

EDA画图函数的数据类型
EDA/IC设计
描述
Step1:导入数据并了解数据轮廓
查看各个特征的基本数据类型并且计算哪些特征缺失值比较多。
将特征的数据类型分为数值型和离散型两大类。
Step2: 分析特征和标签的分布情况
单变量分布
对于连续特征
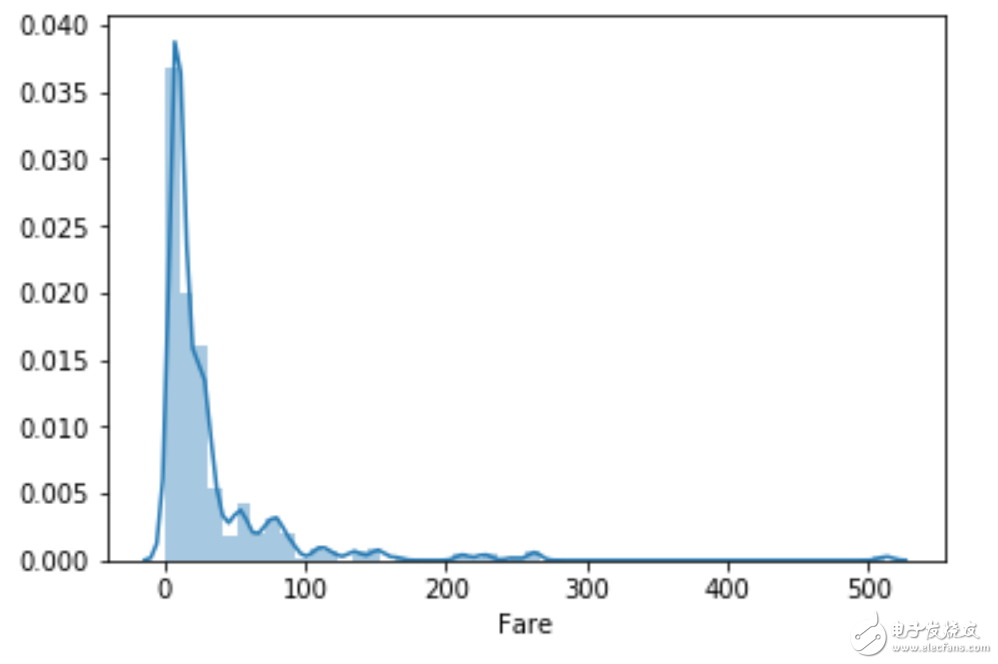
给出特征分布(可以不考虑缺失值)
sns.distplot(df["Fare"])
对于离散特征
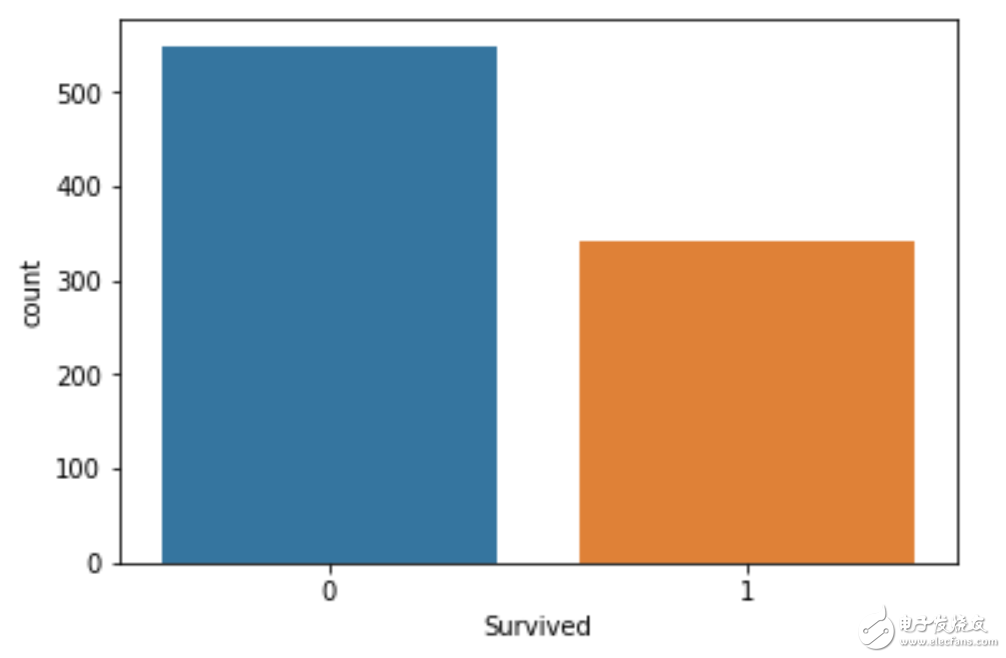
就是看特征分布是否均衡
sns.countplot(x='Survived', data=df)
