

ICLR 2019论文解读:深度学习应用于复杂系统控制
电子说
描述
引言
20世纪,控制论、系统论、信息论,对工业产生了颠覆性的影响。继2011年深度学习在物体检测上超越传统方法以来,深度学习在识别传感(包含语音识别、物体识别),自然语言处理领域里产生了颠覆性的影响。最近在信息论里,深度学习也产生了重要影响。使用深度学习可以对不同形式编码的信息进行自动解码。如今,深度学习再次影响控制论,传统控制论往往是模型驱动算法,需要设计复杂的模型和控制方案,而以数据驱动为核心的深度学习用作控制领域的春天即将到来,这将推动数十万亿的工业、服务业的进一步升级。通过深度学习控制,可以让机器人,能源,交通等行业效率显著提升。例如,使用深度学习进行智能楼宇控制,可以节约大楼20%的能耗,传统的控制需要多名专家2年的时间建立一个楼宇模型,深度学习可以利用楼宇历史数据在一天内得到超越传统方法的模型;在机器人控制和强化学习领域里,相比传统控制方法,本文提出的方法可以节约80%以上的运算时间并且提升10%以上的控制准确度。
深度学习控制行业刚刚兴起,还有很多的问题没有解决,还需要很多的理论突破。近期,华盛顿大学研究组在ICLR2019发表了一篇深度学习控制的最新成果[1],这是第一次将深度学习与凸优化理论结合应用到最优控制理论中,在从理论层面保证模型达到全局最优解的同时,大幅提升了复杂系统控制的效率和准确度。该论文在公开评审中获得了6/7/8的评分,在所有1449submissions中得分位列前90位(top6%)。在这里,论文的两位作者将亲自为我们解读其中的核心思想。

论文地址:https://openreview.net/forum?id=H1MW72AcK7¬eId=HylsgDCzeV
机器学习/强化学习与控制
自动控制与机器学习作为两个拥有深厚历史的学科,已经发展了数十年,并建立了各自较为完善的学科体系。在自动控制中的重要一环,是首先根据历史数据对控制系统进行输入-输出的端到端建模。目前广泛使用的系统辨识(systemidentification)方法主要有两种:一是使用线性/或分段线性模型来预测系统的(状态,控制变量)->(状态)关系。这样做的好处是后续的优化问题是线性优化问题(linearprogramming)并可结合控制论中的线性二次型调节器LQR(LinearQuadraticRegulator)等控制模型,易于求解并实现闭环最优控制。同时控制论较为注重系统的理论性质研究,如系统的李雅普诺夫稳定性,以及基于卡尔曼滤波等的最优状态估计等。但是线性模型很难准确地描述复杂系统的动态,且建模过程需要大量专家知识和调试。因为存在对物理对象的建模,这类方法也被称为基于模型的控制和强化学习model-basedcontrol/reinforcementlearning。第二种方法是使用一些较为复杂的机器学习模型,比如深度神经网络,支持向量机(SVM)等对物理系统进行建模。相比线性模型,这些模型能够更为准确地捕捉系统输入-输出的动态关系。而在一般的(深度)强化学习算法中,通常研究者也会训练一个端到端的算法,由状态直接输出控制。由于不存在物理建模过程,这类方法也一般被称为model-freecontrol/reinforcementlearning。但是这些复杂模型给后续的优化控制问题求解带来了困难。我们都知道深度神经网络,一般来说输出对于输入都是非凸的,包含很多局部最优点,所以在优化过程中很容易陷入局部最优情况。在对稳定性要求很高的系统控制情境下(比如电力系统控制,航天系统以及工业控制),这种多个局部最优解并且没有全局最优收敛性保证的情况是我们非常不愿看到的,也一定程度限制了目前深度模型在这些行业中的应用。同时,在当前的深度强化学习研究中,尽管在多个应用和领域中已经取得行业领先的控制和优化效果,但对模型的理论性质尚缺乏研究,同时需要大量标注的状态和决策数据以泛化模型的表征能力和应用场景[2](ICML2018tutorialandAnnualReviewofControl,RoboticsandAutonomousSystems,Recht,Berkeley)。
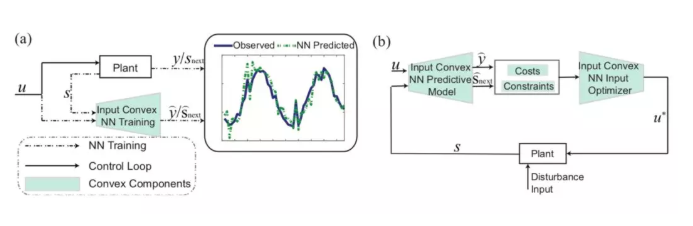
图一:本文提出的输入凸的神经网络的(a)动态系统学习与(b)闭环控制过程。
