

浅析AI芯片和传统芯片的不同之处
电子说
描述
所谓的AI芯片,一般是指针对AI算法的ASIC(专用芯片)。传统的CPU、GPU都可以拿来执行AI算法,但是速度慢,性能低,无法实际商用。
比如,自动驾驶需要识别道路行人红绿灯等状况,但是如果是当前的CPU去算,那么估计车翻到河里了还没发现前方是河,这是速度慢,时间就是生命。如果用GPU,的确速度要快得多,但是,功耗大,汽车的电池估计无法长时间支撑正常使用,而且,老黄家的GPU巨贵,经常单块上万,普通消费者也用不起,还经常缺货。另外,GPU因为不是专门针对AI算法开发的ASIC,所以,说到底,速度还没到极限,还有提升空间。而类似智能驾驶这样的领域,必须快!在手机终端,可以自行人脸识别、语音识别等AI应用,这个必须功耗低,所以GPU OUT!
所以,开发ASIC就成了必然。
说说,为什么需要AI芯片。
AI算法,在图像识别等领域,常用的是CNN卷积网络,语音识别、自然语言处理等领域,主要是RNN,这是两类有区别的算法。但是,他们本质上,都是矩阵或vector的乘法、加法,然后配合一些除法、指数等算法。
一个成熟的AI算法,比如YOLO-V3,就是大量的卷积、残差网络、全连接等类型的计算,本质是乘法和加法。对于YOLO-V3来说,如果确定了具体的输入图形尺寸,那么总的乘法加法计算次数是确定的。比如一万亿次。(真实的情况比这个大得多的多)
那么要快速执行一次YOLO-V3,就必须执行完一万亿次的加法乘法次数。
这个时候就来看了,比如IBM的POWER8,最先进的服务器用超标量CPU之一,4GHz,SIMD,128bit,假设是处理16bit的数据,那就是8个数,那么一个周期,最多执行8个乘加计算。一次最多执行16个操作。这还是理论上,其实是不大可能的。
那么CPU一秒钟的巅峰计算次数=16X4Gops=64Gops。
这样,可以算算CPU计算一次的时间了。
同样的,换成GPU算算,也能知道执行时间。因为对GPU内部结构不熟,所以不做具体分析。
再来说说AI芯片。比如大名鼎鼎的谷歌的TPU1。
TPU1,大约700M Hz,有256X256尺寸的脉动阵列,如下图所示。一共256X256=64K个乘加单元,每个单元一次可执行一个乘法和一个加法。那就是128K个操作。(乘法算一个,加法再算一个)
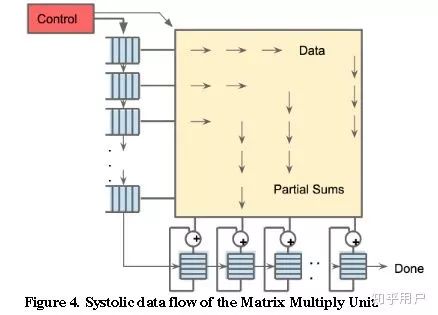
另外,除了脉动阵列,还有其他模块,比如激活等,这些里面也有乘法、加法等。
所以,看看TPU1一秒钟的巅峰计算次数至少是=128K X 700MHz=89600Gops=大约90Tops。
对比一下CPU与TPU1,会发现计算能力有几个数量级的差距,这就是为啥说CPU慢。
当然,以上的数据都是完全最理想的理论值,实际情况,能够达到5%吧。因为,芯片上的存储不够大,所以数据会存储在DRAM中,从DRAM取数据很慢的,所以,乘法逻辑往往要等待。另外,AI算法有许多层网络组成,必须一层一层的算,所以,在切换层的时候,乘法逻辑又是休息的,所以,诸多因素造成了实际的芯片并不能达到利润的计算峰值,而且差距还极大。
可能有人要说,搞研究慢一点也能将就用。
目前来看,神经网络的尺寸是越来越大,参数越来越多,遇到大型NN模型,训练需要花几周甚至一两个月的时候,你会耐心等待么?突然断电,一切重来?(曾经动手训练一个写小说的AI,然后,一次训练(50轮)需要大约一天一夜还多,记得如果第一天早上开始训练,需要到第二天下午才可能完成,这还是模型比较简单,数据只有几万条的小模型呀。)
修改了模型,需要几个星期才能知道对错,确定等得起?
突然有了TPU,然后你发现,吃个午饭回来就好了,参数优化一下,继续跑,多么爽!
计算速度快,才能迅速反复迭代,研发出更强的AI模型。速度就是金钱。
GPU的内核结构不清楚,所以就不比较了。肯定的是,GPU还是比较快的,至少比CPU快得多,所以目前大多数都用GPU,这玩意随便一个都能价格轻松上万,太贵,而且,功耗高,经常缺货。不适合数据中心大量使用。
总的来说,CPU与GPU并不是AI专用芯片,为了实现其他功能,内部有大量其他逻辑,而这些逻辑对于目前的AI算法来说是完全用不上的,所以,自然造成CPU与GPU并不能达到最优的性价比。
谷歌花钱研发TPU,而且目前已经出了TPU3,用得还挺欢,都开始支持谷歌云计算服务了,貌似6点几美元每小时吧,不记得单位了,懒得查.
可见,谷歌觉得很有必要自己研发TPU。
就酱。
看到有答案点我名说不应该用CPU做对比,这个锅我不背。
做一点解释。
目前在图像识别、语音识别、自然语言处理等领域,精度最高的算法就是基于深度学习的,传统的机器学习的计算精度已经被超越,目前应用最广的算法,估计非深度学习莫属,而且,传统机器学习的计算量与 深度学习比起来少很多,所以,我讨论AI芯片时就针对计算量特别大的深度学习而言。毕竟,计算量小的算法,说实话,CPU已经很快了。而且,CPU适合执行调度复杂的算法,这一点是GPU与AI芯片都做不到的,所以他们三者只是针对不同的应用场景而已,都有各自的主场。
至于为何用了CPU做对比?
而没有具体说GPU。是因为,我说了,我目前没有系统查看过GPU的论文,不了解GPU的情况,故不做分析。因为积累的缘故,比较熟悉超标量CPU,所以就用熟悉的CPU做详细比较。而且,小型的网络,完全可以用CPU去训练,没啥大问题,最多慢一点。只要不是太大的网络模型。
那些AI算法公司,比如旷世、商汤等,他们的模型很大,自然也不是一块GPU就能搞定的。GPU的算力也是很有限的。
至于说CPU是串行,GPU是并行。
没错,但是不全面。只说说CPU串行。这位网友估计对CPU没有非常深入的理解。我的回答中举的CPU是IBM的POWER8,百度一下就知道,这是超标量的服务器用CPU,目前来看,性能已经是非常顶级的了,主频4GHZ。不知是否注意到我说了这是SIMD?这个SIMD,就代表他可以同时执行多条同样的指令,这就是并行,而不是串行。单个数据是128bit的,如果是16bit的精度,那么一周期理论上最多可以计算八组数据的乘法或加法,或者乘加。这还不叫并行?只是并行的程度没有GPU那么厉害而已,但是,这也是并行。
不知道为啥就不能用CPU来比较算力?
有评论很推崇GPU。说用CPU来做比较,不合适。
拜托,GPU本来是从CPU中分离出来专门处理图像计算的,也就是说,GPU是专门处理图像计算的。包括各种特效的显示。这也是GPU的天生的缺陷,GPU更加针对图像的渲染等计算算法。但是,这些算法,与深度学习的算法还是有比较大的区别,而我的回答里提到的AI芯片,比如TPU,这个是专门针对CNN等典型深度学习算法而开发的。另外,寒武纪的NPU,也是专门针对神经网络的,与TPU类似。
谷歌的TPU,寒武纪的DianNao,这些AI芯片刚出道的时候,就是用CPU/GPU来对比的。
无图无真相,是吧?
看看,谷歌TPU论文的摘要直接对比了TPU1与CPU/GPU的性能比较结果,见红色框:

看不清?
没事,放大。

这就是摘要中介绍的TPU1与CPU/GPU的性能对比。
再来看看寒武纪DianNao的paper,摘要中直接就是DianNao与CPU的性能的比较,见红色框:

回顾一下历史。
上个世纪出现神经网络的时候,那一定是用CPU计算的。
比特币刚出来,那也是用CPU在挖。目前已经进化成ASIC矿机了。比特大陆了解一下。
从2006年开始开启的深度学习热潮,CPU与GPU都能计算,发现GPU速度更快,但是贵啊,更多用的是CPU,而且,那时候GPU的CUDA可还不怎么样,后来,随着NN模型越来越大,GPU的优势越来越明显,CUDA也越来越6,目前就成了GPU的专场。
寒武纪2014年的DianNao(NPU)比CPU快,而且更加节能。ASIC的优势很明显啊。这也是为啥要开发ASIC的理由。
至于说很多公司的方案是可编程的,也就是大多数与FPGA配合。你说的是商汤、深鉴么?的确,他们发表的论文,就是基于FPGA的。
这些创业公司,他们更多研究的是算法,至于芯片,还不是重点,另外,他们暂时还没有那个精力与实力。FPGA非常灵活,成本不高,可以很快实现架构设计原型,所以他们自然会选择基于FPGA的方案。不过,最近他们都大力融资,官网也在招聘芯片设计岗位,所以,应该也在涉足ASIC研发了。
如果以FPGA为代表的可编程方案真的有巨大的商业价值,那他们何必砸钱去做ASIC?
-
C语言指针和引用的不同之处及使用场合2023-06-14 581
-
AI芯片哪里买?芯广场 2024-05-31
-
数字舵机与模拟舵机有哪些不同之处2021-08-23 3077
-
STM32板与FPGA有哪些不同之处呢2021-10-09 1786
-
GD32和STM32有哪些不同之处2021-10-19 2485
-
USART与USAR有哪些不同之处呢2021-12-13 2547
-
RK3399Pro与AR9201处理器内核有哪些不同之处2022-02-14 1431
-
LDO-DCDC-Charge-Pump的原理比较与不同之处2017-11-27 3659
-
AI芯片的架构和传统芯片有什么不同?2018-08-01 12693
-
AI芯片和传统芯片到底有什么区别2019-12-21 9020
-
ai芯片和传统芯片的区别2023-08-08 7840
-
贴片Y电容内部构造是什么样子的,和传统插件Y电容有什么不同之处?2023-08-27 2700
-
科普语音芯片和语音合成芯片的不同之处2023-10-31 1225
-
噪音抑制与主动降噪:有何不同之处?2023-11-30 1485
-
智能制造与传统制造有什么不同之处2024-06-07 5276
全部0条评论

快来发表一下你的评论吧 !
