

如何在Hadoop上运行这些深度学习工作
电子说
描述
Hadoop是用于大型企业数据集的分布式处理的最流行的开源框架,它在本地和云端环境中都有很多重要用途。
深度学习对于语音识别,图像分类,AI聊天机器人,机器翻译等领域的企业任务非常有用,仅举几例。为了训练深度学习/机器学习模型,可以利用TensorFlow / MXNet / Pytorch / Caffe / XGBoost等框架。有时需要将这些框架进行组合使用以用于解决不同的问题。
为了使分布式深度学习/机器学习应用程序易于启动,管理和监控,Hadoop社区启动了Submarine项目以及其他改进,例如一流的GPU 支持,Docker容器支持,容器DNS支持,调度改进等。
这些改进使得在Apache Hadoop YARN上运行的分布式深度学习/机器学习应用程序就像在本地运行一样简单,这可以让机器学习工程师专注于算法,而不是担心底层基础架构。通过升级到最新的Hadoop,用户现在可以在同一群集上运行其他ETL / streaming 作业来运行深度学习工作负载。这样可以轻松访问同一群集上的数据,从而实现更好的资源利用率。
典型的深度学习工作流程:数据从各个终端(或其他来源)汇聚到数据湖中。数据科学家可以使用笔记本进行数据探索,创建 pipelines 来进行特征提取/分割训练/测试数据集。 并开展深度学习和训练工作。 这些过程可以重复进行。因此,在同一个集群上运行深度学习作业可以显著提高数据/计算资源共享的效率。
让我们仔细看看Submarine项目(它是Apache Hadoop项目的一部分),请看下如何在Hadoop上运行这些深度学习工作。
为什么叫Submarine 这个名字?
因为潜艇是唯一可以将人类带到更深处的装置设备。B-)
图片由NOAA办公室提供,海洋勘探与研究,墨西哥湾2018年。
SUBMARINE 概览
Submarine项目有两个部分:Submarine计算引擎和一套集成 Submarine的生态系统软件和工具。
Submarine计算引擎通过命令行向YARN提交定制的深度学习应用程序(如 Tensorflow,Pytorch 等)。这些应用程序与YARN上的其他应用程序并行运行,例如Apache Spark,Hadoop Map / Reduce 等。
最重要的是我们的有一套集成Submarine的生态系统软件和工具,目前包括:
Submarine-Zeppelin integration:允许数据科学家在 Zeppelin 的notebook中编写算法和调参进行可视化输出,并直接从notebook提交和管理机器学习的训练工作。
Submarine-Azkaban integration:允许数据科学家从Zeppelin 的notebook中直接向Azkaban提交一组具有依赖关系的任务,组成工作流进行周期性调度。
Submarine-installer:在你的服务器环境中安装Submarine和 YARN,轻松解决Docker、Parallel network和nvidia驱动的安装部署难题,以便你更轻松地尝试强大的工具集。
图表说明了 Submarine 的整体构成,底部显示了 Submarine 计算引擎,它只是 YARN 的一个应用程序。 在计算引擎之上,它集成到其他生态系统,如笔记本电脑(Zeppelin / Jupyter)和 Azkaban。
SUBMARINE 能够做什么?
