

四大维度讲述了一个较为完整的智能任务型对话全景
电子说
描述
在阿里巴巴的X峰会上,阿里巴巴-智能服务事业部高级算法专家李永彬(水德)分享了小蜜智能开发平台的构建,他围绕平台来源、设计理念、核心技术、业务落地情况四大维度讲述了一个较为完整的智能任务型对话全景。以下为演讲具体内容:
平台由来
为什么要做一个平台?我觉得还是从一个具体的任务型对话的例子说起,在我们日常工作中,一个很高频的场景就是要约一个会议,看一下我们内部的办公助理是怎么来实现约会议的:我说“帮我约一个会议”,然后它问“你是哪一天开会?”,跟它说是“后天下午三点”,接下来它又会问“你跟谁一起开会啊?”,我会把我想约的人告诉它,这个时候它在后台发起一次服务调用,因为它要去后台拿到所有参会者的日程安排,看一下在我说的这个时间有没有共同的空闲时间,如果没有的话它会给我推荐几个时间段,我看了一下我说的那个时间段大家没有共同的空闲时间,所以我就会改一个时间。
我说“上午十一点吧”,然后它会接着问,“你会持续多长时间”,我会告诉它“一个小时”,然后它接着问“会议的主题是什么”,然后我跟它说“我们讨论一下下周的上线计划”,到此为止它把所有的信息收集全了,然后它会给我一个 summary,让我确认是不是要发送会议邀约,我回复确认以后,它在后台就会调用我们的邮件系统,把整个会议邀约发出来。
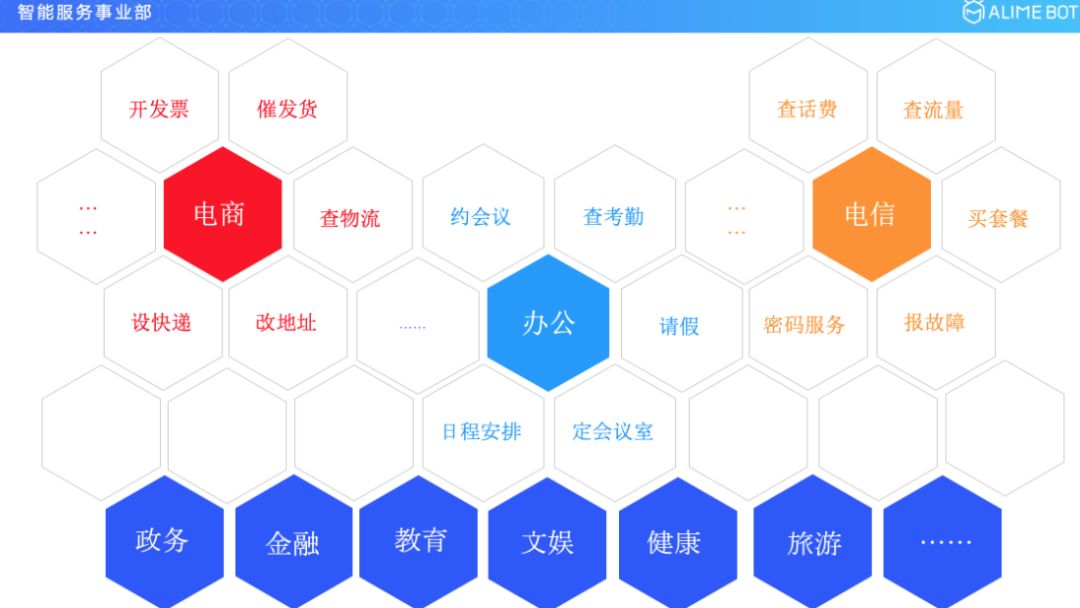
这是一个非常典型的任务型的对话,它满足两个条件,第一,它有一个明确的目标;第二,它通过多轮对话交互来达成这个目标。像这样的任务型对话在整个办公行业里面,除了约会议以外还有查考勤、请假、定会议室或者日程安排等等。
如果我们把视野再放大一点的话,再看一下电商行业,电商行业里面就会涉及到开发票、催发货、查物流、改地址、收快递等等,也会涉及到很多很多的这样的任务型对话场景;视野再放大一下,我们再看一下电信行业或者整个运营商的行业里面,会有查话费、查流量、买套餐、报故障或者是进行密码的更改服务等,也会有大量的这种任务型的对话场景。如果我们再一步去看的话,像政务、金融、教育、文娱、健康、旅游等,在各行各业的各种场景里面我们都会发现这种任务型的对话,它是一种刚需,是一种普遍性的存在。
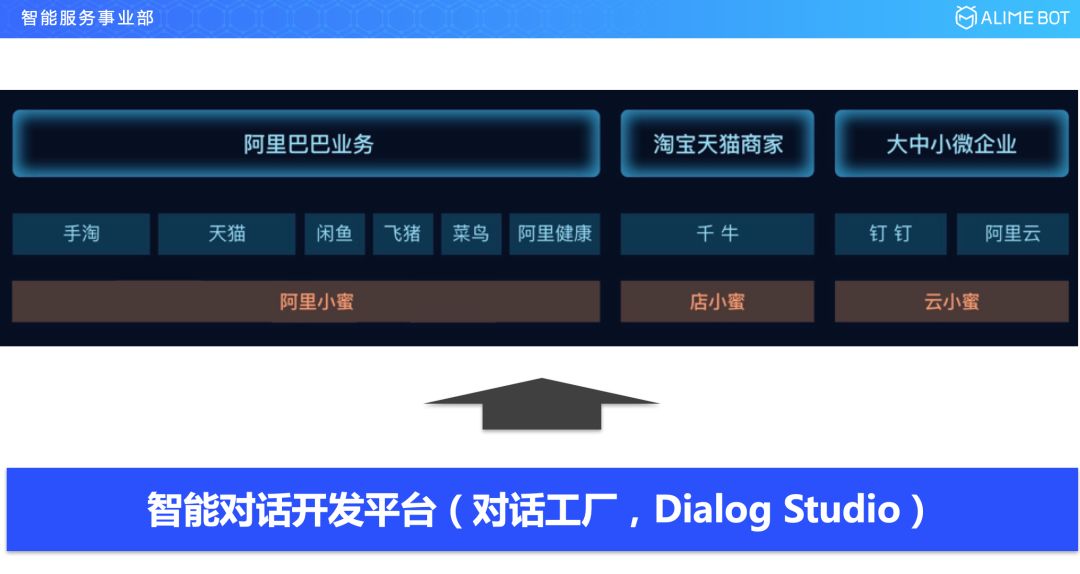
所有的这些场景落地到我们小蜜家族的时候,是通过刚刚介绍过的三大小蜜来承载:阿里小蜜、店小蜜和云小蜜。我们不可能给每一个行业里面的每一个场景去定制一个对话流程,所以我们就沿用了阿里巴巴一贯做平台的思路,这也是我们整个智能对话开发平台的由来。这款产品在内部的名字叫对话工厂(Dialog Studio)。
以上主要是给大家介绍我们为什么要做智能对话开发平台,总结起来就是我们目前面临的业务,面临的场景太宽泛了,不可能铺那么多人去把所有的场景都定制化,所以我们需要有一个平台来让开发者进来开发各行各业的各种场景对话。
设计理念
再看第二部分,对话工厂的一些核心设计理念。整个设计理念这块我觉得概括起来就是“一个中心,三个原则”。一个中心就是以对话为中心,这句话大家可能觉得有点莫名其妙,你做对话的,为何还要强调以对话为中心呢?
