

半定制化的FPGA芯片和全定制化的ASIC芯片
电子说
描述
当前阶段,GPU 配合 CPU 仍然是 AI 芯片的主流,而后随着视觉、语音、深度学习的算法在 FPGA以及 ASIC芯片上的不断优化,此两者也将逐步占有更多的市场份额,从而与GPU达成长期共存的局面。从长远看,人工智能类脑神经芯片是发展的路径和方向。本文主要介绍半定制化的FPGA芯片和全定制化的 ASIC芯片。
AI 芯片是人工智能时代的技术核心之一,决定了平台的基础架构和发展生态。
芯片发展历程
AI 芯片按技术架构分类可分为GPU(Graphics Processing Unit,图形处理单元)、半定制化的 FPGA、全定制化 ASIC和神经拟态芯片等。
各个芯片的特点如下:
GPU 通用性强、速度快、效率高,特别适合用在深度学习训练方面,但是性能功耗比较低。
FPGA 具有低能耗、高性能以及可编程等特性,相对于 CPU 与 GPU 有明显的性能或者能耗优势,但对使用者要求高。
ASIC 可以更有针对性地进行硬件层次的优化,从而获得更好的性能、功耗比。但是ASIC 芯片的设计和制造需要大量的资金、较长的研发周期和工程周期,而且深度学习算法仍在快速发展,若深度学习算法发生大的变化,FPGA 能很快改变架构,适应最新的变化,ASIC 类芯片一旦定制则难于进行修改。
当前阶段,GPU 配合 CPU 仍然是 AI 芯片的主流,而后随着视觉、语音、深度学习的算法在 FPGA以及 ASIC芯片上的不断优化,此两者也将逐步占有更多的市场份额,从而与GPU达成长期共存的局面。从长远看,人工智能类脑神经芯片是发展的路径和方向。
本文主要介绍半定制化的FPGA芯片和全定制化的 ASIC芯片。
半定制化的 FPGA
FPGA 是在 PAL、GAL、CPLD 等可编程器件基础上进一步发展的产物。用户可以通过烧入 FPGA 配置文件来定义这些门电路以及存储器之间的连线。这种烧入不是一次性的,比如用户可以把 FPGA 配置成一个微控制器 MCU,使用完毕后可以编辑配置文件把同一个FPGA 配置成一个音频编解码器。因此,它既解决了定制电路灵活性的不足,又克服了原有有可编程器件门电路数有限的缺点。
FPGA 可同时进行数据并行和任务并行计算,在处理特定应用时有更加明显的效率提升。对于某个特定运算,通用 CPU 可能需要多个时钟周期;而 FPGA 可以通过编程重组电路,直接生成专用电路,仅消耗少量甚至一次时钟周期就可完成运算。
此外,由于 FPGA的灵活性,很多使用通用处理器或 ASIC难以实现的底层硬件控制操作技术,利用 FPGA 可以很方便的实现。这个特性为算法的功能实现和优化留出了更大空间。同时 FPGA 一次性成本(光刻掩模制作成本)远低于 ASIC,在芯片需求还未成规模、深度学习算法暂未稳定,需要不断迭代改进的情况下,利用 FPGA 芯片具备可重构的特性来实现半定制的人工智能芯片是最佳选择之一。
功耗方面,从体系结构而言,FPGA 也具有天生的优势。传统的冯氏结构中,执行单元(如 CPU 核)执行任意指令,都需要有指令存储器、译码器、各种指令的运算器及分支跳转处理逻辑参与运行,而 FPGA 每个逻辑单元的功能在重编程(即烧入)时就已经确定,不需要指令,无需共享内存,从而可以极大的降低单位执行的功耗,提高整体的能耗比。
由于 FPGA 具备灵活快速的特点,因此在众多领域都有替代 ASIC 的趋势。FPGA 在人工智能领域的应用如图所示。
FPGA在人工智能领域的应用
全定制化的 ASIC
目前以深度学习为代表的人工智能计算需求,主要采用 GPU、FPGA 等已有的适合并行计算的通用芯片来实现加速。在产业应用没有大规模兴起之时,使用这类已有的通用芯片可以避免专门研发定制芯片(ASIC)的高投入和高风险。但是,由于这类通用芯片设计初衷并非专门针对深度学习,因而天然存在性能、功耗等方面的局限性。随着人工智能应用规模的扩大,这类问题日益突显。
GPU 作为图像处理器,设计初衷是为了应对图像处理中的大规模并行计算。因此,在应用于深度学习算法时,有三个方面的局限性:
第一,应用过程中无法充分发挥并行计算优势。深度学习包含训练和推断两个计算环节,GPU 在深度学习算法训练上非常高效,但对于单一输入进行推断的场合,并行度的优势不能完全发挥;
第二,无法灵活配置硬件结构。GPU 采用 SIMT 计算模式,硬件结构相对固定。目前深度学习算法还未完全稳定,若深度学习算法发生大的变化,GPU 无法像 FPGA 一样可以灵活的配制硬件结构;
第三,运行深度学习算法能效低于 FPGA。
