

针对计算机生成的假脸假视频DeepFake较为全面测评的论文
电子说
描述
根据一篇针对计算机生成的假脸假视频DeepFake较为全面测评的论文,现有的先进人脸识别算法在面对计算机生成的假脸时基本束手无策,假脸生成算法和人脸识别军备竞赛已经开始。不过,目前还有些小技巧,可以帮你用肉眼来分辨计算机生成的假脸。
2015年,现任教皇方济各 (Pope Francis) 访美,他是首次对美国进行正式访问的教皇,还将主持在美国领土上的首次封圣,并在国会发表演讲。时任美国总统和副总统的奥巴马及拜登,分别携各自的夫人,一起在美国安德鲁斯空军基地 (Andrews Air Force Base,也是总统机队“空军一号”的驻地) 迎接了教皇专机的降临。
访问期间,方济各“一个出人意料之举”震惊了世界:只见他在向圣坛礼拜后,转身顺手将桌布一抽,上演了一出绝妙的“抽桌布”戏法,动作之行云流水,令人膜拜。
教皇竟然还会这一手!相关视频很快就火遍了全美乃至全球。
2015年现任教皇访美,上演绝妙“抽桌布”戏法,美国主教看后表示不爽。当然,这段视频是假造的,但这并不影响其流行。
世人震惊之余,几乎都没有怀疑——这个视频当然是假造的。
在“毫无PS痕迹”的说法还十分流行的2015年,这个“毫无PS痕迹”的视频成了后来被称为DeepFake视频的始祖。
现如今,DeepFake已被用于指代所有看起来或听起来像真的一样的假视频或假音频。
日前,Idiap 生物识别安全和隐私小组负责人 (注:Idiap研究所是瑞士的一家半私人非营利性研究机构,隶属于洛桑联邦理工学院和日内瓦大学,进行语音、计算机视觉、信息检索、生物认证、多模式交互和机器学习等领域的研究)、瑞士生物识别研究和测试中心主任 Sébastien Marcel 和他的同事、Idiap 研究所博士后 Pavel Korshunov 共同撰写了论文,首次对人脸识别方法检测 DeepFake 的效果进行了较为全面的测评。

他们经过一系列实验发现,当前已有的先进人脸识别模型和检测方法,在面对 DeepFake 时基本可以说是束手无策——性能最优的图像分类模型 VGG 和基于 Facenet 的算法,分辨真假视频错误率高达 95%;基于唇形的检测方法,也基本检测不出视频中人物说话和口型是否一致。
Pavel Korshunov 和 Sébastien Marcel 指出,随着换脸技术的不断发展,更加逼真的 DeepFake 视频,将对人脸识别技术构成更大的挑战。
