

tf.data API的功能和最佳实践操作
描述
GPU 和 TPU 可以从根本上缩短执行单个训练步骤所需的时间。欲将性能提高到极致,则需要有一个高效的输入管道,能够在当前步骤完成之前为下一步提供数据。tf.data API 有助于构建灵活高效的输入管道。本文介绍了 tf.data API 的功能和最佳实践操作,用于在各种模型和加速器上构建高性能 TensorFlow 输入管道。
本文将主要介绍下列内容:
说明 TensorFlow 输入管道本质上是一个 ETL 过程
描述 tf.data API 上下文中的常见性能优化
讨论应用转换顺序的性能影响
总结设计高性能 TensorFlow 输入管道的最佳实践操作。
输入数据管道的结构
一个典型的 TensorFlow 训练输入管道可以构建为 ETL 过程:
提取:从持久存储中读取数据 - 本地(例如 HDD 或 SSD)或远程(例如 GCS 或 HDFS)
转换:使用 CPU 内核对数据进行解析和执行预处理操作,例如图像解压缩,数据扩充转换(例如随机裁剪,翻转和颜色失真),随机洗牌和批处理
加载:将变换后的数据加载到执行机器学习模型的加速器设备(例如,GPU 或 TPU)上。
这种模式有效地利用了 CPU,与此同时为了模型训练这种繁重的工作,还保留了加速器。此外,将输入管道视为 ETL 过程提供了便于性能优化应用的结构。
使用 tf.estimator.Estimator API 时,前两个阶段(提取和转换)将在传递给 tf.estimator.Estimator 的 input_fn 中捕获。在代码中,这可能会看起来像以下(naive, sequential)执行情况:
def parse_fn(example): "Parse TFExample records and perform simple data augmentation." example_fmt = { "image": tf.FixedLengthFeature((), tf.string, ""), "label": tf.FixedLengthFeature((), tf.int64, -1) } parsed = tf.parse_single_example(example, example_fmt) image = tf.image.decode_image(parsed["image"]) image = _augment_helper(image) # augments image using slice, reshape, resize_bilinear return image, parsed["label"]def input_fn(): files = tf.data.Dataset.list_files("/path/to/dataset/train-*.tfrecord") dataset = files.interleave(tf.data.TFRecordDataset) dataset = dataset.shuffle(buffer_size=FLAGS.shuffle_buffer_size) dataset = dataset.map(map_func=parse_fn) dataset = dataset.batch(batch_size=FLAGS.batch_size) return dataset
下一部分将基于此输入管道构建,添加性能优化。
性能优化
首先,我们定义要使用的模型种类。主智能体会拥有全局网络,且每个本地工作器智能体在自己的进程中都会拥有此网络的副本。我们会使用模型子类化对模型进行实例化。虽然模型子类化会使进程更冗长,但却为我们提供了最大的灵活性。
正如您从我们的正向传递中看到的,我们的模型会采用输入和返回策略概率的分对数和值。
随着新的计算设备(诸如 GPU 和 TPU)不断问世,训练神经网络的速度变得越来越快,这种情况下 CPU 处理很容易成为瓶颈。tf.data API 为用户提供构建块,以设计有效利用 CPU 的输入管道,优化 ETL 过程的每个步骤。
Pipelining
