

微软亚洲研究院视觉计算组又一个令人拍案叫绝的操作
电子说
描述
微软亚洲研究院视觉计算组又一个令人拍案叫绝的操作:可变形卷积网络v2版!DCNv2方法简单,结果更好,在COCO基准测试中比上个版本提升了5个点。
同样的物体在图像中可能呈现出不同的大小、姿态、视角变化甚至非刚体形变,如何适应这些复杂的几何形变是物体识别的主要难点,也是计算机视觉领域多年来关注的核心问题。
去年,微软亚洲研究院视觉计算组提出了 “Deformable Convolutional Networks”(可变形卷积网络),首次在卷积神经网络(CNN)中引入了学习空间几何形变的能力,得到可变形卷积网络(Deformable ConvNets),从而更好地解决了具有空间形变的图像识别任务。
通俗地说,图像中的物体形状本来就是千奇百怪,方框型的卷积核,即使卷积多次反卷积回去仍然是方框,不能真实表达物体的形状,如果卷积核的形状是可以变化的,这样卷积后反卷积回去就可以形成一个多边形,更贴切的表达物体形状,从而可以更好地进行图像分割和物体检测。
研究员们通过大量的实验结果验证了该方法在复杂的计算机视觉任务(如目标检测和语义分割)上的有效性,首次表明在深度卷积神经网络(deep CNN)中学习空间上密集的几何形变是可行的。
但这个Deformable ConvNets也有缺陷,例如,激活单元的样本倾向于集中在其所在对象的周围。然而,对象的覆盖是不精确的,显示出超出感兴趣区域的样本的扩散。在使用更具挑战性的COCO数据集进行分析时,研究人员发现这种倾向更加明显。这些研究结果表明,学习可变形卷积还有更大的可能性。
昨天,MSRA视觉组发布可变形卷积网络的升级版本:Deformable ConvNets v2 (DCNv2),论文标题也相当简单粗暴:更加可变形,更好的结果!
论文地址:
https://arxiv.org/pdf/1811.11168.pdf
DCNv2具有更强的学习可变形卷积的建模能力,体现在两种互补的形式:
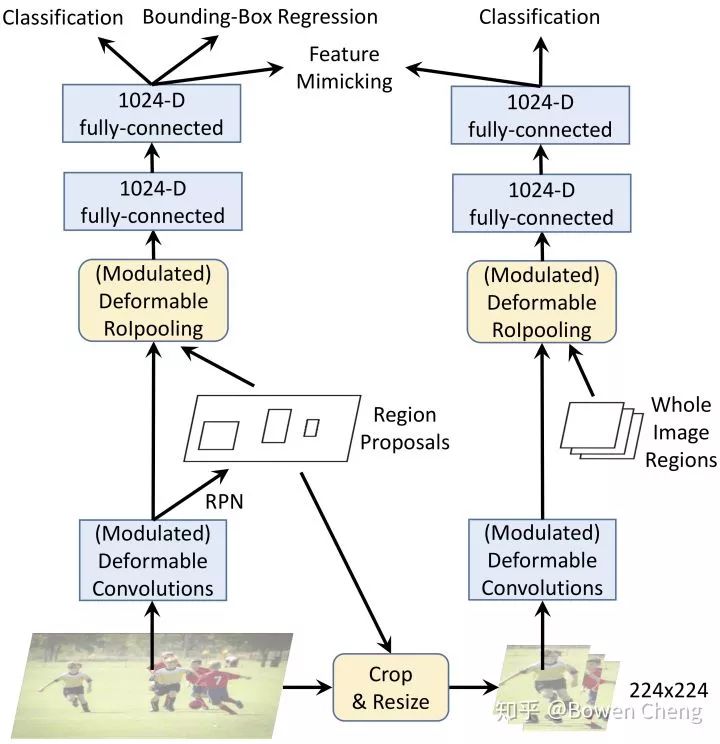
第一种是网络中可变形卷积层的扩展使用。配备具有offset学习能力的更多卷积层允许DCNv2在更广泛的特征级别上控制采样。
第二种是可变形卷积模块中的调制机制,其中每个样本不仅经过一个学习的offset,而且还被一个学习特征调制。因此,网络模块能够改变其样本的空间分布和相对影响。