“在 DeepFake 方法和检测算法之间的一场新的军备竞赛可能已经开始了。”
面对假脸生成算法,现有人脸识别系统几乎束手无策
针对 Deepfake 视频中人脸识别的漏洞,两人在论文中对基于VGG和Facenet的人脸识别系统做了漏洞分析,还使用SVM方法评估了 DeepFake 的几种检测方法,包括嘴唇动作同步法和图像质量指标检测等。
结果令人遗憾——
无论是基于VGG还是基于Facenet的系统,都不能有效区分GAN生成假脸与原始人脸。而且,越先进的Facenet系统越容易受到攻击。
VGG模型是2014年ILSVRC竞赛的第二名,第一名是GoogLeNet。但是VGG模型在多个迁移学习任务中的表现要优于googLeNet。而且,从图像中提取CNN特征,VGG模型是首选算法。它的缺点在于,参数量有140M之多,需要更大的存储空间。但是这个模型很有研究价值。
Facenet该模型没有用传统的softmax的方式去进行分类学习,而是抽取其中某一层作为特征,学习一个从图像到欧式空间的编码方法,然后基于这个编码再做人脸识别、人脸验证和人脸聚类等。
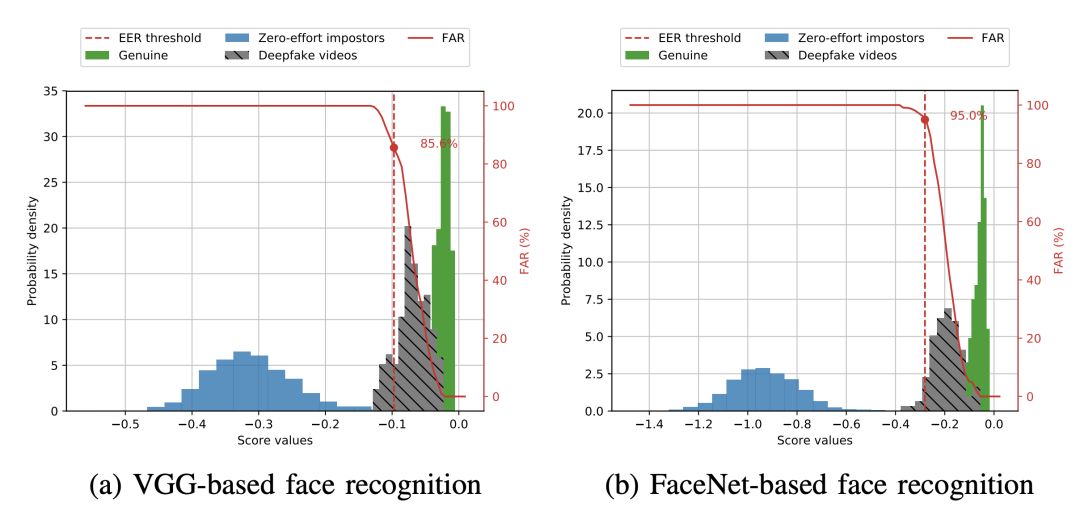
直方图显示了基于VGG和Facenet的人脸识别在高质量人脸交换中的漏洞。
检测Deepfake视频
他们还考虑了几种基线Deepfake检测系统,包括使用视听数据检测唇动和语音之间不一致的系统,以及几种单独基于图像的系统变体。这种系统的各个阶段包括从视频和音频模态中提取特征,处理这些特征,然后训练两个分类器,将篡改的视频与真实视频分开。
所有检测系统的检测结果如下表所示。
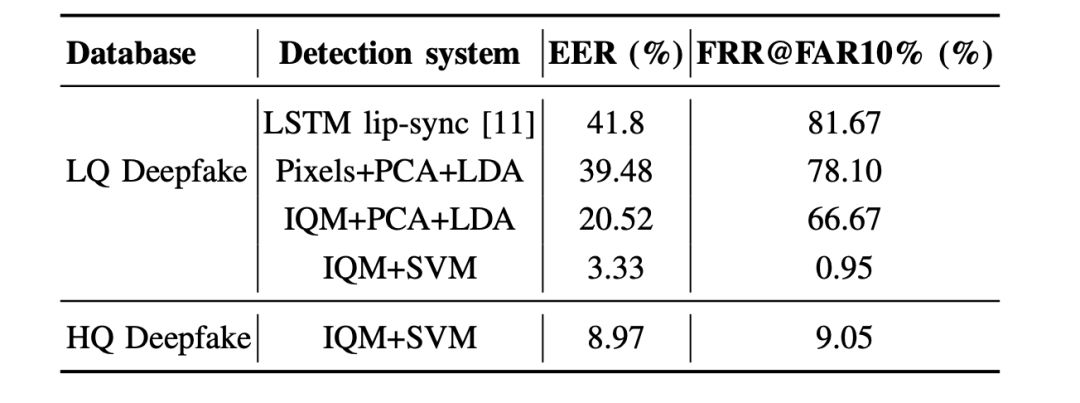
说明一下表格中各种“符号”和数字的意思,你也可以直接跳过看本节最后结论:
在本系统中,使用MFCCs作为语音特征,以mouth landmarks之间的距离作为视觉特征。将主成分分析(PCA)应用于联合音视频特征,降低特征块的维数,训练长短期记忆(long short-term memory, LSTM)网络,将篡改和非篡改视频进行分离。
作为基于图像的系统,实现了以下功能:
Pixels+PCA+LDA:使用PCA-LDA分类器将原始人脸作为特征,保留99%的方差,得到446维变换矩阵。
IQM+PCA+LDA:IQM特征与PCA-LDA分类器结合,具有95%保留方差,导致2维变换矩阵。