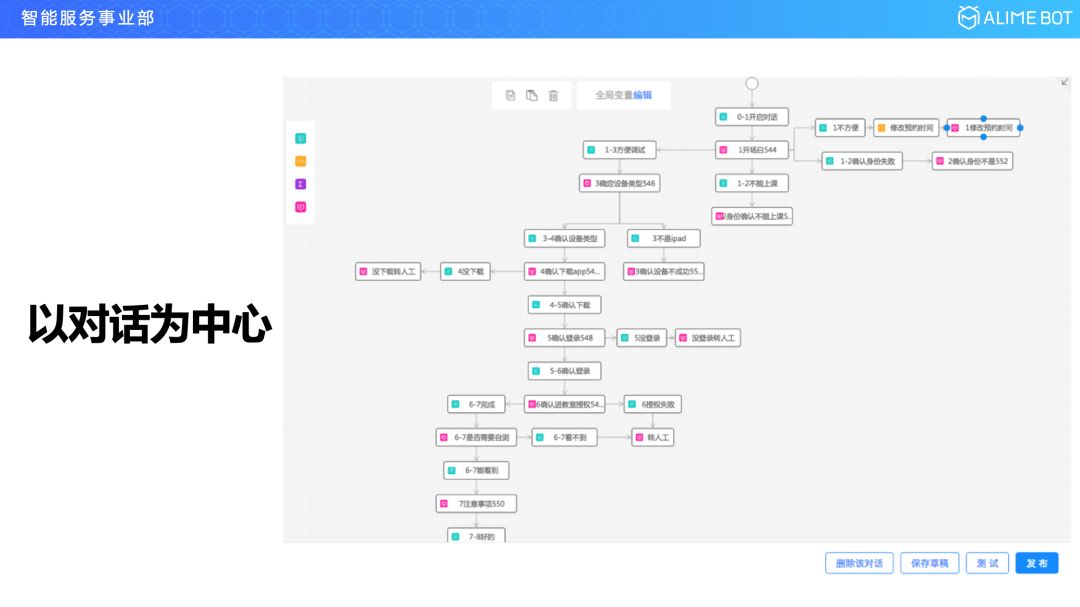
这是有来源的,因为在过去几年全世界范围的技术实践以及直到今天很多巨头的对话平台里面,我们能看到的基本还是以意图为中心的设计模式,它把意图平铺在这里,比如你想完成音乐领域的一些事情,可是你看到的其实是一堆平铺的意图列表,完全看不出对话在哪里。

我们在这次对话工厂的设计中彻底把它扭转回来,对话就是要以对话为中心,你在我们的产品界面里面看到的不再是一个个孤立的意图,而是关联在一起的、有业务逻辑关系的对话流程。以意图为中心的设计中,你看到的其实是一个局部视角,就只能实现一些简单的任务,比如控制一个灯,讲个笑话,或者查个天气,如果你想实现一个复杂的任务,比如开一个发票,或者去 10086 里开通一个套餐,它其实是较难实现,很难维护的。我们把整个理念转换一下,回到以对话为中心以后,就会看到全局视野,可以去做复杂的任务,可以去做无限的场景。
整个对话工厂刚刚也说过了,它是一个平台,要做一个平台就会遇到很多挑战。
第一个挑战就是对用户来说,希望使用门槛越低越好;第二个挑战是要面对各行各业的各种场景,就要求能做到灵活定制;第三个挑战是上线以后所有的用户肯定都希望你的机器人,你的对话系统能够越用越好,而不是停留在某一个水平就不动了。这就是我们平台所面临的三大挑战。
为了应对这三个挑战,我们提出了在整个平台的设计以及实现过程中始终要遵循三个原则。
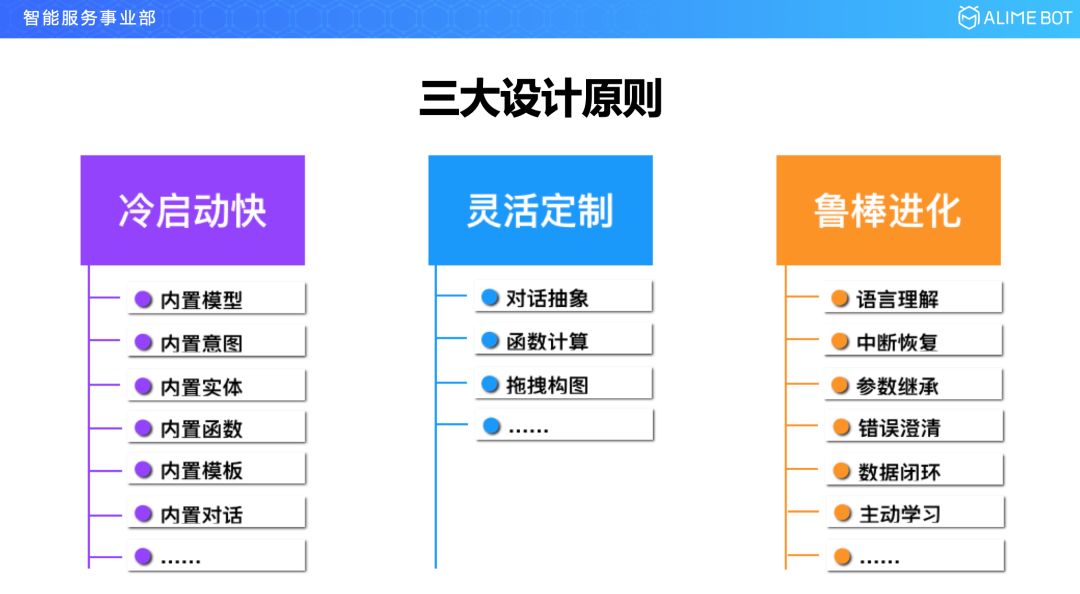
第一个原则是冷启动要快,其实就是要让用户的使用门槛低一点;第二个原则是要有灵活定制的能力,只有这样才能满足各行各业的各种场景需求;第三个是要有鲁棒进化的能力,就是模型上线以后,随着时间的变化,随着各种数据的不断回流,模型效果要不断提升。
这三个原则里面,冷启动这一块,其实就是要把用户用到的各种能力和各种数据都尽量变成一种预置的能力,简单来说就是平台方做得越多,用户就做得越少;第二块关于灵活定制,就要求我们把整个对话平台的基础元素进行高度抽象,你抽象的越好就意味着你平台的适应能力越好,就像是经典力学只要三条定律就够了;第三块就是鲁棒进化,这一块就是要在模型和算法上做深度了,语言理解的模型,对话管理的模型,数据闭环,主动学习,在这些方面能够做出深度来。
以上说的都是一些理念和原则,接下来给大家介绍一下具体在实现过程中是怎么来做的。
核心技术
讲到技术这块的话,因为我们做的是一个平台,涉及到的技术非常广,是全栈的技术,从算法到工程到前端到交互所有的技术都会涉及到。我摘取里面算法的核心部分来给大家做一个介绍。
