
描述
深度神经网络训练速度越来越快已经不是新鲜事,但是,将ImageNet训练时间降低到200秒级别仍然让人震撼!近日,索尼发布新的方法,在ImageNet数据集上,使用多达2176个GPU,在224秒内成功训练了ResNet-50,刷新了纪录。
随着用于深度学习的数据集和深度神经网络模型的规模增大,训练模型所需的时间也在增加具有数据并行性的大规模分布式深度学习可以有效缩短训练时间。
然而,由于大型 mini-batch 训练的不稳定性和梯度同步的开销,将分布式深度学习扩展到大规模的GPU集群级别很有挑战性。
日本索尼公司的Hiroaki Mikami等人近日提出一种新的大规模分布式训练方法,通过控制batch size解决了大型mini-batch训练的不稳定性,用2D-Torus all-reduce解决了梯度同步的开销。
具体而言,2D-Torus all-reduce将GPU排列在一个逻辑2D网格中,并以不同的方向执行一系列操作。
这两种技术都是基于索尼的神经网络库NNL(Neural Network Libraries)实现的。最终,索尼的研究人员在224秒内(使用多达2176个GPU)成功训练了ImageNet/ResNet-50,并在ABCI 集群上没有明显的精度损失。
在ImageNet数据集上训练ResNet-50是用于测量深度学习分布式学习速度的一般行业基准,该研究刷新了这个基准的速度。

论文地址:
https://arxiv.org/pdf/1811.05233.pdf
224秒!刷新深度学习纪录
在大型GPU集群中,大规模分布式深度学习存在两个技术问题。第一个问题large mini-batch训练造成的收敛精度下降。第二个问题是GPU间梯度同步的通信开销。解决这两个问题需要一种新的分布式处理方法。
近年来,许多研究人员提出了多种方案来解决这两个问题(见原文参考文献)。这些工作利用ImageNet/ResNet-50训练来衡量训练效果。ImageNet/ResNet-50分别是最流行的数据集和最流行的DNN模型,用于对大规模分布式深度学习进行基准测试。
表1比较了近期一些工作的训练时间和top-1验证精度。其中,Facebook使用256个Tesla P100 GPU,在1小时内训练完ResNet-50,是加速了这一任务的著名研究。
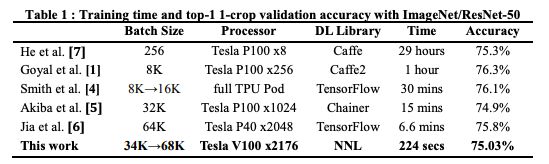
表1:ImageNet/ResNet-50训练时间及top-1 -crop验证精度
之前的其他一些业界最好水平来自:
日本Perferred Network公司Chainer团队,15分钟训练好ResNet-50 [5]
腾讯机智团队,6.6分钟训练好ResNet-50 [6]
索尼团队的研究着重于解决大型mini-batch训练的不稳定性和梯度同步开销,他们使用2176 个Tesla V100 GPU,将训练时间缩短至224秒,验证精度为75.03%。
研究人员还尝试在不造成明显精度损失的情况下提高GPU scaling效率,使用1088个Tesla V100 GPU将GPU scaling效率提高到91.62%(表2)。

表2:ImageNet/ResNet-50训练的GPU scaling 效率
2大方法解决不稳定问题
大规模分布式训练有两个主要问题:大型mini-batch训练的不稳定性和同步通信的开销。
众所周知, large mini-batch训练是不稳定的,会产生泛化差距。
数据并行分布式训练需要在每个训练迭代之间增加一个步骤,以便在参与的GPU之间同步和平均梯度。这个步骤是使用一个all-reduce的集合操作来实现的。在一个大型GPU集群中,all-reduce集合操作的开销使得线性缩放变得非常具有挑战性。
针对这两个问题,我们使用Batch Size控制技术来解决不稳定问题,并开发了2D-Torus all-reducing方案,有效地跨GPU交换梯度。
Batch Size Control
以往的工作已经证明,在训练期间逐渐增加总的mini-batch size可以减少大型 mini-batch训练的不稳定性。直观地说,随着训练的损失情况变得“平坦”而增加批大小有助于避免局部最小值。
在这项工作中,我们采用 Batch Size Control来减少精度下降, batch size超过了32K。在训练期间采用了预定的batch-size来更改调度。
2 D-Torus All- reduce
有效的通信拓扑对于减少集体操作的通信开销至关重要。
为了解决这个问题,我们开发了2D-Torus all-reduce。2D-Torus拓扑结构如图1所示。集群中的GPU排列在2D网格中。在2D-torus拓扑中,all-reduce由三个步骤组成:reduce-scatter,all-reduce和all-gather。
图1:2D-Torus拓扑由水平和垂直方向的多个环组成。
2D-Torus all-reduce的示例如图2所示。
图2:在2x2网格中,一个4-GPU集群的2D-Torus all-reduce步骤
评估:实验设置和训练设置
实验设置
软件:使用神经网络库(NNL)及其CUDA扩展,作为DNN训练框架。通信库使用NCCL和OpenMPI。2D-Torus all-reduce在NCCL上实现。以上软件打包在Singularity容器中,用于运行分布式DNN训练。
硬件:使用AI桥接云基础设施(ABCI)作为GPU集群。ABCI是日本先进工业科技研究所(AIST)运营的GPU集群。它包括1088个节点,每个节点有4个NVIDIA Tesla V100 GPU,2个Xeon Gold 6148处理器,376 GB内存。同一节点的GPU由NVLink互连,而节点由2个InfiniBand EDR互连。
数据集和模型:使用ImageNet数据集。使用ResNet-50作为DNN模型。模型中的所有层都由[9]中描述的值初始化。
训练设置:
使用LARS [9],系数为0.01,eps为1e-6更新权重。学习率(LR)通过以下公式计算:
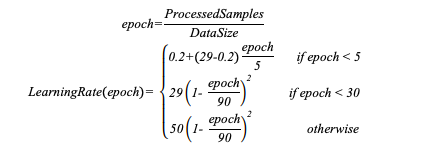
用以下公式计算出总的mini-batch size和学习率。

