

内存性能的正确解读
今日头条
描述
一台服务器,不管是物理机还是虚拟机,必不可少的就是内存,内存的性能又是如何来衡量呢。
1. 内存与缓存
现在比较新的CPU一般都有三级缓存,L1 Cache(32KB-256KB),L2 Cache(128KB-2MB),L3 Cache(1M-32M)。缓存逐渐变大,CPU在取数据的时候,优先从缓存去取数据,取不到才去内存取数据。
2. 内存与时延
显然,越靠近CPU,取数据的速度越块,通过LMBench进行了读数延迟的测试。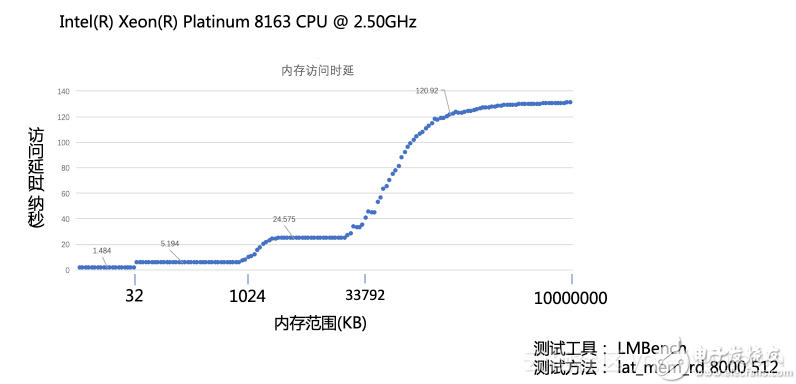
从上图可以看出:
Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz 这款CPU的L1D Cache,L1I Cache为32KB,而L2 Cache为1M,L3为32M;
在对应的Cache中,时延是稳定的;
不同缓存的时延呈现指数级增长;
所以我们在写业务代码的时候,如果想要更快地提高效率,那么使得计算更加贴近CPU则可以获取更好的性能。但是从上图也可以看出,内存的时延都是纳秒为单位,而实际业务中都是毫秒为单位,优化的重点应该是那些以毫秒为单位的运算,而内存时延优化这块则是长尾部分。
3. 内存带宽
内存时延与缓存其实可谓是紧密相关,不理解透彻了,则可能测的是缓存时延。同样测试内存带宽,如果不是正确的测试,则测的是缓存带宽了。
为了了解内存带宽,有必要去了解下内存与CPU的架构,早期的CPU与内存的架构还需要经过北桥总线,现在CPU与内存直接已经不需要北桥,直接通过CPU的内存控制器(IMC)进行内存读取操作:
那对应的内存带宽是怎样的呢?测试内存带宽有很多很多工具,linux下一般通过stream进行测试。简单介绍下stream的算法: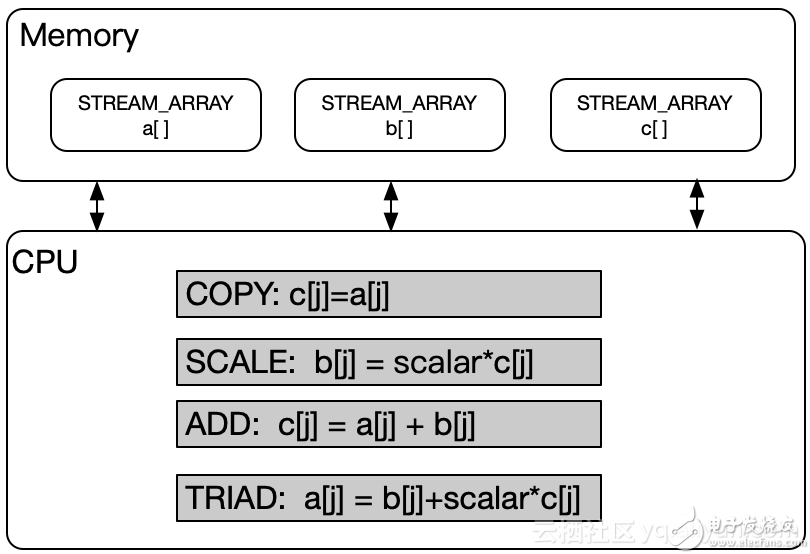
stream算法的原理从上图可以看出非常简单:某个内存块之间的数据读取出来,经过简单的运算放入另一个内存块。那所谓的内存带宽:内存带宽=搬运的内存大小/耗时。通过整机合理的测试,可以测出来内存控制器的带宽。下图是某云产品的内存带宽数据:
------------------------------------------------------------- Function Best Rate MB/s Avg time Min time Max timeCopy: 128728.5 0.134157 0.133458 0.136076Scale: 128656.4 0.134349 0.133533 0.137638Add: 144763.0 0.178851 0.178014 0.181158Triad: 144779.8 0.178717 0.177993 0.180214-------------------------------------------------------------
内存带宽的重要性自然不言而喻,这意味着操作内存的最大数据吞吐量。但是正确合理的测试非常重要,有几个注意事项需要关注:
内存数组大小的设置,必须要远大于L3 Cache的大小,否则就是测试缓存的吞吐性能;
CPU数目很有关系,一般来说,一两个核的计算能力,是远远到不了内存带宽的,整机的CPU全部运行起来,才可以有效地测试内存带宽。当然跑单核的stream测试也有意义,可以测试内存的延时。
4. 其他
内存与NUMA的关系:开启NUMA,可以有效地提供内存的吞吐性能,降低内存时延。
stream算法的编译方法选择:通过icc编译,可以有效地提供内存带宽性能分。原因是Intel优化了CPU的指令,通过指令向量化和指令Prefetch操作,加速了数据的读写操作以及指令操作。当然其他C代码都可以通过icc编译的方法,提供指令的效率。
- 相关推荐
- 热点推荐
-
HarmonyOS优化应用内存占用问题性能优化一2025-05-21 712
-
DDR5内存与DDR4内存性能差异2024-11-29 4723
-
DDR内存频率对性能的影响2024-11-20 5645
-
RAM内存频率对性能的影响2024-11-11 8057
-
嵌入式释放RTOS内存性能的使用技巧2022-09-27 2731
-
为您的设计选择正确的内存解决方案2021-07-27 1188
-
影响内存性能的主要指标有哪些呢?2021-06-18 1638
-
苹果手机必备知识:如何正确清理内存,使系统更加流畅2020-10-22 4222
-
内存时序对内存性能的影响有哪些2020-09-03 6333
-
内存条正确插拔的方法2019-09-18 29996
-
正确选择内存条的4个小技巧2018-09-24 17626
-
这个差分运放和三阶滤波的正确解读姿势?2017-09-26 4740
-
Labview性能和内存信息2016-02-23 6841
-
【mfxp】如何正确设置Windows7系统虚拟内存2013-02-03 2498
全部0条评论

快来发表一下你的评论吧 !
