

ίοΓϊ╜ΧίΙδώΑιίΠψϊ┐κϊ╗╗ύγΕόε║ίβρίφοϊ╣ιόρκίηΜΎ╝θίΖΙϋοΒύΡΗϋπμϊ╕ΞύκχίχγόΑπ
ϊ║║ί╖ξόβ║ϋΔ╜
όΠΠϋ┐░
όζξό║ΡΎ╝γόε║ίβρϊ╣Μί┐Δύ╝ΨϋψΣ ϊ╜εϋΑΖΎ╝γEric Jang
ϊ╕ΞύκχίχγόΑπόαψόε║ίβρίφοϊ╣ιώλΗίθθίΗΖϊ╕Αϊ╕ςώΘΞϋοΒύγΕύιΦύσ╢ϊ╕╗ώλαΎ╝ΝEric Jangϋ┐ΣόΩξύγΕϊ╕ΑύψΘίΞγίχλίψ╣ϋ┐βϊ╕Αϊ╕╗ώλαϋ┐δϋκΝϊ║Ηϋψού╗ΗύγΕώαΡϋ┐░ήΑΓώκ║ϊ╛┐ϊ╕ΑόΠΡΎ╝Νϊ╗ΨύγΕίΞγίχλϋ┐αόεΚϊ╕Αϊ║δόεΚϋ╢μύγΕό╖▒ί║οίφοϊ╣ιϋ┐╖ίδιήΑΓ
ίερϋ░ΙίΙ░ϊ║║ί╖ξόβ║ϋΔ╜ίχΚίΖρήΑΒώμΟώβσύχκύΡΗήΑΒόΛΧϋ╡Εύ╗ΕίΡΙϊ╝αίΝΨήΑΒύπΣίφοό╡ΜώΘΠίΤΝϊ┐ζώβσόΩ╢Ύ╝Νϊ║║ϊ╗υώΔ╜ϊ╝γόΠΡίΙ░ήΑΝϊ╕ΞύκχίχγόΑπΎ╝ΙuncertaintyΎ╝ΚήΑΞύγΕόοΓί┐╡ήΑΓϊ╕ΜώζλόεΚίΘιϊ╕ςϊ║║ϊ╗υϋρΑϋψφϊ╕φό╢ΚίΠΛϊ╕ΞύκχίχγόΑπύγΕϊ╛ΜίφΡΎ╝γ
ήΑΝόΙΣϊ╗υόΔ│ϋχσόε║ίβρίφοϊ╣ιόρκίηΜύθξώΒΥίχΔϊ╗υϊ╕ΞύθξώΒΥύγΕϊ╕εϋξ┐ήΑΓήΑΞ
ήΑΝϋ┤θϋ┤μϋψΛόΨφύΩΖϊ║║ίΤΝύ╗βίΘ║ό▓╗ύΨΩόΨ╣όκΙύγΕAIί║ΦϋψξίΣΛϋψΚόΙΣϊ╗υίχΔίψ╣ϋΘςί╖▒ύγΕόΟρϋΞΡύγΕϊ┐κί┐ΔήΑΓήΑΞ
ήΑΝύπΣίφοϋχκύχΩϊ╕φύγΕόα╛ϋΣΩόΑπίΑ╝ϊ╗μϋκρϊ║Ηό╡ΜώΘΠϊ╕φύγΕϊ╕ΞύκχίχγόΑπήΑΓήΑΞ
ήΑΝόΙΣϊ╗υόΔ│ϋχσϋΘςίΛρόβ║ϋΔ╜ϊ╜ΥόΟλύ┤λίχΔϊ╗υϊ╕ΞύκχίχγΎ╝Ιίψ╣ϊ║ΟίξΨίΛ▒όΙΨώλΕό╡ΜΎ╝ΚύγΕίΝ║ίθθΎ╝Νϋ┐βόι╖ίχΔϊ╗υϊ╣θϋχ╕ϋΔ╜ίΠΣύΟ░ύρΑύΨΠύγΕίξΨίΛ▒ήΑΓήΑΞ
ήΑΝίερόΛΧϋ╡Εύ╗ΕίΡΙϊ╝αίΝΨϊ╕φΎ╝ΝόΙΣϊ╗υί╕ΝόεδόεΑίνπίΝΨίδηόΛξΎ╝ΝίΡΝόΩ╢ώβΡίΙ╢ώμΟώβσήΑΓήΑΞ
ήΑΝύΦ▒ϊ║Οίε░ύ╝αόΦ┐ό▓╗ϊ╕ΞύκχίχγόΑπίληίνπΎ╝Νύ╛Οίδ╜ϋΓκί╕Γ2018ί╣┤ίερίν▒όεδϊ╕φόΦ╢ί░╛ήΑΓήΑΞ
ώΓμήΑΝϊ╕ΞύκχίχγόΑπήΑΞύσ╢ύτθόαψϊ╗Αϊ╣ΙΎ╝θ
ϊ╕ΞύκχίχγόΑπί║οώΘΠίΠΞόαιύγΕόαψϊ╕Αϊ╕ςώγΠόε║ίΠαώΘΠύγΕύο╗όΧμύρΜί║οΎ╝ΙdispersionΎ╝ΚήΑΓόΞλίΠξϋψζϋψ┤Ύ╝Νϋ┐βόαψϊ╕Αϊ╕ςόιΘώΘΠΎ╝ΝίΠΞί║Φϊ║Ηϊ╕Αϊ╕ςώγΠόε║ίΠαώΘΠόεΚίνγήΑΝώγΠόε║ήΑΞήΑΓίερώΘΣϋηΞώλΗίθθΎ╝Νϋ┐βώΑγί╕╕ϋλτύπ░ϊ╕║ήΑΝώμΟώβσήΑΞήΑΓ
ϊ╕ΞύκχίχγόΑπϊ╕ΞόαψόθΡύπΞίΞΧϊ╕Αί╜λί╝ΠΎ╝Νίδιϊ╕║ϋκκώΘΠύο╗όΧμύρΜί║ούγΕόΨ╣ό│ΧόεΚί╛ΙίνγΎ╝γόιΘίΘΗί╖χήΑΒόΨ╣ί╖χήΑΒώμΟώβσίΑ╝Ύ╝ΙVaRΎ╝ΚίΤΝύΗ╡ώΔ╜όαψίΡΙώΑΓύγΕί║οώΘΠήΑΓϊ╜ΗόαψΎ╝ΝϋοΒϋχ░ϊ╜Πϊ╕ΑύΓ╣Ύ╝γίΞΧϊ╕ςόιΘώΘΠόΧ░ίΑ╝ϊ╕ΞϋΔ╜όΠΠύ╗αήΑΝώγΠόε║όΑπήΑΞύγΕόΧ┤ϊ╜Υίδ╛όβψΎ╝Νίδιϊ╕║ϋ┐βώεΑϋοΒϊ╝ιώΑΤόΧ┤ϊ╕ςώγΠόε║ίΠαώΘΠόευϋ║τόΚΞϋκΝΎ╝Β
ί░╜ύχκίοΓόφνΎ╝Νϊ╕║ϊ║Ηϊ╝αίΝΨίΤΝόψΦϋ╛ΔΎ╝Νί░ΗώγΠόε║όΑπίΟΜύ╝σόΙΡίΞΧϊ╕ςόΧ░ίΑ╝ϊ╗ΞύΕ╢όαψόεΚύΦρύγΕήΑΓόΑ╗ϊ╣ΜϋοΒϋχ░ϊ╜ΠΎ╝ΝήΑΝϋ╢ΛώταύγΕϊ╕ΞύκχίχγόΑπήΑΞί╛Αί╛ΑϋλτϋπΗϊ╕║ήΑΝόδ┤ύ│θύ│ΧήΑΞΎ╝Ιώβνϊ║ΗίερόρκόΜθί╝║ίΝΨίφοϊ╣ιίχηώςΝϊ╕φΎ╝ΚήΑΓ
ϊ╕ΞύκχίχγόΑπύγΕύ▒╗ίηΜ
ύ╗θϋχκόε║ίβρίφοϊ╣ιίΖ│ό│ρύγΕόαψόρκίηΜp(θ|D)ύγΕϊ╝░ϋχκΎ╝Νϋ┐δϋΑΝίΠΙϊ╝░ϋχκύγΕόαψόεςύθξώγΠόε║ίΠαώΘΠp(y|x)ήΑΓίΖ╢ϊ╕φόεΚίνγύπΞϊ╕ΞίΡΝί╜λί╝ΠύγΕϊ╕ΞύκχίχγόΑπήΑΓόθΡϊ║δϊ╕ΞύκχίχγόΑπύγΕόοΓί┐╡όΠΠϋ┐░ϊ║ΗόΙΣϊ╗υϋΔ╜ίνθώλΕόεθύγΕίδ║όεΚύγΕώγΠόε║όΑπΎ╝ΙόψΦίοΓόΛδύκυί╕ΒύγΕύ╗ΥόηεΎ╝ΚΎ╝ΝίΠοϊ╕Αϊ║δόοΓί┐╡ίΙβόΠΠϋ┐░ϊ║ΗόΙΣϊ╗υίψ╣όρκίηΜίΠΓόΧ░ύγΕόεΑϊ╜│ύΝεό╡ΜύγΕϊ┐κί┐Δύ╝║ϊ╣ΠύρΜί║οήΑΓ
ϊ╕║ϊ║Ηϋψ┤ί╛ΩίΖ╖ϊ╜Υϊ╕ΑύΓ╣Ύ╝ΝόΙΣϊ╗υίΒΘϋχ╛όεΚϊ╕Αϊ╕ςί╛ςύΟψύξηύ╗Πύ╜Σύ╗εΎ╝ΙRNNΎ╝ΚώεΑϋοΒόι╣όΞχϊ╕Αϊ╕ςόψΠόΩξό░ΦίΟΜϋκρϋψ╗όΧ░ί║ΠίΙΩώλΕό╡Μί╜ΥίνσύγΕώβΞώδρώΘΠήΑΓό░ΦίΟΜϋκρϋΔ╜όμΑό╡Μίνπό░ΦίΟΜΎ╝Νίνπό░ΦίΟΜϊ╕ΜώβΞί╛Αί╛ΑόαψώβΞώδρύγΕίΚΞίΖΗήΑΓϊ╕Μίδ╛όΑ╗ύ╗Υϊ║ΗώβΞώδρώΘΠώλΕό╡ΜόρκίηΜϊ╕Οϊ╕ΞίΡΝύ▒╗ίηΜύγΕϊ╕ΞύκχίχγόΑπήΑΓ