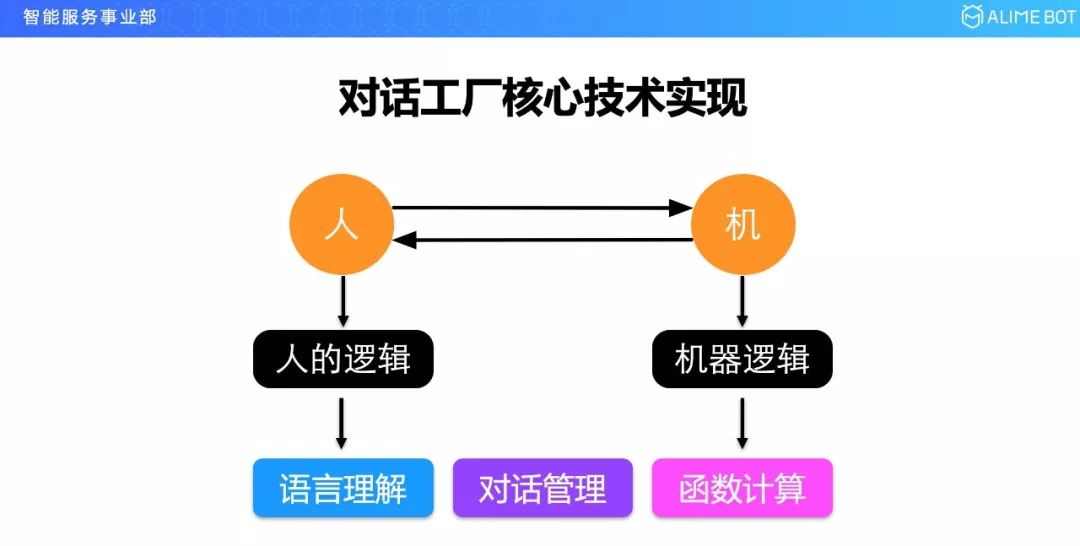
对话工厂首先是用来做对话的,人机对话有两个主体,一个是人,一个是机器,人有人的逻辑,人的逻辑使用什么来表达呢?到今天为止主要还是通过语言,所以我们需要有一个语言理解的服务来承载这一块;机器有机器的逻辑,机器的逻辑到今天为止还是通过代码来表达的,所以我们需要一个函数计算的服务;在人和机器对话的过程中,这种对话过程需要有效的管理,所以我们需要一个对话管理模块。整个对话工厂最核心的三个模块就是语言理解、对话管理和函数计算。
第一个模块是语言理解。
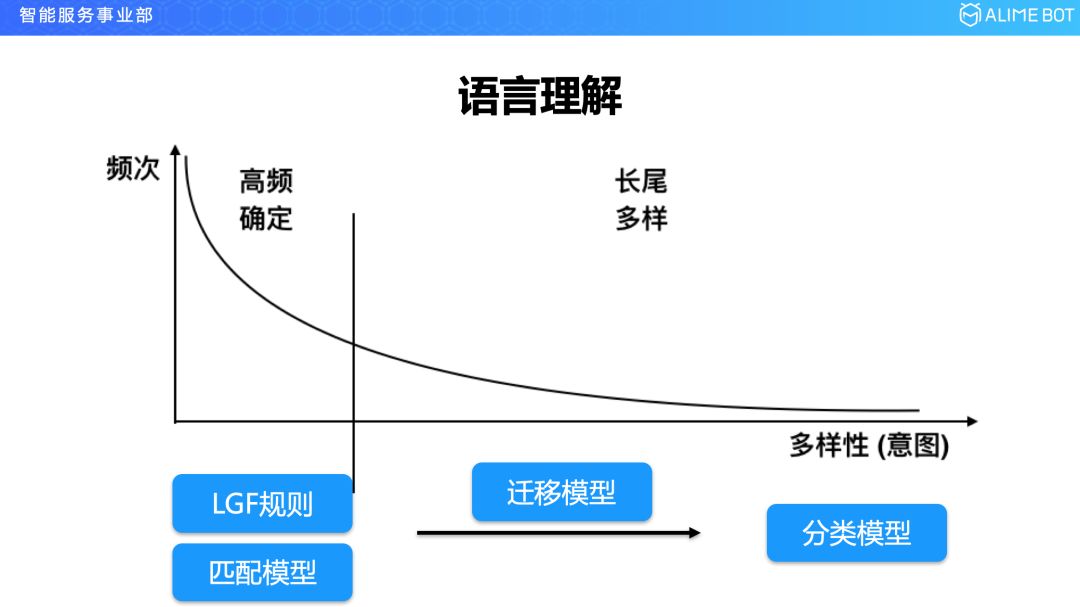
我们先看一下这个图,在整个这个图里面,横轴是意图的多样性,纵轴是频次,这样说有点抽象,我举一个具体的例子,比如说我要开发票,这是一个意图,如果去采样十万条这个意图的用户说法作为样本,把这些说法做一个频率统计,可能排在第一位的就是三个字“开发票”,它可能出现了两万次,另外排在第二位可能是“开张发票”,它可能出现了八千次,这些都是一些高频的说法,还有一些说法说的很长,比如“昨天我在你们商铺买了一条红色的裙子,你帮我开个发票呗”,这种带着前因后果的句式,在整个说法里面是比较长尾的,可能只出现了一次或两次。
我们统计完以后,整个意图的说法的多样性分布符合幂律分布。这种特征可以让我们在技术上进行有效的针对性设计,首先针对这种高频的部分,我们可以上一些规则,比如上下文无关文法,可以比较好的 cover 这一块,但是基于规则的方法,大家也知道,规则是没有泛化能力的,所以这时候要上一个匹配模型,计算一个相似度来辅助规则,这两块结合在一起就可以把我们高频确定性的部分解决的比较好;对于长尾的多样性的这一部分,基本到今天为止还是上有监督的分类模型,去收集或者去标注很多数据,把这一块做好;在规则和分类模型之间,我们又做了一部分工作,就是迁移学习模型,为什么要引入这个模型呢?我们看下一张图。
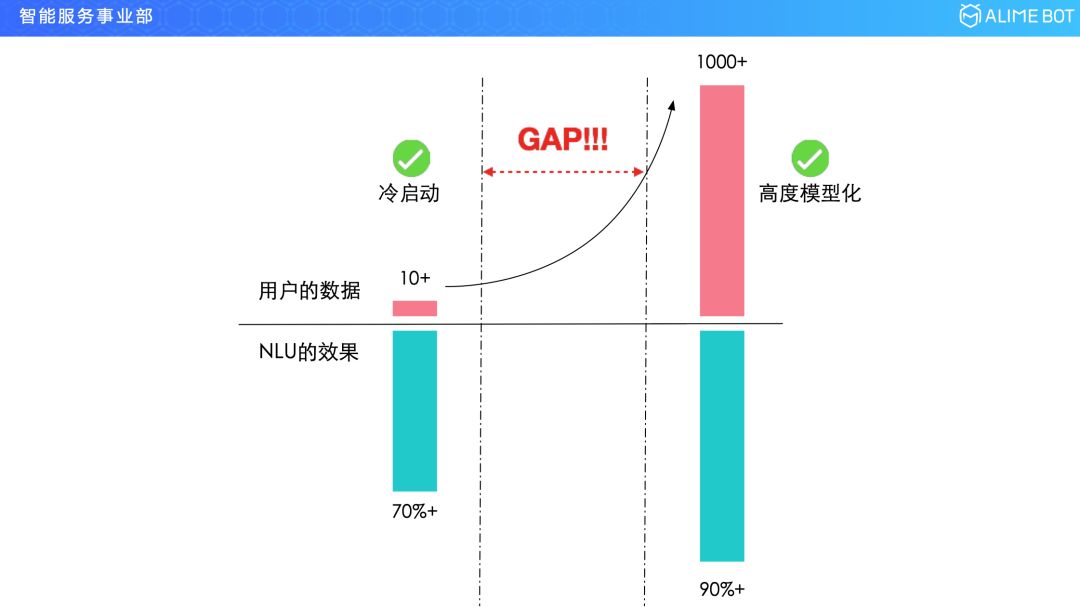
在冷启动阶段,用户在录入样本的时候,不会录入太多,可能录入十几条几十条就已经很多了,这个时候按照刚才那个幂律分布,二八原则的话,它的效果的话可能也就是 70% 多,它不可能再高了。但对于用户的期望来说,如果想要上线,想要很好的满足他的用户需求,其实是想要模型效果在 90% 以上,如果想要达到这个效果,就需要复杂的模型,需要标注大量数据。所以其实是存在一个 gap 的,我们引入了迁移学习模型。
