

Reaver在《星际争霸 II》各种小型游戏上与其他AI的性能对比
电子说
描述
如果说我们的征途是星辰大海,那么星际争霸必定是其中一关。今天,有人在Github开源了他潜心研究一年半的成果,一个新手和资深研究人员都能受益的深度强化学习框架,单机运行速度快、方便调式,支持多种强化学习训练环境。
上周结束的 AI Challenger 星际争霸竞赛,让 AI 挑战星际争霸这个议题又稍稍火了一把。虽然这届冠军使用的仍然是硬编码方法,但从其他解决方案中不难看出,AI算法的占比在不断提升。
作为围棋之后 DeepMind 公开宣布的下一个攻克目标,《星际争霸》的魅力可见一斑。而随后不久 DeepMind 便将其相关研究及平台开源,更是印证了让 AI 玩星际争霸的挑战。
今天,塔尔图大学的 Roman Ring 在 Github 上开源了他倾力投入一年半的成果,一个名叫 Reaver 的《星际争霸 II》AI,可用于训练《星际争霸 II》的各种基本任务。
Reaver 的基本思路是沿着 DeepMind 的路线在走,也即 AI 的玩法是像人类玩家一样,从游戏画面中获取视觉特征,然后再做出决策。
补充说明,Roman 去年本科毕业项目是使用《Actor-Critic 法复现 DeepMind 星际争霸 II 强化学习基准》[1],Reaver 则是在此基础上的改善提升。
Reaver 的强项在于比其他开源的同类框架单机运行速度快;除了支持星际争霸游戏训练环境 SC2LE,也支持 OpenAI Gym、ATARI 和 MUJOCO;模块化组成,容易调试。
根据作者所说,Reaver 不到10 秒就解决 CartPole-v0,在 4 核 CPU 笔记本上每秒处理 5000 张图像,使用 Google Colab,Reaver 通关《星际争霸 II》SC2LE 小型游戏 MoveToBeacon 只需要半小时的时间。
Reaver 玩《星际争霸 II》小型游戏 MoveToBeacon 的画面,左边是未经训练,右边是训练后的情况。来源:Roman Ring/YouTube
套用一句话,如果我们的征途是星辰大海,那么其中的一关必然是《星际争霸》。
Reaver 对于不具备 GPU 集群的人非常友好,正如作者在 Github 库里介绍所说,
“虽然开发是研究驱动的,但 Reaver API 背后的理念类似于《星际争霸II》游戏本身——新手可以用,领域专家也能从中获得东西。
“对于业余爱好者而言,只要对 Reaver 稍作修改(例如超参数),就能得到训练深度强化学习智能体的所有必须工具。对于经验丰富的研究人员,Reaver 提供简单但性能优化的代码库,而且都是模块化架构:智能体、模型和环境都是分开,并且可以随意组合调换。”
欢迎加入星际争霸强化学习阵营。
深度强化学习AI Reaver:模块化且便于调试
性能 大部分已发表的强化学习基准通常针对的都是 MPI 之间 message-based 通信,对于 DeepMind 或者 OpenAI 这样有大规模分布式强化学习配置的机构而言这样做自然很合理,但对于普通研究者或其他没有这类强大基础设施的人,这就成了很大的瓶颈。因此,Roman Ring 采用了共享内存(shared memory)的方法,相比 message-based 并行的解决方案实现了大约 3 倍的速度提升。
模块化 很多强化学习基准都或多或少都是模块化的,不过这些基准通常与作者使用的训练环境密切相关。Roman Ring 自己就曾经因为专注于《星际争霸 II》环境而导致调试花了很长时间。因此,Revar 只需要一个命令行就能改变训练环境,从 SC2 到 Atari 或者 CartPole(将来计划纳入 VizDoom)。每个神经网络都是简单的 Keras 模型,只要符合基本的 API contracts 都能调用。
