

微流体压缩通道阵列结合机器学习识别乳腺癌细胞
电子说
描述
癌症一直以来是威胁人们生命健康的首要疾病,随着世界范围内科技进步发展,自身因素导致的突变和外部因素诱导的癌症患者数量大幅提升。目前各种抗癌药物研发和治疗手段的发展在临床应用上起到了一定程度的效果,但癌细胞的抗药性和抗治疗方法特性也在不断改变。针对患者自身的癌细胞扩散程度建立治疗方案的“个性化医疗”和“精确医疗”理念也在不断完善和发展。精确医疗需要在诊断病人癌细胞的扩散程度和转移能力方面达到个性化识别。
微流体技术已经广泛应用于细胞的识别,生物物理特性检测,以及药物治疗效果的检测分析。很多综述文章讨论过对于微流体通道本身的制造方法和结构的改进,用来促进不同种类细胞的识别和测量。这种器件可以同时处理大量样品,同时保证达到单细胞精度,确保单个细胞通过多级的压缩和舒张区域,达到对细胞骨架和细胞膜生物机械特性的测量。在细胞检测数据的分析方面,引入机器学习和人工智能算法属于未来医疗的趋势。在医院诊断方面,使用人工智能算法可以综合大量数据作为分析和学习的数据库,可以提供更精确的数据判断结果。
图1:(TOC图)微流体压缩通道阵列识别癌细胞
微流体芯片采用光敏树脂SU-8 3005和3025作为硅片上的光刻材料,可以制造出宽6-10微米,高8-10微米的压缩区通道,以及宽30-40微米,高20-30微米的舒张区。首先在清洁的硅片上添加SU-83025作为第一层,使用能量为300mJ/cm2的紫外光固化。经过SU-8洗涤清洗后干燥,再添加较厚的SU-8 3025作为第二层,使用能量为350mJ/cm2的紫外光固化,洗去不需要的结果之后,用异丙醇清洗整个硅片,同时在硅胶PDMS反向注模之前保持清洁。在确保没有多余气泡产生的情况下,PDMS在65°C 的加热24小时,即可取下作为微流体的主要部分。经过氧气的等离子处理表面70秒后,可与玻璃粘合成为微流体芯片。
在压缩区中,所有细胞都会在流体压力的情况下发生形变,其通过速度可以有高速照相机捕捉。当细胞进入舒张区时,较容易变形的细胞,比如癌细胞,更容易恢复其原有的形状,当进入下一个压缩区时,二次形变发生的程度都会有第一次形变有所不同,表现为在微流体通道中,通道壁与细胞表面的切应力发生非线性的变化,因而改变通过的速度。这一速度变化可以作为标示生物机械特性的一组变量。如果进入微流体通道的是正常细胞,通常正常上皮细胞有更结实的细胞骨架结构,更不容易发生形变,而在微流体压力作用下发生形变之后,在舒张区不容易恢复其原有形态,所以可以更快地通过第二次压缩变形,从而显示出与癌细胞不一样的速度分布。根据这种速度分布,我们可以总结出单个细胞的速度特性,而这种速度特性间接地表现出细胞结构的强度和杨氏模量等参数,从而间接的识别癌细胞与正常细胞。
图2:实验装置示意图(X.Ren,et al., ACS Sensors,2017, 2 (2), 290-299)。