通过使用 Submarine 计算引擎,用户只需提交一个简单的 CLI 命令即可运行单/分布式深度学习训练工作,并从YARN UI 中获取完整的运行情况。所有其他复杂性,如运行分布式等,都会由 YARN 负责。我们来看几个例子:
就像 HELLO WORLD 一样轻松启动分布式深度学习训练
以下命令启动深度学习训练工作读取 HDFS上 的 cifar10 数据。
这项工作是使用用户指定的 Docker 镜像,与YARN 上运行的其他作业共享计算资源(如CPU / GPU /内存)。
yarn jar hadoop-yarn-applications-submarine-
通过 TENSORBOARD 访问你所有的训练历史任务
以下命令启动深度学习训练工作读取 HDFS 上的 cifar10 数据。
yarn jar hadoop-yarn-applications-submarine-
在 YARN UI 上,用户只需单击即可访问 tensorboard:

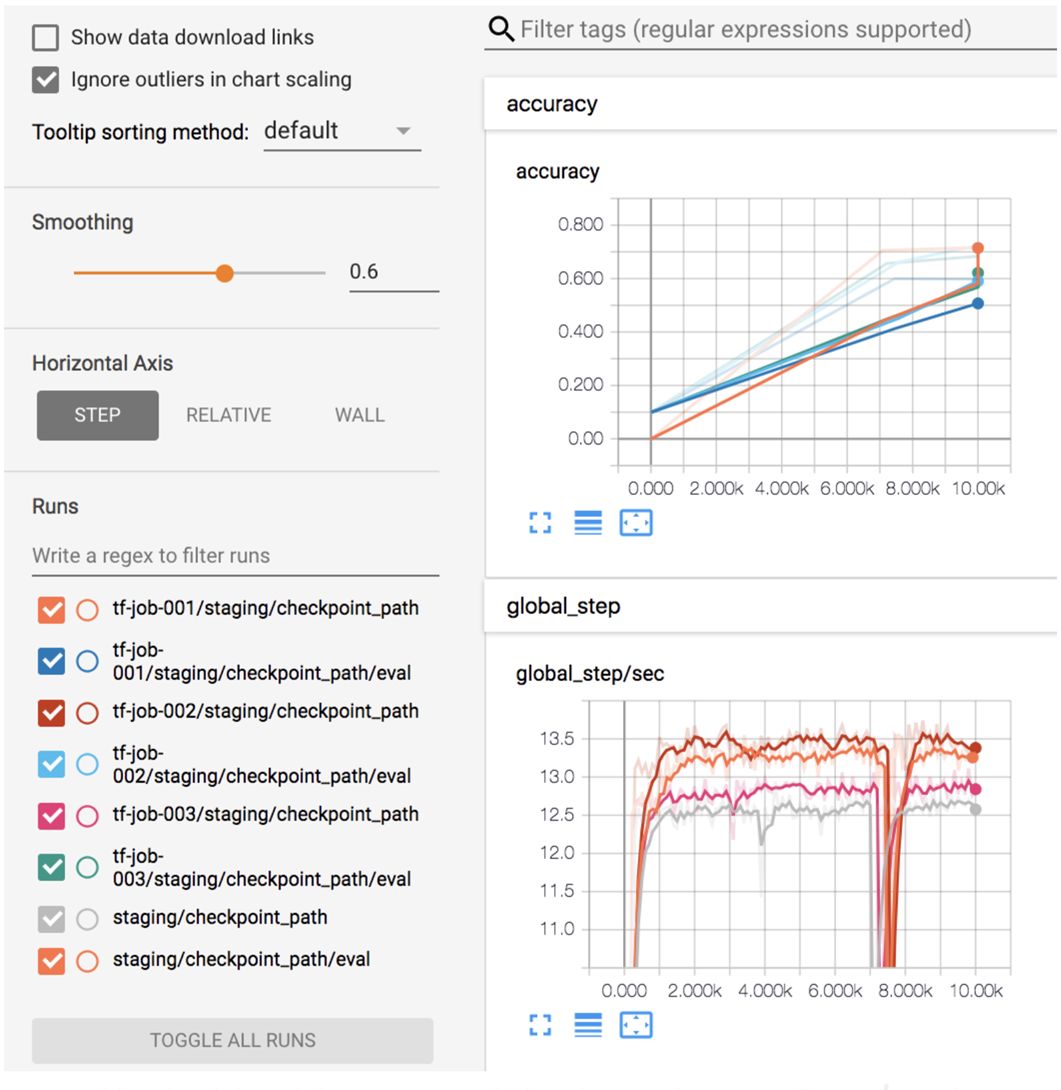
在同一 Tensorboard 上查看训练状态和历史记录。
云端数据科学家 NOTEBOOK
想在 GPU 机器上用笔记本编写算法吗?使用 Submarine,你可以从 YARN 资源池获取云端 notebook。
通过运行以下命令,你可以获得一个notebook,其中包括 8GB 内存,2 个 vcores 和 4 个来自 YARN 的 GPU。
yarn jar hadoop-yarn-applications-submarine-
然后在 YARN UI上,你只需单击一下即可访问笔记本。

SUBMARINE 生态
Hadoop Submarine 项目的目标是提供深度学习场景中的数据(数据采集,数据处理,数据清理),算法(交互式,可视化编程和调优),资源调度,算法模型发布和作业调度的全流程服务支持。