具体来说,我们把胶囊网络引进来和 few-shot learning 结合在一起,提出了一个网络结构叫 Induction Network,就是归纳网络。整个网络结构有三层,一层是 Encoder层,第二层是 Induction,归纳层,第三层是 Relation 层。
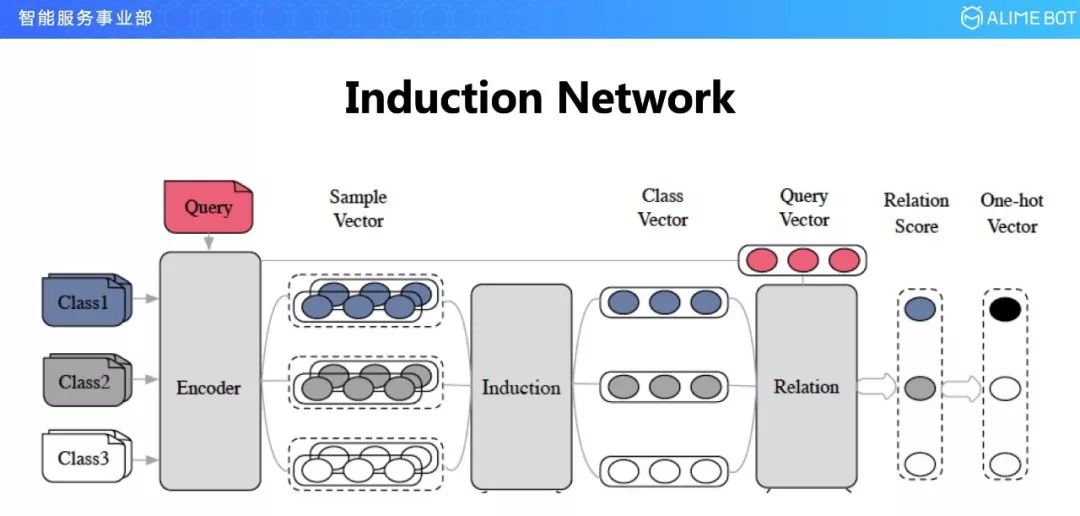
第一层负责将每一个类的每一个样本进行编码,编码成一个向量;第二层是最核心的一层,也就是归纳层,这里面利用胶囊网络的一些方法,把同一个类的多个向量归纳成一个向量;然后第三层 Relation 层把用户新来的一句话和每一个类的归纳向量进行关系计算,输出他们的相似性打分。如果我们想要一个分类结果就输出一个 One-hot,如果不想要 One-hot,就输出一个关系的 Relation score,这是整个 Induction network 的网络结构。
这个网络结构提出来以后,在学术圈里面关于 few-shot learning 的数据集上,我们以比较大的提升幅度做到了 state-of-the-art 的效果,目前是最好的,同时我们将整个网络结构上线到了我们的产品里面,这是语言理解。
第二块我们看对话管理。
对话管理其实我刚刚也说过了,如果想要让平台有足够的适应性的话,那么它的抽象能力一定要好。对话管理是做什么的?对话管理就是管理对话的,那么对话是什么呢?对话的最小单位就是一轮,一个 turn,我们进去看的话,一个 turn 又分为两部分,一个叫对话输入,一个叫对话输出;在输入和输出中间,有一个对话处理的过程,就像两个人互相交流一样,我问你答,但其实你在答之前是有一个思考过程的,如果你不思考就回答,那你的答案就是没有质量的,所以就会有一个中间的对话处理过程。
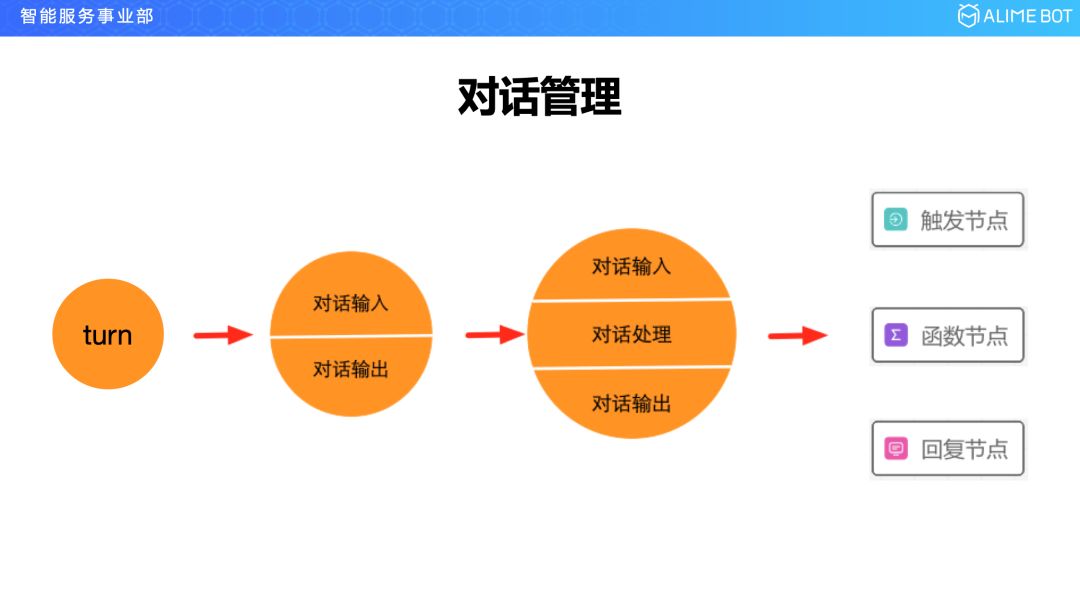
我们把对话抽象到这种程度以后,整个平台就三个节点,一个叫触发节点,一个叫函数节点,一个叫回复节点。
触发节点是和用户的对话输入对着的,函数节点是和对话处理对着的,回复节点是和对话输出对着的。有了这一层抽象以后,无论你是什么行业的什么场景,什么样的对话流程,都可以通过这三个节点通过连线把你的业务流画出来。
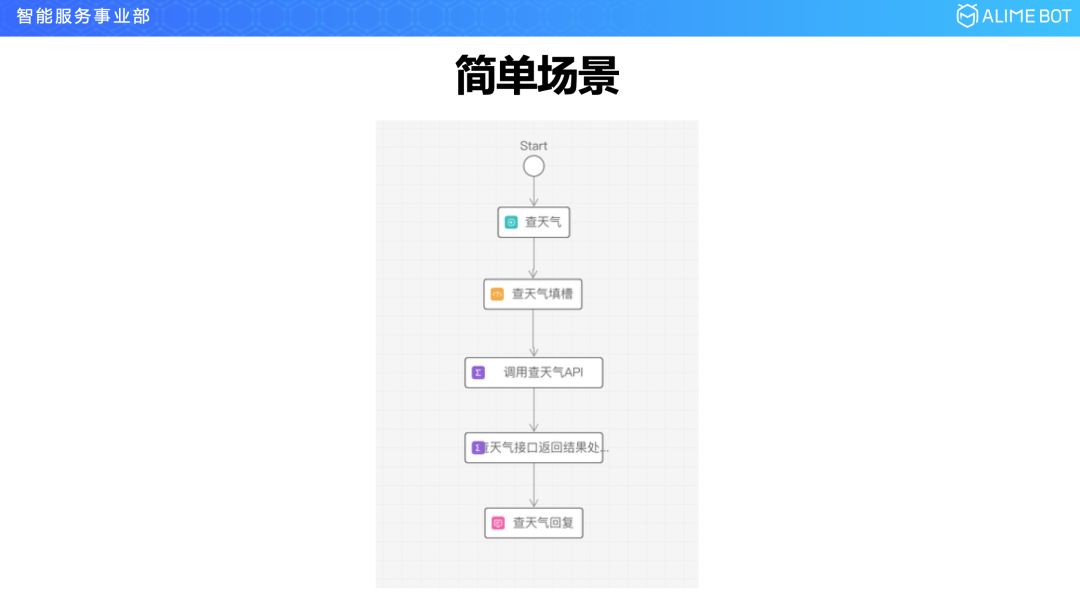