要执行训练步骤,您必须首先提取并转换训练数据,然后将其提供给在加速器上运行的模型。然而,在一个简单的同步执行中,当 CPU 正在准备数据时,加速器则处于空闲状态。相反,当加速器正在训练模型时,CPU 则处于空闲状态。因此,训练步骤时间是 CPU 预处理时间和加速器训练时间的总和。
Pipelining 将一个训练步骤的预处理和模型执行重叠。当加速器正在执行训练步骤 N 时,CPU 正在准备步骤 N + 1 的数据。这样做的目的是可以将步骤时间缩短到极致,包含训练以及提取和转换数据所需时间(而不是总和)。
如果没有使用 pipelining,则 CPU 和 GPU / TPU 在大部分时间处于闲置状态:
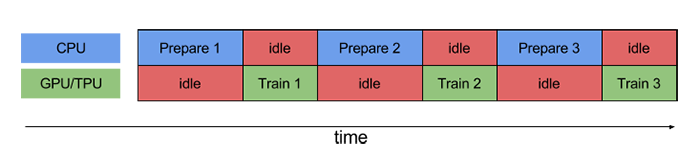
而使用 pipelining 技术后,空闲时间显著减少:
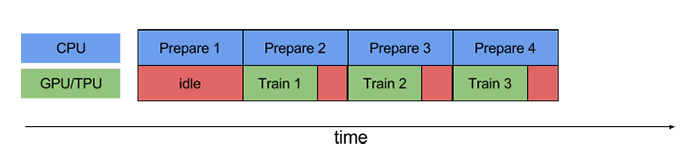
tf.data API 通过 tf.data.Dataset.prefetch 转换提供了一个软件 pipelining 操作机制,该转换可用于将数据生成的时间与所消耗时间分离。特别是,转换使用后台线程和内部缓冲区,以便在请求输入数据集之前从输入数据集中预提取元素。因此,为了实现上面说明的 pipelining 效果,您可以将 prefetch(1) 添加为数据集管道的最终转换(如果单个训练步骤消耗 n 个元素,则添加 prefetch(n))。
要将此更改应用于我们的运行示例,请将:
dataset = dataset.batch(batch_size=FLAGS.batch_size)return dataset
更改为:
dataset = dataset.batch(batch_size=FLAGS.batch_size)dataset = dataset.prefetch(buffer_size=FLAGS.prefetch_buffer_size)return dataset
请注意,在任何时候只要有机会将 “制造者” 的工作与 “消费者” 的工作重叠,预取转换就会产生效益。前面的建议只是最常见的应用程序。
将数据转换并行化
准备批处理时,可能需要预处理输入元素。为此,tf.data API 提供了 tf.data.Dataset.map 转换,它将用户定义的函数(例如,运行示例中的 parse_fn)应用于输入数据集的每个元素。由于输入元素彼此独立,因此可以跨多个 CPU 内核并行化预处理。为了实现这一点,map 转换提供了 thenum_parallel_calls 参数来指定并行度。例如,下图说明了将 num_parallel_calls = 2 设置为 map 转换的效果:
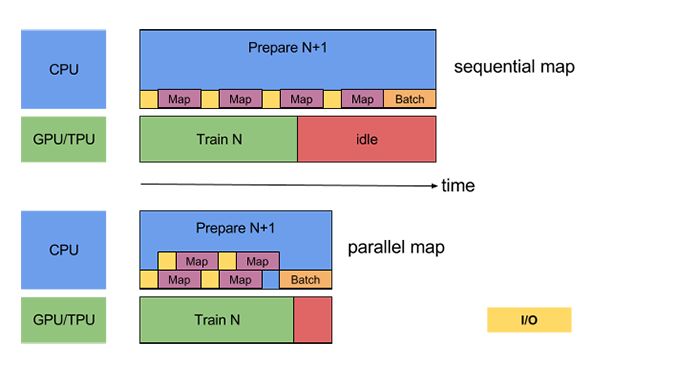
为 num_parallel_calls 参数选择最佳值取决于您的硬件,训练数据的特征(例如其大小和形状),Map 功能的成本以及在 CPU 上同时进行的其他处理;一个简单的启发式方法是使用可用的 CPU 内核数。例如,如果执行上述示例的机器有 4 个内核,则设置 num_parallel_calls = 4 会更有效。另一方面,将 num_parallel_calls 设置为远大于可用 CPU 数量的值可能会导致调度效率低下,从而导致速度减慢。
要将此更改应用于我们的运行示例,请将:
dataset = dataset.map(map_func=parse_fn)
变更为:
dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls)
此外,如果您的批处理大小为数百或数千,您的 pipeline 可能还可以通过并行化批处理创建而从中获益。为此,tf.data API 提供了 tf.contrib.data.map_and_batch 转换,它有效地 “融合” 了 map 和批处理的转换。
要将此更改应用于我们的运行示例,请将:
dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls)dataset = dataset.batch(batch_size=FLAGS.batch_size)
