

利用FPGA工具设置优化FPGA HLS设计
嵌入式技术
描述
用软件从 C 转化来的 RTL 代码其实并不好理解。今天我们就来谈谈,如何在不改变 RTL 代码的情况下,提升设计性能。
本项目所需应用与工具:赛灵思HLS、Plunify Cloud 以及 InTime。
前言
高层次的设计可以让设计以更简洁的方法捕捉,从而让错误更少,调试更轻松。然而,这种方法最受诟病的是对性能的牺牲。在复杂的 FPGA 设计上实现高性能,往往需要手动优化 RTL 代码,这也意味着从 C 转化得到 RTL 基本不可能。其实,使用 FPGA 工具设置来优化设计可以最小限度地减少对性能的牺牲,这种方法是存在的。
高效地找到合适的FPGA工具设置
尽管工程师们知道 FPGA 工具的设置,但是这些设置往往并没有充分利用。一般而言,工具设置只有在出现时序问题的时候才会派上用途。然而,对于已经达到性能目标的设计来说,如果继续调整工具设计,仍然有10%-50%的性能提升潜力。
真正的难点在于选择正确的工具设置,毕竟各种 FPGA 工具一般都有有30-70个不同的布局布线设置,可选的设置组合实在是太多了。您可以写脚本来运行不同的推荐指令/策略。市面上也有工具,来自动管理并运行设计探索。
另一个难点就是不充裕的计算能力。典型的嵌入式应用是在单台电脑上设计的。运行多个编译需要更多的计算能力,这就要求更多的时间。如果您可以(使用云计算)并行运行,周转时间就会变短。
如何优化高层次的设计 - “Sobel滤镜”项目
这是一个用于视屏处理的参考设计,来自赛灵思的官网 https://china.xilinx.com/support/documentation/application_notes/xapp890.。. 。该设计的功能是 Sobel 滤镜,目标器件是拥有双核Dual ARM® Cortex®-A9MPCore 的 FPGA。
我们使用赛灵思 HLS 来打开这个设计。
图一:参考设计– Sobel滤镜
它的时钟周期是5.00ns,也就是200MHz。从下图的时序预估中可以看出,它离时序目标还差506ps(181MH1),也就是比目标速率还差10%。