我们还采用了[15]中介绍的混合精度训练。前向/后向计算和同步梯度的通信在半精度浮点(FP16)中进行。
我们调整每个worker和总batch size,如表3所示,直到将总batch size增到最大。通过增加GPU的数量(Exp.1到Exp.4)来尝试提高最大总batch size。
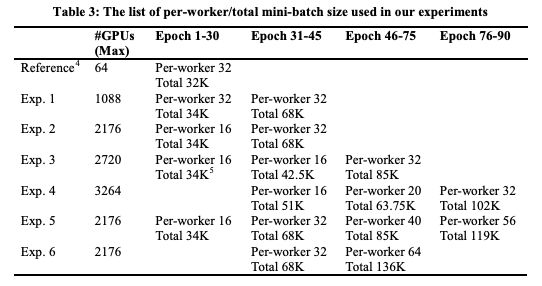
表3:per-worker/total mini-batch size
但是,当使用超过2176个GPU时,训练效率变低了。因此,由于这个问题, Exp. 5 和Exp. 6仅使用2176个GPU。

表4:实验中使用的2D-Torus拓扑的网格尺寸。
结果:精度无损失,训练时间只需224秒
我们在224秒内完成了ResNet-50的训练,没有明显的精度损失,如表5所示。
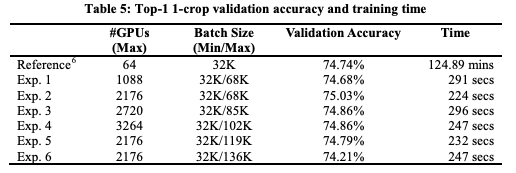
表5:Top-1 1-crop 验证精度和训练时间
训练误差曲线与参考曲线非常相似(图3)。虽然最大的batch size可以增加到119K也不会造成明显的精度损失,但进一步增大会使精度降低约0.5%(表5中的实验6)。
图3:训练误差曲线
我们描述了与单个节点(4个GPU)相比的训练速度和GPU缩放效率。
表6显示了当每个worker的批大小设置为32时的GPU数量和训练吞吐量。虽然当使用超过2176个GPU时,GPU scaling效率降低到70%,但当使用1088 GPU时,scaling效率超过了90%。
在之前的研究[6]中,当使用1024个Tesla P40,每个worker的批大小设置为32时,GPU scaling效率为87.9%。因此,与之前的研究相比,我们的通信方案通过更快、更多的GPU实现了更高的GPU scaling效率。
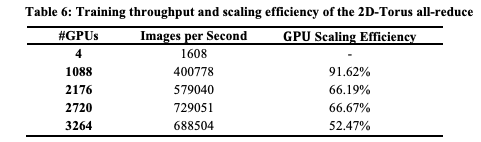
表6:2D-Torus all-reduce的训练吞吐量和scaling效率
结论
大规模分布式深度学习是减少DNN训练时间的有效方法。我们采用了多种技术来减少精度下降,同时在使用一个庞大的GPU集群进行训练的同时保持了较高的GPU scaling效率。
这些技术是用神经网络库(NNL)实现的,我们使用了2176个 Tesla V100 GPU,训练时间224秒,验证精度75.03%。我们还通过1088个Tesla V100 GPU达到了90%以上的GPU扩展效率。
-
一种具有混合精度的高度可扩展的深度学习训练系统2018-08-02 4911
-
一种利用光电容积描记(PPG)信号和深度学习模型对高血压分类的新方法2024-05-11 15689
-
怎样记录10秒内的数据2012-04-20 2744
-
一个benchmark实现大规模数据集上的OOD检测2022-08-31 2252
-
YOLOv6中的用Channel-wise Distillation进行的量化感知训练2022-10-09 4626
-
【CANN训练营第三季】基于Caffe ResNet-50网络实现图片分类2022-12-19 26862
-
富士通实验室在74.7秒内完成了ImageNet上训练ResNet-50网络2019-04-08 5316
-
富士通宣布打破了ImageNet的训练速度记录——在74.7秒内达到75%的准确率2019-04-28 4566
-
如何使用框架训练网络加速深度学习推理2022-04-01 3588
-
MLPerf世界纪录技术分享:优化卷积合并算法提升Resnet50推理性能2022-11-10 2650
-
基于RV1126开发板的resnet50训练部署教程2025-04-18 997
全部0条评论

快来发表一下你的评论吧 !