举两个例子,先看一个简单的,你要查一个天气,很简单,先来一个触发节点,把天气流程触发起来,中间有两个函数节点,一个是调中央气象台的接口,把结果拿过来,另一个是对结果进行一次解析和封装,以一个用户可读的形式通过回复节点回复给用户。这里面稍微解释一下就是增加了一个填槽节点,填槽节点是什么意思呢?就是在任务型对话里面,几乎所有的任务都需要收集用户的信息,比如你要查天气,就需要问时间是哪一天的,地点是什么地方的,这样就叫做填槽,填槽因为太常用太普遍了,就符合我们冷启动快里面做预置的思想,所以通过三个基础节点,我们自己把它搭建成填槽的一个模板,需要填槽的时候从页面上拖一个填槽节点出来就可以了。
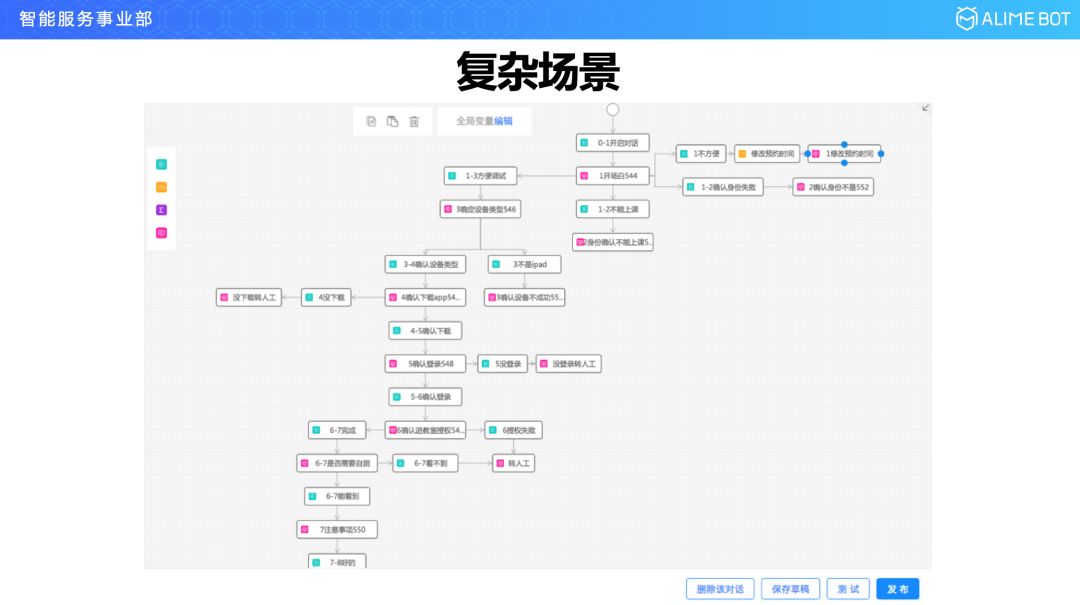
我们再看一个复杂的场景,这是在线教育里面的一个外呼场景,家里有小孩的可能知道,这种在线教育特别火,在上课之前半小时,机器人就会主动给用户打电话,指导软件下载,指导怎么登陆,登陆进去以后怎么进入教室,所有的这些流程都可以通过机器人进行引导。
通过这两个例子我们就可以看到,无论是简单还是复杂的场景,通过这三种抽象节点的连线都可以实现。有时候我们开玩笑就会说,整个这种连线就叫一生二,二生三,三生万千对话。
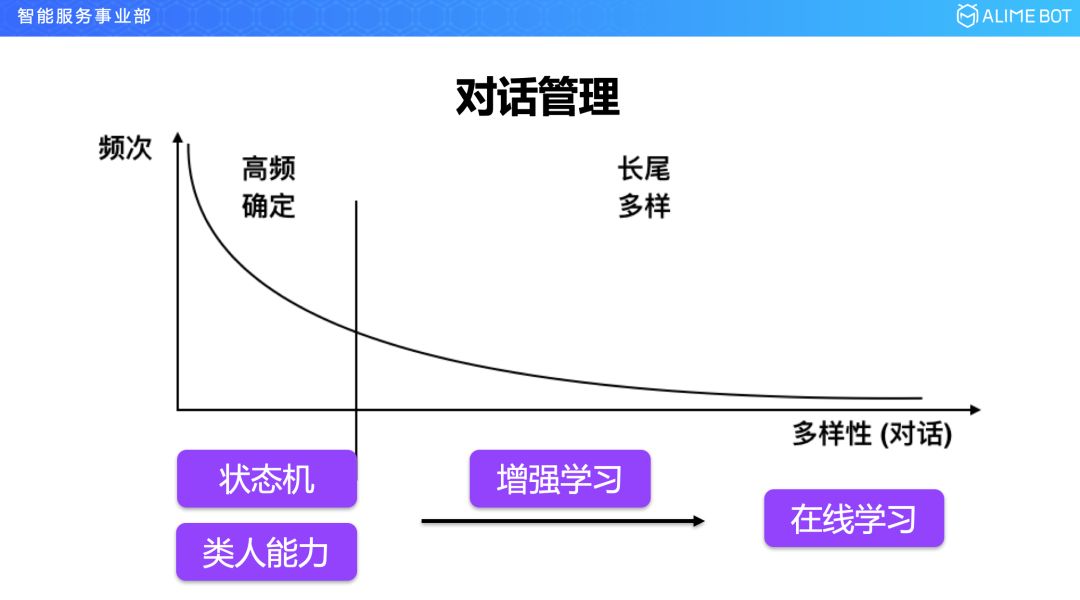
讲了抽象以后,再看一下具体的对话管理技术。从实现上来说,这张图和大家刚才看到的语言理解那张是一模一样的,因为很多东西的分布其实是遵循着共同规律的,区别在与把意图换成了对话。
举一个例子,比如像查天气这样的,如果采集十万个查天气的样本,对这些用户的说法进行一个频率统计的话,大概就是这样一个曲线,用两步能够完成的,比如说查天气,先填槽一个时间再填槽一个地点,然后返回一个结果,通过这种流程来完成的,可能有两万次;中间可能会引入一些问 A 答 B 的情况,这样的 B 可能有各种各样的,就跑到长尾上来了,这样整个对话其实也遵循一个幂律分布。
对于高频确定的部分,可以用状态机进行解决,但状态机同样面临一个问题,它没有一个很好的容错能力,当问 A 答 B 的时候,机器不知道下面怎么接了。在这种情况下,需要引入一个类人能力,对状态机的能力进行补充,状态机加上类人能力以后,基本上可以把高频的对话比较好的解决了。对于长尾上的对话,目前对于整个学术界或者工业界都是一个难题,比较好的解决方式就是上线以后引入在线交互学习,不断跟用户在对话过程中学习对话。在状态机和在线交互学习之间其实是有 gap 的,因为状态机自己没有学习能力,所以需要引入增强学习。接下来我会介绍在类人能力以及增强学习方面的一些工作。
