

Facebook 2018 AI研究全回顾
电子说
描述
在过去的一年,Facebook经历了很多波折和困难,但是在研究方面依旧涌现出了很多高质量的工作。近日,Facebook发文总结了去年在长期研究项目、高性能工具开发和平台开发以及AI的实际应用等各个方面的工作。
随着研究和工程实践的深入,实现了更强大的智能系统、更优秀的开源工具、更稳定高效的开源平台,诸多的研究论文和模型代码为深度学习研究做出了众多贡献。同时,还将AI应用到了医学和社会生活等领域,让技术真正造福人类。那么,就让我们一起看下这些工作都有哪些吧!
基于半监督和无监督学习的先进AI技术
实现人类水平的人工智能是每个从业者和研究人员最终的目标。在过去的一年,Facebook的研究人员利用更少的数据实现了更复杂的功能,让人工智能的目标又近了一步。目前大多数机器学习都基于大量标记数据通过监督学习的方式来实现特定的任务,但耗时的数据标记工作极大地限制了技术的发展。所以如何充分释放半监督和无监督学习的潜力,减少智能系统对于数据量的需求至关重要。在多语言理解和翻译系统中,研究人员提出一种新的方法,基于无监督数据实现自然机器翻译模型自动训练迁移,并达到了与监督数据相比拟的效果。通过减少对于大规模标记数据的依赖,这一系统打开了向更多语言迁移的技术大门,甚至可以用于像乌尔都语一样标记数据十分有限的语言。
多种语言的二维词向量嵌入空间可以通过简单的变换实现匹配。
此外,对于数据集资源有限的语言来说,需要用多种技术手段来实现。使用多语言模型融合同一语系多种方言间的相似性。通过多种技术的综合,研究人员在自动翻译系统中成功的新增了24种语言。同时在与纽约大学的合作中,在MutilNLI数据集中新增了14中语言,将有效助力自然语言理解的研究进程。同时,还发布了跨语言推理数据集XNLI,其中包括了乌尔都语和斯瓦希里语两种小语种。利用半监督和非监督的方式有效减少了对于监督训练数据的需求。研究人员还探索了数据监督的方式,结合监督和非监督数据,通过数据蒸馏的方法实现半监督学习。另外值得一提的是,研究人员探索了基于图像标签的图像识别系统,创造性的利用现存的、非传统标注的数据生成了大规模的自标记训练数据集,其中包括了35亿张来自Instagram的图像。用户为照片标记的标签可以为图像提供更为丰富的信息,将现存的图像转变为弱监督数据样本。结果表明,这些手段不仅有效地提升了基于图像的任务表现,更将图像识别模型的准确率推高了1%。
图像标签可帮助计算机学习到比通常分类更为细的子分类信息,并补充图中元素的信息。
加速AI研究产品化进程