图二:当前时序结果
导出成 RTL 项目
不需要改变 C++ 代码,把设计输出成一个RTL 的 Vivado 项目。在 “Solution”下面,选择“Export RTL”。
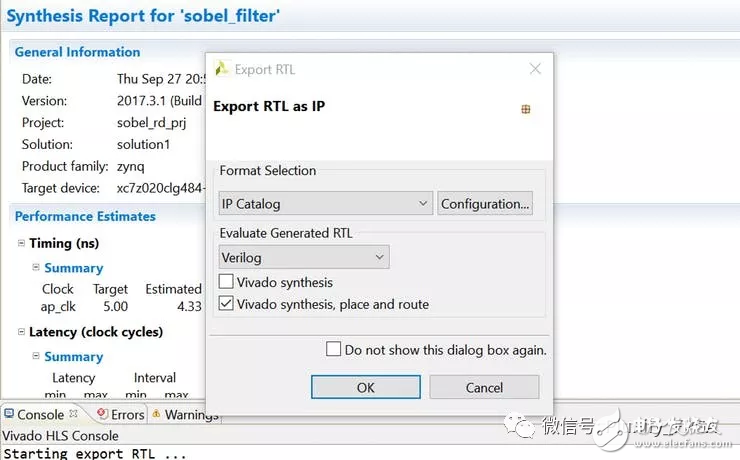
图三:从HLS输出Vivado项目
它会在后台执行 Vivado,并生成一个项目文件(XPR)。它同时也会编译设计,您应该在控制台(Console)看到真实的时序细节。一旦完成,您可以在 /solution/impl/verilog/ 文件夹下找到项目文件。
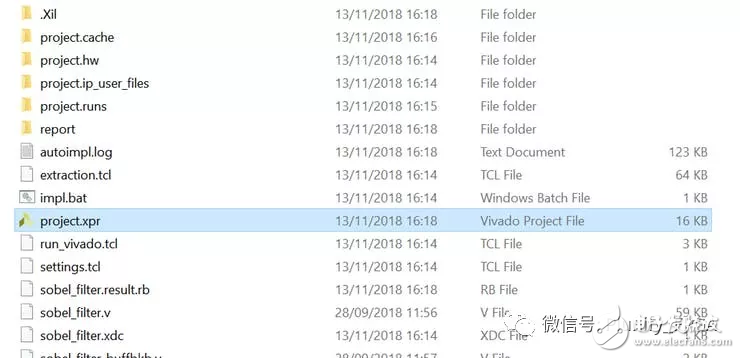
图四:Vivado 项目文件
找到这个 XPR 文件之后,您可以用 Vivado 打开它来验证。您将看到生成好的 RTL 源文件。
图五:从 HLS 生成的 RTL
时序优化
下一步,是使用 InTime 设计探索工具,当然,您也可以自己写脚本来尝试 Vivado 工具中自带的指令和策略。请申请 InTime 的免费试用在本地运行,也可以注册一个 Plunify Cloud 云平台的账户,试用所提供的免费云币来在云端运行预置好的 FPGA 工具。
启动 InTime 之后,打开项目文件。在选择 Vivado 版本时,请使用“相同的”版本。例如,如果您使用2017.3 HLS,请选择2017.3 Vivado。
选择“Hot Start”配方(recipe)。此配方包含一系列更具以往其他设计的经验而推荐的策略。
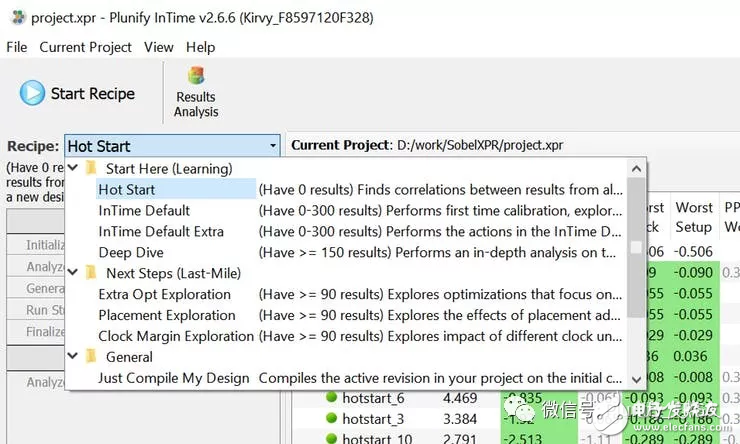
图六:选择 “Hot Start” 配方
点击“Start Recipe”来开始优化。如果您在云端运行,您应该并行运行多个编译来减少周转时间。
优化过程和结果
第一轮结束之后 (“Hot Start”配方),最好的结果是“hotstart_1”策略。然而,它仍然距离目标时序90ns。
我们在“HotStart_1”的结果上使用了第二个配方,叫做“Extra Opt Exploration”。这一轮将集中优化关键的路径。这是一次迭代优化,并且只要仍有提升,就不断地重复自己。如果达到时序目标或者不再提升的时候,它就会停止。
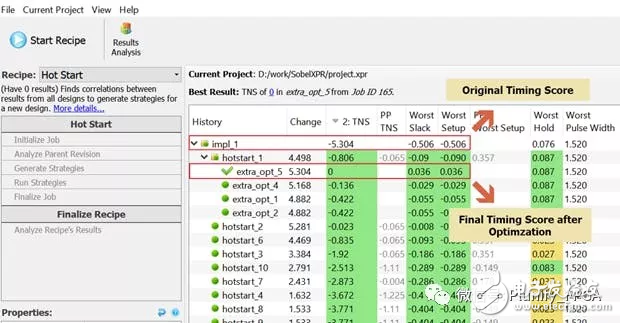
图七:仅通过工具设置完成时序收敛
经过两轮优化,总共15此编译后,设计达到了目标时序,200MHz。而这一切完全没有修改 RTL 源代码。
让性能更进一步
让性能更进一步需要各方面的优化 – 结构设计、代码和工具。工具设置的探索可以克服高层次设计的性能牺牲,并且不会让生产效率的好处减少。对于高层次设计的工程师来说,这是一种共赢。
-
如何在不改变RTL代码的情况下,优化FPGA HLS设计2020-12-20 2657
-
优化 FPGA HLS 设计2024-08-16 1130
-
怎么利用Synphony HLS为ASIC和FPGA架构生成最优化RTL代码?2019-08-13 2687
-
FPGA高层次综合HLS之Vitis HLS知识库简析2022-09-07 3889
-
使用Vivado高层次综合 (HLS)进行FPGA设计的简介2016-01-06 1474
-
FPGA设计中的HLS 工具应用2018-06-04 7822
-
FPGA并行编程:基于HLS技术优化硬件设计2018-11-10 3305
-
XIlinx利用HLS进行加速设计进度2019-07-31 7729
-
利用fpga软件工具实现快速无误的优化过程2019-10-16 3628
-
使用网络实例比较FPGA RTL与HLS C/C++的区别2022-08-02 2421
-
ThunderGP:基于HLS的FPGA图形处理框架2022-10-27 931
-
FPGA基础之HLS2022-12-02 7840
-
AMD-Xilinx FPGA功耗优化设计简介2022-12-29 2703
-
FPGA——HLS简介2023-01-15 6917
-
如何使用HLS加速FPGA上的FIR滤波器2023-06-14 1162
全部0条评论

快来发表一下你的评论吧 !