尽管 FPGA 倍受看好,甚至新一代百度大脑也是基于 FPGA 平台研发,但其毕竟不是专门为了适用深度学习算法而研发,实际应用中也存在诸多局限:第一,基本单元的计算能力有限。为了实现可重构特性,FPGA 内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠 LUT 查找表)都远远低于 CPU 和 GPU 中的 ALU 模块;第二,计算资源占比相对较低。为实现可重构特性,FPGA 内部大量资源被用于可配置的片上路由与连线;第三,速度和功耗相对专用定制芯片(ASIC)仍然存在不小差距;第四,FPGA 价格较为昂贵,在规模放量的情况下单块 FPGA 的成本要远高于专用定制芯片。
因此,随着人工智能算法和应用技术的日益发展,以及人工智能专用芯片ASIC产业环境的逐渐成熟,全定制化人工智能ASIC也逐步体现出自身的优势,从事此类芯片研发与应用的国内外比较有代表性的公司如表 1 所示。
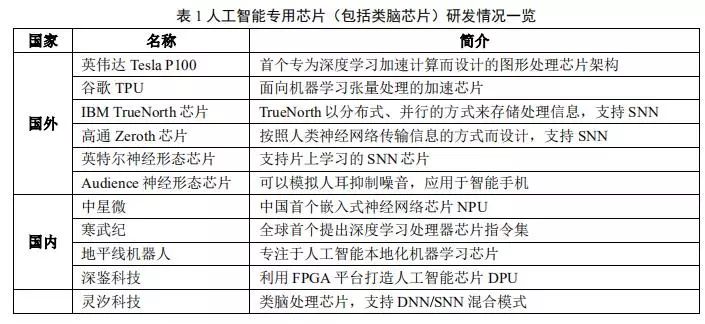
ASIC 芯片非常适合人工智能的应用场景。
首先,ASIC的性能提升非常明显。例如英伟达首款专门为深度学习从零开始设计的芯片 Tesla P100 数据处理速度是其 2014 年推出GPU 系列的 12 倍。谷歌为机器学习定制的芯片 TPU 将硬件性能提升至相当于当前芯片按摩尔定律发展 7 年后的水平。正如 CPU 改变了当年庞大的计算机一样,人工智能 ASIC 芯片也将大幅改变如今 AI 硬件设备的面貌。如大名鼎鼎的 AlphaGo 使用了约 170 个图形处理器(GPU)和 1200 个中央处理器(CPU),这些设备需要占用一个机房,还要配备大功率的空调,以及多名专家进行系统维护。而如果全部使用专用芯片,极大可能只需要一个普通收纳盒大小的空间,,且功耗也会大幅降低。
第二,下游需求促进人工智能芯片专用化。从服务器,计算机到无人驾驶汽车、无人机再到智能家居的各类家电,至少数十倍于智能手机体量的设备需要引入感知交互能力和人工智能计算能力。而出于对实时性的要求以及训练数据隐私等考虑,这些应用不可能完全依赖云端,必须要有本地的软硬件基础平台支撑,这将带来海量的人工智能芯片需要。
目前人工智能专用芯片的发展方向包括:主要基于 FPGA 的半定制、针对深度学习算法的全定制和类脑计算芯片 3 个方向。
在芯片需求还未形成规模、深度学习算法暂未稳定,AI 芯片本身需要不断迭代改进的情况下,利用具备可重构特性的 FPGA 芯片来实现半定制的人工智能芯片是最佳选择之一。这类芯片中的杰出代表是国内初创公司深鉴科技,该公司设计了“深度学习处理单元”(Deep Processing Unit,DPU)的芯片,希望以 ASIC 级别的功耗达到优于 GPU 的性能,其第一批产品就是基于 FPGA 平台开发研制出来的。这种半定制芯片虽然依托于 FPGA 平台,但是抽象出了指令集与编译器,可以快速开发、快速迭代,与专用的 FPGA 加速器产品相比,也具有非常明显的优势。
深度学习算法稳定后,AI 芯片可采用 ASIC 设计方法进行全定制,使性能、功耗和面积等指标面向深度学习算法做到最优。
-
cogoask讲解fpga和ASIC是什么意思2012-02-27 0
-
FPGA和ASIC芯片解密有哪些性能分析2017-06-12 0
-
定制型加密芯片这是一款采用随机变量交换系统的认证加密芯片,请问定制化加密芯片优势在哪里?2018-05-21 0
-
定制化加密芯片优势和产品特点2018-07-20 0
-
对于CV181系列芯片的SDK定制化疑问求解2023-09-18 0
-
全定制和半定制简易IC设计流程介绍2017-10-20 2801
-
联发科成功拿下HomePodWiFi定制化芯片(ASIC)订单2018-01-29 1397
-
什么是ASIC芯片?与CPU、GPU、FPGA相比如何?2018-05-04 253215
-
车载芯片的发展趋势(CPU-GPU-FPGA-ASIC)2018-08-09 23083
-
浅析GPU、FPGA、ASIC三种主流AI芯片的区别2019-03-07 30087
-
中国FPGA芯片行业综述2021-01-04 8958
-
元宇宙浪潮下,AR芯片将走向定制化2022-04-29 2547
-
自动驾驶主流芯片:GPU、FPGA、ASIC2023-03-17 1968
-
半定制快速芯片ASIC可实现高达9GHz的射频功能2023-06-26 773
-
ASIC集成电路与FPGA的区别2024-11-20 344
全部0条评论

快来发表一下你的评论吧 !