先看一下类人能力。我们把人说的话,做一下分类大概可以分为三种:第一种就是用户说的话清晰明了只有一个意思,这种其实对机器来说是可理解的;第二种机器压根儿不知道在说啥,也就是 unknown 的;还有一种就是用户表达的意思可以理解,但是有歧义,有可能包含着两个意图、三个意图,就是uncertain,不确定的。确定性的,状态机其实是可以很好地捕捉和描述的,类人能力主要关注拒识的和不确定性的。
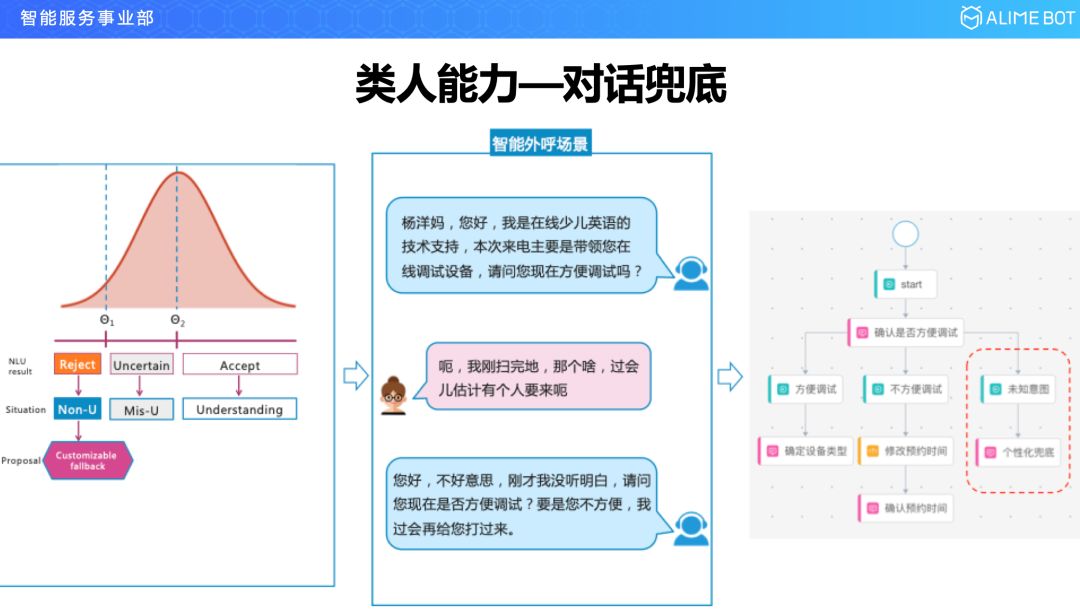
对于拒识这块,比如还是在线英语的这个例子,机器人打来一个电话,问现在方不方便调试设备,这个时候从设计的角度来说希望用户回答方便或者不方便就OK了,但是一旦这个用户回答了一个比较个性化的话,比如,“呃,我刚扫完地,过会儿可能有人要来”,这时候我们的语言理解模块很难捕捉到这是什么语义,这时候需要引入一个个性化的拒识,比如说,“您好,不好意思,刚才没听明白,请问您现在是否方便调试,如果您不方便,我过会儿再给您打过来”,这个就是对话的兜底,是对 unknown 的处理。
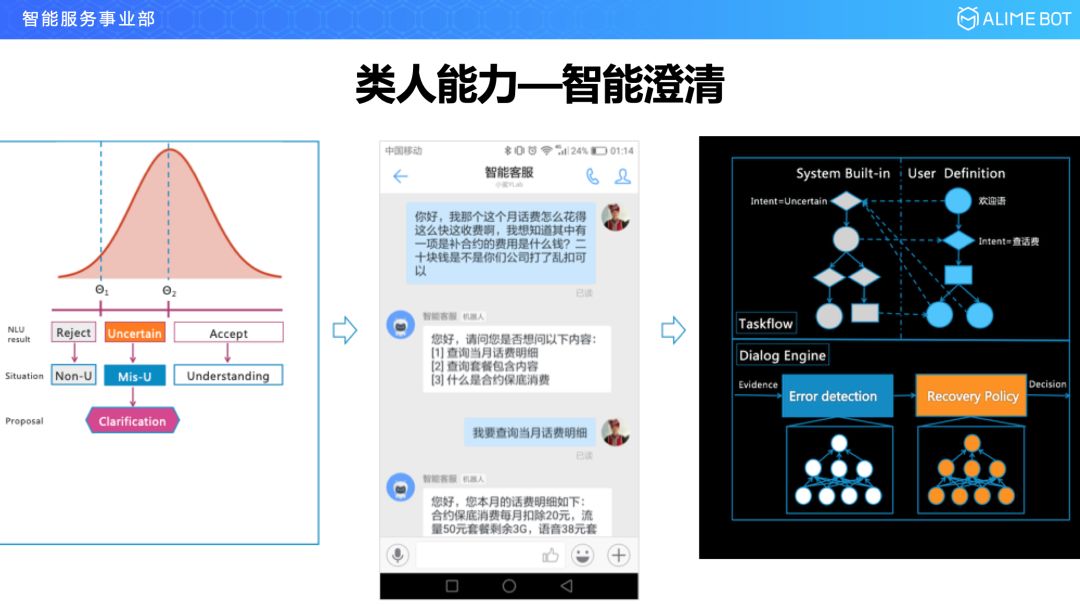
第二个我们看一下澄清,用户说的一句话里面,如果是模糊不清的怎么办?我们通过大量的数据分析发现这种模糊不清主要出现在两种情况下,一种是用户把多个意图杂糅在一段话里来表达;第二种是用户在表达一个意图之前做了很长的铺垫,对于这两种长句子现在的语言理解给出的是意图的概率分布,我们把这个概率分布放到对话管理模块以后就需要让用户进行一轮澄清。比如这个例子,这是移动领域的一个例子,这句话理解有三种意图,到底是想问花费明细,还是套餐的事情还是想问合约的低保,把这三个问题抛给用户进行澄清就可以了。
从技术上来说是怎么实现的呢,我们看一下这个图,开发者负责把对话流程用流程图清晰描述出来,然后像澄清这种其实是我们系统的一种内置能力,什么时候澄清是通过下端的这两个引擎里面的能力来决定的,第一块是 Error Detection,它用来检测用户当前说的这句话是否需要触发澄清,一旦它觉得要触发澄清,就会交给下一个模块,究竟用什么样的方式澄清以及怎么生成澄清的话术,这是目前我们整个智能澄清这块做的工作。
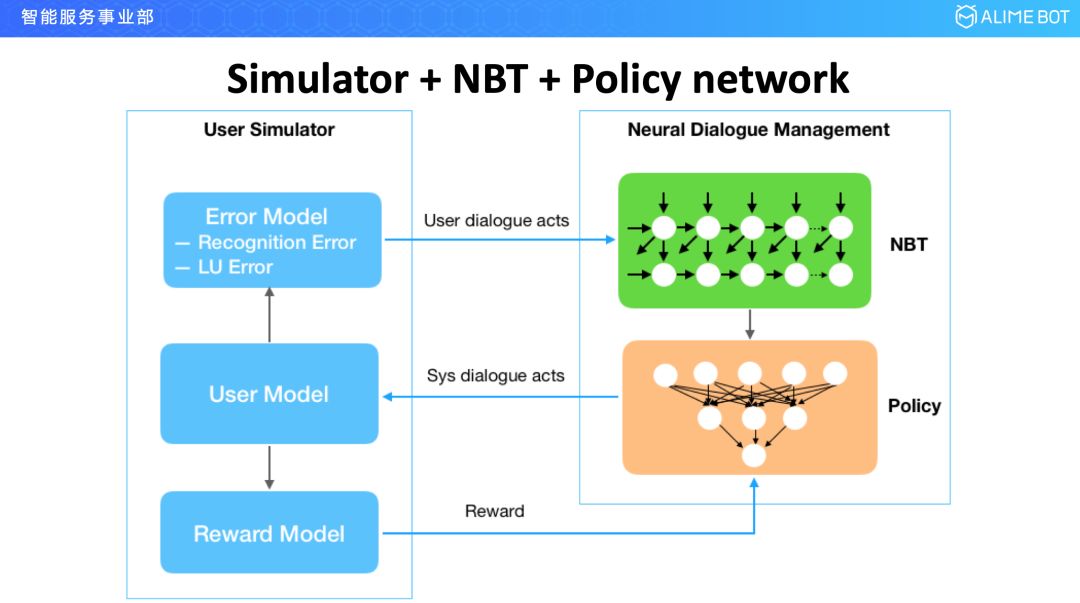