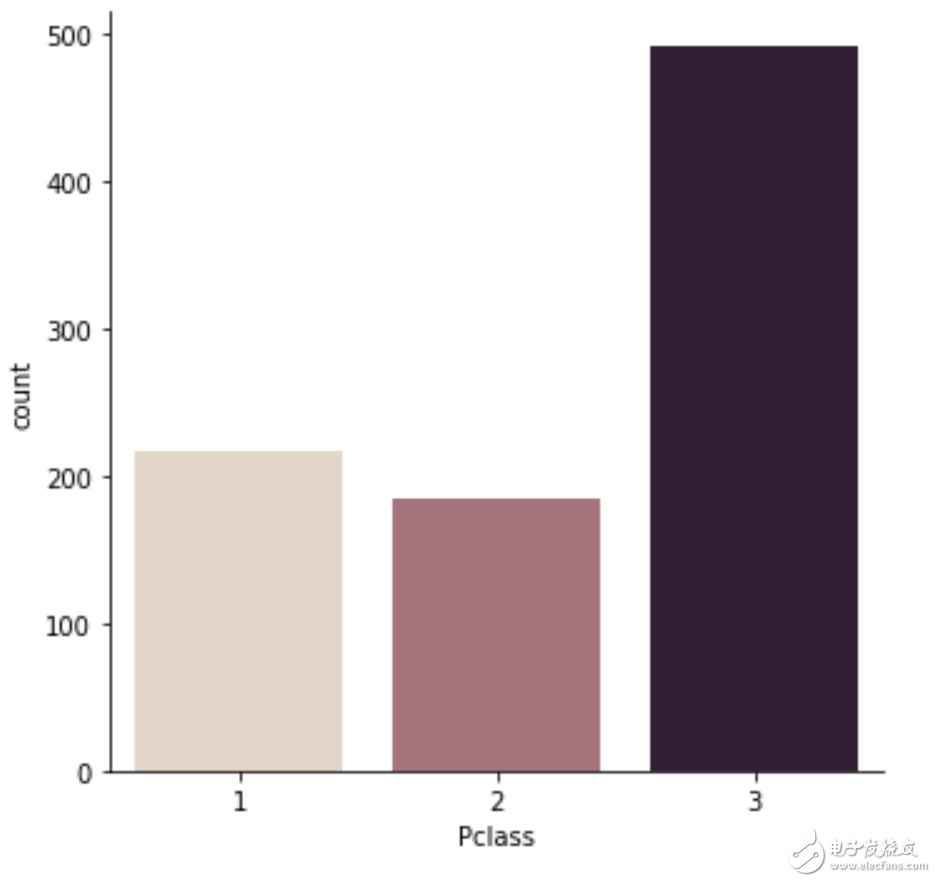
sns.catplot(x="Pclass", kind="count", palette="ch:.25", data=df) ## 这也是countplot
多变量分布(可以是特征之间也可以是特征与标号之间)
连续变量与连续变量
scatter plot
sns.relplot(x="Age", y="Fare", data=df); ## replot是一个figure-level的function,它的默认方法是scatterplot
可以用hue参数引入第三维变量
