

如何用TensorFlow进行机器学习研究
描述
在此之前,我们介绍过用于自动微分的 TensorFlow API - 自动微分,优化机器学习模型的关键技术,这是机器学习的基本构建块。在今天的教程中,我们将使用先前教程中介绍的 TensorFlow 基础来进行一些简单的机器学习。
TensorFlow 还包括一个更高级别的神经网络 API(tf.keras),它提供了有用的抽象来减少样板。我们强烈建议那些使用神经网络的人使用更高级别的 API。但是,在这个简短的教程中我们将从神经网络训练的基本原理来建立一个坚实的基础。
设置
import tensorflow as tftf.enable_eager_execution()
变量
TensorFlow 中的张量是不可变的无状态对象。然而,机器学习模型需要具有可变的状态:随着模型的训练,计算预测的相同代码应该随着时间的推移而表现不同(希望具有较低的损失!)。要表示在计算过程中需要改变的状态,事实上您可以选择依赖 Python 这种有状态的编程语言:
# Using python statex = tf.zeros([10, 10])x += 2 # This is equivalent to x = x + 2, which does not mutate the original # value of xprint(x)
tf.Tensor([[2。2. 2. 2. 2. 2. 2. 2. 2. 2.] [2。2. 2. 2. 2. 2. 2. 2. 2. 2.] [2。2. 2. 2. 2. 2. 2. 2. 2. 2.] [2。2. 2. 2. 2. 2. 2. 2. 2. 2.] [2。2. 2. 2. 2. 2. 2. 2. 2. 2.] [2。2. 2. 2. 2. 2. 2. 2. 2. 2.] [2。2. 2. 2. 2. 2. 2. 2. 2. 2.] [2。2. 2. 2. 2. 2. 2. 2. 2. 2.] [2。2. 2. 2. 2. 2. 2. 2. 2. 2.] [2。2. 2. 2. 2. 2. 2. 2. 2. 2.]],shape =(10,10),dtype = float32)
但是,TensorFlow 内置了有状态操作,这些操作通常比您所用的低级 Python 表示更易于使用。例如,为了表示模型中的权重,使用 TensorFlow 变量通常是方便有效的。
变量是一个存储值的对象,当在 TensorFlow 计算中使用时,它将隐式地从该存储值中读取。有些操作(如:tf.assign_sub,tf.scatter_update 等)会操纵存储在 TensorFlow 变量中的值。
v = tf.Variable(1.0)assert v.numpy() == 1.0# Re-assign the valuev.assign(3.0)assert v.numpy() == 3.0# Use `v` in a TensorFlow operation like tf.square() and reassignv.assign(tf.square(v))assert v.numpy() == 9.0
使用变量的计算在计算梯度时自动跟踪。对于表示嵌入式的变量,TensorFlow 默认会进行稀疏更新,这样可以提高计算效率和内存效率。
使用变量也是一种快速让代码的读者知道这段状态是可变的方法。
示例:拟合线性模型
现在让我们把目前掌握的几个概念 — 张量、梯度带、变量 — 应用到构建和训练一个简单模型中去。这通常涉及几个步骤:
1. 定义模型。
2. 定义损失函数。
3. 获取训练数据。
4. 运行训练数据并使用 “优化器” 调整变量以匹配数据。
在本教程中,我们将介绍一个简单线性模型的简单示例:f(x) = x * W + b,它有两个变量 — W 和 b。此外,我们将综合数据,以便训练好的模型具有 W = 3.0 和 b = 2.0。
定义模型
让我们定义一个简单的类来封装变量和计算。
class Model(object): def __init__(self): # Initialize variable to (5.0, 0.0) # In practice, these should be initialized to random values. self.W = tf.Variable(5.0) self.b = tf.Variable(0.0) def __call__(self, x): return self.W * x + self.b model = Model()assert model(3.0).numpy() == 15.0
定义损失函数
损失函数测量给定输入的模型输出与期望输出的匹配程度。让我们使用标准的 L2 损失。
def loss(predicted_y, desired_y): return tf.reduce_mean(tf.square(predicted_y - desired_y))
获取训练数据
让我们用一些噪音(noise)合成训练数据。
TRUE_W = 3.0TRUE_b = 2.0NUM_EXAMPLES = 1000inputs = tf.random_normal(shape=[NUM_EXAMPLES])noise = tf.random_normal(shape=[NUM_EXAMPLES])outputs = inputs * TRUE_W + TRUE_b + noise
在我们训练模型之前,让我们想象一下模型现在的位置。我们将用红色绘制模型的预测,用蓝色绘制训练数据。
