

人脸识别技术原理与实现方式
人工智能
描述
随着大数据时代的到来,“人脸”也将成为数据的一部分,人脸识别如何实现?本文将为大家从人脸检测、人脸定位、人脸校准以及人脸对比等方面详细阐述人脸识别的原理与实现方式。
随着计算机技术以及光学成像技术的发展,集成了人工智能、机器学习、视频图像处理等技术的人脸识别技术也逐渐成熟。未来五年,我国人脸识别市场规模平均复合增长率将达到25%,到2021年人脸识别市场规模将达到51亿元左右,具有巨大的市场需求与前景。
安防、金融是人脸识别切入细分行业较深的两个领域,移动智能硬件终端成为人脸识别新的快速增长点。因此,这三大领域将是人脸识别快速增长的最大驱动力。
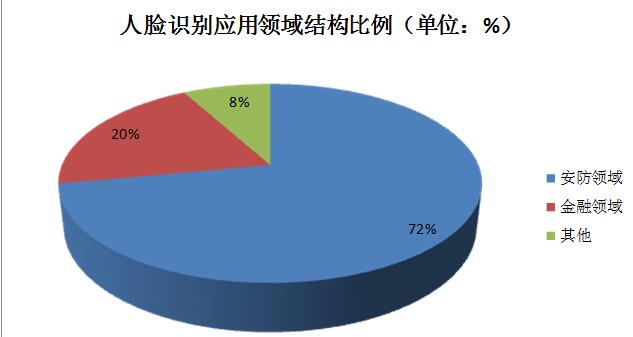
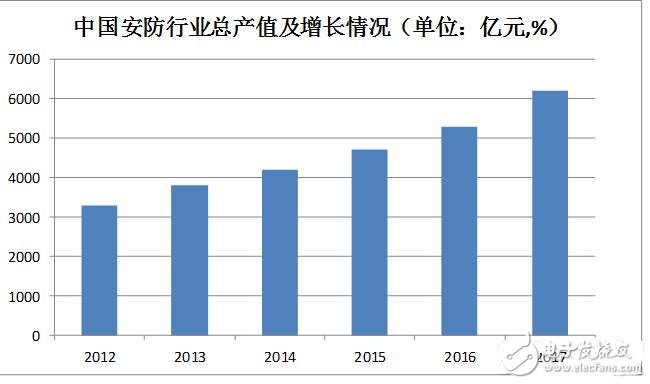
2017年,我国安防行业总产值达到6200亿,同比增长16.98%,维持强劲发展势头。从细分产业来看,视频监控是构建安防系统中的核心,在中国的安防产业中所占市场份额最大。而人脸识别在视频监控领域具有相当的优势,应用前景广阔。
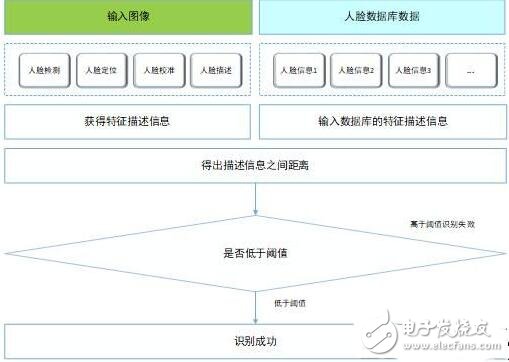
市面上的人脸识别解决方案也越来越多,但在系统框架上基本大同小异,大体框架如下图所示:
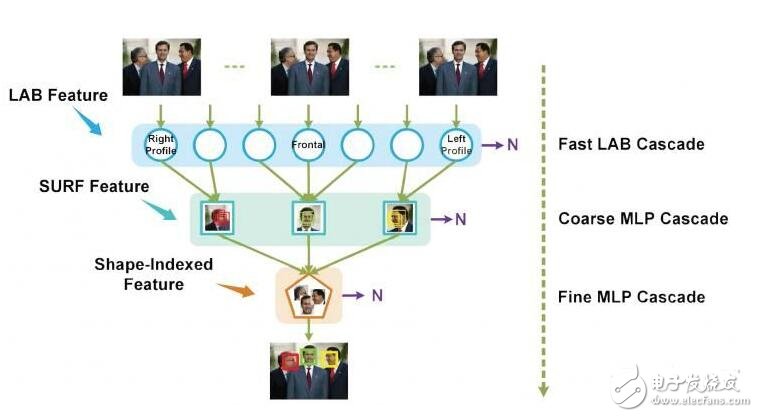
接下来对人脸识别算法各技术点逐一进行详细介绍,包括人脸检测、人脸定位、人脸校准、人脸比对、人脸反欺诈以及算法优化等。
1. 人脸检测
人脸检测算法繁多,我们采用由粗到精的高效方式,即先用计算量小的特征快速过滤大量非人脸窗口图像,然后用复杂特征筛选人脸。这种方式能快速且高精度的检测出正脸(人脸旋转不超过45度)。该步骤旨在选取最佳候选框,减小非人脸区域的处理,从而减小后续人脸校准及比对的计算量。
以下为人脸检测算法的初始化接口, 根据实际应用场景设置人脸的相关参数,包括最小人脸尺寸、搜索步长、金字塔缩放系数等:

人脸检测实测效果如下图所示:
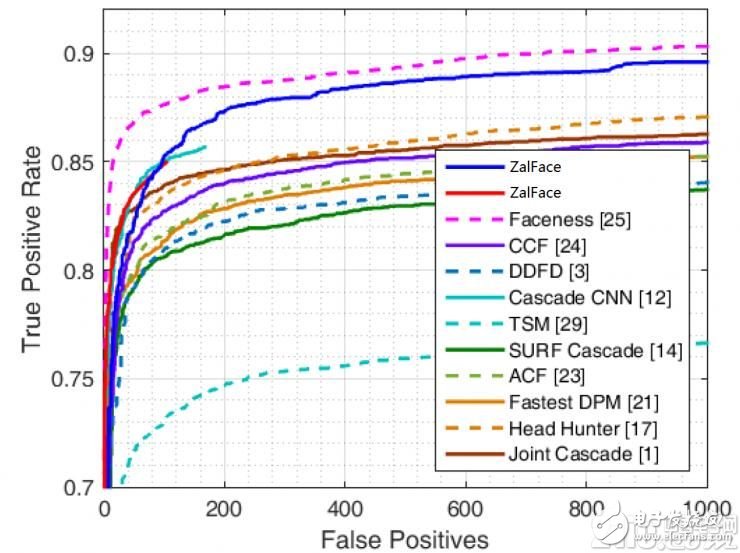
在人脸检测领域比较权威的测试集FDDB上进行评测, 100误检时的召回率达到85.2%, 1000误检时的召回率达到89.3%。
2. 人脸定位
面部特征点定位在人脸识别、表情识别、人脸动画等人脸分析任务中至关重要的一环。人脸定位算法需要选取若干个面部特征点,点越多越精细,但同时计算量也越大。兼顾精确度和效率,我们选用双眼中心点、鼻尖及嘴角五个特征点。经测试,它们在表情、姿态、肤色等差异上均表现出很好的鲁棒性。
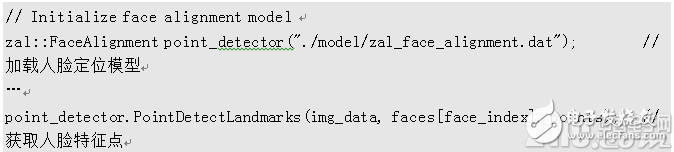
人脸定位接口程序如下所示,需要先加载预先训练好的模型,再进行定位检测:
人脸定位程序的效果如下所示:
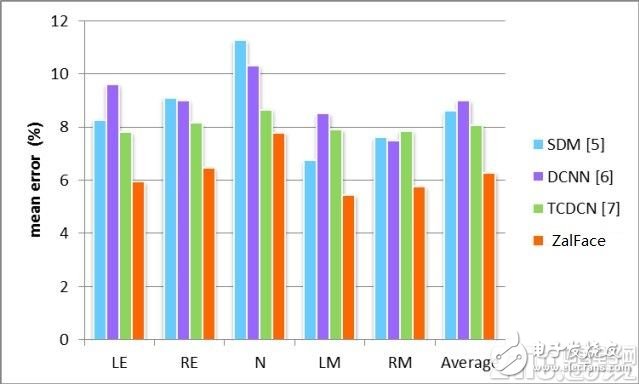
本算法在AFLW数据集上的定位误差及与其他算法的对比情况:
3. 人脸校准
本步骤目的是摆正人脸,将人脸置于图像中央,减小后续比对模型的计算压力,提升比对的精度。主要利用人脸定位获得的5个特征点(人脸的双眼、鼻尖及嘴角)获取仿射变换矩阵,通过仿射变换实现人脸的摆正。
目标图形以(x,y)为轴心顺时针旋转Θ弧度,变换矩阵为:
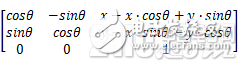
人脸校准C++代码可参考如下所示:

一般此步骤不建议使用外部库做变换,所以这里提供仿射变换python源码以供参考:

人脸校准的效果如图所示:
4. 人脸比对
人脸比对和人脸身份认证的前提是需要提取人脸独有的特征点信息。在人脸校准之后可以利用深度神经网络,将输入的人脸进行特征提取。如将112×112×3的脸部图像提取256个浮点数据特征信息,并将其作为人脸的唯一标识。在注册阶段把256个浮点数据输入系统,而认证阶段则提取系统存储的数据与当前图像新生成的256个浮点数据进行比对最终得到人脸比对结果。
人脸比对流程的示意图如下所示:
通过神经网络算法得到的特征点示意图如下:

而人脸比对则是对256个浮点数据之间进行距离运算。计算方式常用的有两种,一种是欧式距离,一种是余弦距离。x,y向量欧式距离定义如下:
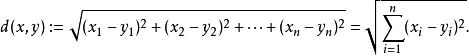
x,y向量之间余弦距离定义如下:
余弦距离或欧式距离越大,则两个特征值相似度越低,属于同一个人的可能性越小。如下图,他们的脸部差异值为0.4296 大于上文所说的该模型最佳阈值0.36,此时判断两人为不同的人,可见结果是正确的。
把归一化为-1到1的图像数据、特征点提取模型的参数还有人脸数据库输入到人脸比对的函数接口face_recgnition,即可得人脸认证结果。程序接口的简单调用方式如下所示:

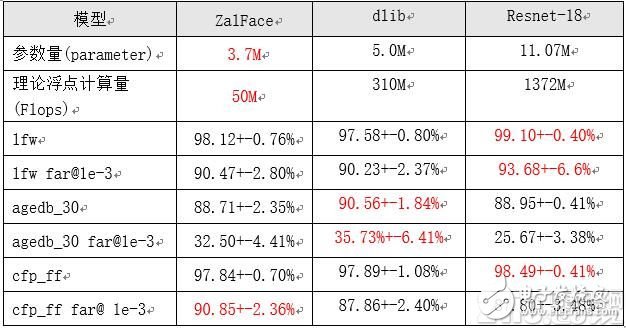
人脸比对算法的准确率方面是以查准率为保证的,AUC (Area under curve)=0.998,ROC曲线图如下所示:
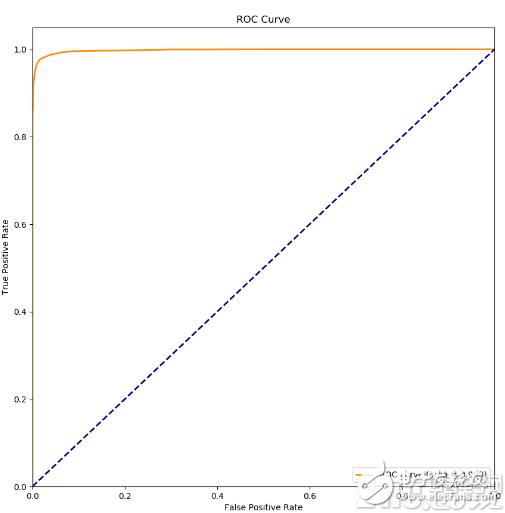
我们设计的比对模型主要特点是模型参数少、计算量少并能保证高的准确率,一定程度上适合在嵌入端进行布置。对比其他人脸比对模型差异如下表格所示:
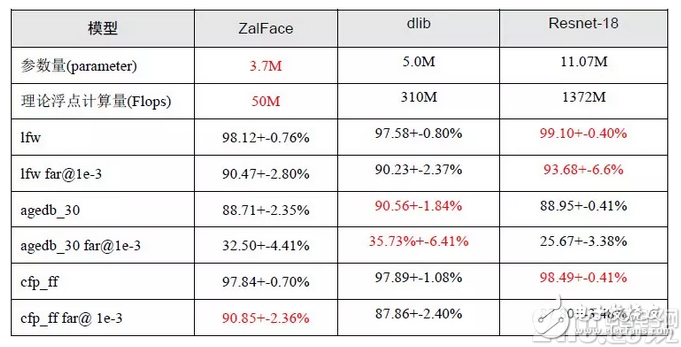
l far@1e-3表示将反例判定为正例的概率控制在千分之一以下时,模型仍能保持的准确率;
l dlib在实际测试中,存在detector检测不出人脸的情况,导致最终效果与官网上有一定差异;
l resnet-18为pytorch的playground标准模型;
l lfw/agedb_30/cfp_ff为标准人脸比对测试库,测试过程中图片已经过人脸居中处理。
5. 人脸反欺诈
从技术角度来说,人脸是唯一不需要用户配合就可以采集的生物特征信息。人脸不同于指纹、掌纹、虹膜等,用户不愿意被采集信息就无法获得高质量的特征信息。人脸信息简单易得,而且质量还好,所以这引发了有关个人数据安全性的思考。而且在没有设计人脸反欺诈算法的人脸识别系统使用手机、ipad或是打印的图片等都能对轻松欺骗系统。
所以我们采用多传感器融合技术的方案,使用红外对管与图像传感器数据进行深度学习来判断是否存在欺诈。红外对管进行用户距离的判断,距离过近则怀疑欺诈行为。图像传感器用深度学习算法进行二分类,把正常用户行为与欺诈用户行为分为两类,对欺诈用户进行排除。
二分类算法能够有效抵抗一定距离的手机、ipad或是打印图片的欺诈攻击。对人脸欺诈数据集与普通人脸数据集预测如图所示:
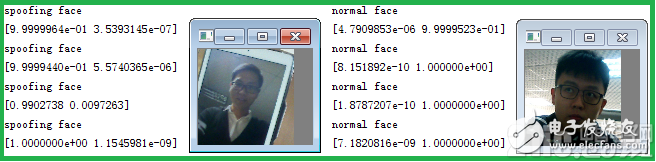
本二分类算法在100万张图片中准确分类的概率为98.89%,所以并不会对整体系统的准确率进行影响,保障系统的可靠性。
6. 算法优化
在使用神经网络算法解决问题的时候,算法效率问题是必要的考量的。特别是在资源与算力不足的嵌入式端,更是头等大问题。除了依托TensorFlow、Keras等开源框架,根据其前向传播的原理写成C++程序,还有必要的编译优化外,模型权重参数的清洗和算法计算的向量化都是比较有效的手段。
1) 模型权重参数清洗
权重参数清洗对神经网络算法的效率影响相当大,没有进行清洗的权重参数访问与操作非常低效,与清洗后的权重参数相比往往能效率相差6-8倍。这差距在算力不足的嵌入式端非常明显,往往决定一个算法是否能落地。具体的方法就是先读取原模型进行重组,让参数变得紧凑且能在计算时连续访问计算,最后获得重组后的模型与对应的重组模型的计算方法。这个步骤需要一定的优化实践经验以达到满意的效果,对模型读取效率与运算效率都会有显著的提高。
2) 算法计算向量化
对于算法的向量化的做法就是让算法的计算能够使用向量乘加等运算,而特别是在使用神经网络算法情况下,大量的计算没有前后相关性且执行相类似的步骤,所以向量化计算会对算法有明显的提升,一般能把算法效率提升三倍左右。
使用NEON指令集的SIMD指令取代ARM通用的SISD指令,是一个常用的算法向量化方法。在基于ARMV7-A和ARMV7-R的体系架构上基本采用了NEON技术,ARMV8也支持并与ARMV7兼容。
以IMX6ULL芯片为例,可以通过查阅官方的参考手册查看其NEON相关信息:

下面举例说明普通的编程写法与NEON instrinsics编程、NEON assembly编程区别。以下为普通的编程写法:

以下为转化为NEON instrinsics的编程:

以为转为NEON assembly的编程:

一般NEON instrinsics已经能做到三倍的提速效果,而NEON assembly效果会更好一些。但是程序向量化需要特殊访存规则,如果不符合则会对导致提速效果大打折扣。
访存特征详细分类如表所示:
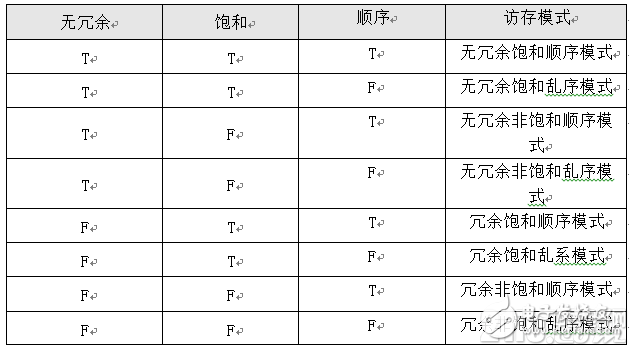
其中,无冗余饱和顺序模式是理想的访问模式,能够发挥算法计算向量化的效果。但是我们神经网络算法的最基本的卷积、全连接等计算却是冗余饱和非顺序模式的计算,这要如何解决呢?
查阅相关论文、期刊对这程序向量化非规则访存的研究,可以发现程序向量化有以下步骤:
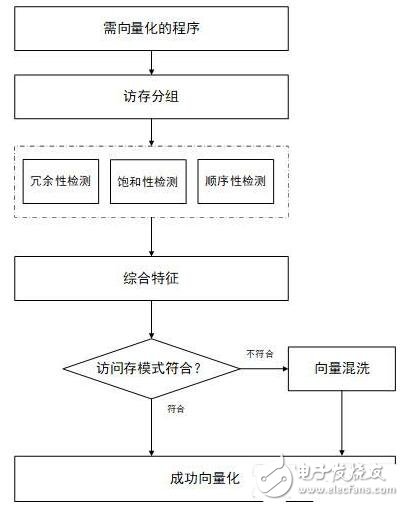
如上图所示,需要对卷积、全连接等冗余饱和非顺序模式计算通过向量混洗为无冗余饱和顺序的模式,以达到优化的效果。
7. 人脸识别效果展示
基于PC的人脸识别展示demo如下视频所示:
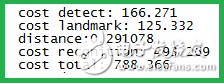
我们的人脸识别算法已经成功移植到了cortex-a7的EPC-6Y2C-L平台,并已经进行了一定的优化,后面会进行进一步的优化。人脸检测效率为166ms左右,人脸定位效率为125ms左右,人脸比对的效率为493ms左右,合计人脸识别总耗时788.3ms左右。下面是在EPC-6Y2C-L的实测效果:
最后附上EPC-6Y2C-L产品图片:
-
机器视觉技术应用之人脸识别2014-01-14 3303
-
泰山哥分享——人脸识别实现技术大解析2016-04-07 4094
-
人脸识别技术原理解析2016-12-23 14942
-
奇谷人脸识别技术2017-06-22 7277
-
人脸识别技术的60年发展史2018-06-20 6512
-
企业安防中的人脸识别技术应用解决方案,八达马人脸技术剖析2018-08-01 2538
-
facexx解析:人脸识别技术市场在哪些领域?2018-12-20 3019
-
LabVIEW人脸识别设计2019-04-28 6360
-
人脸识别技术的优缺点2020-12-24 3919
-
什么是人脸识别技术2021-03-03 4014
-
人脸识别技术入门资料2021-11-23 4600
-
人脸识别是什么_人脸识别技术原理2020-09-27 7456
-
人脸识别技术的原理是什么?2022-12-06 9218
-
人脸识别技术的分类和实现方法2023-06-29 3725
-
人脸识别技术的原理介绍2024-07-04 6456
全部0条评论

快来发表一下你的评论吧 !