sns.relplot(x="Age", y="Fare", hue = 'Pclass',data=df);
lineplot,如时序特征
g = sns.relplot(x="Age", y="Fare", kind="line", data=df)
将x轴的特征按大小排序,然后连接起来。
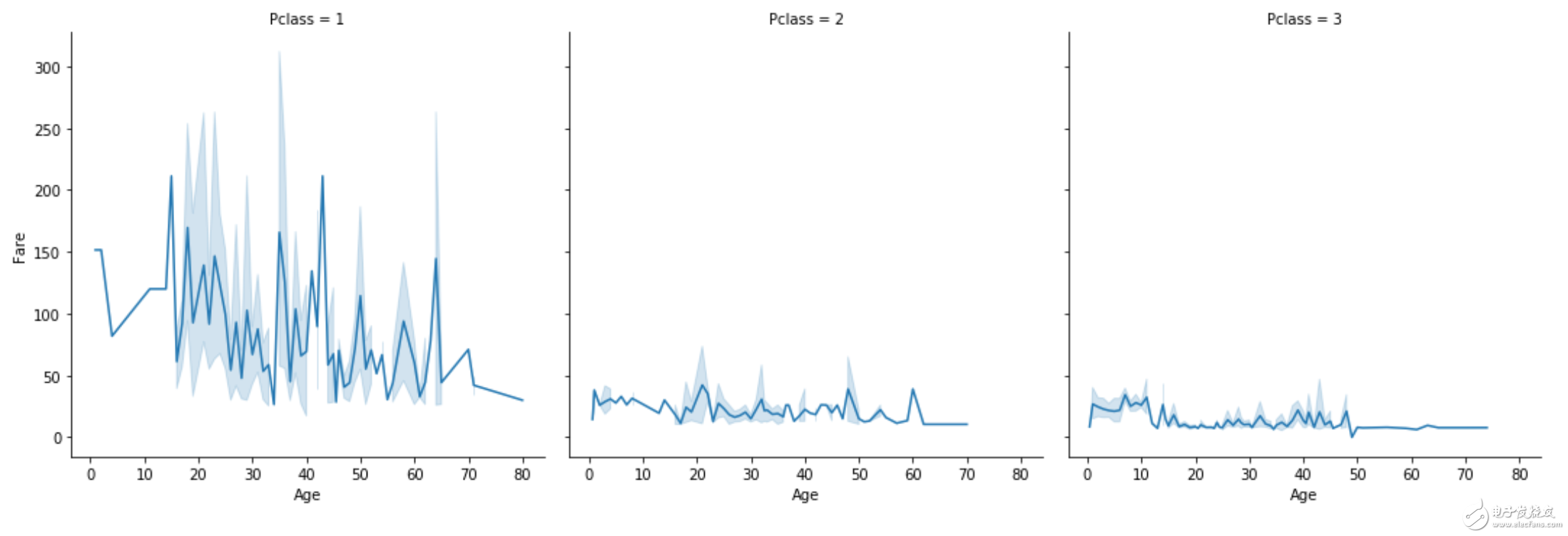
注意上图中的线条并不只有一条线,而是一个范围的区域,这是因为同一个x值可能有多个y值与之对应,颜色最深的线就是他们的均值,上下的范围是95%的置信度区域。
可以通过设置参数ci=None来屏蔽置信度区域。
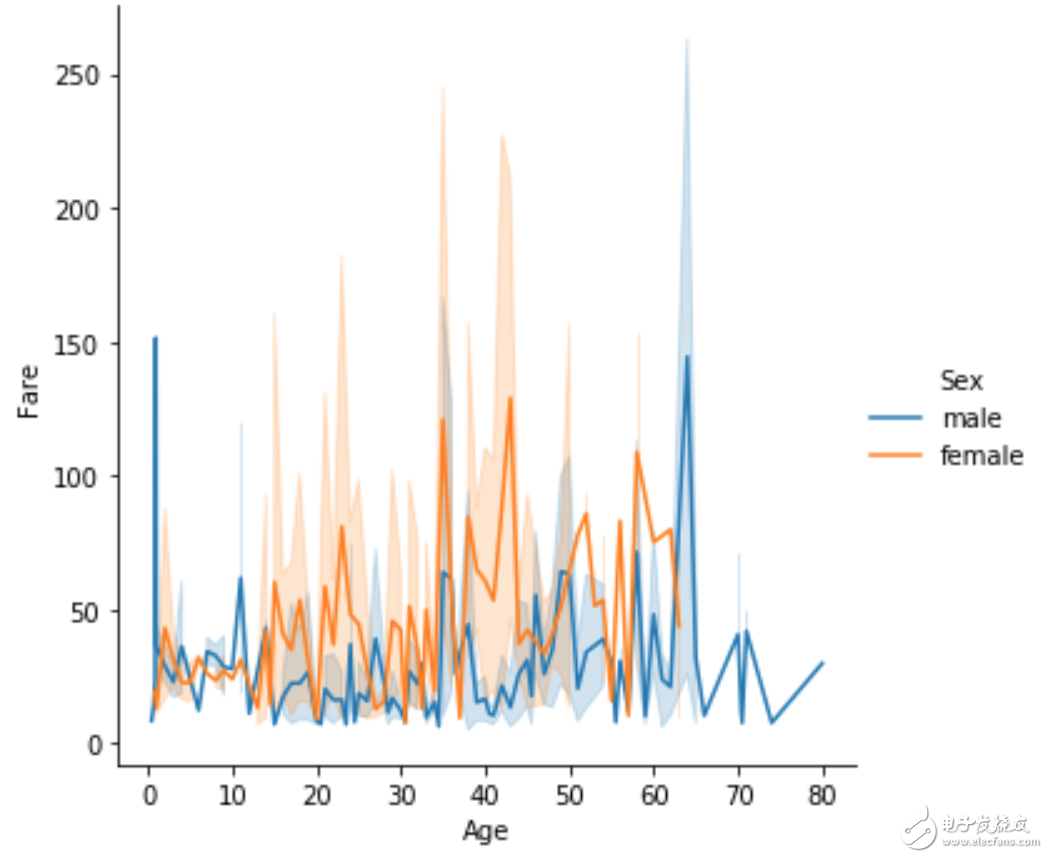