IQM + SVM:具有SVM分类器的IQM功能,每个视频具有20帧的平均分数。
基于图像质量测度(IQM)的系统借鉴了表示域(domain of presentation )的攻击检测,表现出了较好的性能。作为IQM特征向量,使用129个图像质量度量,其中包括信噪比,镜面反射率,模糊度等测量。
下图为两种不同换脸版本中性能最好的IQM+SVM系统的检测误差权衡(DET)曲线。
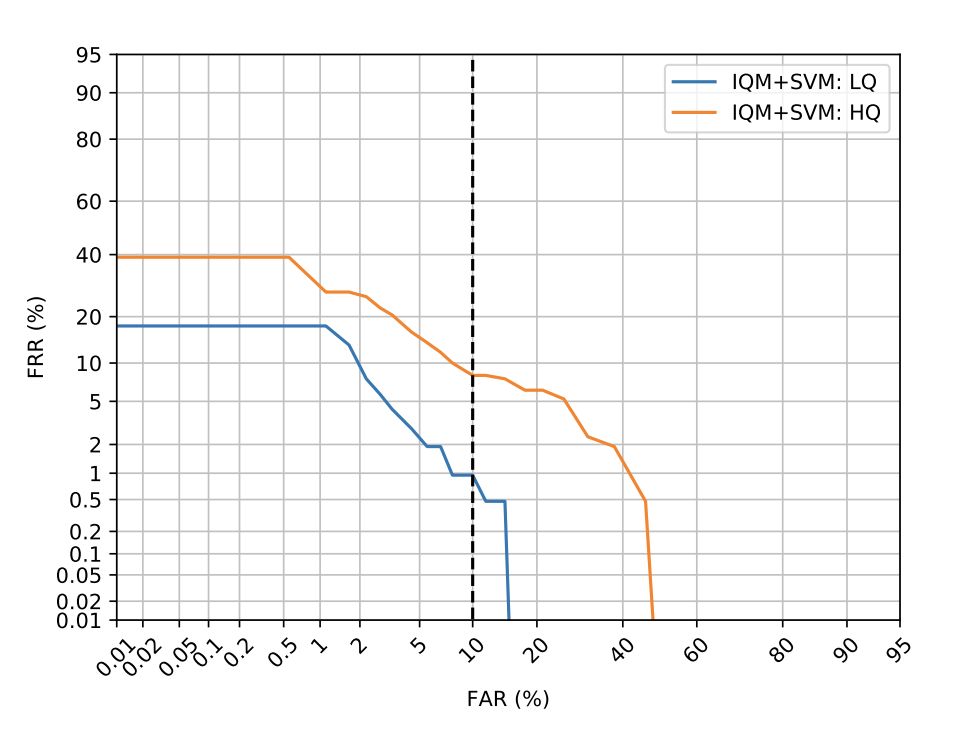
IQM + SVM Deepfake检测
结果表明:
首先,基于唇部同步的算法不能检测人脸交换,因为GAN能够生成与语音匹配的高质量面部表情;因此,目前只有基于图像的方法才能有效检测Deepfake视频。
其次,IQM+SVM系统对Deepfake视频的检测准确率较高,但使用HQ模型生成的视频具有更大的挑战性,这意味着越先进的人脸交换技术将愈发难以检测。
假脸生成和真脸识别算法军备竞赛已经开始
之前,大多数研究都集中在如何提高“换脸”技术上,为了响应公众对检测”换脸“技术的需求,越来越多的研究人员开始研究数据库和检测方法,包括使用较旧的换脸方法Face2Face 生成的图像和视频数据,或使用Snapchat应用程序收集的视频。
在 Pavel Korshunov 和 Sébastien Marcel 写的这篇最新论文中,作者提供了首个使用基于开源GAN方法进行换脸的开源视频数据库。
他们从公开的VidTIMIT数据库中,手动选择了16对长相类似的人,将这32个目标都训练两种不同的模型,分别为低质量 (LQ) 模型,输入/输出大小为64×64,以及高质量 (HQ) 模型,输入/输出大小为128×128尺寸的模型(参见图1)。
图1:来自VidTIMIT数据库原始视频,以及低质量(LQ)和高质量(HQ)Deepfake视频的屏幕截图
为了让其他研究人员能够对其成果进行验证、复制和扩展,作者还提供了他们在研究中使用的Deepfake视频数据库、人脸识别系统和Deepfake检测系统,并将相应的分数一起以Python开源包的形式放出。
肉眼分辨计算机生成假脸的一些技巧
就在不久前,英伟达发表论文,展示了计算机生成的逼真到恐怖的人脸图像。对于虚假视频泛滥的网络来说,这可能导致一场迫在眉睫的“真相危机”。
英伟达新一代GAN生成的人脸,全都是不存在的人