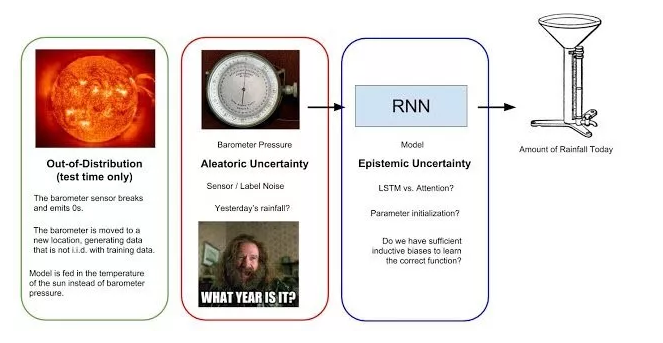
ίδ╛1Ύ╝γϋψΧίδ╛όι╣όΞχό░ΦίΟΜϋκρϋψ╗όΧ░ί║ΠίΙΩώλΕό╡ΜόψΠόΩξώβΞώδρώΘΠύγΕύχΑίΞΧόε║ίβρίφοϊ╣ιόρκίηΜίΠψϋΔ╜ϋΑΔϋβΣύγΕϊ╕ΞύκχίχγόΑπήΑΓίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπΎ╝ΙAleatoricUncertaintyΎ╝Κό║ΡϋΘςόΧ░όΞχόΦ╢ώδΗϋ┐ΘύρΜΎ╝Νόαψϊ╕ΞίΠψώβΞϊ╜ΟύγΕώγΠόε║όΑπήΑΓϋχνύθξϊ╕ΞύκχίχγόΑπΎ╝ΙEpistemicUncertaintyΎ╝ΚίΠΞόαιύγΕόαψόρκίηΜίΒγίΘ║όφμύκχώλΕό╡ΜύγΕύ╜χϊ┐κύρΜί║οήΑΓόεΑίΡΟΎ╝Νϋ╢ΖίΘ║ίΙΗί╕ΔύγΕϋψψί╖χΎ╝ΙOut-of-DistributionerrorΎ╝ΚόαψόΝΘί╜ΥόρκίηΜύγΕϋ╛ΥίΖξϊ╕ΞίΡΝϊ║ΟίΖ╢ϋχφύ╗ΔόΧ░όΞχόΩ╢ίΘ║ύΟ░ύγΕϊ╕ΞύκχίχγόΑπΎ╝ΙόψΦίοΓίνςώα│ό╕σί║ούφΚίΖ╢ίχΔί╝Γί╕╕ύΟ░ϋ▒κΎ╝ΚήΑΓ
ίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπ
ίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπί╛ΩίΡΞϊ║ΟόΜΚϊ╕ΒϋψφϋψΞόι╣aleatoriusΎ╝ΝόΕΠϊ╕║ήΑΝί░ΗίΘιύΟΘύ║│ίΖξίΙδώΑιϋ┐ΘύρΜήΑΞήΑΓϋ┐βόΠΠϋ┐░ύγΕόαψό║ΡϋΘςόΧ░όΞχύΦθόΙΡϋ┐ΘύρΜόευϋ║τύγΕώγΠόε║όΑπΎ╝δϊ╕ΞϋΔ╜ύχΑίΞΧίε░ώΑγϋ┐ΘόΦ╢ώδΗόδ┤ίνγόΧ░όΞχϋΑΝό╢ΙώβνύγΕίβςίμ░ήΑΓί░▒ίΔΠϊ╜ιϊ╕ΞϋΔ╜ώλΕύθξύ╗ΥόηεύγΕόΛδύκυί╕ΒήΑΓ
ίερώβΞώδρώΘΠώλΕό╡ΜύγΕύ▒╗όψΦϊ╕φΎ╝ΝίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπό║ΡϋΘςό░ΦίΟΜϋκρύγΕϊ╕ΞίΘΗύκχί║οήΑΓϊ╣θϋ┐αίφαίερϋ┐βύπΞόΧ░όΞχόΦ╢ώδΗόΨ╣ό│Χό▓κόεΚϋπΓίψθύγΕώΘΞϋοΒίΠαώΘΠΎ╝γόαρόΩξύγΕώβΞώδρώΘΠόαψίνγί░ΣΎ╝θόΙΣϊ╗υό╡ΜώΘΠίνπό░ΦίΟΜύγΕόΩ╢ϊ╗μόαψύΟ░ϊ╗μϋ┐αόαψϊ╕Λϊ╕ςίΗ░ό▓│όΩ╢ϊ╗μΎ╝θϋ┐βϊ║δόεςύθξόαψόΙΣϊ╗υύγΕόΧ░όΞχόΦ╢ώδΗόΨ╣ό│Χϊ╕φίδ║όεΚύγΕΎ╝ΝόΚΑϊ╗ξύΦρϋψξύ│╗ύ╗θόΦ╢ώδΗόδ┤ίνγόΧ░όΞχόΩιό│Χί╕χίΛσόΙΣϊ╗υό╢Ιώβνϋ┐βϊ╕Αϊ╕ΞύκχίχγόΑπήΑΓ
ίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπϊ╝γϊ╗Οϋ╛ΥίΖξϊ╝ιόΤφίΙ░όρκίηΜύγΕώλΕό╡Μύ╗ΥόηεήΑΓίΒΘϋχ╛όεΚϊ╕Αϊ╕ςύχΑίΞΧόρκίηΜy=5xΎ╝ΝίχΔύγΕϋ╛ΥίΖξίΠΨϋΘςόφμόΑΒίΙΗί╕ΔxΎ╜ηN(0,1)ήΑΓίερϋ┐βϊ╕ΑόκΙϊ╛Μϊ╕φΎ╝ΝyΎ╜ηN(0,5)Ύ╝ΝίδιόφνϋψξώλΕό╡ΜίΙΗί╕ΔύγΕίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπίΠψόΠΠϋ┐░ϊ╕║σ=5ήΑΓί╜ΥύΕ╢Ύ╝Νί╜Υϋ╛ΥίΖξόΧ░όΞχxύγΕώγΠόε║ύ╗ΥόηΕόεςύθξόΩ╢Ύ╝ΝώλΕό╡Μύ╗ΥόηεύγΕίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπί░Ηόδ┤ώγ╛ϊ╝░ϋχκήΑΓ
ϊ╣θϋχ╕όεΚϊ║║ϊ╝γόΔ│Ύ╝γίδιϊ╕║ίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπόαψϊ╕ΞίΠψύ║οίΘΠύγΕΎ╝ΝόΚΑϊ╗ξόΙΣϊ╗υίψ╣όφνόΩιϋΔ╜όΩιίΛδΎ╝Νύδ┤όΟξί┐╜ύΧξίχΔί░▒ίξ╜ϊ║ΗήΑΓϋ┐βίΠψϊ╕ΞϋκΝΎ╝Βίερϋχφύ╗ΔόρκίηΜόΩ╢Ύ╝Νί║Φϋψξό│ρόΕΠώΑΚόΜσϋΔ╜ίνθόφμύκχίε░ϊ╗μϋκρίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπύγΕϋ╛ΥίΘ║ϋκρί╛ΒήΑΓόιΘίΘΗύγΕLSTMϊ╕Ξϊ╝γί╛ΩίΘ║όοΓύΟΘίΙΗί╕ΔΎ╝ΝόΚΑϊ╗ξίφοϊ╣ιόΛδύκυί╕ΒύγΕύ╗ΥόηεόΩ╢ίΠςϊ╝γόΦ╢όΧδόΙΡίζΘίΑ╝ήΑΓύδ╕ίψ╣ϋΑΝϋρΑΎ╝ΝύΦρϊ║ΟϋψφϋρΑύΦθόΙΡύγΕόρκίηΜϋΔ╜ίνθί╛ΩίΘ║ϊ╕Αύ│╗ίΙΩύ▒╗ίΙτίΙΗί╕ΔΎ╝ΙϋψΞόΙΨίφΩύυοΎ╝ΚΎ╝Νϋ┐βϋΔ╜ύ║│ίΖξίΠξίφΡίχΝόΙΡϊ╗╗ίΛκϊ╕φύγΕίδ║όεΚόφπϊ╣ΚόΑπήΑΓ