也可以通过hue参数引入第三个变量(一般为离散的特征比较合适)。
g = sns.relplot(x='Age',y ='Fare',hue='Sex',kind='line',data=df)
可以通过使用col参数更直观地展示三个(或四个,使用hue参数)变量之间的关系
g = sns.relplot(x='Age',y='Fare',kind='line',col='Pclass',data=df)
连续变量与离散变量
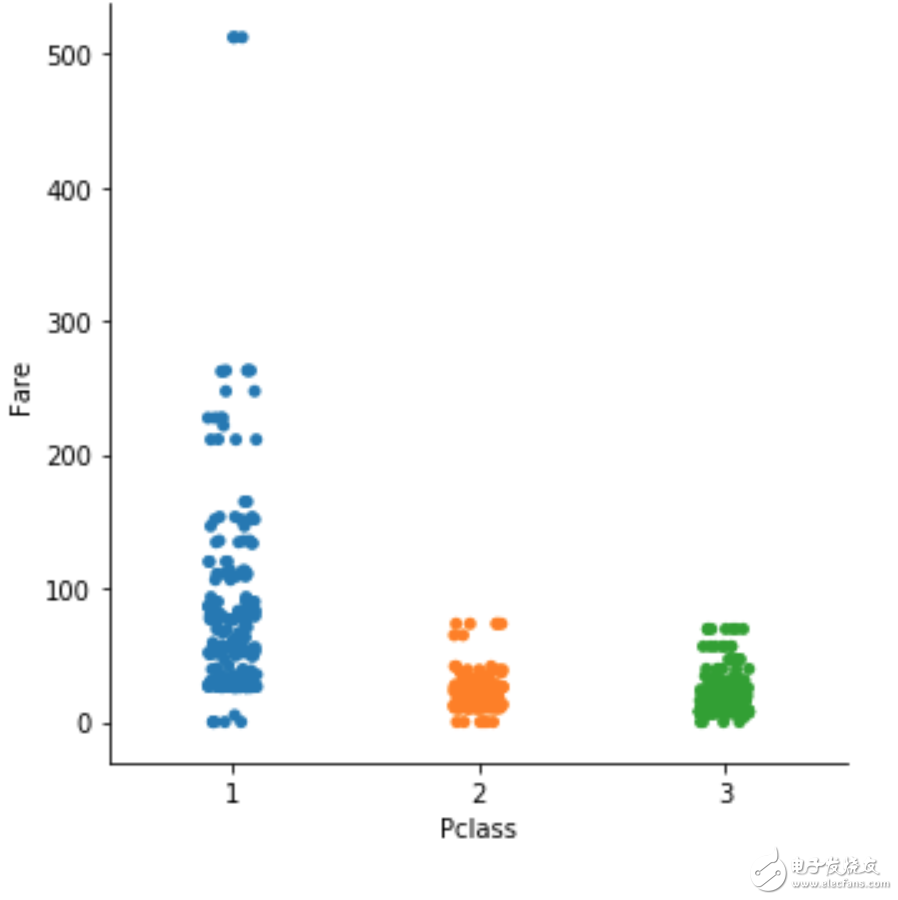
scatter plot
sns.catplot(x="Pclass", y="Fare", data=df);
