

谷歌新研究使用连续拍摄的一对非模糊图像,能够合成运动模糊图像
电子说
描述
要想拍摄运动模糊效果的照片,需要高超的摄影技术。最近,谷歌两名研究员开发了一种新算法,能够使用两张清晰图像合成运动模糊效果。该技术也可用来合成训练去模糊算法所需的训练数据。
谷歌的研究人员最近开发了一种新技术,使用连续拍摄的一对非模糊图像,能够合成运动模糊图像。在发表在arXiv上的预印版论文中,研究人员概述了他们的方法,并与几种基线方法对比,对其进行了评估。
当场景中的物体或相机本身在拍摄时发生移动,运动模糊就会自然产生。这导致移动的物体或整个图像看起来是模糊的。在某些情况下,运动模糊可以用来表示被摄对象的速度或将其与背景分离。
“在图像理解方面,运动模糊是一个有价值的线索,”进行这项研究的谷歌研究员Tim Brooks和Jonathan Barron在论文中写道:“给定一个包含运动模糊的图像,我们可以估计导致观察到的模糊的场景运动的相对方向和幅度。这种运动估计在语义上可能是有意义的,或者可以用去模糊算法来合成一个清晰的图像。”
最近的研究已经探讨了使用深度学习算法从图像中去除不想要的运动模糊或推断给定场景的运动动力学。然而,为了训练这些算法,研究人员需要大量的数据,这些数据通常是通过合成模糊图像生成的。最终,深度学习算法在多大程度上能够有效去除真实图像中的运动模糊,很大程度上取决于用于训练运动模糊的合成数据的真实性。
“在这篇论文中,我们将这个已经有充分研究的模糊估计/模糊去除任务的逆向问题视为一个头等问题。”Brooks和Barron在他们的论文中写道:“我们提出了一种快速有效的方法来合成训练运动去模糊算法所需的训练数据,并且我们定量地证明了我们的技术能够从合成的训练数据推广到真实的运动模糊图像。”
图1:(a)中展示了一个物体在图像平面上移动的两幅图像。我们的系统利用这些图像合成(b)中的运动模糊图像,它传达了一种运动的感觉,并将主体与背景分离。
他们设计的神经网络架构包括一个新的“线性预测”(line prediction)层,它会教一个系统从连续拍摄的两张图像退回到跨越这两张输入图像捕获时间的运动模糊图像。他们的模型需要大量的训练数据,因此研究人员设计并执行了一种新策略,该策略使用帧插值技术(frame interpolation)生成运动模糊图像及其各自输入的大型合成数据集。
架构的图示:以两个输入图像的连接作为输入,并使用U-Net卷积神经网络来预测线性预测层的参数
Brooks和Barron还拍摄了一组由慢动作视频合成的高质量的真实运动模糊图像,然后用这些图像来评估他们的模型与基线技术。他们的模型取得了非常好的结果,在准确性和速度上都优于现有的方法。
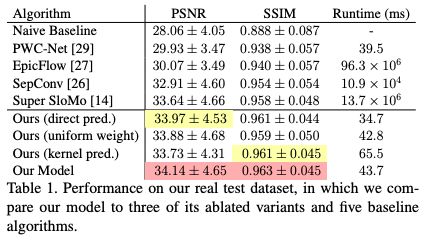
表1:在真实测试数据集上的性能,其中我们的模型与3个简化变体和5个基线算法进行比较
研究人员在论文中写道:“我们的方法快速、准确,并且使用来自视频或’突发’的现成图像作为输入,因此能够为摄影应用程序提供运动模糊处理,或为去模糊算法或运动估计算法所需的真实训练数据的合成提供一种途径。”
从合成训练数据集中随机抽取的5组输入/输出图像对
虽然经验丰富的摄影师经常将动态模糊视为一种艺术效果,但拍摄有效的动态模糊照片是非常具有挑战性的。在大多数情况下,这些图像是长期试错过程的产物,而且需要先进的技术和设备。
在有经验的摄影师手中,利用运动模糊可以产生引人注目的照片,像(a)那样。但是对于大多数业余摄影师来说,运动模糊更有可能像(b)那样。
由于难以获得高质量的运动模糊效果,大多数消费者相机都被设计成尽可能少地拍摄运动模糊的图像。这意味着业余摄影师几乎没有空间能在他们的图像中尝试运动模糊。
“通过将普通消费者相机拍摄到的传统非模糊图像合成为运动模糊图像,我们的技术允许非专业人士在拍摄后创建运动模糊图像。”研究人员在论文中解释道。
最终, Brooks和Barron设计的方法可能会有许多有趣的应用。例如,它可以帮助业余摄影师实现艺术运动模糊效果,同时也能为训练深度学习算法合成更逼真的运动模糊图像。
-
模糊图像处理解决方案2014-06-11 17417
-
工业相机在高速抓拍图像中的应用2015-11-18 8378
-
【NanoPi M2试用体验】图像的模糊2016-06-19 3572
-
基于小波域的图像自适应模糊增强2010-01-15 811
-
模糊目标轮廓图像分割研究2011-07-21 510
-
基于频谱分析的运动模糊图像的参数鉴别2011-11-10 892
-
匀速直线运动模糊图像复原的改进算法2012-03-05 660
-
基于直觉模糊推理的医学图像融合方法研究2012-03-22 1082
-
blur图像模糊2016-06-06 423
-
基于运动模糊图像盲复原方法2017-10-31 917
-
高信躁比无模糊图像的解决方案2017-11-06 867
-
基于能量估计的局部运动模糊检测2017-12-11 957
-
一种新的图像局部模糊区域检测方法2018-02-05 1162
-
如何才能复原运动模糊图像详细资料说明2019-11-01 1457
-
基于深度学习的图像去模糊算法及应用2022-10-28 4055
全部0条评论

快来发表一下你的评论吧 !
