

如何提升RT1050的代码运行速度,使其发挥最大性能
电子说
描述
本文以RT1050为例,讲解如何提升RT1050的代码运行速度,使其发挥最大性能,并列出在提升性能过程中可能会遇到的问题以及解决办法。
1.是谁影响了代码运行速度?
在一般的MCU开发中,我们习惯性的将代码直接下载到MCU的内部Flash中,并直接在内部Flash中运行,在I-CODE、D-CODE总线以及自带的Flash加速器加持下,这么做似乎也没什么问题。但作为一款高性能并拥有最高600M主频的跨界MCU,RT1050并没有内置Flash。那么在实际开发中,就必须外置一块 NOR Flash用于代码的存储。
如果此时我们还像之前开发一般MCU那样,让代码在Flash运行,就会受限于Flash的读写速度,以及MCU与Flash之间的通信速度。那感觉,就像开着V12引擎的布加迪,跑在限速40的公路上,完全发挥不出来600M主频的性能,更别谈让代码的运行速度飞起来了。
2. 如何让代码运行速度飞起来!
代码必须存储在Flash中实现掉电不丢失,而与此同时,我们又要求发挥600M主频的最大性能,让代码的运行速度飞起来,可能你还没想好怎么做,那就跟着小编一起,由浅到深,用实际可行的方案,一步步提升代码运行速度,并解决在提升代码速度时遇到的阻碍,最后让代码的运行速度飞起来。
2.1运行域和加载域的概念
既然在Flash中运行代码效率不高,那我们首先想到的办法,就是不让代码在Flash中运行,那就不得不提到运行域和加载域的概念。
代码在通过编译器链接器的处理后生成了固件文件,此时有两个相关概念需要留意,就是加载域和运行域。
加载域的意思是代码要下载到哪里。这里肯定要选择下载到Flash中。运行域的意思是代码在哪里运行。例如我们可以指定代码在RAM中运行,那么在__main中,就会将相关代码都拷贝到RAM中,在程序运行时,就会去RAM空间取指、译码、执行。加载域和运行域的定义可以在分散加载文件中完成。
听起来是个不错的想法,但是在实施的过程中,就会遇到一个问题,我们所说的代码,也就是固件的CODE部分,也包含了中断复位函数。我们知道,程序在上电时,硬件会去相对地址0x00处取栈指针,而后偏移一个字,取复位中断函数地址,并在复位中断函数中执行系统初始化函数SystemInit和__mian函数,并在__mian函数中实现不同运行域的代码拷贝。按照这种硬件机制,有一些代码是要在代码拷贝之前运行的。
因此我们并不能将所有代码的运行域都拷贝到RAM中运行。这也是为什么分散加载文件规定,加载域中的第一个运行域,其起始地址必须和该加载域起始地址相同。
一种可行的办法是将不能更改运行域的代码提出来,放在加载域的第一个运行域,用于上电启动过程,然后将其他代码段的运行域放在RAM中,这样一来,在上电启动过程完成,进入到mian函数后,代码都是在RAM中运行的,其速度会有飞一样的提升。分散加载文件中相关示例配置和注释如图1所示。
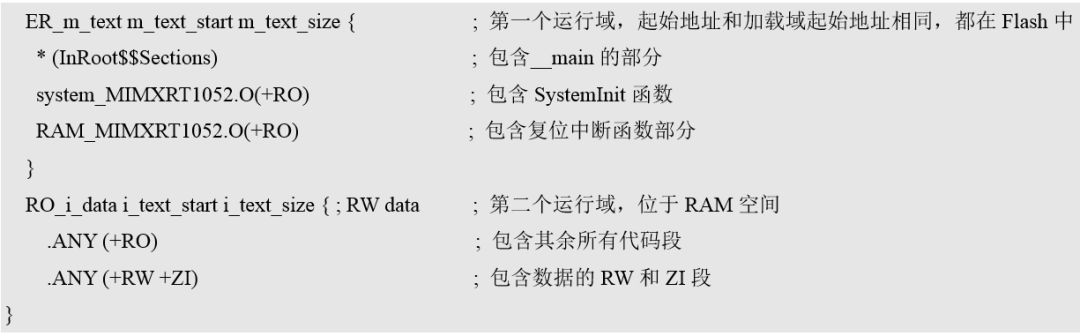
图1 运行域分配
2.2RAM空间的优化
以为上述的配置完成之后就可以起飞了吗?不,还差一点。如果再对RT1050的存储结构多点了解,就会发现其内部的RAM空间被分成了三个部分。包括ITCM、DTCM和OCRAM。这三个部分共享512K的RAM空间。在默认配置下,ITCM和DTCM各占128K、OCRAM占256K。
根据RT1050的内部总线结构,将代码段放在ITCM、数据段放在DTCM中,可以带来更高的性能和更快的代码速度。其分散加载的示例配置如图2所示。
图2 DTCM空间和ITCM空间分配
讲道理,经过这样的处理之后,我们已经将代码和数据的运行域放在了整个RT1050运行最快的位置,其600M主频的性能也能最大力度的发挥出来。但是这样做是不是就大功告成了呢?可能还不是,在实际的项目开发中,还会遇到一些其他的问题。
2.3其他的一些问题
2.3.1 代码和数据容量的问题
如果不考虑整个工程的代码大小,之前所做的一切都是很OK的,但是往往会遇到一种情况,就是代码量或者数据量太大,已经超出了范围。