为了充分利用DCNv2增强的建模能力,需要进行有效的训练。受神经网络的knowledge distillation这一工作的启发,我们利用教师网络来实现这一目的,教师在训练期间提供指导。
具体来说,我们利用R-CNN作为教师网络。由于它是训练用于对裁剪图像内容进行分类的网络,因此R-CNN学习的特征不受感兴趣区域之外无关信息的影响。为了模仿这个属性,DCNv2在其训练中加入了一个特征模拟损失,这有利于学习与R-CNN一致的特征。通过这种方式,DCNv2得到强大的训练信号,用于增强可变形采样。
通过这些改变,可变形模块仍然是轻量级的,并且可以容易地结合到现有网络架构中。
具体而言,我们将DCNv2合并到Faster R-CNN 和Mask R-CNN 系统,并具有各种backbone网络。在COCO基准测试上的大量实验证明了DCNv2相对于DCNv1在物体检测和实例分割方面都有显着改进。
我们将在不久后发布DCNv2的代码。
图1:常规ConvNet、DCNv1以及DCNv2中conv5 stage最后一层节点的空间支持。
图3:利用R-CNN feature mimicking的训练
结果
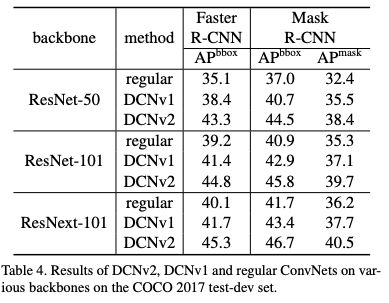
表4:COCO 2017 test-dev set 中各种backbones上的DCNv2、DCNv1和regular ConvNets的结果。
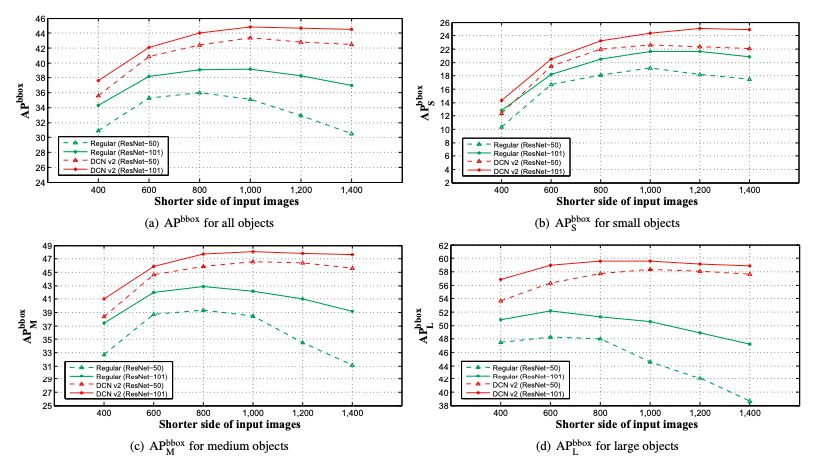
图4:在COCO 2017 test-dev set不同分辨率的输入图像上,DCNv2和regular ConvNets(Faster R-CNN + ResNet-50 / ResNet-101)的APbbox分数。
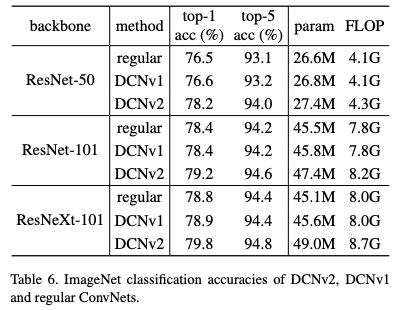
表6:DCNv2、DCNv1和regular ConvNets的ImageNet分类准确度。
可以看到,Deformable ConvNets v2的结果相当亮眼!下面,我们精选了两篇业内对这篇论文的评价,经授权发布:
业界良心DCNV2:方法简单,结果好,分析充分
知乎用户Bowen Cheng的评价:
一周前就听说 Jifeng 组做出了 Deformable ConvNet V2(DCNV2),今天 Jifeng 告诉我 paper 已经挂 ArXiv 上之后果断放下所有事把这篇 paper 好好读了读。感觉这个工作特别 solid,果然没有让人失望。下面简单谈谈个人对这篇 paper 的理解,可能有不对的地方请大家多多指点!