更改为:
dataset = dataset.apply(tf.contrib.data.map_and_batch( map_func=parse_fn, batch_size=FLAGS.batch_size))
将数据提取并行化
在实际环境中,输入数据可能被远程存储(例如,GCS 或 HDFS),因为输入数据不适合本地,或者因为训练是分布式的,因此在每台机器上复制输入数据是没有意义的。在本地读取数据时运行良好的数据集管道在远程读取数据时可能会成为 I / O 的瓶颈,因为本地存储和远程存储之间存在以下差异:
首字节时间:从远程存储中读取文件的第一个字节可能比本地存储长几个数量级
读取吞吐量:虽然远程存储通常提供较大的聚合带宽,但读取单个文件可能只能使用此带宽的一小部分。
另外,一旦将原始字节读入存储器,也可能需要对数据进行反序列化或解密(例如,protobuf),这就增加了额外的系统开销。无论数据是本地存储还是远程存储,都存在这种开销,如果数据未被有效预取,则在远程情况下情况可能更糟。
为了减轻各种数据提取开销的影响,tf.data API 提供了 tf.contrib.data.parallel_interleave 转换。使用此转换可以将其他数据集(例如数据文件读取器)的内容执行和交错并行化。可以通过 cycle_length 参数指定要重叠的数据集的数量。
为 parallel_interleavetransformation 提供 cycle_length = 2 的效果如下图所示:
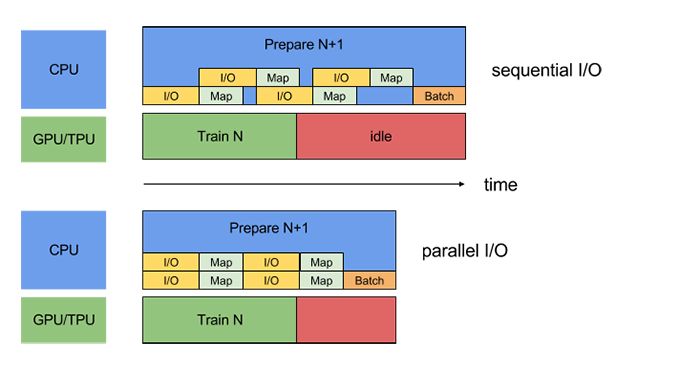
要将此更改应用于我们的运行示例,请将:
dataset = files.interleave(tf.data.TFRecordDataset)
更改为:
dataset = files.apply(tf.contrib.data.parallel_interleave( tf.data.TFRecordDataset, cycle_length=FLAGS.num_parallel_readers))
由于负载或网络事件,远程存储系统的吞吐量可能会随时间而变化。为了解释这种差异,parallel_interleave 转换可以选择使用预取。(请参考 tf.contrib.data.parallel_interleave 了解详情 https://tensorflow.google.cn/api_docs/python/tf/contrib/data/parallel_interleave?hl=zh-CN)。
默认情况下,parallel_interleave 转换提供了元素的确定性排序使之重现。作为预取的替代方法(在某些情况下可能无效),parallel_interleave 转换还提供了一个选项,能够以保证排序作为代价来提高性能。尤其是如果 sloppy 参数设置为 true,则转换可能会偏离其确定的排序,在请求下一元素时那些不可用文件将会暂时跳过。
性能注意事项
tf.data API 围绕可组合转换而设计,为用户提供了灵活性。虽然这些转换中的许多都是可交换的,但某些转换的排序具有性能上的影响。
Map 和 batch
调用传递给 map 转换的用户定义函数会带来与调度和执行用户定义函数相关的系统开销。通常,与函数执行的计算量相比,这种系统开销很小。但是,如果 map 几乎没有使用,那么这种开销可能会占据总成本的大多数。在这种情况下,我们建议对用户定义的函数进行矢量化(即,让它一次对一批输入进行操作),并在 map 转换之前应用 batch 转换。
Map 和 cache
tf.data.Dataset.cache 转换可以在内存或本地存储中缓存数据集。如果传递给 map 转换的用户定义函数非常高,只要结果数据集仍然适合内存或本地存储,就可以在 map 转换后应用缓存转换。如果用户定义的函数增加了存储数据集所需的空间超出缓存容量,请考虑在训练作业之前预处理数据以减少资源使用。
Map 和 Interleave / Prefetch / Shuffle
