

初学者不可错过的分布式机器学习4大知识点 | AI知识科普
今日头条
描述
随着“大数据”概念而兴起的分布式机器学习,在人工智能的新时代里解决了大量最具挑战性的问题。
近几年,机器学习在很多领域取得了空前的成功,也因此彻底改变了人工智能的发展方向。大数据时代的到来一方面促进了机器学习的长足发展,另一方面也给机器学习带来了前所未有的新挑战。
在这些发展与挑战中,分布式机器学习应运而生并成功解决了大量具有挑战性的关键问题,今天晚上班主任就来和同学们聊一聊分布式机器学习起源、流程、算法以及目前流行的分布式机器学习平台。
01
起源:大数据和大模型带来的挑战
在开始聊起源之前,我们先来看张图:
这张图是展示了ImageNet近几年的错误率,2011年的时候错误率还将近有25%,这样的错误率很难运用到实际应用中。到2015年,ImageNet错误率已经降低到3%左右,比人类的错误率(5%)还要低, 短短的4-5年时间,机器在ImageNet上的识别率便超过了人类。
导致这一结果的原因有2个:一是数据,另一个是模型。
大规模训练数据的出现为训练大模型提供了物质基础,大规模机器学习模型具有超强的表达能力,可以解决很多复杂和高难度的问题。
在解决这些问题的同时,大规模机器学习模型也有着非常明显的弊端:包含参数众多,训练耗时;模型巨大,传统的计算机和工作站难以处理;容易过拟合,在训练数据集上表现良好,在未知测试数据上表现不尽人意。
比较典型的例子是电商网站上的用户行为数据,比如在淘宝上很多用户每天都能看到系统推荐的产品,这些产品是根据用户日常浏览和点击习惯进行推荐的,淘宝的服务器将用户点击的产品行为记录下来,作为分布式机器学习系统的输入。输出是一个数学模型,可以预测一个用户喜欢看到哪些商品,从而在下一次展示推荐商品的时候,多展示那些用户喜欢的商品。
类似的,还有互联网广告系统,根据几亿用户的广告点击行为,为其推荐更容易被点击的广告。
淘宝推荐系统大致如图所示
由上述案例可以知,现在我们很难用一台计算机去处理工业规模的机器学习模型了,所以说分布式训练已经成为了一个先决条件。
流程:了解-探索-设计
分布式机器学习说白了,其实就是把任务发放给许多机器,然后让它们协同去帮忙训练数据和模型。
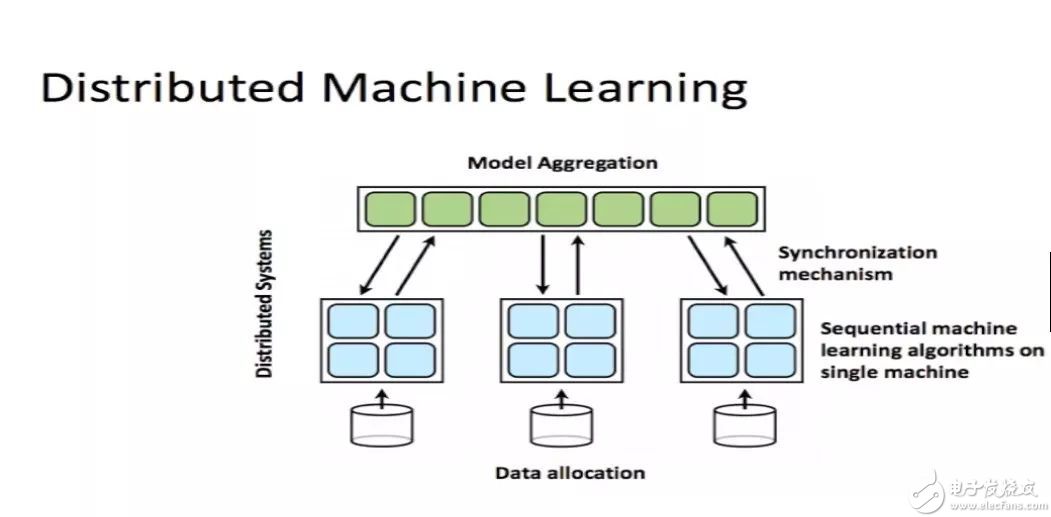
如图所示,我们会把任务下发给许多的worker,然后这些worker协同的去训练模型。
通过对分布式机器学习起源的讲解,我们可以将分布式机器学习的使用场景粗分为三类:计算量太大、训练数据太多、训练模型太大太过复杂。
这三种场景都有相对应的解决办法,对于计算量太大可采用共享内存的多机并行运算;对于训练数据太多,可以将数据进行划分,分配到多个工作节点上进行训练;而对于训练模型太大,也可以将模型进行划分,分配到不同的工作节点上进行训练。
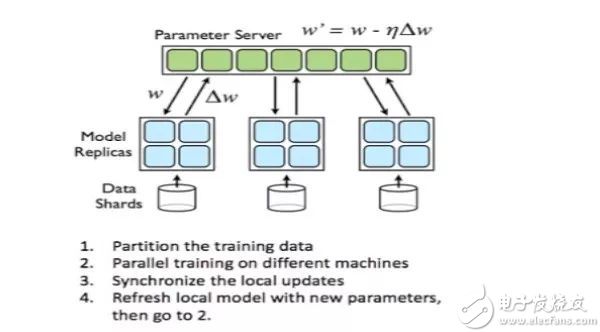
不管是以上场景中的哪一种,还是几种场景混合在一起的情况,分布式机器学习都可以分为三步流程:
第一步是了解机器学习的模型以及优化方法;第二步是要去探索分布式机器学习的范式;第三步是设计系统,无论系统的设计者还是系统的使用者,都要知道系统为什么要这样设计,这样设计对我们选择什么样的机器学习有怎样的帮助。
算法:数据并行、模型并行、梯度下降
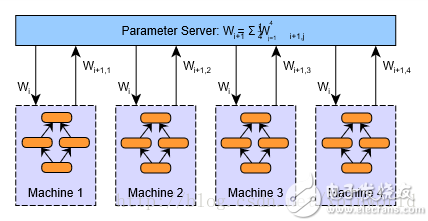
数据并行
数据并行是指由于训练样本非常多模型非常大,我们需要把训练数据划分到不同的机器上,比如说我们用100台机器同时存储这些数据,如果这些模型有10万个数据样,用100台机器来存储,每台机器存储1000条数据即可。
对于每一台worker来说,训练算法、分布式和在单机上没有什么区别,只是需要在节点之间同步模型参数。
其中参数平均是最简单的一种数据并行化。若采用参数平均法,训练的过程如下所示:
1、基于模型的配置随机初始化网络模型参数
2、将当前这组参数分发到各个工作节点
3、在每个工作节点,用数据集的一部分数据进行训练
4、将各个工作节点的参数的均值作为全局参数值
5、若还有训练数据没有参与训练,则继续从第二步开始
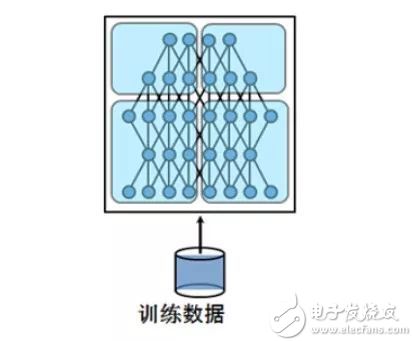
模型并行
模型并行将模型拆分成几个分片,由几个训练单元分别持有,共同协作完成训练。
深度学习的计算其实主要是矩阵运算,而在计算时这些矩阵都是保存在内存里的,如果是用GPU卡计算的话就是放在显存里,可是有的时候矩阵会非常大。面对这种超大矩阵便需要将其拆分,分到不同处理器上去计算。
梯度下降
1847年梯度下降被提出来之后,这些年业内提出了各种各样的优化算法,优化算法是一个非常漫长的演变过程。

大家可以看到图中有一条分界线, 在2010之前的算法主要是Deterministic algorithms,这种算法具有很强确定性。换句话说,就是可以在数学上保证此算法进行的每一步都是精确的,能够指导我们的优化目标。
2010年之后的这些模型被称做stochastic algorithms,不再要求每一步都是精确的梯度下降,或者每一步要做最精确的优化。stochastic algorithms让每一步只进行随机的优化,最终把所有数据优化完以后,还是能够优化到最低点。
随着数据越来越大,Deterministic algorithms规则已经越来变得越来越不适用了。对于大量的计算数据,我们不可能每一次都做梯度下降,随机梯度下降变得越来越有优势,资源利用率也会更高。
04
分布式机器学习三大平台:Spark、PMLS、TensorFlow
在纽约州立大学布法罗分校计算机科学与工程教授、Petuum Inc. 顾问 Murat Demirbas 和他的两位学生一起发表的那篇对比现有分布式机器学习平台的论文中,将分布式机器学习平台归类为了三大基本设计方法:
1.基本数据流(basic dataflow)
2.参数服务器模型(parameter-server model)
3.先进数据流(advanced dataflow)