除此之外,对于宽度超过细胞大小的舒张区可以给细胞完全恢复原有形态的机会,我们还可以设计出相对于这种“完全舒张区”的“部分舒张区”微流体通道。现有设计中30微米以上的舒张区可以改为9-12微米的部分舒张区。当细胞在舒张区试图恢复原有形态的时候,部分舒张区只允许细胞恢复到9-12微米的柱状,这种形态下,不同种类的细胞会表现出与完全舒张区不同的速度分布特性。对于我们使用机器学习方法的项目,产生这种更独特的速度分布数据只会更有利于最终的结果分析。尤其是针对临床样品的癌细胞研究,当检测某种特定的抗癌药物的药效时,尽可能精确的区分产生药效的和为产生药效,或者本身已经产生抵抗药物的现象下的癌细胞就尤为重要。采用这种多级的微流体芯片能获取尽可能多的细胞生物机械特性数据。
图3:(a)微流体通道示意图;(b)采集到的细胞速度。
Kernel模型的机器学习方法可以实现针对高维变量的大数据分析。主要采用三种方法:Ridge,NGK,和Lasso。其中Ridge和Lasso都是基于线性模型,而NGK突出非线性变量在模型中的权重。采集到的细胞生物机械特性由大量的速度变量组成,同时不同运算下的速度变量又可以产生大量的高维变量。传统的数据处理和数据分析在处理这样大量的数据结果时不容易捕捉到有效变量和有效的变量内在关系,所以使用机器学习的方法可以用于快速,有效地识别不同类型的细胞。
选取变量是第一步,比如间接描述生物机械特性的速度变量,在一个微流体通道中可以定义12个速度变量v1, v2, … , v12。进一步可以定义速度变化率,比如αm,n=(vm-vn)/vn, (m=1,2,…,12; n=1,2,…,12),这样就可以再产生66个变量。
首先,将所有高维变量数据分为10组,以便于交叉运算。首先考虑对每种细胞类型t,t=1,…,T,做n次测量,得到p个变量的数据组(y,Xt), 其中 Xt=[x1t,x2t,…,xpt],定义xjt=[xj1t,xj2t,…,xjnt]T是一个第j组的n×1的向量,有j=1,…,p.对于Ridge和Lasso,根据变量产生线性模型:
其中H是函数,而且有:
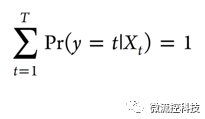
Ridge和Lasso分别采用L2绝对值||β||2和L1绝对值||β||,其中β=(β0,β1,…, βp)T。Ridge的目标函数是得到下面这个方程的最小值:
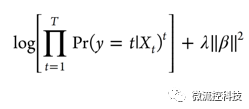
而Lasso的目标是得到下面这个方程的最小值:
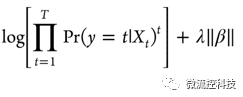
NGK与这两种不同,NGK除了寻找高维变量的线性关系外,还加入非线性模型kernel函数,包含非显著的隐藏变量,此模型表述为:
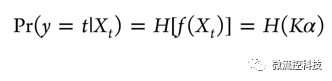
其中f(Xt)是未知函数,K是kernel矩阵对应的希尔伯特空间,而α是未知常数。这样kernel模型可以表达为一个非线性方程:
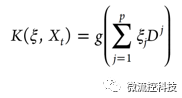
其中g是未知的高斯形态函数,Dj是第(k,l)个输入的dklj=-(xjk-xjl)2组成的矩阵。这时选用变量ξ=(ξ0,ξ1,…, ξp),NGK的目标函数则是:
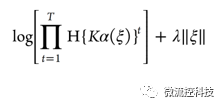
每次使用10组数据中的9组作为机器学习的训练组,用剩余的1组作为检验组,通过反复选组10次,可以获得预测值。包括最大值,最小值,Q25,Q50(中值),Q75,和平均值。