以下图片是从Nvidia的最新论文中获取的截图。看看这份指南里是怎么说的吧。
不对称的面部特征、配饰
上面的图片有一堆可疑的线索。最简单的就是,此人头顶位置出现的大块的怪异斑点。这种现象或像差在AI生成的图像中很常见,与几年前谷歌的DeepDream实验的表现一致。
但是,当你环顾这个人的耳朵时,会发现图像略微不对称。一侧头发显得模糊而且看上去很奇怪,且一只耳朵上没有耳环。
算法不具备常识,并且不懂规则,比如不知道耳环一般要两只耳朵都戴。因此,AI算法有时无法生成足够真实的面部特征或首饰等。
牙齿
AI算法不知道正常人应该有多少颗牙以及这些牙齿的朝向。一般AI算法不会选择多角度描绘出这些牙齿的样貌,而是乱来一气。图中的虚假头像的牙齿就是典型例子。
上面这张图可能稍微难辨别一点,但如果你仔细看她的牙,会发现她中间第三颗牙异常地小,而且耳朵也非常不自然,所以这也是一张生成的假头像。
衣服和背景
上边图中的女性的衣服明显有问题,此外注意这张图片的背景也很奇怪,此外右侧的头发和耳环部分都很不自然,而且耳环只有一只。
上图中,人物的衣服实在太奇怪了,图中左侧的耳朵上并未戴耳环等配饰,但衣服上方却出现了一个悬在空中的“不明装饰物”,这种现象在AI生成的虚假图像中也不少见。
-
绝对的计算机知识大全,由浅入深的全面介绍计算机知识2012-08-05 11782
-
计算机视觉论文速览2021-08-31 1939
-
计算机科学与技术本科毕业论文指导培训2008-11-07 734
-
一种计算机音/视频切换电路的设计2010-05-13 1569
-
科学家已找到AI换脸视频的破解之法2018-07-20 16229
-
什么是Deepfake?为什么Deepfake生成的假脸会这么自然?2018-09-03 117306
-
盘点2018年计算机视觉大突破2019-01-07 6240
-
伯克利打造AI识别系统,DeepFake不再可怕!精准判断真伪2019-06-24 5678
-
阿里DeepFake检测技术获国际顶会认可,实现更好的检测效果2020-09-02 2398
-
计算机专业毕业设计-ASP.NET+ACCES视频点播系统设计(源代码+论文)2021-07-26 890
-
超级计算机与量子计算机扳手腕,量子霸权是真是假2022-04-07 4174
-
计算机快速全息生成技术研究2023-12-12 1692
全部0条评论

快来发表一下你的评论吧 !