ϋχνύθξϊ╕ΞύκχίχγόΑπ
ήΑΝίξ╜ύγΕόρκίηΜώΔ╜όαψύδ╕ϊ╝╝ύγΕΎ╝δί╖χύγΕόρκίηΜίΡΕόεΚϊ╕ΞίΡΝήΑΓήΑΞ
ϋχνύθξϊ╕ΞύκχίχγόΑπόζξϋΘςί╕ΝϋΖΛϋψφϋψΞόι╣epist─Υm─ΥΎ╝Νί▒ηϊ║Οϊ╕ΟύθξϋψΗύδ╕ίΖ│ύγΕύθξϋψΗήΑΓϋ┐βϋκκώΘΠϊ║ΗόΙΣϊ╗υίψ╣ήΑΝό║ΡϋΘςόΙΣϊ╗υίψ╣όφμύκχόρκίηΜίΠΓόΧ░ύγΕόΩιύθξύρΜί║οήΑΞύγΕόφμύκχώλΕό╡ΜύγΕόΩιύθξύρΜί║οήΑΓ
ϊ╕Μίδ╛ί▒Χύν║ϊ║Ηϊ╕Αϊ╕ςίερόθΡϊ╕ςύχΑίΞΧύγΕϊ╕Αύ╗┤όΧ░όΞχώδΗϊ╕ΛύγΕώταόΨψϋ┐ΘύρΜίδηί╜ΤόρκίηΜήΑΓίΖ╢ύ╜χϊ┐κίΝ║ώΩ┤ίΠΞόαιϊ║Ηϋχνύθξϊ╕ΞύκχίχγόΑπΎ╝δϋχφύ╗ΔόΧ░όΞχύγΕϋχνύθξϊ╕ΞύκχίχγόΑπϊ╕║ώδ╢Ύ╝Ιύ║λύΓ╣Ύ╝ΚήΑΓώγΠύζΑόΙΣϊ╗υύο╗ϋχφύ╗ΔόΧ░όΞχύΓ╣ύγΕϋ╖ζύο╗ϋ╢Λϋ┐εΎ╝ΝόρκίηΜί║Φϋψξύ╗βώλΕό╡ΜίΙΗί╕ΔίΙΗώΖΞϋ╢ΛώταύγΕόιΘίΘΗί╖χήΑΓϊ╕ΞίΡΝϊ║ΟίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπΎ╝Νϋχνύθξϊ╕ΞύκχίχγόΑπίΠψϊ╗ξώΑγϋ┐ΘόΦ╢ώδΗόδ┤ίνγόΧ░όΞχίΤΝήΑΝίΟ╗ώβνήΑΞόρκίηΜύ╝║ϊ╣ΠύθξϋψΗύγΕϋ╛ΥίΖξίΝ║ίθθϋΑΝώβΞϊ╜ΟήΑΓ
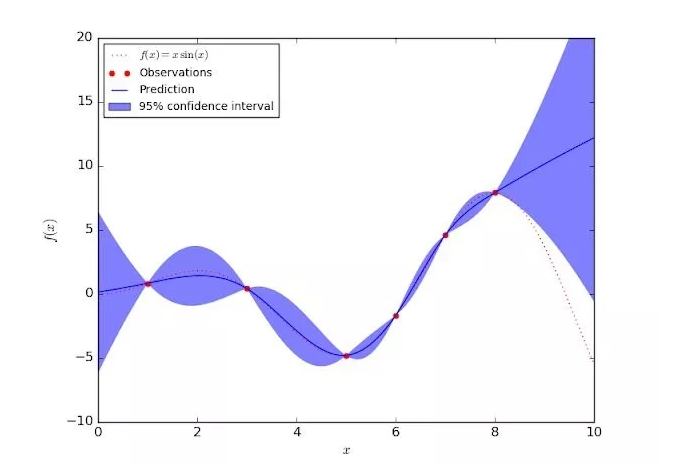
ίδ╛2Ύ╝γϊ╕Αύ╗┤ώταόΨψϋ┐ΘύρΜίδηί╜ΤόρκίηΜΎ╝Νί▒ΧύΟ░ϊ║Ηϋχφύ╗ΔώδΗϊ╣ΜίνΨύγΕϋ╛ΥίΖξϊ╕ΛύγΕϋχνύθξϊ╕ΞύκχίχγόΑπ
ό╖▒ί║οίφοϊ╣ιϊ╕ΟώταόΨψϋ┐ΘύρΜϊ╣ΜώΩ┤όεΚϊ╕░ίψΝύγΕίΖ│ϋΒΦήΑΓϊ║║ϊ╗υί╕ΝόεδϋΔ╜ώΑγϋ┐Θύξηύ╗Πύ╜Σύ╗εύγΕϋκρί╛ΒϋΔ╜ίΛδόΚσί▒ΧώταόΨψϋ┐ΘύρΜύγΕϋΔ╜όΕθύθξϊ╕ΞύκχίχγόΑπύγΕόΑπϋ┤ρήΑΓϊ╕Ξί╣╕ύγΕόαψΎ╝ΝώταόΨψϋ┐ΘύρΜώγ╛ϊ╗ξόΚσί▒ΧύΦρϊ║ΟίνπόΧ░όΞχώδΗύγΕύ╗θϊ╕ΑώγΠόε║ί░ΠόΚ╣ώΘΠϋχ╛ύ╜χΎ╝ΝϋΑΝϊ╕ΦύιΦύσ╢ίνπίηΜόρκίηΜίΤΝόΧ░όΞχώδΗύγΕϊ║║ϊ╣θί╖▓ύ╗Πϊ╕ΞίΗΞόΦψόΝΒϋ┐βύπΞόΨ╣ό│ΧήΑΓ
ίοΓόηεϊ║║ϊ╗υί╕ΝόεδίερώΑΚόΜσόρκίηΜόΩΠόΩ╢όεΚόεΑίνπύγΕύΒ╡ό┤╗ί║οΎ╝Νϊ╜┐ύΦρώδΗόΙΡΎ╝ΙensembleΎ╝ΚόΨ╣ό│Χόζξϊ╝░ϋχκϊ╕ΞύκχίχγόΑπόαψϊ╕Αϊ╕ςίξ╜ώΑΚόΜσΎ╝Νϋ┐βίχηώβΖϊ╕Λί░▒όαψϊ╜┐ύΦρήΑΝίνγϊ╕ςύΜυύτΜύγΕίφοϊ╣ιίΡΟύγΕόρκίηΜήΑΞήΑΓώταόΨψϋ┐ΘύρΜόρκίηΜόαψίΙΗόηΡί╝Πίε░ίχγϊ╣ΚώλΕό╡ΜίΙΗί╕ΔΎ╝ΝϋΑΝώδΗόΙΡόΨ╣ό│ΧίΙβϋλτύΦρϊ║ΟϋχκύχΩώλΕό╡ΜύγΕύ╗ΠώςΝίΙΗί╕ΔΎ╝ΙempiricaldistributionΎ╝ΚήΑΓ
ύΦ▒ϊ║Οϋχφύ╗Δϋ┐ΘύρΜϊ╕φίΘ║ύΟ░ύγΕώγΠόε║ίΝΨίΒΠί╖χΎ╝Νϊ╗╗ϊ╜ΧίΞΧϊ╕ςόρκίηΜώΔ╜ϊ╝γόεΚϊ╕Αϊ║δϋψψί╖χήΑΓίερώδΗόΙΡόΨ╣ό│Χϊ╕φΎ╝ΝίΖ╢ίχΔόρκίηΜί╛Αί╛Αϊ╝γόΠφύν║ίΘ║ίΞΧϊ╕ςόρκίηΜύΚ╣όεΚύγΕώΦβίνΕϊ╣ΜίνΕΎ╝ΝίΡΝόΩ╢ϋχνίΡΝόΟρύΡΗόφμύκχύγΕώλΕό╡Μύ╗ΥόηεΎ╝δίδιόφνώδΗόΙΡόρκίηΜόαψί╛Ιί╝║ίνπύγΕήΑΓ
όΙΣϊ╗υϋψξίοΓϊ╜ΧώγΠόε║ίΠΨόι╖όρκίηΜϊ╗ξόηΕί╗║ϊ╕Αϊ╕ςώδΗόΙΡόρκίηΜίΣλΎ╝θίερϊ╜┐ύΦρbootstrapaggregationόηΕί╗║ώδΗόΙΡόρκίηΜόΩ╢Ύ╝ΝόΙΣϊ╗υώοΨίΖΙϊ╗Οϊ╕Αϊ╕ςίνπί░Πϊ╕║NύγΕϋχφύ╗ΔόΧ░όΞχώδΗί╝ΑίπΜΎ╝Νί╣╢ϊ╗ΟίΟθίπΜϋχφύ╗ΔώδΗώΘΘόι╖Mϊ╕ςίνπί░Πϊ╕║NύγΕόΧ░όΞχΎ╝ΙόεΚόδ┐όΞλΎ╝Νϋ┐βόι╖όψΠϊ╕ςόΧ░όΞχώδΗώΔ╜ϊ╕Ξϊ╝γίΞιόΞχόΧ┤ϊ╕ςόΧ░όΞχώδΗΎ╝ΚήΑΓίΙΗίΙτίερϋ┐βϊ║δόΧ░όΞχώδΗϊ╕Λϋχφύ╗ΔMϊ╕ςόρκίηΜΎ╝ΝίΗΞί░ΗίχΔϊ╗υύγΕώλΕό╡Μύ╗Υόηεύ╗╝ίΡΙϋ╡╖όζξί╛ΩίΙ░ϊ╕Αϊ╕ςύ╗ΠώςΝώλΕό╡ΜίΙΗί╕ΔήΑΓ
