

机器学习算法概念介绍及选用建议
描述
在从事数据科学工作的时候,经常会遇到为具体问题选择最合适算法的问题。虽然有很多有关机器学习算法的文章详细介绍了相关的算法,但要做出最合适的选择依然非常困难。
在这篇文章中,我将对一些基本概念给出简要的介绍,对不同任务中使用不同类型的机器学习算法给出一点建议。在文章的最后,我将对这些算法进行总结。
首先,你应该能区分以下四种机器学习任务:
监督学习
无监督学习
半监督学习
强化学习
监督学习
监督学习是从标记的训练数据中推断出某个功能。通过拟合标注的训练集,找到最优的模型参数来预测其他对象(测试集)上的未知标签。如果标签是一个实数,我们称之为回归。如果标签来自有限数量的值,这些值是无序的,那么称之为分类。
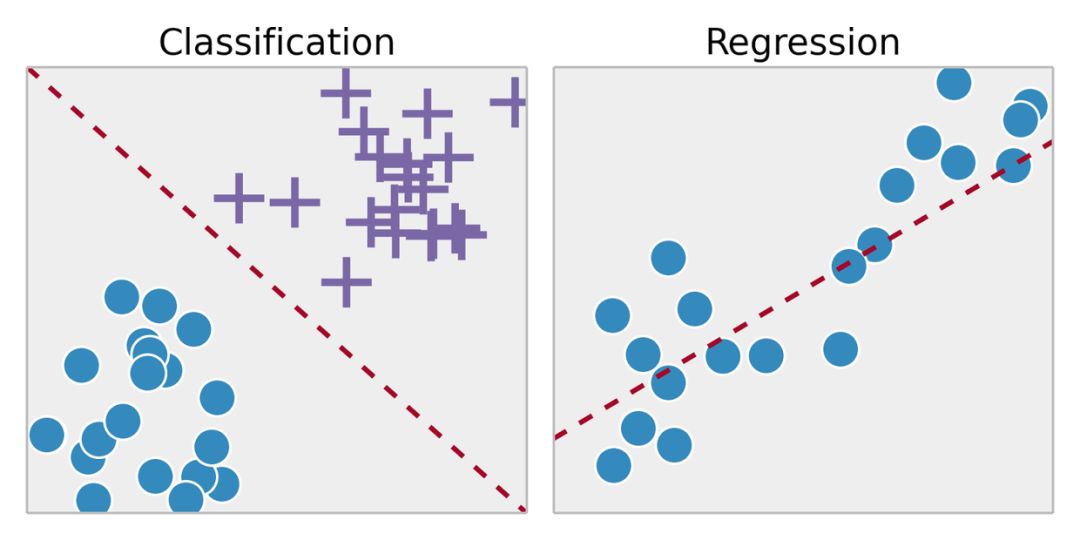
无监督学习
在无监督学习中,我们对于物体知道的信息比较少,特别是训练集没有做过标记。那现在的目标是什么呢?观察对象之间的相似性,并将它们划分到不同的群组中。某些对象可能与其他群组中的对象都有很大的区别,那么我们就认为这些对象是异常的。
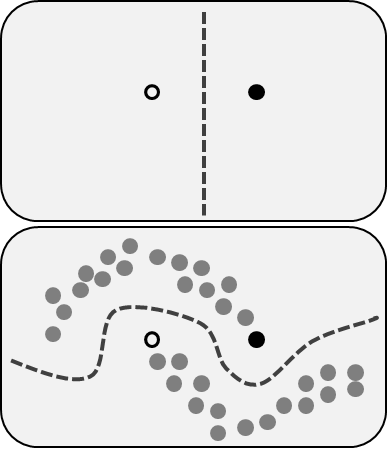
半监督学习
半监督学习包括了前面描述的两个问题:同时使用标记和未标记的数据。对于那些无法标注所有数据的人来说,这是一个很好的方法。该方法能够显著提高准确性,因为在使用训练集中未标记数据的同时,还能使用少量带有标记的数据。
强化学习
强化学习跟上面提到的方法不太一样,因为在这里并没有标记或未标记的数据集。强化学习涉及到软件代理应该如何在某些环境中采取行动来最大化累积奖励。

想象一下,你是一个在陌生环境中的机器人,你可以执行一些动作,并从中获得奖励。在每执行一个动作之后,你的行为会变得越来越复杂越来越聪明,也就是说 ,你正在训练自己在执行每一个动作之后让自己表现得更为有效。在生物学中,这被称为适应自然环境。
常用的机器学习算法
现在,我们对机器学习的类型有了一定的了解,下面,我们来看一下最流行的算法及其在现实生活中的应用。
线性回归和线性分类器
这些可能是机器学习中最简单的算法了。假设有对象(矩阵A)的特征x1,... xn和标签(向量B)。我们的目标是根据某些损失函数(例如MSE或MAE)找到最优权重w1,... wn和这些特征的偏差。 在使用MSE的情况下,有一个来自最小二乘法的数学公式:
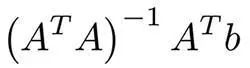
在实践中,使用梯度下降来进行优化则更为容易,计算上更有效率。尽管这个算法很简单,但是在存在成千上万个特征的时候,这个方法依然能够表现良好。更复杂的算法可能会遇到过拟合特征或者是没有足够大的数据集的问题,而线性回归则是一个不错的选择。
为了防止过拟合,可使用像lasso和ridge这样的规则化技术。其主要思路是分别把权重总和以及权重平方的总和加到损失函数中。
逻辑回归
逻辑回归执行的是二元分类,所以输出的标签是二元的。给定输入特征向量x,定义P(y=1|x)为输出y等于1时的条件概率。系数w是模型要学习的权重。
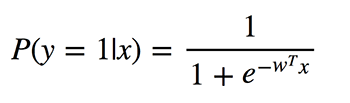
由于该算法需要计算每个类别的归属概率,因此应该考虑概率与0或1的差异程度,并像在线性回归中一样对所有对象取平均值。这种损失函数是交叉熵的平均值:

逻辑回归有什么好处呢?它采用了线性组合的特征,并对其应用非线性函数(sigmoid),所以它是一个非常小的神经网络实例!
决策树
另一个比较流行、并且容易理解的算法是决策树。它的图形能让你看到你自己的想法,它的引擎有一个系统的、有记录的思考过程。
这个算法很简单。在每个节点中,我们选择所有特征和所有可能的分割点之间的最佳分割。选择每个分割以最大化某些功能。在分类树中使用交叉熵和基尼指数。在回归树中,最小化该区域中的点的目标值的预测变量与分配给它的点之间的平方误差的总和。
算法会在每个节点上递归地完成这个过程,直到满足停止条件为止。
K-means
有的时候你并不知道标签,而目标是根据对象的特征来分配标签。这被称为集聚化任务。
假设要把所有的数据对象分成k个簇,则需要从数据中随机选择k个点,并将它们命名为簇的中心。其他对象的簇由最近的簇中心定义。然后,聚类的中心会被转换并重复该过程直到收敛。
虽然这个技术非常不错,但它仍然有一些缺点。首先,我们并不知道簇的数量。其次,结果依赖开始时随机选择的那个点,算法无法保证我们能够实现功能的全局最小值。
主成分分析(PCA)
昨晚或者最近的几个小时里你有没有在准备考试?你无法记住所有的信息,但是想要在可用的时间内最大限度地记住信息,例如,首先学习考试中经常出现的定理等等。
主成分分析基于类似的思想。该算法提供了降维的功能。有时,你有很多的特征,并且彼此之间强相关,模型可以很容易地适应大量的数据。然后,你可以应用PCA。
你应该计算某些向量上的投影,以使数据的方差最大化,并尽可能少地丢失信息。而这些向量是来自数据集特征的相关矩阵的特征向量。
算法的内容现在已经很清楚了:
计算特征列的相关矩阵,找出该矩阵的特征向量。
将这些多维向量计算出来,并计算所有特征的投影。
新特征是投影中的坐标,其数量取决于投影的特征向量的数量。
神经网络
在上文讲到逻辑回归的时候,就已经提到了神经网络。在一些具体的任务中,有很多不同的体系结构都非常有价值。而神经网络更多的时候是一系列的层或组件,它们之间存在线性连接并遵循非线性。
如果你正在处理图像,那么卷积深度神经网络能展现出不错的结果。而非线性则通过卷积层和汇聚层表现出来,它能够捕捉图像的特征。
要处理文本和序列,最好选择递归神经网络。 RNN包含了LSTM或GRU模块,并且能够数据一同使用。也许,最有名的RNN应用是机器翻译吧。
结论
我希望能向大家解释最常用的机器学习算法,并就针对具体问题如何选择机器学习算法提供建议。为了能让你更轻松的掌握这些内容,我准备了下面这个总结。
线性回归和线性分类器。尽管看起来简单,但当其他算法在大量特征上遇到过拟合的问题时,它的优势就表现出来了。
Logistic回归是最简单的非线性分类器,具有二元分类的参数和非线性函数(S形)的线性组合。
决策树通常与人类的决策过程相似,并且易于解释。但它们最常用于随机森林或梯度增强这样的组合中。
K-means是一个更原始、但又非常容易理解的算法。
PCA是降低信息损失最少的特征空间维度的绝佳选择。
神经网络是机器学习算法的新武器,可以应用于许多任务,但其训练的计算复杂度相当大。
-
NPU与机器学习算法的关系2024-11-15 1976
-
深度学习算法的选择建议2023-08-17 1287
-
常用机器学习算法的基本概念和特点2023-01-17 4511
-
机器学习算法的基础介绍2022-10-24 2569
-
机器学习简介与经典机器学习算法人才培养2022-04-28 30381
-
人工智能基本概念机器学习算法2021-09-06 2669
-
机器学习算法基本概念及选用指南2019-01-15 3236
-
关于机器学习的常识性概念是需要注意的2018-07-03 3250
-
Spark机器学习库的各种机器学习算法2017-09-28 1283
-
【阿里云大学免费精品课】机器学习入门:概念原理及常用算法2017-06-23 3502
全部0条评论

快来发表一下你的评论吧 !