import matplotlib.pyplot as pltplt.scatter(inputs, outputs, c='b')plt.scatter(inputs, model(inputs), c='r')plt.show()print('Current loss: '),print(loss(model(inputs), outputs).numpy())
Current loss:
7.92897
定义训练循环
我们现在有了网络和培训数据。我们来训练一下,使用训练数据更新模型的变量 ( W 和 b),以便使用梯度下降减少损失。在 tf.train.Optimizer 实现中有许多梯度下降方案的变体。我们强烈建议使用这种实现,但本着从基本原理出发的精神,在这个特定的例子中,我们将自己实现基本的数学。
def train(model, inputs, outputs, learning_rate): with tf.GradientTape() as t: current_loss = loss(model(inputs), outputs) dW, db = t.gradient(current_loss, [model.W, model.b]) model.W.assign_sub(learning_rate * dW) model.b.assign_sub(learning_rate * db)
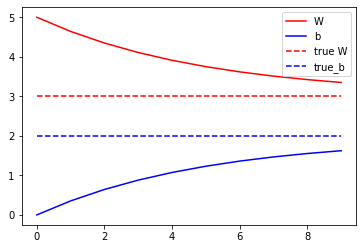
最后,让我们反复运行训练数据,看看 W 和 b 是如何发展的。
model = Model()# Collect the history of W-values and b-values to plot laterWs, bs = [], []epochs = range(10)for epoch in epochs: Ws.append(model.W.numpy()) bs.append(model.b.numpy()) current_loss = loss(model(inputs), outputs) train(model, inputs, outputs, learning_rate=0.1) print('Epoch %2d: W=%1.2f b=%1.2f, loss=%2.5f' % (epoch, Ws[-1], bs[-1], current_loss))# Let's plot it allplt.plot(epochs, Ws, 'r', epochs, bs, 'b')plt.plot([TRUE_W] * len(epochs), 'r--', [TRUE_b] * len(epochs), 'b--')plt.legend(['W', 'b', 'true W', 'true_b'])plt.show()
Epoch 0: W=5.00 b=0.00, loss=7.92897Epoch 1: W=4.64 b=0.35, loss=5.61977Epoch 2: W=4.35 b=0.64, loss=4.07488Epoch 3: W=4.11 b=0.88, loss=3.04133Epoch 4: W=3.91 b=1.07, loss=2.34987Epoch 5: W=3.75 b=1.23, loss=1.88727Epoch 6: W=3.62 b=1.36, loss=1.57779Epoch 7: W=3.51 b=1.47, loss=1.37073Epoch 8: W=3.42 b=1.55, loss=1.23221Epoch 9: W=3.35 b=1.62, loss=1.13954
下一步
在本教程中,我们介绍了变量 Variables,使用了到目前为止讨论的 TensorFlow 基本原理构建并训练了一个简单的线性模型。
从理论上讲,这几乎是您使用 TensorFlow 进行机器学习研究所需要的全部内容。在实践中,特别是对于神经网络,更高级别的 API tf.keras 会更方便,因为它提供更高级别的构建块(称为 “层”),保存和恢复状态的实用程序,一套损失函数,一套优化策略等等。
- 相关推荐
- 热点推荐
- 机器学习
- tensorflow
-
如何使用TensorFlow构建机器学习模型2024-01-08 1899
-
关于 TensorFlow2018-03-30 2587
-
干货!教你怎么搭建TensorFlow深度学习开发环境!2018-09-27 4517
-
tensorflow机器学习日志2020-04-14 2447
-
TensorFlow的特点和基本的操作方式2020-11-23 2910
-
labview+yolov4+tensorflow+openvion深度学习2021-05-10 20849
-
如何用BMlang搭建Tensorflow模型?2023-09-18 973
-
TensorFlow的框架结构解析2018-04-04 7534
-
深度学习的发展与应用,TensorFlow从研究到实践2018-06-05 5191
-
Swift for TensorFlow:无边界机器学习,值得大家期待2019-09-20 3411
-
推荐初学者的TensorFlow延伸阅读2020-11-04 2591
-
使用TensorFlow建立深度学习和机器学习网络2021-03-26 1162
-
如何使用TensorFlow进行大规模和分布式的QML模拟2021-08-10 3494
-
使用TensorFlow对自平衡机器人进行手势控制2022-11-09 828
-
轻松入门,高效成长: "TensorFlow 机器学习技能解锁季"2022-11-10 1446
全部0条评论

快来发表一下你的评论吧 !