ίοΓόηεϋχφύ╗Δίνγϊ╕ςόρκίηΜύγΕόΙΡόευϋ┐ΘώταΎ╝Νϊ╣θίΠψϊ╗ξϊ╜┐ύΦρdropoutϋχφύ╗Δόζξϋ┐Σϊ╝╝όρκίηΜώδΗόΙΡήΑΓϊ╜ΗόαψΎ╝Νί╝ΧίΖξdropoutϊ╝γό╢ΚίΠΛίΙ░ϊ╕Αϊ╕ςώλζίνΨύγΕϋ╢ΖίΠΓόΧ░ί╣╢ϊ╕Φϊ╣θίΠψϋΔ╜όεΚόΞθίΞΧϊ╕ςόρκίηΜύγΕϋκρύΟ░Ύ╝Ιίψ╣ϊ║ΟίχηώβΖί║ΦύΦρϋΑΝϋρΑί╛Αί╛Αόαψϊ╕ΞίΠψόΟξίΠΩύγΕΎ╝δίερίχηώβΖί║ΦύΦρϊ╕φΎ╝ΝόικίΘΗϊ╕ΞύκχίχγόΑπϊ╝░ϋχκύδ╕ίψ╣ίΘΗύκχί║οϋΑΝϋρΑόαψόυκϋοΒύγΕΎ╝ΚήΑΓ
ίδιόφνΎ╝ΝίοΓόηεϋΔ╜ϊ╜┐ύΦρίνπώΘΠϋχκύχΩϋ╡Εό║ΡΎ╝Ιί░▒ίΔΠϋ░╖όφΝώΓμόι╖Ύ╝ΚΎ╝ΝώΑγί╕╕ίΠςώεΑϋοΒώΘΞίνΞϋχφύ╗Δίνγϊ╕ςόρκίηΜίΚψόευΎ╝Νϋ┐βϋοΒόδ┤ίΛιίχ╣όαΥήΑΓϋ┐βϋ┐αϋΔ╜ίερόΩιόΞθόΑπϋΔ╜ύγΕίΚΞόΠΡϊ╕Μϊ║τίΠΩώδΗόΙΡόΨ╣ό│ΧύγΕίξ╜ίνΕήΑΓϋ┐βύψΘό╖▒ί║οώδΗόΙΡϋχ║όΨΘί░▒ώΘΘύΦρϊ║Ηϋ┐βϊ╕ΑόΨ╣ό│ΧΎ╝γhttps://arxiv.org/pdf/1612.01474.pdfήΑΓϋ┐βύψΘϋχ║όΨΘύγΕϊ╜εϋΑΖϋ┐αόΠΡίΙ░ύΦ▒ϊ╕ΞίΡΝύγΕόζΔώΘΞίΙζίπΜίΝΨί╕οόζξύγΕώγΠόε║ϋχφύ╗ΔίΛρόΑΒϋ╢│ϊ╗ξί╛ΩίΙ░ϊ╕Αϊ╕ςίνγόι╖ίΝΨύγΕόρκίηΜώδΗίΡΙΎ╝ΝϋΑΝϊ╕Ξί┐ΖώΑγϋ┐ΘbootstrapaggregationόζξώβΞϊ╜Οϋχφύ╗ΔώδΗίνγόι╖όΑπήΑΓϊ╗ΟίχηώβΖύγΕί╖ξύρΜί╝ΑίΠΣϋπΤί║ούεΜΎ╝ΝόΛ╝ό│ρϊ╕Ξϊ╝γί╜▒ίΥΞόρκίηΜόΑπϋΔ╜ύγΕώμΟώβσϊ╝░ϋχκόΨ╣ό│ΧόΙΨύιΦύσ╢ϋΑΖόΔ│ϋοΒί░ζϋψΧύγΕίΖ╢ίχΔόΨ╣ό│ΧόαψόαΟόβ║ύγΕ
ϋ╢ΖίΘ║ίΙΗί╕ΔύγΕϊ╕ΞύκχίχγόΑπ
ίψ╣ϊ║ΟόΙΣϊ╗υύγΕώβΞώδρώΘΠώλΕό╡ΜίβρΎ╝ΝίοΓόηεόΙΣϊ╗υϊ╕║ίΖ╢όΠΡϊ╛δύγΕϋ╛ΥίΖξϊ╕Ξόαψό░ΦίΟΜϋκρϋψ╗όΧ░ί║ΠίΙΩΎ╝ΝϋΑΝόαψίνςώα│ύγΕό╕σί║οίΣλΎ╝θϋοΒόαψόΠΡϊ╛δϊ╕Αϊ╕ςίΖρόαψώδ╢ύγΕί║ΠίΙΩίΣλΎ╝θόΙΨϋΑΖύΦρϊ╕ΞίΡΝύγΕίΞΧϊ╜Ξϋχ░ί╜ΧύγΕό░ΦίΟΜϋκρϋψ╗όΧ░ίΣλΎ╝θRNNϋ┐αόαψϊ╝γύ╗πύ╗φϋχκύχΩΎ╝Νϊ╕║όΙΣϊ╗υόΠΡϊ╛δϊ╕Αϊ╕ςώλΕό╡ΜΎ╝Νϊ╜Ηύ╗Υόηεί╛ΙίΠψϋΔ╜όψτόΩιόΕΠϊ╣ΚήΑΓ
ϋ┐βϊ╕ςόρκίηΜίχΝίΖρό▓κόεΚϋΔ╜ίΛδίθ║ϊ║ΟώΑγϋ┐Θϊ╕ΞίΡΝϊ║Οϋχφύ╗ΔώδΗίΙδί╗║ό╡ΒύρΜύγΕό╡ΒύρΜύΦθόΙΡύγΕόΧ░όΞχϋ┐δϋκΝώλΕό╡ΜήΑΓίερίθ║ίΘΗώσ▒ίΛρύγΕόε║ίβρίφοϊ╣ιύιΦύσ╢ώλΗίθθΎ╝Νϋ┐βόαψϊ╕ΑύπΞί╕╕ϋλτί┐╜ϋπΗύγΕίν▒ϋ┤ξόρκί╝ΠΎ╝Νίδιϊ╕║όΙΣϊ╗υώΑγί╕╕ίΒΘϋχ╛ϋχφύ╗ΔήΑΒώςΝϋψΒίΤΝό╡ΜϋψΧώδΗώΔ╜ίχΝίΖρύΦ▒ύΜυύτΜίΡΝίΙΗί╕ΔύγΕόΧ░όΞχόηΕόΙΡήΑΓ
ύκχίχγϋ╛ΥίΖξόαψίΡοήΑΝόεΚόΧΙήΑΞόαψίχηώβΖώΔρύ╜▓όε║ίβρίφοϊ╣ιόΚΑώζλϊ╕┤ύγΕϊ╕Αϊ╕ςϊ╕ξί│╗ώΩχώλαΎ╝Νϋ┐βϊ╣θϋλτύπ░ϊ╕║ϋ╢ΖίΘ║ίΙΗί╕ΔΎ╝ΙOoD/OutofDistributionΎ╝ΚώΩχώλαήΑΓOoDϊ╕ΟήΑΝόρκίηΜϋψψϋχ╛ώΦβϋψψήΑΞίΤΝήΑΝί╝Γί╕╕όμΑό╡ΜήΑΞόαψίΡΝϊ╣ΚϋψΞήΑΓ
ί╝Γί╕╕όμΑό╡Μϊ╕Ξϊ╗Ζίψ╣ίληί╝║όε║ίβρίφοϊ╣ιύ│╗ύ╗θύρ│ίΒξόΑπί╛ΙώΘΞϋοΒΎ╝ΝϋΑΝϊ╕Φόευϋ║τϊ╣θόαψϊ╕ΑύπΞώζηί╕╕όεΚύΦρύγΕόΛΑόεψήΑΓϊ╕╛ϊ╕ςϊ╛ΜίφΡΎ╝ΝόΙΣϊ╗υίΠψϋΔ╜όΔ│όηΕί╗║ϊ╕Αϊ╕ςϋΔ╜ύδΣόΟπίΒξί║╖ϊ║║ίμτύγΕύΦθίΣ╜ϊ╜Υί╛ΒύγΕύ│╗ύ╗θΎ╝Νϋχσϋψξύ│╗ύ╗θϋΔ╜ίερόΝΘόιΘί╝Γί╕╕όΩ╢ίΠΣίΘ║ϋφοόΛξΎ╝Νϋ┐βί╣╢ϊ╕ΞώεΑϋοΒύ│╗ύ╗θϊ╣ΜίΚΞϋπΒϋ┐Θϋ┐βύπΞί╝Γί╕╕ύγΕύΩΖύΡΗόρκί╝ΠήΑΓόΙΣϊ╗υϊ╣θίΠψϊ╗ξύΦρί╝Γί╕╕όμΑό╡ΜόζξύχκύΡΗόΧ░όΞχϊ╕φί┐ΔύγΕήΑΝίΒξί║╖ήΑΞΎ╝Νϊ╕ΑόΩοόεΚϊ╕ΞίΡΝίψ╗ί╕╕ύγΕϊ║ΜόΔΖίΠΣύΦθΎ╝ΙύμΒύδαό╗κϋ╜╜ήΑΒίχΚίΖρό╝Πό┤ηήΑΒύκυϊ╗╢όΧΖώγεύφΚΎ╝ΚΎ╝ΝόΙΣϊ╗υί░▒ϋΔ╜ί╛ΩίΙ░ώΑγύθξήΑΓ
ίδιϊ╕║OoDϋ╛ΥίΖξϊ╗ΖίΘ║ύΟ░ίερό╡ΜϋψΧόΩ╢ώΩ┤Ύ╝ΝόΚΑϊ╗ξόΙΣϊ╗υϊ╕Ξί║ΦίΒΘϋχ╛όΙΣϊ╗υϊ║ΜίΖΙύθξώΒΥόρκίηΜϊ╝γώΒΘίΙ░ύγΕί╝Γί╕╕ύγΕίΙΗί╕ΔήΑΓϋ┐βόφμόαψOoDόμΑό╡ΜύγΕόμαόΚΜϊ╣ΜίνΕ——όΙΣϊ╗υί┐Ζώκ╗ώΤΙίψ╣όρκίηΜίερϋχφύ╗Δώα╢όχ╡ϊ╗ΟόεςϋπΒϋ┐ΘύγΕϋ╛ΥίΖξόζξίληί╝║ϋψξόρκίηΜίψ╣ϋ┐βϊ║δϋ╛ΥίΖξύγΕόΛΩόΑπΎ╝Βϋ┐βόφμόαψίψ╣όΛΩί╝Πόε║ίβρίφοϊ╣ιϊ╕φόΠΠϋ┐░ύγΕόιΘίΘΗύγΕόΦ╗ίΘ╗ίε║όβψήΑΓ