通过与 Zeppelin 结合,很明显可以解决数据和算法问题。Hadoop Submarine 还将解决 Azkaban 的作业调度问题。 三件套工具集:Zeppelin + Hadoop Submarine + Azkaban 为你提供一个零软件成本的、开放所有源码的随时可用的深度学习开发平台。
SUBMARINE 集成 ZEPPELIN
zeppelin 是一个基于 notebook 交互式的数据分析系统。你可以使用 SQL,Scala,Python 等来制作数据驱动的交互式协作文档。
在完成机器学习之前,你可以使用 Zeppelin 中的 20 多种解释器(例如 Spark,Hive,Cassandra,Elasticsearch,Kylin,HBase 等)在 Hadoop 中的数据中收集数据,清理数据,特征提取等。模特训练,完成数据预处理过程。
我们提供 Submarine 解释器,以支持机器学习工程师从 Zeppelin 笔记本中进行算法开发,并直接向 YARN 提交训练任务并从 Zeppelin 中获得结果。
使用 ZEPPELIN SUBMARINE 解释器
你可以在 zeppelin 中创建 submarine 解释器。
在 notebook 的第一行种输入 %submarine.python REPL(Read-Eval-Print Loop,简称REPL)名称,你就可以开始编写 tensorflow 的 python 算法,你可以在一个 Notebook 中至上而下分段落的编写一个或多个算法模块,分块编写算法结合可视化输出将会帮助你更容易验证代码的正确性。
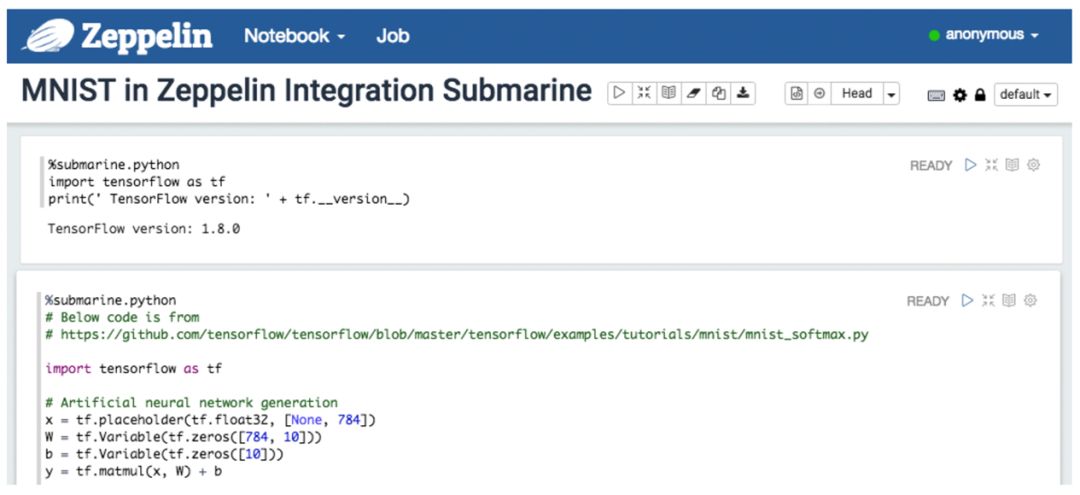