AI作为一种基础能力已经在产品的方方面面得到体现。2018年Facebook最主要的工作也集中在如何将AI方面的研究成果尽可能的产品化并部署到系统中,主要体现在PyTroch平台和一系列工具的开发上。PyTroch自2018年发布以来已经跃居为GitHub上增长第二的开源项目。其灵活的接口对于研究AI研究的快速迭代十分友好,同时开源的框架设计有助平台包容并蓄快速迭代和发展。随着代码体系的不断完善,今年发布的PyTorch1.0实现了产品级别的框架,涵盖了从原型研究到服务部署的全套流程。
包括Google、微软和英伟达在内的大厂以及Fast.ai、Udacity等教育机构都在使用PyTorch来实现研究、产品开发和教育过程。近日,发布完整版的PyTorch1.0涵盖了混合前端的新特性,可以在图模式和eager模式下无缝切换,同时改进了分布式训练流程,为高性能研究用户提供了纯cpp的编程接口。
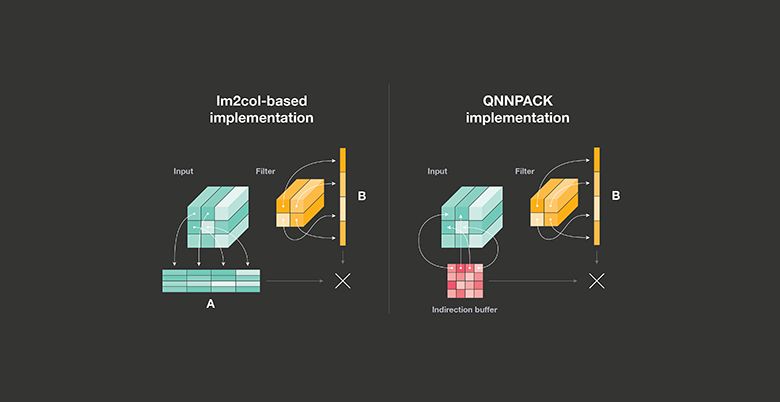
研究人员也基于PyTorch开发了包括 QNNPACK 、FBGEMM等工具库,使得移动端和服务器更容易地运行最新的AI模型。
同时开发了PyText,加速了自然语言处理的研究发展。
在强化学习方面,Facebook开发了Horizon框架,利用强化学习在大规模生成系统中进行优化。它吸收了研究领域大量使用的基于决策的方式,并应用于十亿级别的数据集上。在部署了这套框架后,使得优化视频流和信息流更为高效。这套工具的开源搭建了强化学习研究和产品化之间的桥梁。
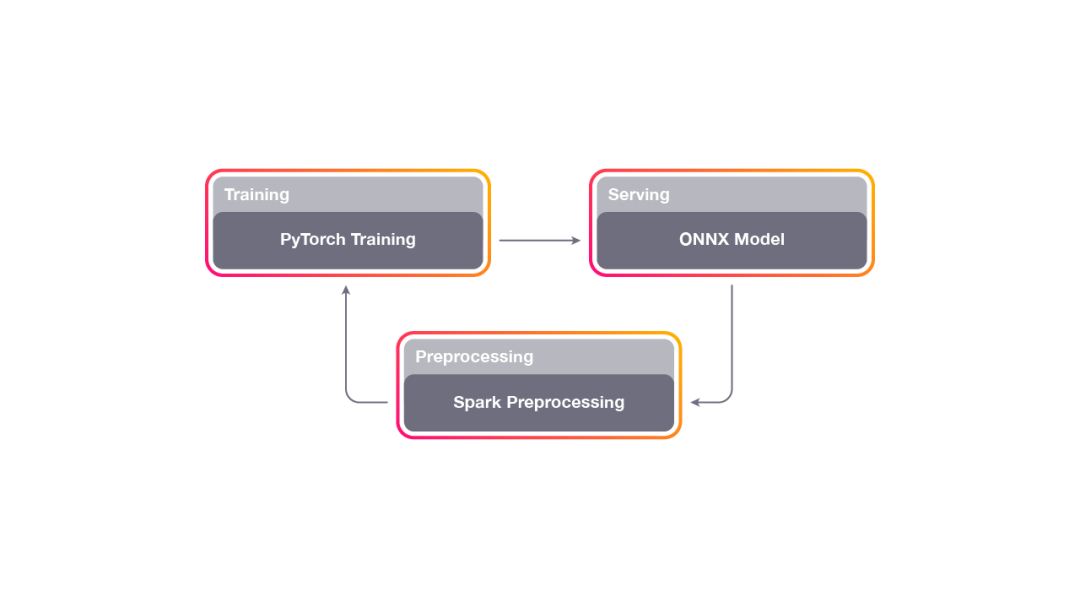
Horizon的流程图解。首先对系统中的数据进行预处理,随后离线训练模型测量、最后对策略进行部署和测试,并循环改进整个流程。
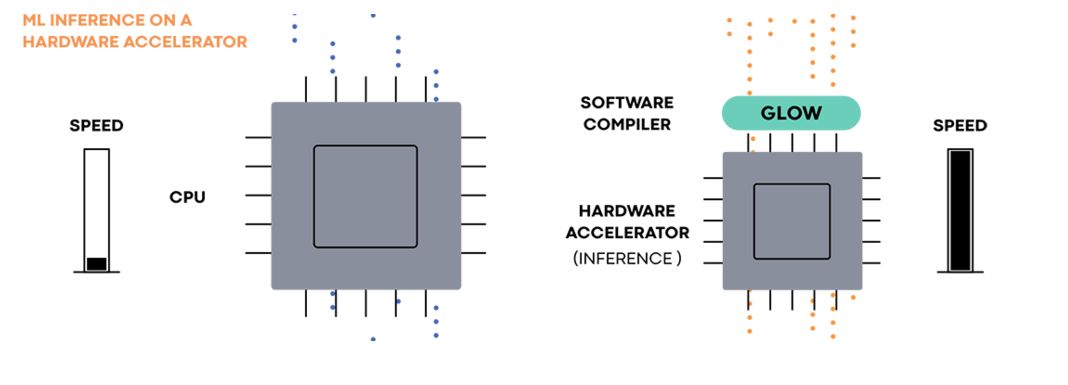
为了加速机器学习的运算过程,另一个称为Glow的开源项目衔接了不同的编译器、硬件平台和深度学习框架,通过与厂家合作开发,在Intel,Cadence, Esperanto, Marvell,Qualcomm 等平台上实现了高效的加速。
作为Open Computer Project的一部分,Facebook还推出了面向工业界机器学习用户的Big Basin v2。
在VR/AR方面,研究人员结合深度学习进行了更深入的研究,在DeepFocus项目中发布了数据和模型。利用深度学习算法渲染出VR中的真实场景,包括了变焦多焦距和光场效果的智能渲染等。
用AI造福人类
将技术广泛应用于改善人类生活的方方面面是每个技术从业者的追求。Facebook在过去一年——利用音频视觉描述技术帮助视觉障碍的人,同时基于跨语言的自然语言处理和文本分析预测用户的自杀倾向,及时拯救更多的人。
同时,研究人员还利用AI迅速精确地计量自然灾害地区的受损状况。为灾难救援、受损评估和灾后重建提供了高效准确定量的手段。
