

一个基于区块链的电子病历共享系统
电子说
描述
在“歪评”区块链之后,前IBM认知医疗研究总监、平安科技首席医疗科学家谢国彤回归本行,聚焦MIT基于区块链的电子病历共享系统MedRec,从Linked Data角度思考区块链的医疗行业应用。
自从今年3月份写完《最具娱乐精神的区块链科普》以后,一直没有写下篇。最近看了MIT Media Lab做的MedRec,一个基于区块链的电子病历共享系统,有点儿感想,分享一下。
万维网和Linked Data
每当听到有人说要把医疗数据放到区块链上的时候,我的第一个问题都是:什么信息应该放到链上?什么不应该放到链上?在区块链诞生的“比特币”场景下,链上记录的是比特币交易信息,这类金融信息的特点是交易频次高,但结构简单,每次交易的数据量小。
电子病历数据却不太一样。相比金融交易系统,电子病历的频次要低很多。在这个“买买买”的时代,一个人可以在一天内轻轻松松扫20次以上的支付宝或微信支付,但他/她一年也不见得会有20次电子病历数据交易。可是单次电子病历数据却相当复杂度,一个患者一次就诊就可以产生挂号信息、病历信息、检验单、检查结果、医学影像、入院记录、手术记录、护理记录和出院小结等结构复杂、模态多样的电子病历数据。
这时问题就来了:难道我们要把这些数据都放到链上吗?把这些数据在区块链的每个节点上都复制一遍?这看起来不像个好主意。
类似的跨系统、多模态复杂数据的共享平台其实我们每天都在用,就是万维网(World Wide Web)。当你刷着淘宝追着剧,同时不停在微信上积赞换购物红包,或者在微博上点评剧中男/女主的时候,你已经在多个复杂的异构系统中进行了信息访问和共享。只不过这个信息共享系统的设计实在太优美,简洁直观,以至于你都没有意识到自己做了这么复杂的事情。
这个优美系统的设计者就是Tim Berners-Lee(TBL),他在1990年圣诞节实现了第一次HTTP通讯,并于2016年因为这个伟大的设计获得了图灵奖。
Tim Berners-Lee因为发明了万维网获得了2016年的图灵奖
在完成万维网的设计后,TBL在2006年提出了Web 2.0的概念,Linked Data。顾名思义,就是把数据,而不是网页,通过链接关联起来;让程序,而不是人,可以在数据的海洋中冲浪。
这个希望在Web之上构建一个分布式结构化数据共享平台的想法远远没有Web成功,但它的一些设计指导原则在基于区块链的电子病历共享系统方面其实很有借鉴意义。
Linked Data有四个设计原则:
用URI(Uniform Resource Identifier)标识所有的数据资源
用户可以通过HTTP协议访问URI
当URI被访问时,返回一些基于标准的有用信息
在URI之间建立链接,这样用户可以发现更多的信息
基于区块链的电子病历共享系统设计
参考Linked Data的四大设计原则,会发现在基于区块链的电子病历共享系统设计中,有一些基本的问题要思考:
什么是数据资源?在Web时代,最基本的数据资源是一个网页、一张图片或者一段视频。在电子病历共享系统中的资源是什么?一个患者,一个医疗机构,一次就诊,一次就诊中产生的一个临床文档?
用什么做数据资源的URI?用什么协议访问这个URI?这里应该用区块链的程序访问协议来代替HTTP。
当用户访问某个URI的时候,应该由谁返回信息?返回什么信息?是由区块链的分布式账本,还是每个医疗机构的本地服务器来返回信息?是返回患者的就诊列表,还是患者的电子病历数据集?返回的信息格式应该如何设计才能更好的支持互操作性(Interoperability)。
URI之间有什么样的语义链接?如何让程序可以在通过链接在数据的海洋中穿梭遨游?
看完MedRec的系统设计,虽然它并没有提Linked Data,不过我觉得它无意中遵循了一些LInked Data的设计原则。想想也不奇怪,毕竟MedRec也是在解决分布式异构数据共享问题,只不过从Web平台换到了区块链平台上。
MedRec的智能合约设计
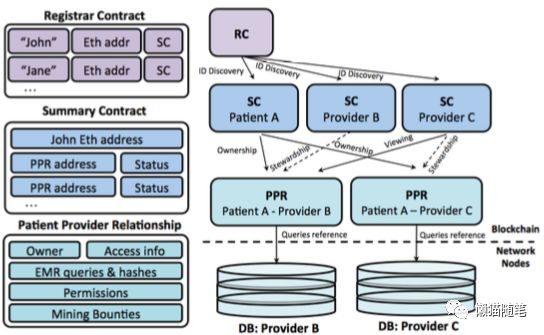
MedRec采用智能合约(Smart Contract)来表示区块链上的患者、医疗机构、病历信息指针和患者-机构之间的就诊关系,这属于电子病历的元数据(metadata),而真正的数据依然存储在每个医疗机构本地的数据库中。
从智能合约中可以找到医疗机构本地数据库的指针,然后程序通过这个指针可以查询到最终的数据。类似你从谷歌和百度的搜索结果页面中找到Web链接,然后再通过链接访问包含原始数据的网站,获取链接内容。它主要包含三个合约:
管理合约(Registrar Contract):它承担了资源定义的工作。目前MedRec里只有两类资源:患者(Patient)和医疗机构(Provider)。每个资源定义了唯一的URI:Eth addr(Ethereum address),是这个资源在Ethereum区块链平台上唯一的地址,类似一个RDFResource的集合。
摘要合约(Summary Contract):以每个资源(患者或医疗机构)为索引,把这个资源相关的所有数据(关系)都整合起来。这样从一个资源的URI出发,就可以找到所有跟它有关的数据。类似一个RDFGraph,记录了所有以某个RDFResource为subject的RDFStatement的集合。
医患关系合约(Patient Provider Relationship):它表示的是两类URI(患者和医生)之间的语义关系:就诊,类似一个RDFStatement。但它还要表示很多其他信息,所以采用了类似属性图(Property Graph)的方法,在二元关系上附加了很多属性,比如:
Access info:包含实际存储了原始电子病历数据的医疗机构的本地数据库访问信息,如IP地址,数据库用户名等;
EMR queries & hashes:在医疗机构本地数据库中查询某个患者电子病历信息的SQL语句,还有电子病历信息的哈希值。这样如果数据上传区块链之后,医疗机构又对本地电子病历数据进行了修改,通过哈希值是可以发现的,这体现了区块链的不可篡改性和可溯源性;
Permission:它是个哈希表,记录了第三方访问者可以调用哪些额外的SQL查询,类似rdfs:seeAlso的设计,告诉访问者还有哪些有意思的信息可以“顺便”看看;
Mining Bounties:非常区块链风格的赏金设计,很有趣。为了激励区块链上的矿工们(Miner)参与平台的计算,当包含这个电子病历数据更新的block(块)被挖到的时候,矿工自动会得到访问这个赏金(bounty)查询的权限。赏金查询主要是针对人群的一些统计信息,比如“最近一个月来医院A就诊的糖尿病患者的血糖均值”,不会泄漏患者的个人信息,所以也不需要患者的授权。
MedRec的智能合约基本还是从数据库设计的角度出发,考虑的是如何简洁高效地把数据的关系表示清楚,但它无意中遵循了一些Linked Data对数据建模的原则。如果一开始就从Linked Data的设计原则(而不是具体的RDF语法或者W3C标准)出发,这个智能合约的结构应该还可以优化。
另外,请各位RDF(Resource Description Framework)大神不要追究我对RDFStatement,RDFResource,RDFGraph或者Reification等概念的语义内涵或外延不严谨的陈述,这里只是示意而已。
MedRec的系统实现
我觉得MedRec最核心的是智能合约设计,至于系统的实现会因为底层区块链平台的不同选择(Ethereum或HyperLedger或其它平台),或者架构师对工程美学的不同理解而千差万别。
出于完整性的角度,我也非常简单地介绍一下MedRec的系统实现。
MedRec设计了4个模块,通过9个步骤完成资源的注册、病历信息的上链更新、患者授权和病历信息查询等关键过程:
Backend API Library:主要是一些utility功能,简化系统操作的AP;
Ethereum Client:参与和使用Ethereum区块链平台的客户端模块;
Database Gatekeeper:在区块链下访问医疗机构本地数据库的模块I;
EHR Manager:MedRec系统对终端用户的前端用户界面
MedRec可以改进的方面
MedRec比很多随便在HyperLedger上搭的所谓区块链电子病历共享系统的质量高很多,不愧是MIT Media Lab出品。不过它依然只是个原型系统,还有很多方面可以提高,我抛几块砖:
智能合约的设计:Web是目前最成功的异构多模态数据访问和共享架构,Linked Data是Web向结构化数据共享迈进的一步,它的很多设计原则可以应用在基于区块链的电子病历共享系统中,让资源的表示和访问模式更加简洁优美,提高系统的可扩展性和鲁棒性
避免单点失败:目前真正的电子病历数据还是存储在医疗机构本地的数据库中。Web系统设计的初衷就是为了支持大规模多用户访问的,而医疗机构的数据库不是为这个目标设计的,它只是为了支持医院自身的流程管理和分析应用而已。一旦医疗机构的数据库不能被访问,就像微博宕机一样,什么数据都访问不了。目前MedRec去中央数据库的设计并不能避免单点失败的尴尬,也许可以参考Hadoop的思想,在区块链平台的另外2-3个可信赖的节点中保存数据的备份,保证即使某个医疗机构的数据库挂了,真个电子病历共享系统依然不受影响
数据的互操作性:数据共享平台输出的数据格式要满足互操作性的要求。简单的说,就是要让数据使用方能理解查询到的数据,就像Web系统用HTML,Linked Data系统用RDF一样。在医疗领域,除了数据格式的规范,还有医疗术语的语义互操作性。可以考虑目前比较流行的FHIR格式,加上SNOMED-CT这样的医疗术语标准
分布式机器学习:目前MedRec只是个数据查询系统,但并不支持跨医疗机构的数据分析,即使是最基本的统计。可以考虑“加载”类似MapReduce的分布式计算框架,甚至是分布式机器学习框架,支持跨医疗机构的分布式数据分析。
-
什么是区块链?区块链都有哪些应用?2021-06-28 8549
-
区块链分成两部分, 一个是区块,一个是链2021-03-20 8096
-
区块链技术的新用途有哪些2020-06-23 3178
-
《区块链+从全球50个案例看区块链的应用与未来》高清pdf2020-03-13 5069
-
区块链对我们的生活有什么影响2019-07-10 4001
-
区块链能否成为医疗产业进步的关键?2018-12-30 3294
-
区块链+教育,是改革的良性循环?2018-12-20 3453
-
区块链将如何优化产业链?2018-12-13 6918
-
区块链软件开发公司谈未来区块链的主要应用方向2018-11-22 1850
-
区块链软件:区块链可以对金融机构的商业模式带来什么改变呢?2018-11-19 2583
-
区块链技术可为病人隐私和病历提供安全保障2018-09-11 1428
-
区块链将改革供应链2018-08-08 3689
-
什么是区块链 区块链有什么用2018-03-26 10734
-
区块链如何改变AI2018-02-27 3134
全部0条评论

快来发表一下你的评论吧 !