όε║ίβρίφοϊ╣ιόρκίηΜόεΚϊ╕νύπΞίνΕύΡΗOoDϋ╛ΥίΖξύγΕόΨ╣ό│ΧΎ╝γ1Ύ╝Κίερϋ╛ΥίΖξίΙ░ϋ╛╛όρκίηΜίΚΞί░▒ϋψΗίΙτίΘ║ύ│θύ│ΧύγΕϋ╛ΥίΖξΎ╝δ2Ύ╝Κόι╣όΞχόρκίηΜώλΕό╡Μύ╗ΥόηεύγΕήΑΝόΑςί╝ΓόΑπήΑΞόζξί╕χίΛσόΙΣϊ╗υώΚ┤ίΙτίΠψϋΔ╜ίφαίερώΩχώλαύγΕϋ╛ΥίΖξήΑΓ
ίερύυυϊ╕ΑύπΞόΨ╣ό│Χϊ╕φΎ╝ΝόΙΣϊ╗υϊ╕Ξϊ╝γίψ╣ϊ╕Μό╕╕όε║ίβρίφοϊ╣ιϊ╗╗ίΛκίΒγϊ╗╗ϊ╜ΧίΒΘϋχ╛Ύ╝ΝίΠςϊ╝γϋΑΔϋβΣϋ╛ΥίΖξόαψίΡοίνΕϊ║Οϋχφύ╗ΔίΙΗί╕Δϊ╕φύγΕώΩχώλαήΑΓϋ┐βόφμόαψύΦθόΙΡίψ╣όΛΩύ╜Σύ╗εΎ╝ΙGANΎ╝Κϊ╕φίΙνίΙτίβρύγΕί╖ξϊ╜εήΑΓϊ╜ΗόαψΎ╝ΝίΞΧϊ╕ςίΙνίΙτίβρί╣╢ϊ╕ΞίΖ╖όεΚίχΝύ╛ΟύγΕύρ│ίΒξόΑπΎ╝Νίδιϊ╕║ίχΔίΠςόΥΖώΧ┐ϋ╛ρίΙτύεθίχηόΧ░όΞχίΙΗί╕ΔίΤΝύΦθόΙΡίβρί╛ΩίΙ░ύγΕίΙΗί╕ΔΎ╝δίψ╣ϊ║Οϊ╕Ξί▒ηϊ║ΟίΖ╢ϊ╕φϊ╗╗όΕΠϊ╕Αϊ╕ςίΙΗί╕ΔύγΕϋ╛ΥίΖξϋΑΝϋρΑΎ╝ΝίχΔόεΚίΠψϋΔ╜ί╛ΩίΘ║ϊ╗╗όΕΠύγΕώλΕό╡Μύ╗ΥόηεήΑΓ
ώβνϊ║ΗίΙνίΙτίβρΎ╝ΝόΙΣϊ╗υϊ╣θίΠψϊ╗ξόηΕί╗║ϊ╕Αϊ╕ςίΙΗί╕ΔίΗΖόΧ░όΞχύγΕίψΗί║οόρκίηΜΎ╝ΝόψΦίοΓϊ╕Αϊ╕ςόι╕ίψΗί║οϊ╝░ϋχκίβρόΙΨύΦρϊ╕Αϊ╕ςNormalizingFlowόζξόΜθίΡΙόΧ░όΞχήΑΓHyunsunChoiίΤΝόΙΣόεΑϋ┐ΣύιΦύσ╢ϋ┐Θϋ┐βϊ╕ΑώΩχώλαΎ╝ΝίΠΓώαΖόΙΣϊ╗υόεΑϋ┐Σϊ╜┐ύΦρύΟ░ϊ╗μύΦθόΙΡόρκίηΜόΚπϋκΝOoDόμΑό╡ΜύγΕϋχ║όΨΘΎ╝γhttps://arxiv.org/abs/1810.01392
ύυυϊ║ΝύπΞOoDόμΑό╡ΜόΨ╣ό│Χό╢ΚίΠΛίΙ░ϊ╜┐ύΦρϊ╗╗ίΛκόρκίηΜύγΕώλΕό╡ΜΎ╝ΙϋχνύθξΎ╝Κϊ╕ΞύκχίχγόΑπόζξϋ╛ρίΙτίΥςϊ║δϋ╛ΥίΖξόαψOoDήΑΓύΡΗόΔ│όΔΖίΗ╡ϊ╕ΜΎ╝ΝόρκίηΜίερόΦ╢ίΙ░ώΦβϋψψύγΕϋ╛ΥίΖξόΩ╢ί║Φϋψξϊ╝γί╛ΩίΙ░ήΑΝόΑςί╝ΓύγΕήΑΞύγΕώλΕό╡ΜίΙΗί╕Δp(y|x)ήΑΓϊ╕╛ϊ╕ςϊ╛ΜίφΡΎ╝ΝHendrycksandGimpelΎ╝Ιhttps://arxiv.org/abs/1610.02136Ύ╝ΚϋκρόαΟOoDϋ╛ΥίΖξύγΕόεΑίνπίΝΨsoftmaxόοΓύΟΘΎ╝ΙώλΕό╡Μί╛ΩίΙ░ύγΕύ▒╗ίΙτΎ╝Κί╛Αί╛Αϊ╜Οϊ║ΟίΙΗί╕ΔίΗΖύγΕϋ╛ΥίΖξήΑΓϋ┐βώΘΝΎ╝Νϊ╕ΞύκχίχγόΑπίΠΞόψΦϊ║ΟόεΑίνπsoftmaxόοΓύΟΘί╗║όρκύγΕήΑΝύ╜χϊ┐κί║οήΑΞήΑΓώταόΨψϋ┐ΘύρΜϋ┐βόι╖ύγΕόρκίηΜϋΔ╜ώΑγϋ┐ΘόηΕώΑιϊ╕║όΙΣϊ╗υόΠΡϊ╛δϋ┐βϊ║δϊ╕ΞύκχίχγόΑπϊ╝░ϋχκΎ╝ΝόΙΨϋΑΖόΙΣϊ╗υϊ╣θίΠψώΑγϋ┐Θό╖▒ί║οώδΗόΙΡόζξϋχκύχΩϋχνύθξϊ╕ΞύκχίχγόΑπήΑΓ
ίερί╝║ίΝΨίφοϊ╣ιώλΗίθθΎ╝Νϊ║║ϊ╗υίχηώβΖϊ╕ΛίΒΘϋχ╛OoDϋ╛ΥίΖξόαψϊ╕Αϊ╗╢ίξ╜ϊ║ΜΎ╝Νίδιϊ╕║ϋ┐βόαψόβ║ϋΔ╜ϊ╜Υϋ┐αϊ╕ΞύθξώΒΥίοΓϊ╜ΧίνΕύΡΗύγΕϊ╕ΨύΧΝϋ╛ΥίΖξήΑΓώ╝ΥίΛ▒ύφΨύΧξίψ╗όΚ╛ϋΘςί╖▒ύγΕOoDϋ╛ΥίΖξϋΔ╜ίχηύΟ░ήΑΝίΗΖίερύγΕίξ╜ίξΘί┐ΔήΑΞΎ╝Νϊ╗ΟϋΑΝόΟλύ┤λόρκίηΜύγΕώλΕό╡ΜόΧΙόηεϋ╛Δί╖χύγΕίΝ║ίθθήΑΓϋ┐βόαψί╛Ιίξ╜ύγΕίΒγό│ΧΎ╝Νϊ╜ΗόΙΣί╛Ιίξ╜ίξΘίοΓόηεί░Ηϋ┐βύπΞίξ╜ίξΘί┐Δώσ▒ίΛρύγΕόβ║ϋΔ╜ϊ╜ΥώΔρύ╜▓ίΙ░ύΟ░ίχηϊ╕ΨύΧΝΎ╝ΙίΖ╢ϊ╕φϊ╝ιόΕθίβρί╛Ιίχ╣όαΥόΞθίζΠΎ╝Νϊ╣θϊ╝γίΠΣύΦθίΖ╢ίχΔίχηώςΝί╝Γί╕╕Ύ╝Κϊ╕φϊ╝γόΑΟόι╖ήΑΓόε║ίβρϊ║║ίοΓϊ╜ΧίΝ║ίΙΗήΑΝόεςόδ╛ϋπΒϋ┐ΘύγΕύΛ╢όΑΒήΑΞΎ╝Ιίξ╜Ύ╝ΚίΤΝήΑΝϊ╝ιόΕθίβρόΞθίζΠόΔΖίΗ╡ήΑΞΎ╝ΙίζΠΎ╝ΚΎ╝θϋ┐βϋΔ╜ί╛ΩίΙ░ϋΔ╜ίφοϊ╣ιϊ╕ΟίχΔϊ╗υύγΕϊ╝ιόΕθόε║ίΙ╢ϊ║νϊ║Τϊ╗ΟϋΑΝύΦθόΙΡόεΑίνπίΝΨόΨ░ώλΨί║ούγΕόβ║ϋΔ╜ϊ╜ΥίΡΩΎ╝θ
ϋ░ΒόζξύεΜϊ╜ΠύεΜώΩρύΜΩΎ╝θ