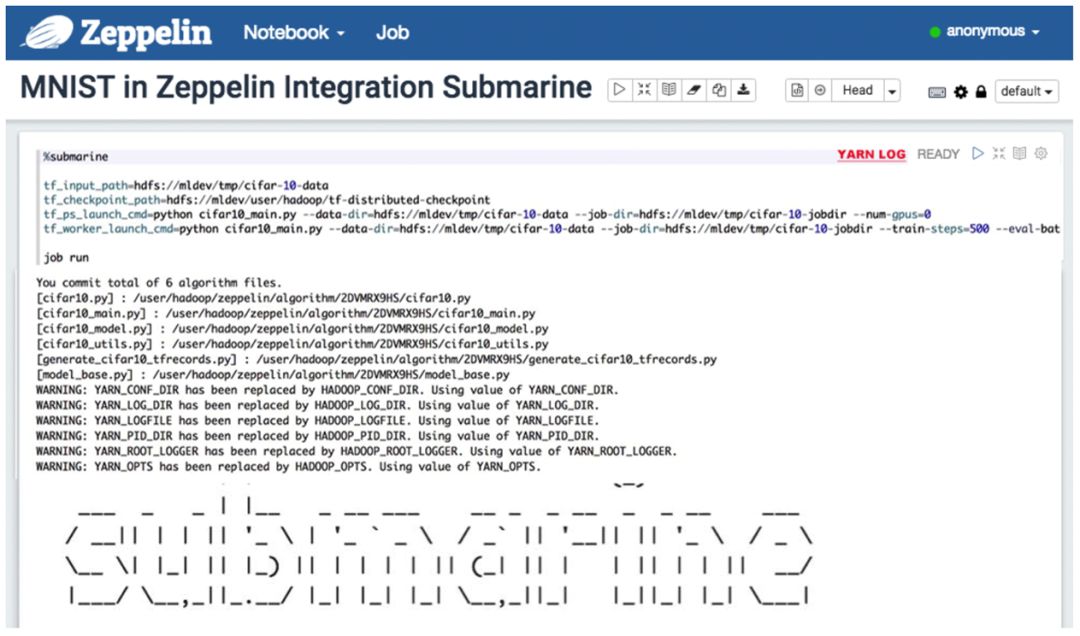
The zeppelin submarine 解释器会自动将分块编写的算法模块进行合并提交到 submarine 计算引擎中执行。
通过点击 Notebook 中的 YARN LOG 超链接,你将会打开 YARN 的管理页面查看执行的任务。
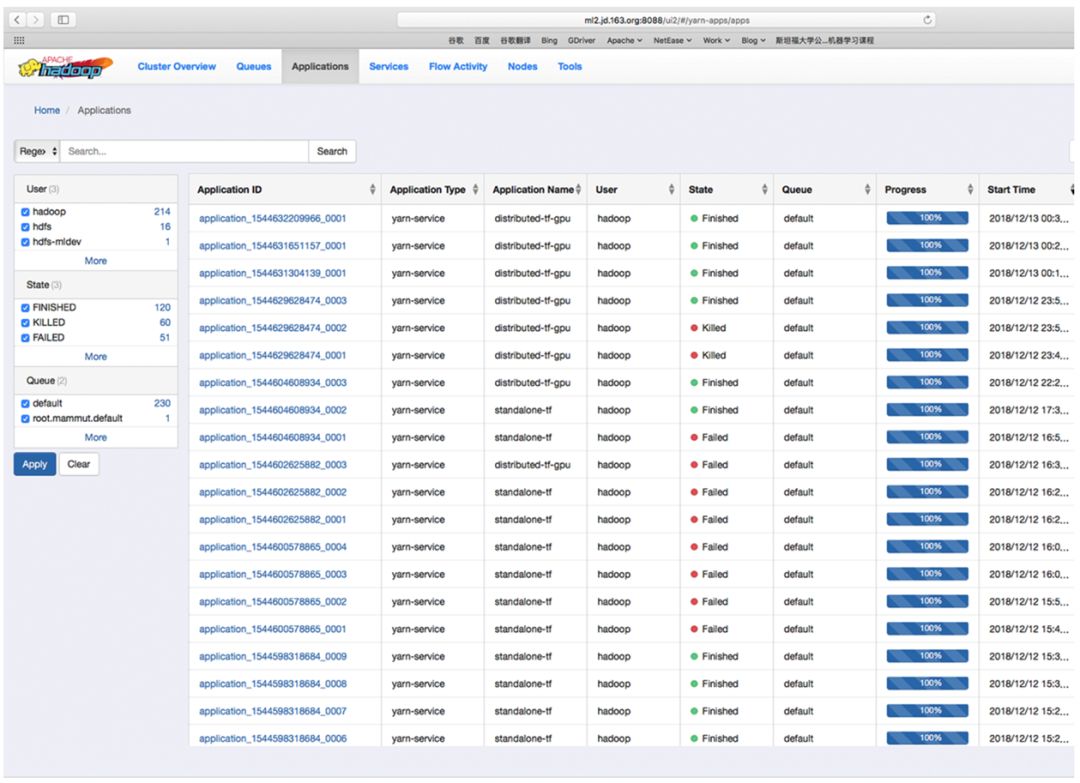
在 YARN 管理页面中,你可以打开自己的任务链接,查看任务的 docker 容器使用情况以及所有执行日志。
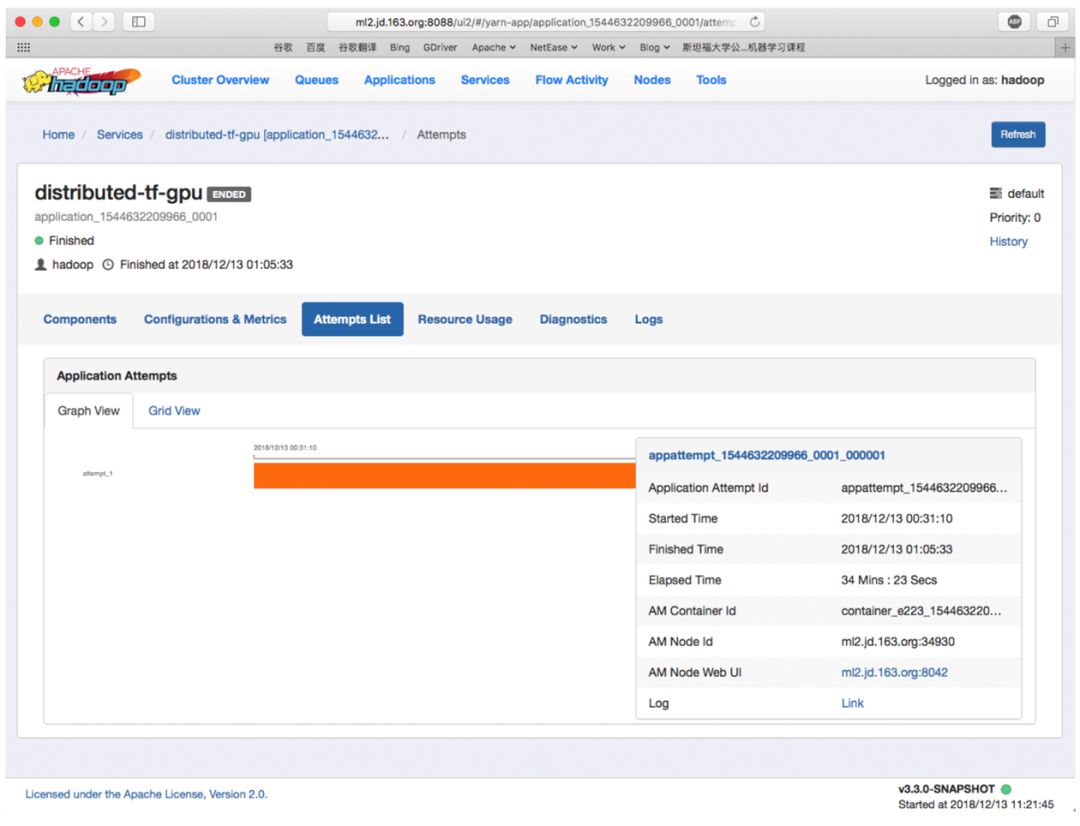
有了这个强大的工具,数据科学家不需要了解 YARN 的复杂性或如何使用 Submarine 计算引擎。提交 Submarine 训练工作与在笔记本中运行 Python 脚本完全相同。最重要的是,用户无需更改其已有算法程序即可转换为 Submarine 作业运行。
