

GPU如何训练大批量模型?方法在这里
控制/MCU
描述
深度学习模型和数据集的规模增长速度已经让 GPU 算力也开始捉襟见肘,如果你的 GPU 连一个样本都容不下,你要如何训练大批量模型?通过本文介绍的方法,我们可以在训练批量甚至单个训练样本大于 GPU 内存时,在单个或多个 GPU 服务器上训练模型。
分布式计算
2018 年的大部分时间我都在试图训练神经网络时克服 GPU 极限。无论是在含有 1.5 亿个参数的语言模型(如 OpenAI 的大型生成预训练 Transformer 或最近类似的 BERT 模型)还是馈入 3000 万个元素输入的元学习神经网络(如我们在一篇 ICLR 论文《Meta-Learning a Dynamical Language Model》中提到的模型),我都只能在 GPU 上处理很少的训练样本。
但在多数情况下,随机梯度下降算法需要很大批量才能得出不错的结果。
如果你的 GPU 只能处理很少的样本,你要如何训练大批量模型?
有几个工具、技巧可以帮助你解决上述问题。在本文中,我将自己用过、学过的东西整理出来供大家参考。
在这篇文章中,我将主要讨论 PyTorch 框架。有部分工具尚未包括在 PyTorch(1.0 版本)中,因此我也写了自定义代码。
我们将着重探讨以下问题:
在训练批量甚至单个训练样本大于 GPU 内存,要如何在单个或多个 GPU 服务器上训练模型;
如何尽可能高效地利用多 GPU 机器;
在分布式设备上使用多个机器的最简单训练方法。
在一个或多个 GPU 上训练大批量模型
你建的模型不错,在这个简洁的任务中可能成为新的 SOTA,但每次尝试在一个批量处理更多样本时,你都会得到一个 CUDA RuntimeError:内存不足。
这位网友指出了你的问题!
但你很确定将批量加倍可以优化结果。
你要怎么做呢?
这个问题有一个简单的解决方法:梯度累积。
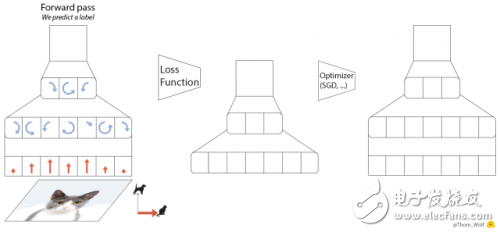
梯度下降优化算法的五个步骤。
与之对等的 PyTorch 代码也可以写成以下五行:
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss.backward() # Backward pass
optimizer.step() # Optimizer step
predictions = model(inputs) # Forward pass with new parameters
在 loss.backward() 运算期间,为每个参数计算梯度,并将其存储在与每个参数相关联的张量——parameter.grad 中。
累积梯度意味着,在调用 optimizer.step() 实施一步梯度下降之前,我们会对 parameter.grad 张量中的几个反向运算的梯度求和。在 PyTorch 中这一点很容易实现,因为梯度张量在不调用 model.zero_grad() 或 optimizer.zero_grad() 的情况下不会重置。如果损失在训练样本上要取平均,我们还需要除以累积步骤的数量。
以下是使用梯度累积训练模型的要点。在这个例子中,我们可以用一个大于 GPU 最大容量的 accumulation_steps 批量进行训练:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulated
扩展到极致
你可以在 GPU 上训练连一个样本都无法加载的模型吗?
如果你的架构没有太多跳过连接,这就是可能的!解决方案是使用梯度检查点(gradient-checkpointing)来节省计算资源。
基本思路是沿着模型将梯度在小组件中进行反向传播,以额外的前馈传递为代价,节约存储完整的反向传播图的内存。这个方法比较慢,因为我们需要添加额外的计算来减少内存要求,但在某些设置中挺有意思,比如在非常长的序列上训练 RNN 模型(示例参见 https://medium.com/huggingface/from-zero-to-research-an-introduction-to-meta-learning-8e16e677f78a)。
这里不再赘述,读者可以查看以下链接:
TensorFlow:https://github.com/openai/gradient-checkpointing
PyTorch 文档:https://pytorch.org/docs/stable/checkpoint.html

“节约内存”(Memory-poor)策略需要 O(1) 的内存(但是要求 O(n²) 的计算步)。
充分利用多 GPU 机器
现在我们具体来看如何在多 GPU 上训练模型。
在多 GPU 服务器上训练 PyTorch 模型的首选策略是使用 torch.nn.DataParallel。该容器可以在多个指定设备上分割输入,按照批维度(batch dimension)分割,从而实现模块应用的并行化。
DataParallel 非常容易使用,我们只需添加一行来封装模型:
parallel_model = torch.nn.DataParallel(model) # Encapsulate the model
predictions = parallel_model(inputs) # Forward pass on multi-GPUs
loss = loss_function(predictions, labels) # Compute loss function
loss.backward() # Backward pass
optimizer.step() # Optimizer step
predictions = parallel_model(inputs) # Forward pass with new parameters
但是,DataParallel 有一个问题:GPU 使用不均衡。
在一些设置下,GPU-1 会比其他 GPU 使用率高得多。
这个问题从何而来呢?下图很好地解释了 DataParallel 的行为:
使用 torch.nn.DataParallel 的前向和后向传播。
在前向传播的第四步(右上),所有并行计算的结果都聚集在 GPU-1 上。这对很多分类问题来说是件好事,但如果你在大批量上训练语言模型时,这就会成为问题。
我们可以快速计算语言模型输出的大小:
语言模型输出中的元素数量。
假设我们的数据集有 4 万词汇,每一条序列有 250 个 token、每个 batch 中有 32 条序列,那么序列中的每一个元素需要 4 个字节的内存空间,模型的输出大概为 1.2GB。要储存相关的梯度张量,我们就需要把这个内存翻倍,因此我们的模型输出需要 2.4GB 的内存。
这是典型 10GB GPU 内存的主要部分,意味着相对于其它 GPU,GPU - 1 会被过度使用,从而限制了并行化的效果。
如果不调整模型和/或优化方案,我们就无法轻易减少输出中的元素数量。但我们可以确保内存负载在 GPU 中更均匀地分布。
- 相关推荐
- 热点推荐
-
东风新能源车大批量签约交付2025-07-31 829
-
小批量SMT加工的“定制化”与大批量生产的“标准化”:差异全解析2025-07-16 808
-
PyTorch GPU 加速训练模型方法2024-11-05 2194
-
EVASH Ultra EEPROM和Microchip 32位MCU在功放产品中的大批量应用2024-06-24 1208
-
线路板生产该选大批量还是小批量?2023-12-13 1851
-
MEMS封装推向市场大批量生产2022-06-20 1547
-
在Ubuntu上使用Nvidia GPU训练模型2022-01-03 2412
-
如何简化从原型向大批量PCB生产的过渡2020-10-12 1916
-
蓝牙大批量制造测试系统2019-06-10 1276
-
未来大批量PCB胜在规模 小批量PCB以毛利率取胜2019-05-09 7240
-
面向大批量应用的的Artix-7 FPGA的能耗优势演示2018-06-04 3748
-
CC2640怎么大批量测试FR性能2016-03-24 3489
-
赛灵思针对大批量应用大幅提升设计生产力2013-02-20 1193
-
三星大批量生产移动4GB DRAM内存芯片2011-03-25 1048
全部0条评论

快来发表一下你的评论吧 !