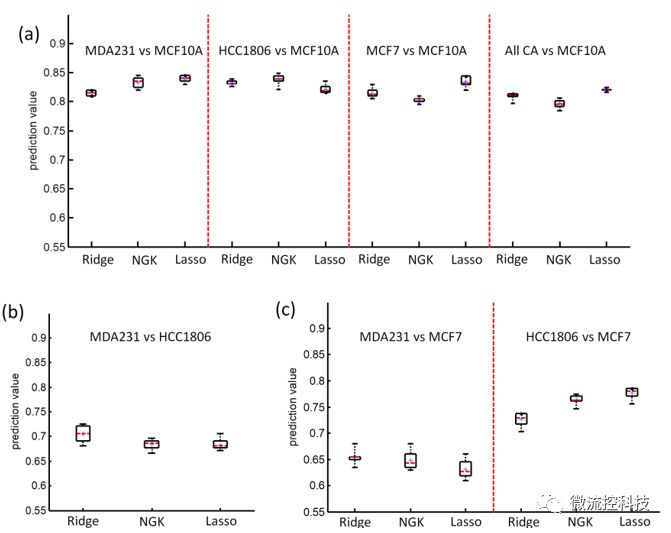
图4:细胞系的Kernel机器学习预测结果。
仅使用16组微流体通道中细胞的速度变量作为目标的高维变量组,使用三种机器学习方法识别出的不同类型的细胞,TNBC乳腺癌细胞MDA-MB-231与普通上皮细胞MCF-10A的识别率为81-84%,其中NGK和Lasso方法比Ridge方法的结果更显著。同样对于TNBC的HCC-1806与普通细胞对比结果为82-85%;而ER+/PR+/Her2-的乳腺癌细胞MCF-7与普通细胞对比结果为80-84%。所以基于癌细胞和正常细胞的生物机械特性,机器学习方法就可以达到80%以上的识别率。
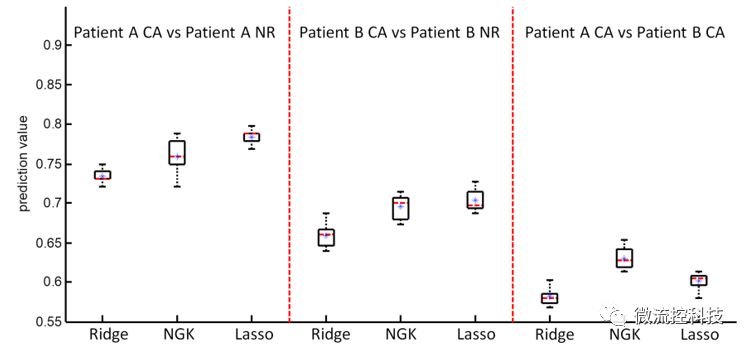
图5:病人乳腺癌组织的Kernel机器学习预测结果。
同样的方法应用于乳腺癌病人的活检样品上,由于淋巴细胞和巨噬细胞存在的情况,机器学习预测结果比细胞系较低,但仍能给活检样品提供转移性和浸润性提供数据支持。
文章信息:Xiang Ren, Parham Ghassemi, Yasmine M.Kanaan, Tammey Naab, Robert L. Copeland, Robert L. Dewitty, Inyoung Kim,Jeannine S. Strobl, and Masoud Agah. "Kernel-basedmicrofluidic constriction assay for tumor sample identification." ACS sensors, vol. 3, no. 8 (2018):1510-1521.
这篇2018年的文章延续了作者2017年发表在ACS Sensors上的文章。
-
基于逻辑回归算法的乳腺癌肿瘤二分类预测2019-06-18 3395
-
基于kNN算法可以诊断乳腺癌2019-06-21 2036
-
HE染色乳腺癌组织病理图像分析2017-11-22 3764
-
DeepMind通过机器学习技术有助于改善乳腺癌2017-12-12 1095
-
谷歌DeepMind放下围棋 转攻乳腺癌2018-04-24 1293
-
英特尔携手汇医慧影,利用AI技术检查乳腺癌2018-09-30 1738
-
乳腺钼靶AI落地临床,乳腺癌患者的福音2018-10-19 3540
-
AI新闻:训练AI检测乳腺癌2018-11-05 2582
-
如何使用机器学习方法进行乳腺癌的辅助诊断2019-01-17 1216
-
MIT研究员最新AI模型可提前5年预测乳腺癌风险!2019-05-11 5060
-
谷歌人工智能模型乳腺癌识别还存在什么没有完善的2020-01-03 1067
-
人工智能乳腺癌诊断能力精确 在防控乳腺癌的长期战斗中取得突破2020-01-07 884
-
复旦肿瘤医院与华米联手研究:可穿戴设备可促进乳腺癌康复2020-11-03 1913
-
使用Movidius和UP2进行乳腺癌分类2023-06-13 681
-
利用微流控技术模拟骨仿生微环境促进乳腺癌进展机理研究2023-07-11 1595
全部0条评论

快来发表一下你的评论吧 !