DCNV2 首先用了更好的 visualization 来更深入的理解 DCNV1 为什么 work 以及还存在什么缺陷,发现存在的问题就是因为 offset 不可控导致引入了过多的 context,而这些 context 可能是有害的([1]和 [2] 中也说明了这些 context 可能是有害的)。
解决方法也很简单粗暴:
(1) 增加更多的 Deformable Convolution
(2)让 Deformable Conv 不仅能学习 offset,还能学习每个采样点的权重(modulation)
(3)模拟 R-CNN 的 feature(knowledge distillation)
(1) 就不用说了,在 DCNV1 中只有 ResNet 的 Conv5 stage 中有 Deformable Conv,在 DCNV2 中把 Conv3-Conv5 的 3x3 convolution 都换成了 Deformable Conv
(2) 在 DCNV1 里,Deformable Conv 只学习 offset:
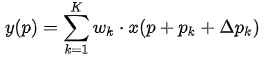
而在 DCNV2 中,加入了对每个采样点的权重:
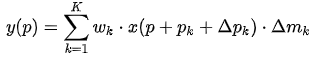
其中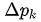 是学到的 offset,
是学到的 offset,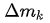 是学到的权重。这样的好处是增加了更大的自由度,对于某些不想要的采样点权重可以学成 0。
是学到的权重。这样的好处是增加了更大的自由度,对于某些不想要的采样点权重可以学成 0。
(3) [1] 中作者(好吧,其实作者是我)发现把 R-CNN 和 Faster RCNN 的 classification score 结合起来可以提升 performance,说明 R-CNN 学到的 focus 在物体上的 feature 可以解决 redundant context 的问题。但是增加额外的 R-CNN 会使 inference 速度变慢很多。DCNV2 里的解决方法是把 R-CNN 当做 teacher network,让 DCNV2 的 ROIPooling 之后的 feature 去模拟 R-CNN 的 feature。(图里画的很清楚了)
其中 feature mimic 的 loss 定义是:
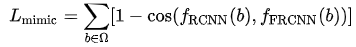
在 end-to-end train 的时候这个 loss 给了一个 0.1 的 weight。
实验结果大家看 paper 就好了,在 ResNet-50 backbone COCO 上跟 DCNV1 比涨了 5 个点!这比目前大部分 detection paper 靠东拼西凑涨的那一两个点要强多了。我惊讶的是和 DCNV1 对比,在 image classification 上也有很大的提升。
说说自己的想法吧,DCNV2 方法简单,结果好,分析充分,我觉得和近期各种 detection paper 比算是业界良心了。我觉得还有可以学习的一点就是 context 的问题。很多 detection 的 paper 都在引入 context(大家都 claim 说小物体需要引入 context 来解决),其实我个人觉得有点在扯淡,物体小最直接的方法难道不是放大物体来解决吗?比如 SNIP/SNIPER 都是在 “放大” 物体。所以在 context 这个问题上我(详情见 [1] 和[2])跟 Jifeng 他们的看法是一样的,我们也许不需要那么多没用的 context。作者都是熟人,我也不多吹了,反正我是准备去 follow 这个工作了哈哈。
最后说说 DCN 有一个小缺点,其实就是速度的问题。因为没有 cudnn 的加速,DCN 完全是靠 im2col 实现的(从目前的 MXNet 版本来看是这样的),当 batchsize 大的时候我感觉速度会比有 cudnn 加速的 3x3 conv 慢。很好奇当 batchsize 大的时候(比如 ImageNet)的 training 时间会慢多少。希望以后能和 dilated convolution 一样被加到 cudnn 里支持吧。
发现好多人好像没有看过 [1][2],放张 network 的图(宣传一下自己的工作),DCN V2 的 mimic R-CNN 和 DCR V1 的结构类似,但是通过 knowledge distillation 很巧妙的在 inference 阶段把 R-CNN 给去掉了。
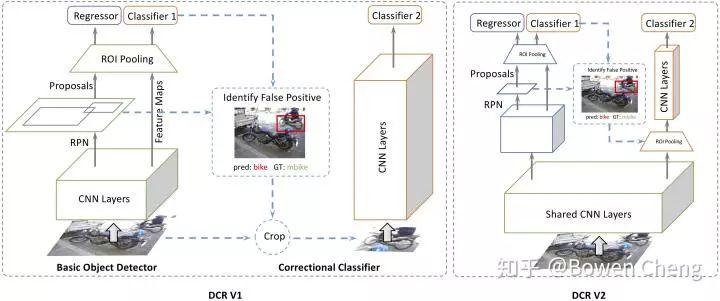
[1] Revisiting RCNN: On Awakening the Classification Power of Faster RCNN
[2] Decoupled Classification Refinement: Hard False Positive Suppression for Object Detection
创新性与性能双赢,COCO涨了5个点!