再看一下我们在增强学习方面的工作。在对话管理模型里面,经典的分成两个模块,一个是 neural belief tracker,用来做对话状态追踪的,另一个是 policy network,用来做行为决策的。在整个框架下,要去训练这个网络的时候,有两种训练方式,一种是端到端的去训练,用增强学习去训练,但这种方式一般它的收敛速度会比较慢,训练出的结果也不好;另外一种方式是先分别做预训练,这个时候用监督学习训练就好了,不用增强学习训练,训练完以后再用增强学习对监督学习预训练的模型进行调优就可以了。
无论是端到端的一步训练还是先预训练再调优,只要涉及增强学习这一块,都需要有一个外部环境,所以在我们的实现架构里面,引入了模拟器的概念,就是user simulator。模拟器这主要分为三大块,一个是 user model,用来模拟人的行为的;第二个是 error model,模拟完人的行为以后经过 error model 引入一个错误扰动,用 user model 产出的只是一个概率为 1 的东西,它对网络训练是不够好的,error model 会对这个结果进行扰动并给他引进几个其他的结果,并且把概率分布进行重新计算一下,这样训练出的模型在扩展能力或者泛化能力上会更好一些;第三个模块是 reward model,用来提供 reward 值。这是我们今天在整个增强学习的对话管理这块的一些工作。
最后看一下函数计算。
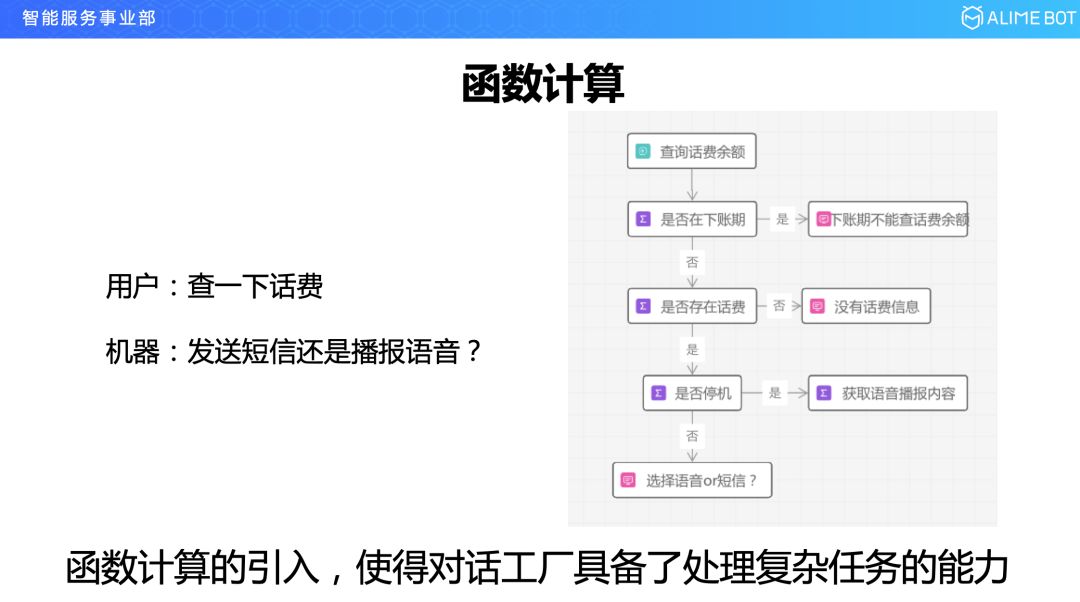
函数计算是什么东西呢?还是举一个例子吧,比如说,10086 里面用户说要查一下话费,10086 那边的机器人就会回复一句是发短信还是播放语音,表面看来就是简单的一入一出,其实在这背后要经过多轮的服务查询,才能完成这个结果,因为当要查话费的时候,先要经过函数计算查一下现在是哪一天,如果是下账期的话是不能查话费的,就是每个月的最后一天不能查话费,如果可以查话费的话,先看一下用户是否存在话费,如果存在花费的话第三步调用的服务看是不是停机了,因为停机了的话只能语音播报不能接收短信。所以看一下在一个简单的一入一出的对话背后,是走了一个复杂的流程的,这些流程今天都是在机器端用代码来实现的。函数计算的引入,使对话工厂可以去处理复杂的任务。
业务应用
最后我们看一下对话工厂的业务应用情况。这是我们在浙江上线的 114 移车,当有市民举报违规停车挡路后,就会自动打一个电话让他移车。第二个是在金融领域里面关于贷款催收的例子。在刚刚过去的双十一里面,对话工厂在整个电商里面也有大量应用,主要是在店小蜜和阿里小蜜里面。
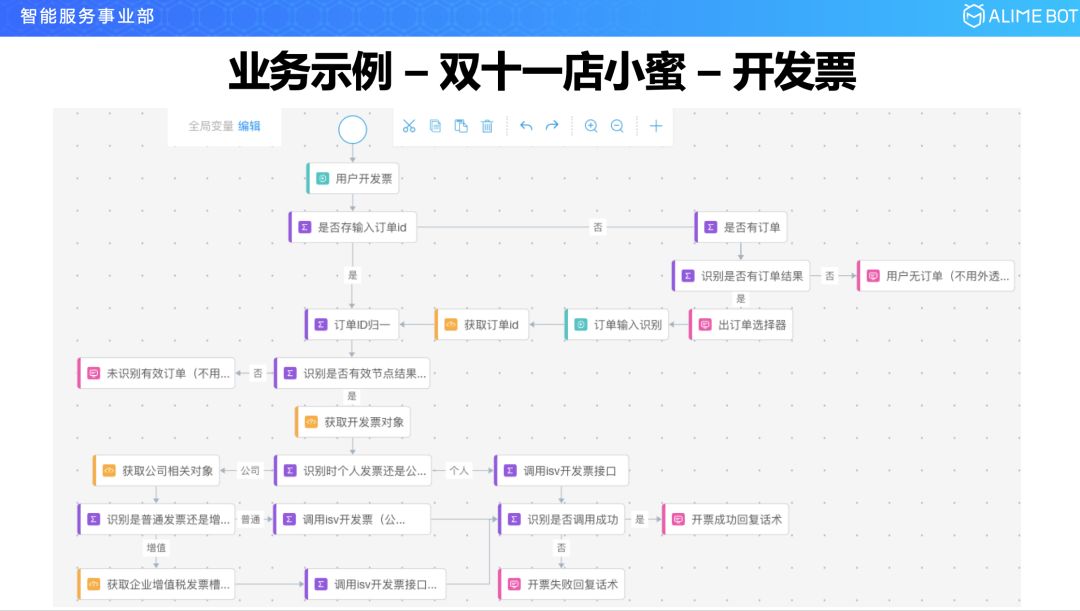
