

工业大数据挖掘的利器——Spark MLlib
描述
格物汇之前刊发的《工业大数据处理领域的“网红”——Apache Spark》中提到,在“中国制造2025”的技术路线图中,工业大数据是作为重要突破点来规划的,而在未来的十年,以数据为核心构建的智能化体系会成为支撑智能制造和工业互联网的核心动力。Apache Spark 作为新一代轻量级大数据快速处理平台,集成了大数据相关的各种能力,是理解大数据的首选。Spark有一个机器学习组件是专门用于解决海量数据如何进行高效数据挖掘的问题,那就是SparkMLlib组件。今天的格物汇就给大家详细介绍一下Spark MLlib。
Spark MLlip 天生适合迭代计算
在介绍Spark MLlib 这个组件前,我们先了解一下机器学习的定义。在维基百科中对机器学习给出如下定义:
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
机器学习是对能通过经验自动改进的计算机算法的研究。
机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
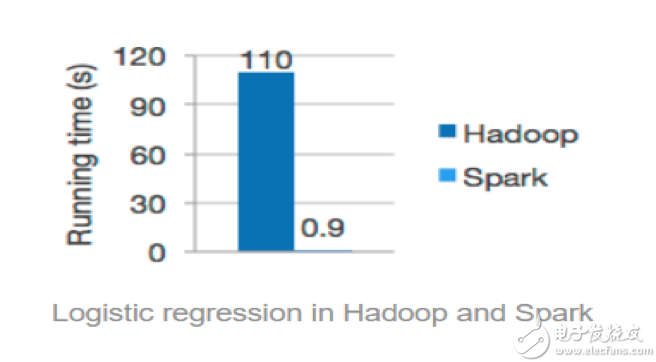
很明显,机器学习的重点之一就是“经验”,对于计算机而言,经验就是需要进行多次迭代计算得到的,Spark 的基于内存的计算模式天生就擅长迭代计算,多个步骤计算直接在内存中完成,只有在必要时才会操作磁盘和网络,所以说Spark正是机器学习的理想的平台。在Spark官方首页中展示了Logistic Regression算法在Spark和Hadoop中运行的性能比较,如图下图所示。
Spark MLlib 算法以及功能
MLlib由一些通用的学习算法以及工具组成,其中包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。具体主要包含以下内容:
>>>>
回归(Regression)
线性回归(Linear)
广义线性回归(Generalized Linear)
决策树(Decision Tree)
随机森林(Random Forest)
梯度提升树(Gradient-boosted Tree)
Survival
Isotonic
>>>>
分类(Classification)
逻辑回归(Logistic,二分类和多酚类)
决策树(Decision Tree)
随机森林(Random Forest)
梯度提升树(Gradient-boosted Tree)
多层反馈(Multilayer Perceptron)
支持向量机(Linear support vector machine)
One-vs-All
朴素贝叶斯(Naive Bayes)
>>>>
聚类(Clustering)
K-means
隐含狄利克雷分布(LDA)
BisectingK-means
高斯混合模型(Gaussian Mixture Model)
协同过滤(Collaborative Filtering)
>>>>
特征工程(Featurization)
特征工程(Featurization)
特征提取
转换
降维(Dimensionality reduction)
筛选(Selection)
>>>>
管道(Pipelines)
组合管道(Composing Pipelines)
构建、评估和调优(Tuning)机器学习管道
>>>>
持久化(Persistence)
保存算法,模型和管道到持久化存储器,以备后续使用
从持久化存储器载入算法、模型和管道
>>>>
实用工具(Utilities)
线性代数(Linear algebra)
统计
数据处理
其他
综上可见,Spark在机器学习上发展还是比较快的,目前已经支持了主流的统计和机器学习算法。
Spark MLlib API 变迁
Spark MLlib 组件从Spark 1.2版本以后就出现了两套机器学习API:
spark.mllib基于RDD的机器学习API,是Spark最开始的机器学习API,在Spark1.0以前的版本就已经存在的了。
spark.ml提供了基于DataFrame 高层次的API,引入了PipLine,可以向用户提供一个基于DataFrame的机器学习流式API套件。
Spark 2.0 版本开始,spark mllib就进入了维护模式,不再进行更新,后续等spark.ml API 足够成熟并足以取代spark.mllib 的时候就弃用。
那为什么Spark要将基于RDD的API 切换成基于DataFrame的API呢?原因有以下三点:
首先相比spark.mllib,spark.ml的API更加通用和灵活,对用户更加友好,并且spark.ml在DataFrame上的抽象级别更高,数据与操作的耦合度更低;
spark.ml中无论是什么模型,都提供了统一的算法操作接口,例如模型训练就调用fit方法,不行spark.mllib中不同模型会有各种各样的trainXXX;
受scikit-learn 的Pipline概念启发,spark.ml引入pipeline, 跟sklearn,这样可以把很多操作(算法/特征提取/特征转换)以管道的形式串起来,使得工作流变得更加容易。
如今工业互联网飞速发展,企业内部往往存储着TB级别甚至更大的数据,面对海量数据的难以进行有效快速的进行数据挖掘等难题,Spark提供了MLlib 这个组件,通过利用了Spark 的内存计算和适合迭代型计算的优势,并且提供用户友好的API,使用户能够轻松快速的应对海量数据挖掘的问题,加快工业大数据的价值变现。作为TCL集团孵化的创新型科技公司,格创东智正在致力于深度融合包括Spark在内的大数据、人工智能、云计算等前沿技术与制造行业经验,打造行业领先的“制造x”工业互联网平台。随着未来Spark社区在AI领域的不断发力,相信Spark MLlib组件的表现会越来越出色。
本文作者:格创东智大数据工程师黄欢(转载请注明作者及来源)
-
如何成功实施工业大数据2021-09-30 1864
-
工业大数据在制造企业的应用场景2021-01-17 5622
-
SparkMLlib GBDT算法工业大数据的实战案例2020-12-25 1710
-
工业大数据的技术与应用2020-11-23 6650
-
大数据系列之Spark2020-04-30 2759
-
工业大数据如何管理2020-04-21 3652
-
SparkMLlib GBDT算法工业大数据实战2019-04-28 4646
-
工业大数据前景2019-03-28 4589
-
工业大数据的概念2019-03-05 4844
-
工业大数据处理领域的“网红”——Apache Spark2018-12-17 3755
-
工业大数据分析平台的应用价值探讨2018-11-12 3636
-
大数据开发之spark应用场景2018-04-10 2698
-
工业大数据技术综述2018-03-27 1339
-
工业大数据2016-06-19 3147
全部0条评论

快来发表一下你的评论吧 !