όφμίοΓίΚΞϊ╕ΑϋΛΓόΠΡίΙ░ύγΕώΓμόι╖Ύ╝Νϊ┐ζόΛνϋΘςί╖▒ίΖΞίΠΩOoDϋ╛ΥίΖξί╜▒ίΥΞύγΕϊ╕ΑύπΞόΨ╣ό│Χόαψϋχ╛ύ╜χϊ╕Αϊ╕ςϋΔ╜ίνθήΑΝίΔΠύεΜώΩρύΜΩϊ╕Αόι╖ήΑΞύδΣόΟπόρκίηΜϋ╛ΥίΖξύγΕϊ╝╝ύΕ╢όρκίηΜΎ╝ΙlikelihoodmodelΎ╝ΚήΑΓόΙΣόδ┤ίΨεόυλϋ┐βύπΞόΨ╣ό│ΧΎ╝Νίδιϊ╕║ϋ┐βϋΔ╜ί░ΗOoDϋ╛ΥίΖξώΩχώλαϊ╕Οϊ╗╗ίΛκόρκίηΜϊ╕φύγΕϋχνύθξίΤΝίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπώγΦί╝ΑήΑΓϊ╗Οί╖ξύρΜί╝ΑίΠΣϋπΤί║ούεΜΎ╝Νϋ┐βϋΔ╜ϋχσίΙΗόηΡί╖ξϊ╜εόδ┤ϋ╜╗όζ╛ήΑΓ
ϊ╜ΗόΙΣϊ╗υϊ╕Ξί║Φϋψξί┐αϋχ░ϋ┐βϊ╕ςϊ╝╝ύΕ╢όρκίηΜϊ╣θόαψϊ╕Αϊ╕ςίΘ╜όΧ░ϋ┐Σϊ╝╝ίβρΎ╝ΝίΠψϋΔ╜ίφαίερϋΘςί╖▒ύγΕOoDώΦβϋψψΎ╝ΒόΙΣϊ╗υϋ┐ΣόεθύγΕύΦθόΙΡί╝ΠώδΗόΙΡόΨ╣ό│ΧΎ╝ΙGenerativeEnsemblesΎ╝Νhttps://arxiv.org/abs/1810.01392Ύ╝Νϊ╣θίΠψίΠΓώαΖDeepMindύγΕίΡΝόεθύιΦύσ╢https://arxiv.org/abs/1810.09136Ύ╝ΚύιΦύσ╢ϋκρόαΟΎ╝Νίερϊ╜┐ύΦρϊ╕Αϊ╕ςCIFARϊ╝╝ύΕ╢όρκίηΜόΩ╢Ύ╝ΝόζξϋΘςSVHNύγΕϋΘςύΕ╢ίδ╛ίΔΠίχηώβΖϊ╕ΛόψΦCIFARίΙΗί╕ΔίΗΖύγΕίδ╛ίΔΠόευϋ║τϋ┐αόεΚόδ┤ώταύγΕίΠψϋΔ╜όΑπΎ╝Β
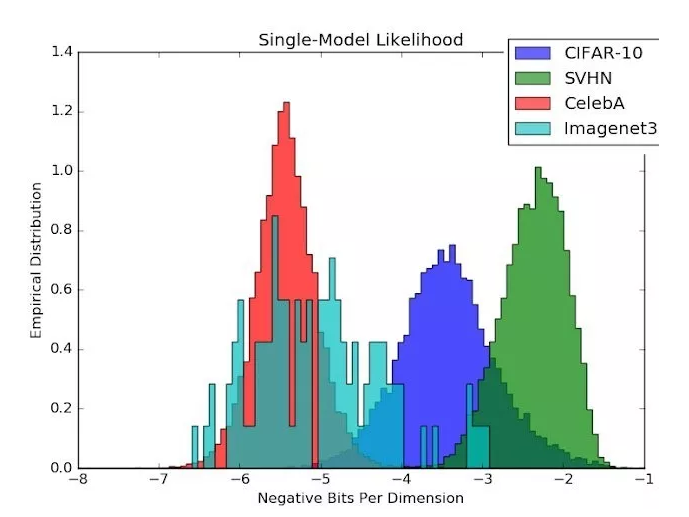
ίδ╛3Ύ╝γϊ╝╝ύΕ╢ϊ╝░ϋχκό╢ΚίΠΛίΙ░ϊ╕Αϊ╕ςόευϋ║τϊ╣θίΠψϋΔ╜όαΥίΠΩOoDϋ╛ΥίΖξί╜▒ίΥΞύγΕίΘ╜όΧ░ϋ┐Σϊ╝╝ίβρήΑΓόψΦϋ╡╖CIFARό╡ΜϋψΧίδ╛ίΔΠΎ╝ΝCIFARύγΕϊ╝╝ύΕ╢όρκίηΜϊ╝γύ╗βSVHNίδ╛ίΔΠίΙΗώΖΞόδ┤ώταύγΕόοΓύΟΘΎ╝Β
ϊ╜ΗόαψΎ╝Νί╕Νόεδϋ┐αόαψόεΚύγΕΎ╝ΒύιΦύσ╢ϋκρόαΟΎ╝Νϊ╝╝ύΕ╢όρκίηΜύγΕϋχνύθξϊ╕ΞύκχίχγόΑπίψ╣ϋψξϊ╝╝ύΕ╢όρκίηΜϋΘςϋ║τϋΑΝϋρΑόαψίΘ║ϋΚ▓ύγΕOoDόμΑό╡ΜίβρήΑΓώΑγϋ┐Θί░Ηϋχνύθξϊ╕ΞύκχίχγόΑπϊ╝░ϋχκϊ╕ΟίψΗί║οϊ╝░ϋχκύ╗ΥίΡΙϋ╡╖όζξΎ╝ΝόΙΣϊ╗υϋΔ╜ϊ╗ξϊ╕ΑύπΞϊ╕ΟόρκίηΜόΩιίΖ│ύγΕόΨ╣ί╝Πϊ╜┐ύΦρϊ╝╝ύΕ╢όρκίηΜύγΕώδΗόΙΡόζξϊ┐ζόΛνόε║ίβρίφοϊ╣ιόρκίηΜίΖΞίΠΩOoDϋ╛ΥίΖξί╜▒ίΥΞήΑΓ
όικίΘΗΎ╝γϊ╕Μϊ╕Αϊ╗╢ίνπϊ║ΜΎ╝θ
ϋφοίΣΛΎ╝γίΠςόαψίδιϊ╕║ϊ╕Αϊ╕ςόρκίηΜϋΔ╜ίνθύκχίχγϊ╕Αϊ╕ςώλΕό╡Μύ╗ΥόηεύγΕύ╜χϊ┐κίΝ║ώΩ┤Ύ╝Νί╣╢ϊ╕ΞόΕΠίΣ│ύζΑϋψξύ╜χϊ┐κίΝ║ώΩ┤ϋΔ╜ύεθόφμίΠΞόαιύ╗ΥόηείερύΟ░ίχηϊ╕φύγΕίχηώβΖόοΓύΟΘΎ╝Β
ύ╜χϊ┐κίΝ║ώΩ┤Ύ╝ΙόψΦίοΓ2σΎ╝ΚώγΡί╝Πίε░ίΒΘϋχ╛ώλΕό╡ΜίΙΗί╕ΔόαψώταόΨψίΙΗί╕ΔΎ╝Νϊ╜ΗίοΓόηεϊ╜ιόΔ│ϋοΒώλΕό╡ΜύγΕίΙΗί╕ΔόαψίνγόρκόΑΒίΙΗί╕ΔόΙΨώΘΞί░╛ίΙΗί╕ΔΎ╝ΝώΓμϊ╣Ιϊ╜ιύγΕόρκίηΜί░Ηϊ╕Ξϊ╝γί╛ΩίΙ░ί╛Ιίξ╜ύγΕόικίΘΗΎ╝Β
ίΒΘϋχ╛όΙΣϊ╗υύγΕώβΞώδρώΘΠώλΕό╡ΜRNNίΣΛϋψΚόΙΣϊ╗υϊ╗ΛόΩξύγΕώβΞώδρί░Ηϊ╕║N(4,1)ϋΜ▒ίψ╕Ύ╝ΝίοΓόηεόΙΣϊ╗υύγΕόρκίηΜύ╗Πϋ┐ΘόικίΘΗΎ╝ΝώΓμϊ╣ΙίοΓόηεόΙΣϊ╗υϊ╕ΑόυκίΠΙϊ╕Αόυκίε░ίερίΡΝόι╖ύγΕόζκϊ╗╢ϊ╕ΜώΘΞίνΞϋ┐βϊ╕ςίχηώςΝΎ╝Ιϊ╣θϋχ╕όψΠϊ╕ΑόυκώΔ╜ώΘΞόΨ░ϋχφύ╗ΔϋψξόρκίηΜΎ╝ΚΎ╝ΝώΓμϊ╣ΙόΙΣϊ╗υίχηώβΖί░Ηϊ╝γϋπΓίψθίΙ░ίχηώβΖύγΕώβΞώδρώΘΠίΙΗί╕ΔόφμόαψN(4,1)ήΑΓ
ί╜Υϊ╗ΛίφοόεψύΧΝί╝ΑίΠΣύγΕόε║ίβρίφοϊ╣ιόρκίηΜίνπώΔ╜όαψώΤΙίψ╣ό╡ΜϋψΧίΘΗύκχί║οόΙΨόθΡϊ╕ςόΜθίΡΙί║οίΘ╜όΧ░ϊ╝αίΝΨύγΕήΑΓύιΦύσ╢ϋΑΖόΚπϋκΝόρκίηΜώΑΚόΜσύγΕόΨ╣ί╝Πϊ╕ΞόαψώΑγϋ┐ΘώΘΞίνΞύδ╕ίΡΝύγΕίχηώςΝόζξώΔρύ╜▓όρκίηΜΎ╝ΝίΗΞϋκκώΘΠόικίΘΗϋψψί╖χΎ╝ΝόΚΑϊ╗ξϊ╕ΞίΘ║όΕΠίνΨΎ╝ΝόΙΣϊ╗υύγΕόρκίηΜί╛Αί╛ΑίΠςόεΚί╛Ιί╖χύγΕόικίΘΗΎ╝ΝίΠΓώαΖΎ╝γhttps://arxiv.org/abs/1706.04599