店小蜜主要是一些开发票、催发货、改地址这样的流程,这里是一个开发票的例子,用户可能会先说一个开发票,进来以后要进行复杂的流程,一种是在说的时候其实他已经把它的订单号送进来了,如果没有说订单号的话需要去后台系统查订单号,查出来以后弹一个订单选择器选择订单,接下来如果是个人发票就走这个流程,如果是公司发票走另一个流程,接下来会问是普通发票还是增值税发票,如果是普通发票接着往这儿走,如果是增值税发票需要获取企业增值税的税号,最后汇总到一个节点,调用后台开发票的系统,把发票开出来。这是这次双十一里面用到的开发票的一个例子。
最后看一下我们整体的落地情况。整个对话工厂在店小蜜里面主要是做像开发票这样的售后流程的处理。在云小蜜,公有云是一大块;私有云现在有70多家客户了,主要有银行、电信运营商还有金融等;钉钉是我们另一个重要的端,钉钉上也有几百万的企业;内外小蜜是我们集团用小蜜实现的一个办公助理;另外两个巨大的客户,一个是浙江省的政务,第二个是中国移动,这是云小蜜的业务。
阿里小蜜主要是负责阿里巴巴集团内部各个 BU 的业务,手淘是一个最大的业务,进入手机淘宝以后,进入“我的”里面有一个客服小蜜,就是阿里小蜜;上个月我们刚刚在优酷上线了优酷小蜜,星巴克是 9 月份上的,是属于新零售的一个最大的尝试点,还有很多其他的场景。
-
思必驰任务型对话算法通过国家备案2025-11-20 704
-
示波器测量之抖动的四个维度2022-11-22 5894
-
基于知识的对话生成任务2022-09-05 2507
-
NLP中基于联合知识的任务导向型对话系统HyKnow2021-09-08 4811
-
【快包故事简讯】服务商竞标+交付经验分享,三个成功秘诀和四大误区!2021-08-11 1554
-
视觉问答与对话任务研究综述2021-04-08 993
-
口语语言理解在任务型对话系统中的探讨2021-03-31 2918
-
变频器常见的四大常见故障及原因2020-08-31 16799
-
UCOS2系统内核讲述(四)_ 创建任务2020-03-25 4086
-
详解阿里巴巴智能对话开发平台2019-07-31 3108
-
2018年智能家居迎来了四大机遇2018-02-09 2395
-
360°全景可视泊车/行车记录(四路全景+行车记录仪+熄火震)2014-05-22 6423
-
全景监控摄像机四大特性2012-10-11 3351
全部0条评论

快来发表一下你的评论吧 !