SUBMARINE 集成 AZKABAN
Azkaban 是一种易于使用的工作流程安排服务,通过 Azkaban 安排 Zeppelin 编写的 Hadoop Submarine Notebook 来安排指定 Notebook 设置某些段落之间的工作流程。
你可以在 Zeppelin 中使用 Azkaban 的作业文件格式,编写具有执行依赖性的多个笔记本执行任务。
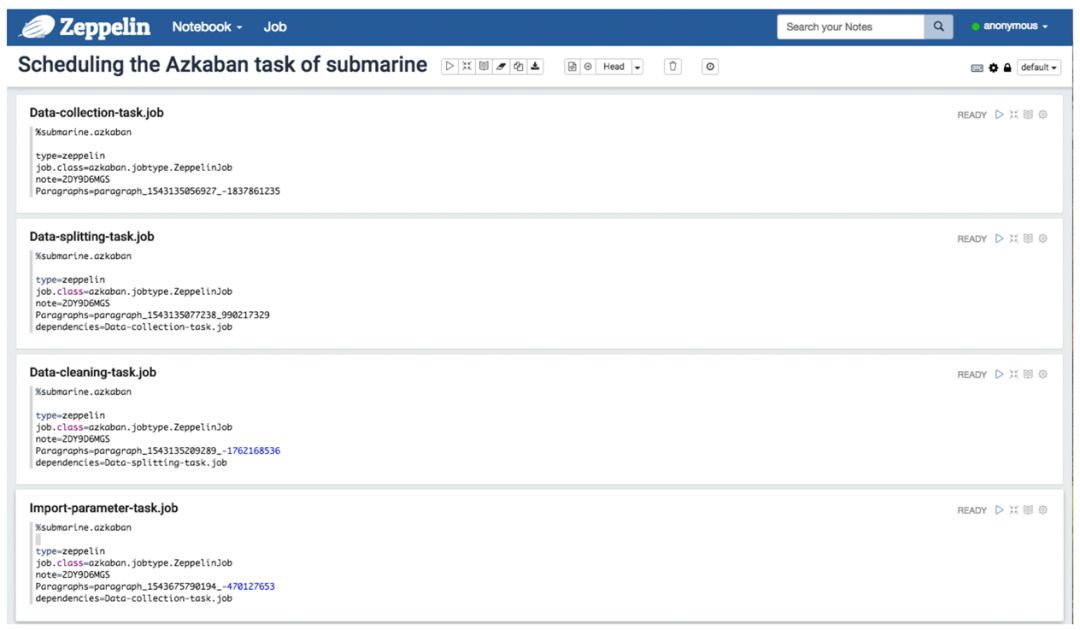
Azkaban 能够调度这些通过 zeppelin 编辑好的具有依赖关系的 notebook。
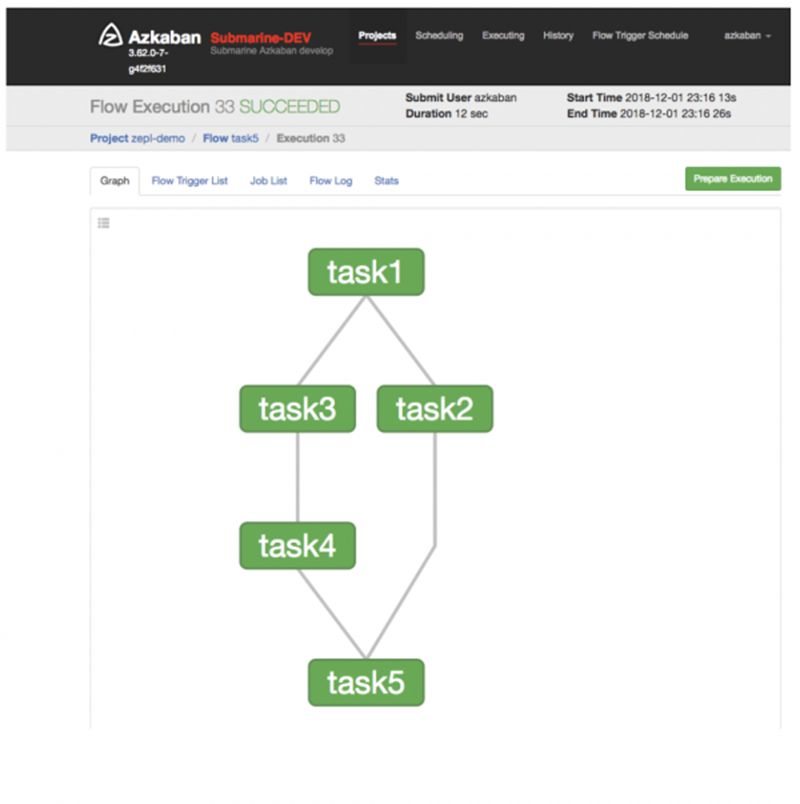
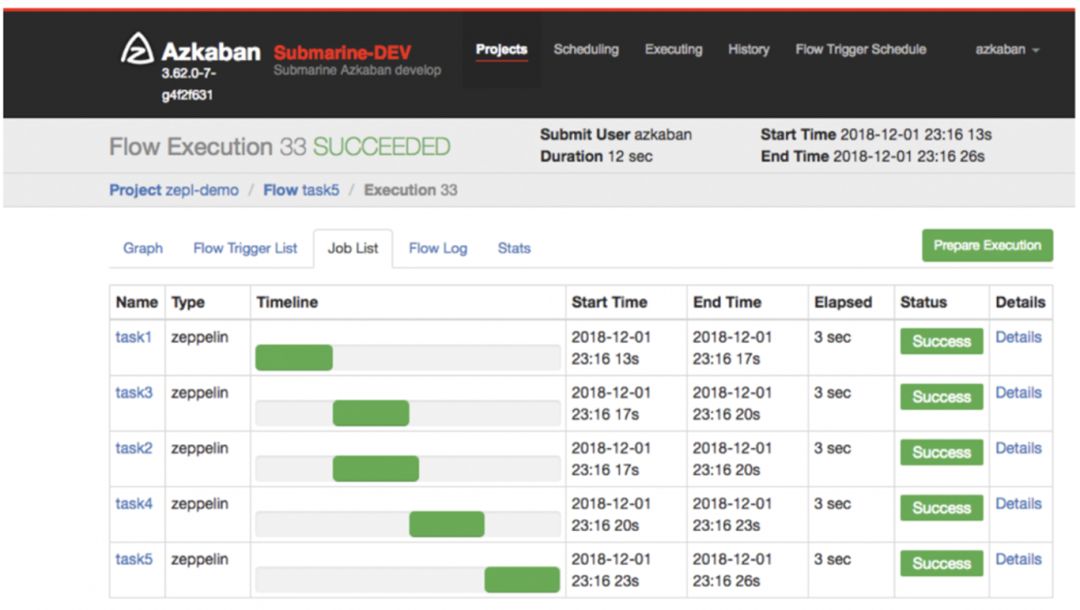