此外通过机器学习技术,研究人员还开发出了Rosetta系统,用于检测图像和视频中的文本信息,并能在多种语言间进行语义的合规性检查,大大减少了人工成本以及不良言论的出现和传播。
Rosetta文本检测的两步架构
最后在医学影像方面,fastMRI项目加速了核磁共振影像的检测速度,加速了深度学习技术向医学领域的迁移和发展。项目不仅发布了充足的数据集,同时也开源了基本模型供来自世界各地的研究人员学习改进。
核磁共振的原始数据和重建后膝盖图像
过去的一年里,研究人员还改进了Getafix, predictive test selection, SapFix, Sapienz, and Spiral等等一系列系统,提高了SLAM和AI in Marketplace等技术在产品中的应用,并发表了一系列研究成果,包括了著名的wav2letter++, 结合多词的表示, 以及multilingual embeddings, 和audio processing等工作。
在新的一年里,更加扎实的工作和研究将在基础设施研究、高精尖应用和AI造福社会等方面展开。希望2019,Facebook能带来更多优秀的研究成果和高效的开源工具,推动AI技术更好发展。
-
Facebook背后的软件揭秘2019-07-16 2736
-
Facebook后台背后的技术2019-07-17 4043
-
脸书AI实验室掌门Yann LeCun宣布卸任 转而担任Facebook首席AI科学家2019-03-17 1433
-
Facebook致力AI开源PyTorch 1.0 AI框架2018-05-08 3731
-
Facebook致力AI 开源PyTorch1.0 AI框架2018-06-18 3604
-
Facebook布局机器人研究 突破AI研究极限2018-07-25 3524
-
Facebook开源Horizon主要是为了推进AI强化学习的发展2018-11-05 1126
-
谷歌发布文章回顾2018AI发展2018-12-26 1872
-
2018年三大Micro LED技术回顾2018-12-29 8538
-
回顾2018年世界的科技发展2019-01-13 5236
-
如何从Facebook的2018年的成长中获取养分2019-02-05 2692
-
Facebook做了一份AI年度总结2019-01-24 3275
-
Facebook跻身AI芯片研发领域_AI芯片大混战2019-02-22 3800
-
贾扬清被曝从Facebook离职,任阿里硅谷研究院VP2019-03-08 2048
-
Facebook构建虚拟空间训练AI2019-06-18 3696
全部0条评论

快来发表一下你的评论吧 !