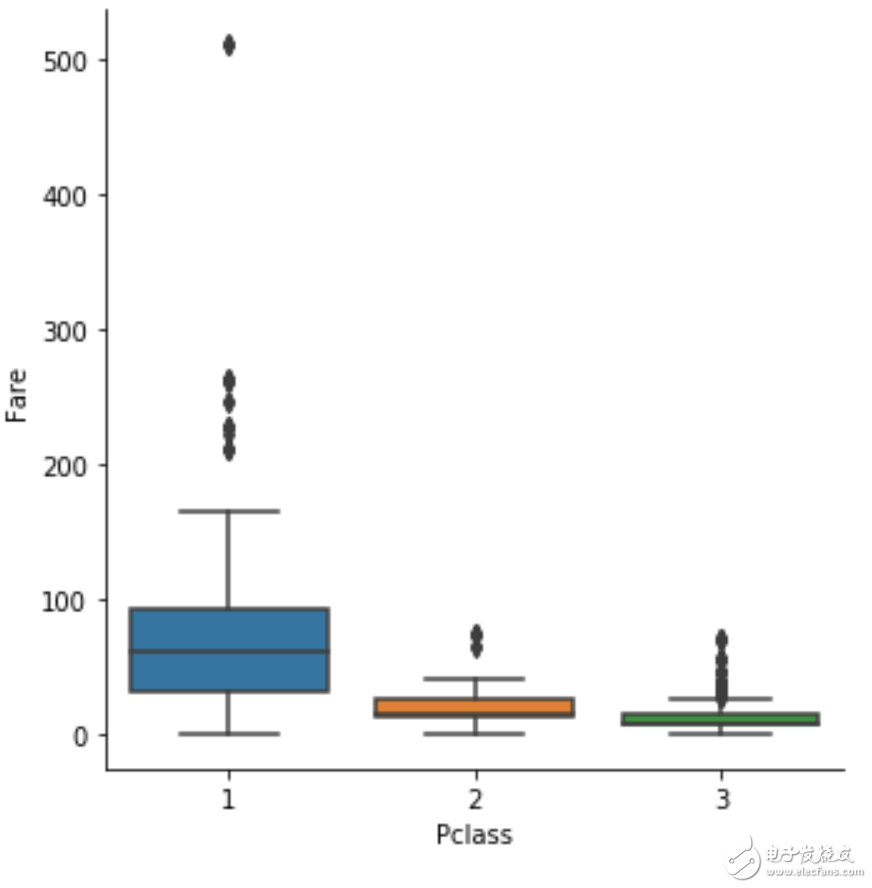
boxplot
表示每个离散变量的取值对应的另一个特征的分布,另一个特征是连续特征,如果是离散特征的话画出来的图非常奇怪
sns.catplot(x="Pclass", y="Fare", kind="box", data=df);
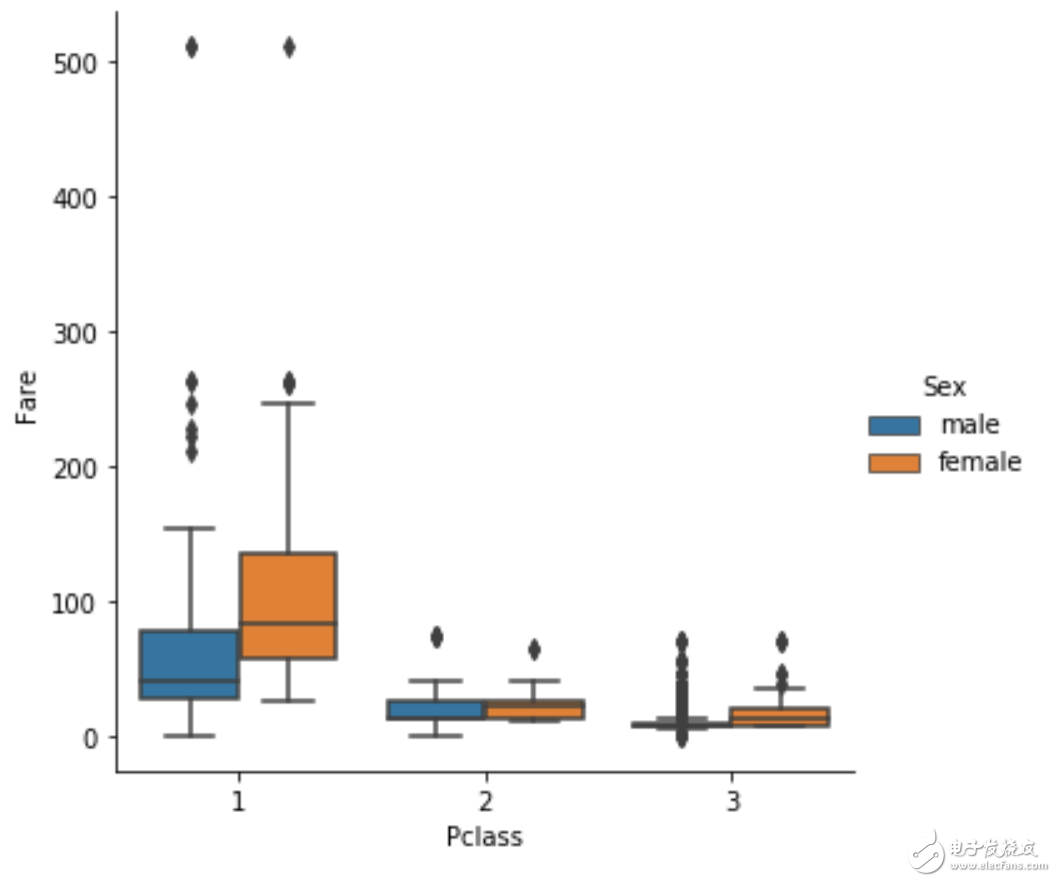
当然也可以使用hue参数引入第三个变量(应该是离散的)
sns.catplot(x="Pclass", y="Fare",hue = 'Sex', kind="box", data=df);