在「Optimalcontrolvianeuralnetwork:aconvexapproach」一文中,作者提出了一种新的数据驱动的控制方法。该篇文章作出了结合model-freecontrol与model-basedcontrol的一步重要尝试。在训练过程中,我们用一个输入凸(inputconvex)的神经网络来表达系统表达复杂的动态特性;在控制与优化过程中,我们就可以将训练好的神经网络作为动态系统的模型,求解凸优化问题从而得到有最优保证的控制输入。算法思路详见图一
基于输入凸神经网络的最优控制框架
为了解决现有模型的不足,本文作者提出了一种新的系统辨识方法:基于输入凸的神经网络的系统辨识。建立在之前InputConvexNeuralNetwork(ICNN)[3](ICML2017,Amosetal.,2017,CMU)的基础上,本文作者提出一种新型的InputConvexRecurrentNeuralNetwork(ICRNN)用于具有时间关联的动态系统建模。不同于通用的神经网络结构,输入凸的神经网络要求所有隐藏层之间的权重矩阵非负,同时加入了对输入向量的负映射以及输入到隐藏层的直连层增加ICNN和ICRNN的表达能力。
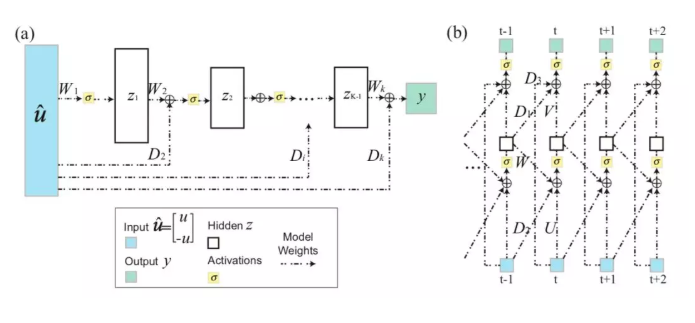
作者在文章中理论证明了,输入凸神经网络ICNN和ICRNN可以表示所有凸函数(Theorem1),并且其表达的效率比分段线性函数高指数级(Theorem2)。两条性质保证所提出的网络架构能够很好地应用于优化与控制问题中用于对象建模与求解。
在使用输入凸神经网络进行系统建模后,作者将系统模型嵌入到模型预测控制(ModelPredictiveControl)框架中,用于求解最优的系统控制值。因为使用了输入凸神经网络,这里的MPC问题是一个凸优化问题,使用经典的梯度下降方法就可以保证我们找到最优的控制策略。如果系统的状态或者控制输入包含约束条件(constraints),我们也可以使用投影梯度下降(ProjectedGradientMethod)或者内点法进行求解。这样,使用ICNN对瞬态特性建模或使用ICRNN对时序过程建模并用于控制对输入优化求解,我们不仅能够满足控制论中对于最优解的性质的保证,同时也可以充分发挥深度模型的表征能力,即可作为一种适用于各领域的建模与控制方法。
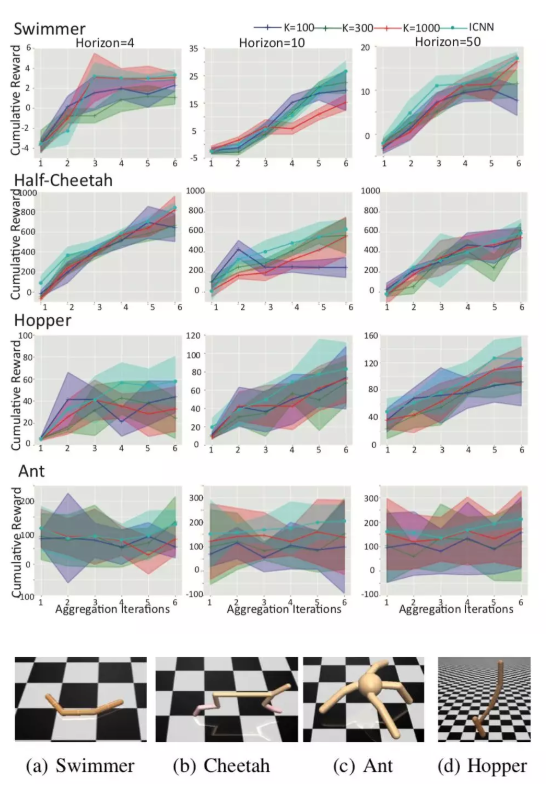
图3.基于ICNN的MuJoColocomotiontasks的控制结果。K=100,300,1000对应[4]中基于模型的强化学习的算法设定,我们测试了在模型预测控制中,不同未来预测区间长度下各任务的回报。
应用一:机器人运动控制
作者首先将提出的深度学习控制框架应用于机器人的控制,使用的是OpenAI中的MuJuCo机器人仿真平台的四个前向运动任务。我们首先使用随机采样的机器人动作和状态的数据作为初始样本训练一个ICNN网络,并结合DAGGER(AISTATS,Rossetal,2011,CMU)以在训练和控制过程中更好地探索和泛化。本文提出的方法相比目前的强化学习方法更加高效、准确。同目前最好的基于模型的强化学习算法(model-basedRL)[4](2018ICRA,Nagabandietal.,2018,Berkeley)相比,本文提出的方法仅仅使用20%的运算时间就可以达到比之前方法高10%的控制效果(图3)。与无模型的深度强化学习算法如TRPO,DDPG往往超过10^6的样本数量相比,我们的控制方法可以从10^4量级的样本中学习到极为准确的动态模型并用于控制。同时我们还可以将该方法得到控制结果作为初始控制策略,然后随着机器人在环境中收集更多的样本,与无模型的强化学习方法(model-freeRL)结合,在动态系统环境下实现更好的控制效果。
应用二:大楼的能源管理
同时,本文作者也将提出的深度学习控制框架应用于智能楼宇的供热通风与空气调节系统(HVAC)控制。我们通过建筑能耗仿真软件EnergyPlus得到一栋大楼的分时能耗数据及各个分区的传感器数据,并使用ICRNN建立楼宇输入特征(如室内温度,人流量,空调设定温度等)到输出特征(如能耗)的动态模型。在控制过程中,文章提出的模型可以非常方便地加入一系列约束,如温度可调节范围等。我们通过设计大楼在一定时间段内的温度设置值,并满足相应约束的前提下,来最优化楼宇的能耗。相比于传统的线性模型以及控制方法,使用ICRNN的控制方法在保证房间温度维持在[19,24]摄氏度区间内的情况下,帮助大楼节约多于20%的能耗。在更大的温度波动区间内([16,27]摄氏度),可以帮助建筑节约近40%能耗(图4左)。同时相比于传统神经网络模型直接用于系统建模,基于ICRNN的控制方法由于有控制求解的最优性保证,得到的温度设定值更加的稳定(图4右中红线为ICRNN控制温度设置,绿线为普通神经网络控制温度设置)。

