

基于二叉树的ensemble异常检测算法
电子说
描述
iForest (Isolation Forest)是由Liu et al. [1] 提出来的基于二叉树的ensemble异常检测算法,具有效果好、训练快(线性复杂度)等特点。
1. 前言
iForest为聚类算法,不需要标记数据训练。首先给出几个定义:
划分(partition)指样本空间一分为二,相当于决策树中节点分裂;
isolation指将某个样本点与其他样本点区分开。
iForest的基本思想非常简单:完成异常点的isolation所需的划分数大于正常样本点(非异常)。如下图所示:
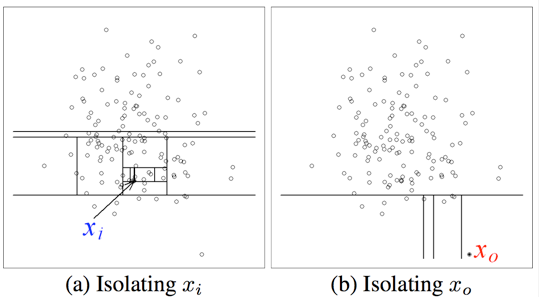
xi 样本点的isolation需要大概12次划分,而异常点x0指需要4次左右。因此,我们可以根据划分次数来区分是否为异常点。但是,如何建模呢?我们容易想到:划分对应于决策树中节点分裂,那么划分次数即为从决策树的根节点到叶子节点所经历的边数,称之为路径长度(path length)。假设样本集合共有n个样本点,对于二叉查找树(Binary Search Tree, BST),则查找失败的平均路径长度为
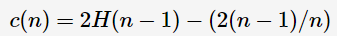
其中,H(i)为harmonic number,可估计为ln(i)+0.5772156649。那么,可建模anomaly score:
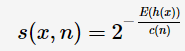
其中,h(x)为样本点x的路径长度,E(h(x))为iForest的多棵树中样本点x的路径长度的期望。特别地,

当s值越高(接近于1),则表明该点越可能为异常点。若所有的样本点的s值都在0.5左右,则说明该样本集合没有异常点。
2. 详解
iForest采用二叉决策树来划分样本空间,每一次划分都是随机选取一个属性值来做,具体流程如下:

停止分裂条件:
树达到了最大高度;
落在孩子节点的样本数只有一个,或者所有样本点的值均相同;
为了避免错检(swamping)与漏检(masking),在训练每棵树的时候,为了更好地区分,不会拿全量样本,而会sub-sampling样本集合。iForest的训练流程如下:

sklearn给出了iForest与其他异常检测算法的比较。
-
二叉树的代码实现2023-01-18 1708
-
C++构建并复制二叉树2023-01-10 1517
-
使用C语言代码实现平衡二叉树2022-09-21 1694
-
怎么就能构造成二叉树呢?2022-07-14 2129
-
C语言数据结构:什么是二叉树?2022-04-21 4296
-
数据结构与算法分析中的二叉树与堆有关知识汇总2021-11-03 687
-
二叉树的前序遍历非递归实现2021-05-28 2402
-
二叉树操作的相关知识和代码详解2020-12-12 2466
-
详解电源二叉树到底是什么2019-06-06 11181
-
二叉树,一种基础的数据结构类型2019-04-13 4973
-
二叉树层次遍历算法的验证2017-11-28 2336
-
基于二叉树的时序电路测试序列设计2012-07-12 999
-
基于二叉树分解的自适应防碰撞算法2009-11-17 662
-
二叉树算法在单总线技术中的应用2009-03-16 759
全部0条评论

快来发表一下你的评论吧 !