如果只是超过了RAM默认的配置范围,那可以将RAM的空间重新分配,以32K为单位,可以按照实际需要调整ITCM和DTCM的空间大小,不过有两点需要注意,一是OCRAM至少要保留32K的空间大小、二是一定要在__main之前调整好RAM的分区,否则在__mian函数中拷贝函数拷贝代码时就会因为空间不足而产生硬件错误。
一种可行的办法是在复位中断函数的起始位置通过汇编指令去调整RAM的分区,示例代码如图3所示。主要是修改三个寄存器中内容,详细信息可查阅参考手册中相关的部分。
图3 通过汇编指令调整RAM分区
如果代码或者数据的容量已经超出了RAM区域能调整的范围,那就不能将代码和数据的运行域都放在RAM中了。例如使用libpng解码库解码png图片,可能需要1M以上的堆空间。在这种情况下,可以使用一块大容量的SDRAM作为辅助,虽然代码运行的速度没有在RAM中高,但是解决了RAM空间本身不是很充足的问题,且在SDRAM中运行代码肯定会比在Flash中运行代码要快上很多。
有了SDRAM的加持,就可以选择性的将需要高速运行的代码或者关键数据放在RAM的空间。一些不需要高速运行的代码或者数据放在SDRAM的空间。如果需要使用的堆太大,也可以将堆的空间放在SDRAM中。
通过这种策略灵活的调整之后,在最佳性能和代码量之间能找到一个平衡点,以更好的应用于一些大型的工程,例如带了操作系统、lwip协议栈、emWin等。
2.3.2 中断响应的问题
在前面的操作中,我们一直没有留意中断这个对嵌入式系统十分重要的部分。由前面的操作可知,我们将中断向量表加载到了Flash中用于上电启动,而后就一直没有管它,只是专注于代码的运行域。但是如果中断向量表还在Flash中,那么当产生中断的时候,硬件还是会到Flash中的中断向量表位置去查找相应的中断服务函数,这样一去一回,无疑就拖慢了中断的响应速度,要知道,在零等待的情况下,RT1050的中断响应时间可是能达到20ns的。
可以将中断向量表也拷贝到RAM中,然后重新对中断向量表的地址进行映射。一种可行的方式是修改启动文件。在启动文件中再命名一个中断向量表,该中断向量表中添加原中断向量表中除复位中断函数之外的其他部分,而原中断向量表中只保留复位中断函数和栈指针。将新做的中断向量表的运行域放在RAM的起始位置。这样在程序上电的时候。__main会将该中断向量表拷贝到RAM的起始地址,而后在main函数的开头,对中断向量表进行重映射。不过需要注意的是,这种操作有一个弊端,就是需要保证在复位到执行中断向量表重映射期间,不能产生除了复位中断之外的其他中断,否则会造成硬件异常。
3. 代码运行速度已经起飞
经过上面的处理之后,怎么能不感受一下实际的起飞效果,可做一个LED灯翻转的小例程用于测试,在例程中用软件延时的方式翻转小灯。先在Flash中运行,让软件延时达到200ms左右的延时效果。能正常显示之后,不改变代码内容,只是将代码运行域放在RAM中,再次运行代码,就能看到,此时小灯翻转的频率,已经达到了起飞的效果。
-
RT1050仿真器有什么要求吗?2023-11-08 456
-
在i.MX RT1050上如何实现双大容量存储(MSC)设备2023-10-30 1175
-
i.MX RT系列(例如 RT1050/1060)有多少个PWM通道?2023-05-18 508
-
基于 NXP i.MX RT1050 的 3D 打印机方案2023-04-06 1988
-
请问如何测量RT1050的USB性能?2023-04-04 686
-
有人在RT1050或RT1060上用过PN7160吗?2023-04-03 553
-
如何使用J-link在没有EVB的情况下调试RT1050?2023-03-14 492
-
i.MX RT1050的功耗和测量资料分享2022-12-12 491
-
i.MX RT1050平台的相关资料推荐2021-11-29 1142
-
【044】SylixOS 正式支持 i.MX RT1050平台2021-11-19 780
-
RT1050的uclinux该如何去使用呢2021-10-21 1589
-
【大联大品佳 NXP i.MX RT1050试用申请】基于 NXP i.MX RT1050工业机器人开发2020-08-10 1319
-
rt1050程序在外部flash中跑同时去操作外部flash保存数据2019-05-15 1412
全部0条评论

快来发表一下你的评论吧 !