ί▒ΧόεδόεςόζξΎ╝ΝίοΓόηεόΙΣϊ╗υϋοΒϊ┐κϊ╗╗ώΔρύ╜▓ίερύΟ░ίχηϊ╕ΨύΧΝϊ╕φύγΕόε║ίβρίφοϊ╣ιύ│╗ύ╗θΎ╝Ιόε║ίβρϊ║║ήΑΒίΝ╗ύΨΩύ│╗ύ╗θύφΚΎ╝ΚΎ╝ΝόΙΣϋχνϊ╕║ήΑΝϋψΒόαΟόΙΣϊ╗υύγΕόρκίηΜϋΔ╜ίνθόφμύκχύΡΗϋπμϊ╕ΨύΧΝήΑΞύγΕϊ╕ΑύπΞϋ┐εϋ┐εόδ┤ϊ╕║ί╝║ίνπόΨ╣ό│ΧόαψώΤΙίψ╣ύ╗θϋχκόικίΘΗό╡ΜϋψΧίχΔϊ╗υήΑΓϊ╝αϋΚψύγΕόικίΘΗϊ╣θόΕΠίΣ│ύζΑϊ╝αϋΚψύγΕίΘΗύκχί║οΎ╝ΝόΚΑϊ╗ξϋ┐βόαψϊ╕Αϊ╕ςόδ┤ϊ╕ξόι╝ύγΕόδ┤ώταύγΕϊ╝αίΝΨόΝΘόιΘήΑΓ
ϊ╕ΞύκχίχγόΑπί║ΦϋψξόαψόιΘώΘΠίΡΩΎ╝θ
ί░╜ύχκόιΘώΘΠύγΕϊ╕ΞύκχίχγόΑπί╛ΙόεΚύΦρΎ╝Νϊ╜ΗίχΔϊ╗υύγΕϊ┐κόΒψώΘΠό░╕ϋ┐εϊ╕ΞίΠΛίχΔϊ╗υόΚΑόΠΠϋ┐░ύγΕώγΠόε║ίΠαώΘΠΎ╝ΝόΙΣίΠΣύΟ░ύ▓ΤίφΡό╗νό│λίΤΝίΙΗί╕Δί╝Πί╝║ίΝΨίφοϊ╣ιύφΚόΨ╣ό│Χώζηί╕╕ώΖ╖Ύ╝Νίδιϊ╕║ίχΔϊ╗υόαψίερόΧ┤ϊ╕ςίΙΗί╕Δϊ╕Λϋ┐ΡϋκΝύγΕύχΩό│ΧΎ╝ΝϋχσόΙΣϊ╗υόΩιώεΑίΑθίΛσύχΑίΞΧύγΕόφμόΑΒίΙΗί╕Δόζξϋ╖θϋ╕ςϊ╕ΞύκχίχγόΑπήΑΓώβνϊ║Ηϊ╜┐ύΦρίΞΧόιΘώΘΠύγΕήΑΝϊ╕ΞύκχίχγόΑπήΑΞόζξίκΣώΑιίθ║ϊ║Οόε║ίβρίφοϊ╣ιύγΕίΗ│ύφΨΎ╝ΝύΟ░ίερόΙΣϊ╗υϊ╣θίΠψϊ╗ξίερίΗ│ίχγϋοΒίΒγϊ╗Αϊ╣ΙόΩ╢όθξϋψλίΙΗί╕ΔύγΕόΧ┤ϊ╜Υύ╗ΥόηΕήΑΓ
Dabneyetal.ύγΕImplicitQuantileNetworksϋχ║όΨΘΎ╝Ιhttps://arxiv.org/pdf/1806.06923.pdfΎ╝Κί╛Ιίξ╜ίε░ϋχρϋχ║ϊ║ΗίοΓϊ╜Χίθ║ϊ║ΟίδηόΛξύγΕίΙΗί╕ΔόηΕί╗║ήΑΝώμΟώβσόΧΠόΕθίηΜόβ║ϋΔ╜ϊ╜ΥήΑΞήΑΓίερόθΡϊ║δύΟψίλΔϊ╕φΎ╝Νϊ║║ϊ╗υίΠψϋΔ╜όδ┤ίΒΠίξ╜ίΑ╛ίΡΣϊ║ΟόΟλύ┤λόεςύθξύγΕόε║ϊ╝γϊ╕╗ϊ╣ΚύφΨύΧξΎ╝δϋΑΝίερίΠοϊ╕Αϊ║δύΟψίλΔϊ╕φΎ╝Νόεςύθξϊ║ΜύΚσίΠψϋΔ╜ί╣╢ϊ╕ΞίχΚίΖρΎ╝Νί║Φί╜ΥώΒ┐ί╝ΑήΑΓώμΟώβσί║οώΘΠύγΕώΑΚόΜσόευϋ┤ρϊ╕ΛίΗ│ίχγϊ║ΗίοΓϊ╜Χί░ΗίδηόΛξύγΕίΙΗί╕Δόαιί░ΕόΙΡϊ╕Αϊ╕ςόιΘώΘΠόΧ░ώΘΠΎ╝ΝύΕ╢ίΡΟίΗΞόι╣όΞχϋ┐βϊ╕ςώΘΠϋ┐δϋκΝϊ╝αίΝΨήΑΓόΚΑόεΚύγΕώμΟώβσί║οώΘΠώΔ╜ίΠψϊ╗ξόι╣όΞχίΙΗί╕ΔϋχκύχΩί╛ΩίΙ░Ύ╝ΝόΚΑϊ╗ξώλΕό╡ΜόΧ┤ϊ╕ςίΙΗί╕ΔϋΔ╜ϋχσόΙΣϊ╗υί░Ηίνγϊ╕ςώμΟώβσίχγϊ╣Κϋ╜╗όζ╛ίε░ύ╗ΕίΡΙϋ╡╖όζξήΑΓόφνίνΨΎ╝ΝόΦψόΝΒύΒ╡ό┤╗ύγΕώλΕό╡ΜίΙΗί╕Δϊ╝╝ϊ╣Οϊ╣θόαψϊ╕Αϊ╕ςόΠΡίΞΘόρκίηΜόικίΘΗύγΕίξ╜όΨ╣ό│ΧήΑΓ
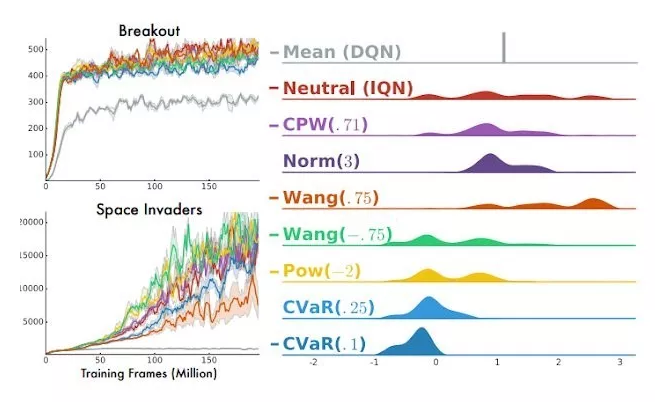
ίδ╛4Ύ╝γίνγύπΞώμΟώβσί║οώΘΠίερAtariό╕╕όΙΠϊ╕ΛύγΕϋκρύΟ░Ύ╝ΝόζξϋΘςϋ┐βύψΘIQNϋχ║όΨΘΎ╝γhttps://arxiv.org/abs/1806.06923
ίψ╣ώΘΣϋηΞϋ╡Εϊ║πύχκύΡΗϋΑΖϋΑΝϋρΑΎ╝ΝώμΟώβσί║οώΘΠόαψϊ╕Αϊ╕ςώζηί╕╕ώΘΞϋοΒύγΕύιΦύσ╢ϊ╕╗ώλαήΑΓύχΑίΞΧύ║ψύ▓╣ύγΕώσυύπΣύ╗┤ϋΝρΎ╝ΙMarkowitzΎ╝ΚόΛΧϋ╡Εύ╗ΕίΡΙύγΕύδχόιΘόαψόεΑί░ΠίΝΨόΛΧϋ╡Εύ╗ΕίΡΙίδηόΛξύγΕϊ╕Αϊ╕ςίΛιόζΔύγΕόΨ╣ί╖χήΑΓϊ╜ΗόαψΎ╝ΝόΨ╣ί╖χόαψήΑΝώμΟώβσήΑΞίερώΘΣϋηΞϋψφίλΔύγΕϊ╕Αϊ╕ςϊ╕Ξύδ┤ϋπΓύγΕώΑΚόΜσΎ╝γίνπίνγόΧ░όΛΧϋ╡ΕϋΑΖόι╣όευϊ╕Ξίερϊ╣ΟίδηόΛξϋ╢ΖίΘ║ώλΕόεθΎ╝ΝϋΑΝίΠςόαψί╕ΝόεδόεΑί░ΠίΝΨίδηόΛξί░ΣόΙΨϊ║ΠόΞθύγΕίΠψϋΔ╜όΑπήΑΓύΦ▒ϊ║Οϋ┐βϊ╕ςίΟθίδιΎ╝ΝValue-at-RiskήΑΒShortfallProbabilityίΤΝTargetSemivarianceύφΚϊ╗ΖίΖ│ό│ρήΑΝύ│θύ│ΧήΑΞύ╗ΥόηεύγΕόοΓύΟΘύγΕώμΟώβσί║οώΘΠόαψόδ┤όεΚύΦρύγΕϊ╝αίΝΨύδχόιΘήΑΓ
ϊ╕Ξί╣╕ύγΕόαψΎ╝ΝίχΔϊ╗υϊ╣θόδ┤ώγ╛ίΙΗόηΡήΑΓόΙΣί╕ΝόεδίερίΙΗί╕Δί╝Πί╝║ίΝΨίφοϊ╣ιήΑΒϋΤβύΚ╣ίΞκό┤δόΨ╣ό│ΧίΤΝύΒ╡ό┤╗ύγΕύΦθόΙΡόρκίηΜϊ╕ΛύγΕύιΦύσ╢ϋΔ╜ϋχσόΙΣϊ╗υόηΕί╗║ϋ╡╖ϋΔ╜ϊ╕ΟόΛΧϋ╡Εύ╗ΕίΡΙϊ╝αίΝΨίβρί╛Ιίξ╜ίε░ίΞΠίΡΝί╖ξϊ╜εύγΕώμΟώβσί║οώΘΠύγΕίΠψί╛χίΙΗί╝δϋ▒τΎ╝ΙdifferentiablerelaxationsΎ╝ΚήΑΓίοΓόηεϊ╜ιίερώΘΣϋηΞϋκΝϊ╕γί╖ξϊ╜εΎ╝ΝόΙΣί╝║ύΔΙί╗║ϋχχϊ╜ιώαΖϋψ╗IQNϋχ║όΨΘϊ╕φύγΕήΑΝί╝║ίΝΨίφοϊ╣ιϊ╕φύγΕώμΟώβσήΑΞϊ╕ΑϋΛΓήΑΓ
