

谷歌DeepMind围棋吊打世界冠军
电子说
描述
作为 AlphaGo 的最新迭代,DeepMind 又在 11 月 6 日发表的《科学》(Science)论文中,隆重介绍了 AlphaZero 。作为谷歌母公司 Alphabet 旗下的英国人工智能子公司,DeepMind 多年来一直致力于改进 Go AI 。2017 年的时候,前 AI 冠军 AlphaGo 正式退休,但在进一步修补之后,AlphaZero 又达到了新的顶峰。
AlphaZero 是一款能够从头学习围棋、象棋等棋子游戏的新型人工智能平台。在三款棋类比赛中,AlphaZero 将三款 AI 都挑落下马。
● Stockfish:国际象棋 AI 世界冠军;
● elmo:2017 年度世界计算机将棋锦标赛冠军;
● AlphaGo Zero:DeepMind 自家的围棋 AI,被誉为史上最强选手。
在仅仅获知有关游戏基本规则的情况下,AlphaZero 在成为人工智能大师之前,会先自己机型数百万场的对抗练习。
该 AI 初期会实施随机战术来取得胜利,但后续会通过‘强化学习’来试错,以逐步了解哪些策略是最有效的。
实测国际象棋需要 9 小时、将棋 12 小时、围棋 13 天,涉及 5000 个张量处理单元(TPU)。
作为参考,一套 TPU 每天可以处理超过 Google Photos 中的 1 亿+照片,所以 AlphaZero 对硬件处理性能的要求还是比较高的。
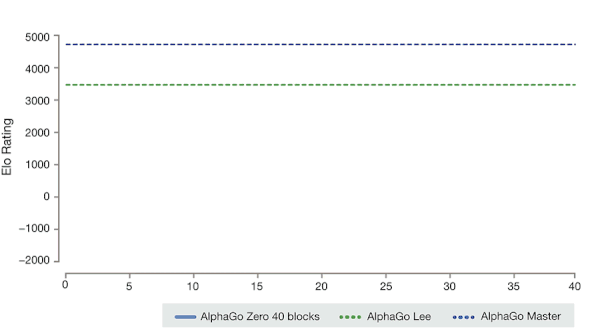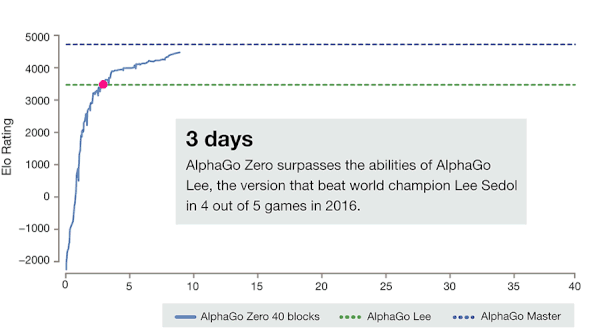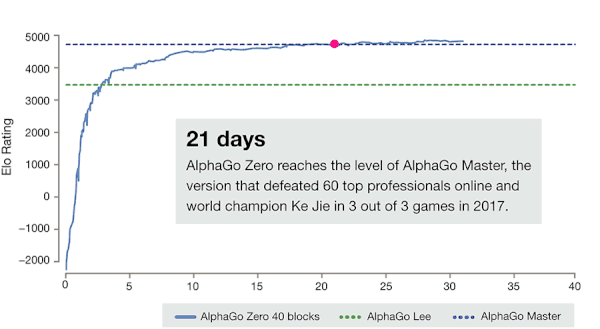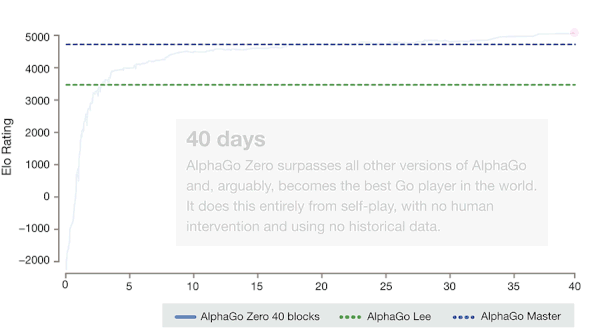
闭关学习结束后,AlphaZero 就可以大杀四方了
这项研究的独特之处在于,研究团队将机器学习算法、与蒙特卡罗树(MCTS)的“搜索方法”结合到了一块。
这是 Go 围棋 AI 决定下一步行动所采用的方式,这次 DeepMind 团队在国际象棋和将棋 AI 上也套用了同样的机制,首次展示了该方法适用于其它复杂的游戏测试。
对于人类国际象棋选手来说,AlphaZero 是极具吸引力的。你可以在与机器对战时,见识到此前从未遇到过的策略、以及一些新颖的想法。
其咄咄逼人的风格、以及高度动态的应变策略,足以让 Matthew Sadler 之类的国际象棋大师感到惊讶(其在 DeepMind 博客上有所表述)。
有关这项研究的详情,已经发表在近日出版的《科学》(Science)期刊上。原标题为:《A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play》《一种通用的强化学习算法,可自学成为国际象棋、将棋、围棋大师》。
-
元萝卜对弈围棋世界冠军见分晓,棋圣聂卫平解说妙语连珠2023-07-31 1808
-
世界冠军级FPV飞手和「人工智能AI」比飞飞机,谁赢了?2022-06-14 1643
-
南卡携手世界冠军郭丹,聚焦女性力量,见证冠军品质2022-03-05 1383
-
未来的AI 深挖谷歌 DeepMind 和它背后的技术2020-08-26 2628
-
从对手到工具 围棋世界冠军亲临济南华为门店谈AI与围棋2019-08-21 531
-
打败围棋天才后,人工智能机器又再次赢得了上风2019-08-19 3388
-
最后一战 AI 2:0吊打世界冠军DOTA2 人类完败2019-07-05 1159
-
解析棋局训练棋手 人工智能助推围棋发展2019-07-02 899
-
谷歌的DeepMind梦能带来多少可能性2018-03-16 1699
-
谷歌DeepMind尝试用AI治疗乳腺癌2017-11-27 953
全部0条评论

快来发表一下你的评论吧 !