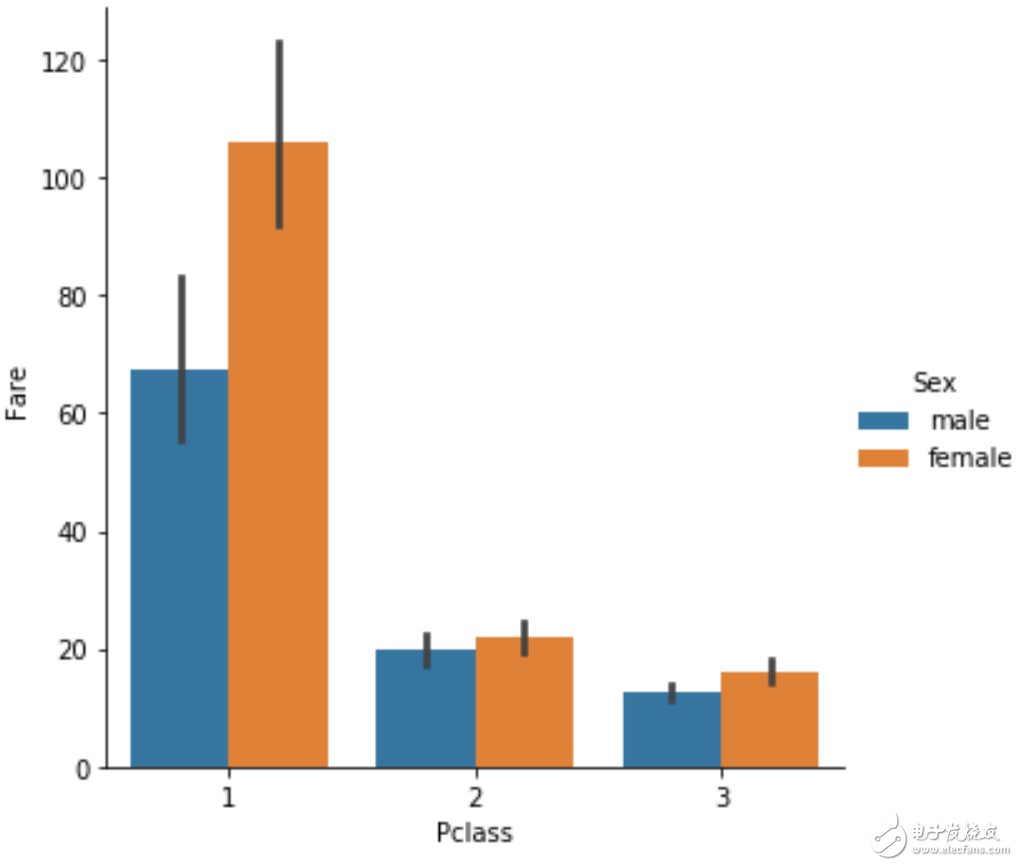
barplot
感觉这个方法与boxplot的方法比较相似,统计的是均值和标准差,而boxplot是均值、分位点和异常点的范围。
sns.catplot(x="Pclass", y="Fare",hue = 'Sex', kind="bar", data=df);
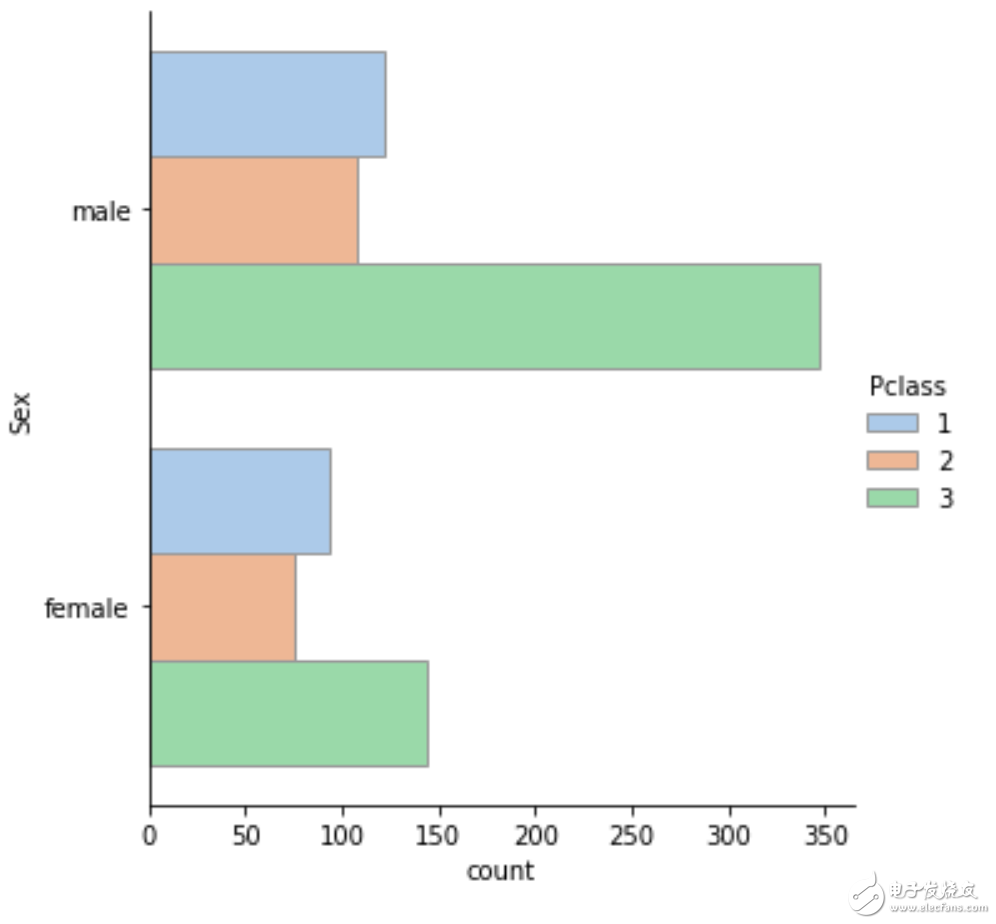
离散变量与离散变量
探索离散变量a与b之间的关系实际上就相当于探索 当a等于某个值时b的各个值的分布情况,可以用如下函数:
sns.catplot(y="Sex", hue="Pclass", kind="count", palette="pastel", edgecolor=".6", data=df);
对于标签
回归问题就是画图分布
离散问题就是看类分布是否均衡
-
SQL 通用数据类型2025-08-18 940
-
plc数据类型怎么理解和应用2023-12-19 7163
-
Redis的数据类型有哪些2023-10-09 1740
-
定义数据类型2023-03-03 2187
-
type( ) 函数查询数据类型是什么2023-02-23 3514
-
结构数据类型(Struct)及应用案例2022-07-27 2996
-
Struct结构数据类型2022-07-25 4154
-
编程语言SCL中ANY数据类型2021-05-25 6319
-
ABB机器人数据类型的秘密是什么?2020-12-26 2044
-
ABB机器人的RAPID指令与函数和数据类型的技术参考手册免费下载2019-11-15 3183
-
EDA教程之VHDL数据类型与顺序语句的详细资料免费下载2018-10-17 739
-
vhdl数据类型2018-03-30 1966
-
51单片机中的数据类型解析2017-11-16 27274
-
函数声明没有写上数据类型是什么意思2013-06-10 3152
全部0条评论

快来发表一下你的评论吧 !