知乎用户孔涛的评价:
首先祭出结论,这是一篇干货满满,novelty 和 performance 双赢的 paper (COCO 直接涨了~ 5 个点啊)。
自己一直在做 object detection 相关的工作,再加上之前在 MSRA 跟 Jifeng 及 CV 组的小伙伴共事过一段时间,努力给出客观的评价吧。
从 Deform ConvNet V1 说起
目标检测中有一个比较棘手的问题,即所谓的几何形变问题(Geometric variations)。就拿人检测来讲,人的姿态有多种多样(想想跳舞的场景),这就需要我们设计的模型具备 deformation 的能力。通常情况下为了解决这类问题有两种思路:(a) 收集更多样的数据用于模型的训练;(b) 设计 transformation invariant 的特征来提升模型多样化能力。
Deform ConvNet 是在卷积神经网络的框架下,对 transformation-invariant feature 的比较成功的尝试。思想非常直观,在标准的卷积核上加入了可学习的 offset,使得原来方方正正的卷积核具备了形变的能力。
deformable convolution
用过的童鞋其实都知道,在大型的 object detection/instance segmentation 任务上的表现还蛮抢眼的。
Deform ConvNet V2 在干啥
我认为,Deform ConvNet 是在解决如何让学到的 offset 能更聚焦到感兴趣的物体上边,也就是提取到更聚焦的 feature 来帮助物体的识别定位。在下边的图片中,我们当然希望模型的 feature 能够聚焦到物体上边,这样才能提取到更有意义的 supporting feature。
为了做到这一点,作者主要用了几种策略:
(a) 增加更多的 offset 层,这个不必细说;
(b) 在 deform convolution 中引入调节项 (modulation),这样既学到了 offset,又有了每个位置的重要性信息;
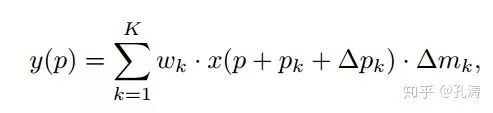
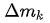
(c) Feature Mimicking,作者强调,简单在对应的 feature 上用 roi-pooling 来提取对应位置的 feature 并不一定能提取到最有用的信息(可能包含无用的 context)。如何才能让 feature 更加聚焦到物体上呢?解决就是 Mimicking 技术,让 roi-pooling 之后的 feature 更像直接用 R-CNN 学到的 feature。
其他
除了漂亮的结果,我觉得 paper 的可视化分析部分也挺值得好好看看的。
另外很难理解为什么 Feature Mimicking 在 regular Faster R-CNN 上不 work。
从最近的一些 paper 结果看,至少目前在 deep 的框架下,针对 task,让模型提取更加有意义的 feature 是个比较热 / 好的方向吧。
-
令人叫绝的极简手机喇叭扩音器2012-12-05 12114
-
中马研究院正式挂牌成立2016-01-07 3805
-
令人拍案叫绝的深圳创客周那些智能机器人2015-06-19 10683
-
人工智能方向在哪里?看微软亚洲研究院四任院长的建言2016-11-17 1435
-
微软将在上海设立微软亚洲研究院2018-09-19 6569
-
微软亚洲研究院被誉为AI黄埔军校,覆盖了国内高科技领导的半壁江山2018-11-06 5652
-
微软亚洲研究院"创新汇": AI为数字化转型注入动能2019-06-29 753
-
微软亚洲研究院开发出了一种超级凤凰人工智能系统2020-04-15 1550
-
又一老牌高校推出AI研究院!2020-10-23 2695
-
微软亚洲研究院的研究员们提出了一种模型压缩的新思路2020-11-24 2154
-
无线及移动网络领域专家邱锂力加入微软亚洲研究院2022-01-25 1775
-
微软亚洲研究院把Transformer深度提升到1000层2022-03-24 2681
-
又一个点阵时钟开源设计2022-11-18 613
-
微软亚洲研究院否认撤离中国,但确认部分 AI 科学家将迁至温哥华2023-06-20 1294
-
科学匠人 | 边江:在研究院的七年“技痒”,探寻大模型助力AI与产业融合之道2023-08-04 1177
全部0条评论

快来发表一下你的评论吧 !