调试 现在一个游戏 AI 通常含有十几个不同的调试参数,如何实现更为统一便捷的调试?Roman Ring 在 Reaver 中只要能用的地方都用了 “gin-config”,这个轻量级调试框架只要是 Python 可调用函数都能调试,非常方便。
更新 是的,现在算法发展很快,去年发表的东西今年就可能过时。在开发 Reaver 的时候 Roman 表示他想着用了 TensorFlow 2.0 API(主要是使用 tf.keras 不用 tf.contrib),希望这个库能活用久一点吧。
单机友好,可用于训练星际争霸II各种任务
Roman Ring 列出了 Reaver 在《星际争霸 II》各种小型游戏上与其他 AI 的性能对比。其中,
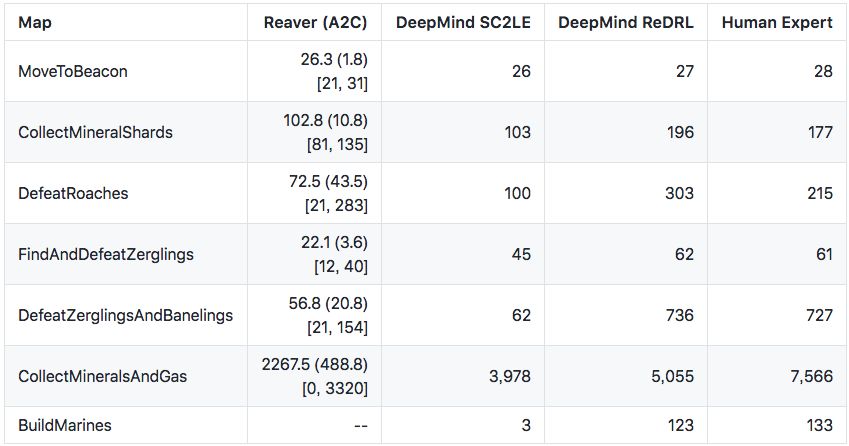
Reaver(A2C)就是在 SC2LE 训练 Reaver 得到的结果
DeepMind SC2LE 是 DeepMind 在《StarCraft II: A New Challenge for Reinforcement Learning》一文中发布的结果[2]
DeepMind ReDRL 则是 DeepMind 在《Relational Deep Reinforcement Learning》中的结果[3]
人类专家是 DeepMind 收集的 GrandMaster 级别人类玩家的结果
以下是 Reaver 在不同小型游戏中训练花费的时间:
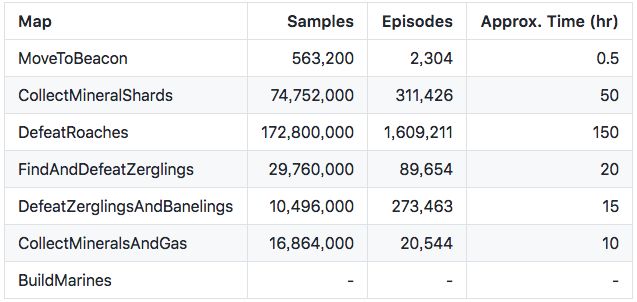
综上,就算 DefeatRoaches 花了 150 小时,但考虑到硬件只是一台笔记本(英特尔酷睿 i5-7300HQ,4核 + GTX 1050 GPU),这个结果已经算很不错。
Roman 还列出了他的路线图,上述成果只是他万里长征的第一步。如果你感兴趣,不妨加入这个项目。
-
星际争霸1.152下载2008-01-22 865
-
NIOS_II_各种性能表格2015-12-21 792
-
看后有点感动 让人惊艳!4K版《星际争霸》配置要求公布:亲民2017-07-03 1064
-
区块链的视频游戏开发还存在哪些障碍?2018-09-18 1533
-
如何让AI符合人类的意图?如何创建符合用户意图的智能体?2018-11-24 5020
-
AlphaStar横空出世 星际争霸2人类1:10输给AI2019-01-25 3919
-
一天等于两百年?人工智能在星际争霸2上向人类发出挑战2019-07-29 1360
-
为什么DeepMind的科学家们对星际争霸如此痴迷2019-01-29 4736
-
DeepMind在伦敦向世界展示了他们的最新成果——星际争霸2人工智能AlphaStar2019-01-30 6291
-
两位研究人员近日推出了本年度的State AI 2019全景报告2019-07-07 4484
-
用AI打星际有多“硬核”?难点和挑战在哪?2019-09-13 3810
-
Llama 3 模型与其他AI工具对比2024-10-27 1998
-
TNC连接器对比分析:与其他射频连接器的性能对决2024-12-17 2256
-
铝电解电容与其他电容类型的性能对比2025-08-07 2691
全部0条评论

快来发表一下你的评论吧 !