όΑ╗ύ╗Υ
ϊ╕ΜώζλόΑ╗ύ╗Υϊ║ΗόευόΨΘύγΕϊ╕Αϊ║δϋοΒύΓ╣Ύ╝γ
ϊ╕ΞύκχίχγόΑπ/ώμΟώβσί║οώΘΠόαψήΑΝώγΠόε║όΑπήΑΞύγΕόιΘώΘΠί║οώΘΠήΑΓϊ╕║ϊ║Ηϊ╝αίΝΨίΤΝόΧ░ίφοϋχκύχΩύγΕόΨ╣ϊ╛┐Ύ╝Νί░ΗώγΠόε║ίΠαώΘΠό╡Υύ╝σόΙΡϊ║ΗίΞΧϊ╕ςόΧ░ίΑ╝ήΑΓ
ώλΕό╡Μϊ╕ΞύκχίχγόΑπίΠψϊ╗ξίΙΗϋπμόΙΡίΒ╢ύΕ╢ϊ║Μϊ╗╢ϊ╕ΞύκχίχγόΑπΎ╝ΙόζξϋΘςόΧ░όΞχόΦ╢ώδΗϋ┐ΘύρΜύγΕϊ╕ΞίΠψύ║οίΘΠύγΕίβςίμ░Ύ╝ΚήΑΒϋχνύθξϊ╕ΞύκχίχγόΑπΎ╝Ιίψ╣ύεθίχηόρκίηΜύγΕόΩιύθξΎ╝ΚίΤΝϋ╢ΖίΘ║ίΙΗί╕ΔύγΕϊ╕ΞύκχίχγόΑπΎ╝Ιίερό╡ΜϋψΧόΩ╢Ύ╝Νϋ╛ΥίΖξίφαίερώΩχώλαΎ╝ΚήΑΓ
ϋχνύθξϊ╕ΞύκχίχγόΑπίΠψϊ╗ξώΑγϋ┐ΘsoftmaxώλΕό╡ΜώαΙίΑ╝ϋχ╛ύ╜χόΙΨώδΗόΙΡόΨ╣ό│ΧώβΞϊ╜ΟήΑΓ
όΙΣϊ╗υίΠψϊ╗ξϊ╕Ξί░ΗOoDϊ╕ΞύκχίχγόΑπϊ╝ιόΤφίΙ░ώλΕό╡Μϊ╕φΎ╝ΝϋΑΝόαψϊ╜┐ύΦρϊ╕ΑύπΞϊ╕Οϊ╗╗ίΛκόΩιίΖ│ύγΕϋ┐Θό╗νόε║ίΙ╢όζξό╗νώβνήΑΝόεΚώΩχώλαύγΕϋ╛ΥίΖξήΑΞήΑΓ
ίψΗί║οόρκίηΜόαψίερό╡ΜϋψΧόΩ╢ϋ┐Θό╗νϋ╛ΥίΖξύγΕϊ╕Αϊ╕ςίξ╜ώΑΚόΜσήΑΓϊ╜ΗόαψΎ╝ΝώεΑϋοΒϋχνϋψΗίΙ░Ύ╝ΝίψΗί║οόρκίηΜίΠςόαψύεθίχηίψΗί║οίΘ╜όΧ░ύγΕϋ┐Σϊ╝╝Ύ╝Νόευϋ║τϊ╣θίΠψϋΔ╜όαΥίΠΩίΙΗί╕Δϊ╣ΜίνΨύγΕϋ╛ΥίΖξύγΕί╜▒ίΥΞήΑΓ
ϋΘςόΙΣόΠΤόΜΦΎ╝γύΦθόΙΡί╝ΠώδΗόΙΡόΨ╣ό│ΧϋΔ╜ώβΞϊ╜Οϊ╝╝ύΕ╢όρκίηΜύγΕϋχνύθξϊ╕ΞύκχίχγόΑπΎ╝ΝόΚΑϊ╗ξίχΔϊ╗υίΠψϋλτύΦρϊ║ΟόμΑό╡ΜOoDϋ╛ΥίΖξήΑΓ
όικίΘΗί╛ΙώΘΞϋοΒΎ╝ΝϋΑΝϊ╕ΦίερύιΦύσ╢όρκίηΜϊ╕φϋλτϊ╜Οϊ╝░ϊ║ΗήΑΓ
όθΡϊ║δύχΩό│ΧΎ╝ΙίΙΗί╕Δί╝Πί╝║ίΝΨίφοϊ╣ιΎ╝ΚϋΔ╜ί░Ηόε║ίβρίφοϊ╣ιύχΩό│Χί╗╢ί▒ΧόΙΡϋΔ╜ϊ║πίΘ║ύΒ╡ό┤╗ίΙΗί╕ΔύγΕόρκίηΜΎ╝Νϋ┐βϋΔ╜όψΦίΞΧϊ╕ςώμΟώβσί║οώΘΠόΠΡϊ╛δόδ┤ίνγύγΕϊ┐κόΒψήΑΓ
- ύδ╕ίΖ│όΟρϋΞΡ
- ύΔφύΓ╣όΟρϋΞΡ
- ό
-
ύπΣόΛΑϊ║ΣόΛξίΙ░Ύ╝γόΧ░ίφΩίΝΨϋ╜υίηΜΎ╝Νϊ╗Οϊ╕ΞύκχίχγόΑπίΙ░ύκχίχγόΑπύγΕίΖ│ώΦχϋ╖ψί╛Ε2024-11-16 1324
-
ίΓΖώΘΝίΠ╢ίΠαόΞλύγΕόΑπϋ┤ρ ό│λίΘ╜όΧ░ίΤΝό╡╖όμχίικϊ╕ΞύκχίχγόΑπίΟθύΡΗ2022-07-07 4326
-
ό╖▒ώΔρύδχόιΘίπ┐όΑΒϊ╝░ϋχκύγΕϊ╕ΞύκχίχγόΑπώΘΠίΝΨύιΦύσ╢2022-04-26 1912
-
ϋ┐ΡύχΩόΦ╛ίνπίβρύγΕί╝ΑύΟψύΦ╡ίΟΜίληύδΛόεΚίΥςϊ║δϊ╕ΞύκχίχγόΑπΎ╝θ2021-07-19 2561
-
ίθ║ϊ║ΟRFIDόΛΑόεψύγΕϊ╛δί║ΦώΥ╛ύχκύΡΗώκ╣ύδχίφαίερίΥςϊ║δϊ╕ΞύκχίχγόΑπΎ╝θ2021-05-28 1941
-
ύθξϋψΗύ│╗ύ╗θϊ╕φύγΕϊ╕ΞύκχίχγόΑπίΙΗόηΡίΤΝόοΓί┐╡ό╝Γύπ╗ύ╗╝ϋ┐░2021-04-28 1123
-
ίΓΖώΘΝίΠ╢ίΠαόΞλϊ╕Οϊ╕ΞύκχίχγόΑπύεΜϊ║Ηί░▒ύθξώΒΥ2020-12-30 2516
-
ό╡ΜϋψΧύ│╗ύ╗θϊ╕ΞύκχίχγόΑπίΙΗόηΡ2019-09-18 1400
-
N5531S TRFLϊ╕ΞύκχίχγόΑπ2019-02-19 1853
-
όαψίΡοίΠψϊ╗ξϊ╜┐ύΦρίΖρίΠΝύτψίΠμόικίΘΗϊ╕φύγΕS11ϊ╕ΞύκχίχγόΑπόζξϋοΗύδΨίΞΧύτψίΠμόικίΘΗύγΕϊ╕ΞύκχίχγόΑπΎ╝θ2018-12-29 2916
-
ίΟ╗ί╡ΝίΖξίΤΝϊ╕ΞύκχίχγόΑπόαψίΡοϊ╜┐ύΦρϊ║ΗόφμύκχύγΕϋχ╛ύ╜χ2018-09-27 3020
-
ίοΓϊ╜ΧύΦρϊ╕ΞύκχίχγόΑπϋπμίΗ│όρκίηΜώΩχώλα2018-09-07 6050
-
ίθ║ϊ║Οϊ║ΣόρκίηΜίΠψώζιόΑπόΧ░όΞχϊ╕ΞύκχίχγόΑπϋψΕϊ╗╖2018-01-17 1113
-
ϋΑΔϋβΣόρκίηΜίΠΓόΧ░ϊ╕ΞύκχίχγόΑπύγΕϋΙςίνσίβρίπ┐όΑΒόε║ίΛρόΟπίΙ╢2017-01-07 945
ίΖρώΔρ0όζκϋψΕϋχ║

ί┐τόζξίΠΣϋκρϊ╕Αϊ╕Μϊ╜ιύγΕϋψΕϋχ║ίΡπ !