并根据这三大基本设计方法,使用了业内著名的三大分布式机器学习平台,其中基本数据流方法使用了 Apache Spark、参数服务器模型使用了 PMLS(Petuum)、先进数据流模型使用了 TensorFlow 和 MXNet。
并在测试中得出相应的结论,班主任摘取关键部分出来,供大家参考(论文原文可访问:https://www.cse.buffalo.edu/~demirbas/publications/DistMLplat.pdf,译文参考网络翻译)
Spark
在基本的设置中,Spark 将模型参数存储在驱动器节点,工作器与驱动器通信从而在每次迭代后更新这些参数。对于大规模部署而言,这些模型参数可能并不适合驱动器,并且会作为一个 RDD 而进行维护更新。
这会带来大量额外开销,因为每次迭代都需要创造一个新的 RDD 来保存更新后的模型参数。更新模型涉及到在整个机器/磁盘上重排数据,这就限制了 Spark 的扩展性。
PMLS
PMLS节点会存储和更新模型参数以及响应来自工作器的请求。工作器会请求来自它们的局部 PS 副本的最新模型参数,并在分配给它们的数据集部分上执行计算。
PMLS还采用了 SSP(Stale Synchronous Parallelism)模型,这比 BSP(Bulk Synchronous Parellelism)模型更宽松——其中工作器在每次迭代结束时同步。SSP 为工作器的同步减少了麻烦,确保最快的工作器不能超过最慢的工作器 s 次迭代。
TensorFlow
TensorFlow使用节点和边的有向图来表示计算。节点表示计算,状态可变。而边则表示多维数据数组(张量),在节点之间传输。
TensorFlow 需要用户静态声明这种符号计算图,并对该图使用复写和分区(rewrite& partitioning)将其分配到机器上进行分布式执行。(MXNet,尤其是 DyNet 使用了图的动态声明,这改善了编程的难度和灵活性。)

- 相关推荐
- 热点推荐
-
嵌入式Linux初学者要了解哪些知识呢2021-11-04 1431
-
嵌入式Linux初学者必须要知道的知识点2021-11-01 646
-
学习STM32F407的必备知识点电源,复位和时钟系统2021-08-10 1502
-
嵌入式知识点总结2021-07-30 1608
-
java编程入门教程之学习Java编程语言需要掌握的4大知识点2018-09-18 915
-
初学者AVR软件入门基础知识(2)2018-07-04 3066
-
九张机器学习和深度学习代码速查表分享_初学者必备2018-06-30 4687
-
初学者怎样学好电子知识2017-03-19 5634
-
模电主要知识点及计算方法2015-12-14 2529
-
初学者需要具备哪些理论知识2013-09-27 2425
-
PCB Layout初学者必会知识总结2012-07-04 6147
-
初学者之路—硬件学习经验2011-12-29 14741
全部0条评论

快来发表一下你的评论吧 !