许多转换(包括 Interleave,prefetch 和 shuffle)会保留元素的内部缓冲区。如果传递给 map 变换的用户定义函数改变了元素的大小,那么 map 变换的顺序和缓冲元素的变换会影响内存使用。通常来说,除非由于性能需要不同的排序(例如,启用 map 和 batch 转换的融合)的情况,否则我们建议选择带来较低内存占用的顺序。
Repeat 和 Shuffle
tf.data.Dataset.repeat 转换以有限(或无限)次数重复输入数据; 每次数据重复通常称为 epoch。
tf.data.Dataset.shuffle 转换随机化数据集示例的顺序。
如果在 shuffle 变换之前应用 repeat 变换,则 epoch 的边界模糊。也就是说,某些元素可以在其他元素出现之前重复一次。另一方面,如果在 repeat 变换之前应用 shuffle 变换,则性能可能在与 shuffle 转换的内部状态的初始化相关的每个 epoch 时期的开始时减慢。换句话说,前者(repeat before shuffle)提供更好的性能,而后者(shuffle before repeat)提供更强的排序保证。
如果可能,我们推荐使用融合的 tf.contrib.data.shuffle_and_repeat 转换,它结合了两方面的优点(良好的性能和强大的排序保证)。否则,我们建议在 repeating 之前进行 shuffling。
最佳的实践操作摘要
以下是设计输入管道的最佳实践操作摘要:
使用 prefetch 转换重叠 “制造者” 和 “消费者” 的工作。特别是,我们建议将 prefetch(n)(其中 n 是训练步骤消耗的元素 / 批次数)添加到输入管道的末尾,以便在 CPU 上执行的转换与加速器上的训练重叠
通过设置 num_parallel_calls 参数来并行化 map 转换。我们建议使用可用 CPU 内核数作为其参数值
如果使用 batch 转换将预处理元素组合成批处理,我们建议使用融合的 map_and_batch 转换,特别是在您使用大型批处理的情况下
如果您正在处理远程存储的数据和 / 或需要反序列化,我们建议使用 parallel_interleave 转换来重叠来自不同文件的数据的读取(和反序列化)
向传递到 map 转换的廉价用户定义函数进行向量化,以分摊与调度和执行函数相关的系统开销
如果您的数据可以存储于内存中,请使用 cache 转换在第一个 epoch 期间将其缓存在内存中,以便后续 epoch 期间避免发生与读取,解析和转换相关的系统开销
如果预处理增加了数据的大小,我们建议您首先应用 interleave,prefetch 和 shuffle(如果可能的话)以减少内存使用量
我们建议在 repeat 转换之前应用 shuffle 转换,理想情况下使用融合的 shuffle_and_repeat 转换。
-
Vue3组合式API最佳实践:从Options API到Composition API2025-10-20 216
-
电商API安全最佳实践:保护用户数据免受攻击2025-07-14 479
-
虚幻引擎的纹理最佳实践2023-08-28 636
-
使用tf.data进行数据集处理2022-11-29 2030
-
local-data-api-gateway本地数据API网关2022-06-14 623
-
支持动态并行的CUDA扩展功能和最佳应用实践2022-04-28 2096
-
6行代码如何实现对TF卡的读写功能2022-02-09 1309
-
6行代码实现对TF卡的读写功能2021-12-05 1181
-
Dockerfile的最佳实践2019-07-11 1452
-
构建简单数据管道,为什么tf.data要比feed_dict更好?2018-12-03 5038
-
PyODPS开发中的最佳实践2018-01-29 3483
-
嵌入式实时操作系统原理与最佳实践2016-07-29 1741
-
C编程最佳实践.doc2012-08-17 2802
全部0条评论

快来发表一下你的评论吧 !