目前,华盛顿大学的PaulAllenCenter电子工程与计算机大楼正在安装相应的传感器,并计划将该控制方案用于该建筑HAVC系统的实时控制。
随着5G时代的到来与物联网技术的进一步发展,越来越多的物理系统中(电力,交通,航天,工业控制等)将会有更多的智能传感器与数据流,本文提出的基于深度学习的控制方法也将会有更广阔的应用空间。
参考资料:
[1]ChenYize*,YuanyuanShi*,andBaosenZhang."OptimalControlViaNeuralNetworks:AConvexApproach."ToAppearinInternationalConferenceonLearningRepresentations(ICLR),2019
[2]Recht,Benjamin."Atourofreinforcementlearning:Theviewfromcontinuouscontrol."AnnualReviewofControl,Robotics,andAutonomousSystems(2018).
[3]Amos,Brandon,LeiXu,andJ.ZicoKolter."Inputconvexneuralnetworks."InternationalConferenceonMachineLearning(ICML),2017
[4]Nagabandi,Anusha,etal."Neuralnetworkdynamicsformodel-baseddeepreinforcementlearningwithmodel-freefine-tuning."2018IEEEInternationalConferenceonRoboticsandAutomation(ICRA).IEEE,2018.
[5]Ross,Stéphane,GeoffreyGordon,andDrewBagnell."Areductionofimitationlearningandstructuredpredictiontono-regretonlinelearning."Proceedingsofthefourteenthinternationalconferenceonartificialintelligenceandstatistics.2011.
本文来源:机器之心
- 相关推荐
- 热点推荐
- 深度学习
-
RDMA设计7:系统控制模块设计2025-11-27 1515
-
毕业论文_无线表决系统控制端设计2012-08-16 2330
-
如何实现多点位、复杂功能的PLC系统控制目标?2019-07-30 4766
-
基于深度学习和3D图像处理的精密加工件外观缺陷检测系统2022-03-08 28329
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2201
-
系统控制(SysCtl)2016-01-13 958
-
系统控制和中断2016-04-29 947
-
ICLR 2019在官网公布了最佳论文奖!2019-05-07 5224
-
ICLR 2019最佳论文日前揭晓 微软与麻省等获最佳论文奖项2019-05-11 3105
-
Chip Huyen总结ICLR 2019年的8大趋势 RNN正在失去研究的光芒2019-05-19 3967
-
机器人控制研究获进展 能应用于真实的复杂移动机械臂控制2020-03-17 1015
-
自监督学习与Transformer相关论文2020-11-02 3534
-
基于评分矩阵与评论文本的深度学习模型2021-06-24 1075
-
深度学习顶级学术会议ICLR 2023录用结果已经公布!2023-02-07 3289
-
西井科技携手同济大学 三篇AI研究成果入选顶会ICLR 20262026-02-12 10983
全部0条评论

快来发表一下你的评论吧 !