一旦执行了带有 Azkaban 脚本的 notebook,它将被编译为 Azkaban 支持的工作流并提交给 Azkaban 以执行。
HADOOP SUBMARINE 安装程序
由于分布式深度学习框架需要在多个 Docker 容器中运行,并且需要能够协调容器中运行的各种服务,因此需要为分布式机器学习完成模型训练和模型发布服务。这其中将涉及到多个系统工程问题,如 DNS,Docker,GPU,网络,显卡驱动,操作系统内核修改等,正确部署这些运行环境是一件非常困难和耗时的事情。
我们为你提供了 submarine installer ,用于运行时环境的安装, submarine installer 是一个完全由 Shell 脚本编写,提供了简单易用的菜单化操作方式,你只需要在一台可以联网的服务器上运行,就可以轻松便捷的安装好运行环境。
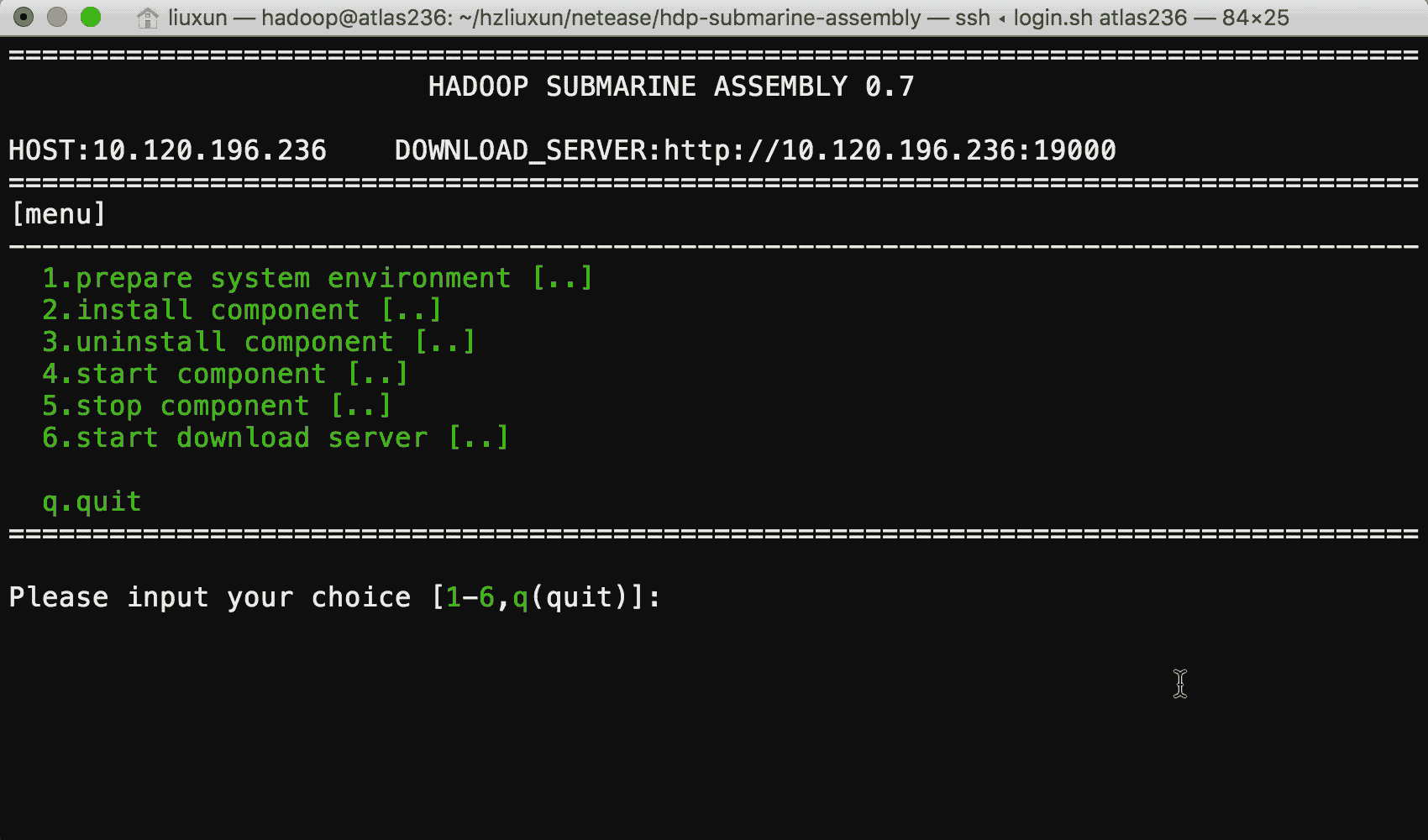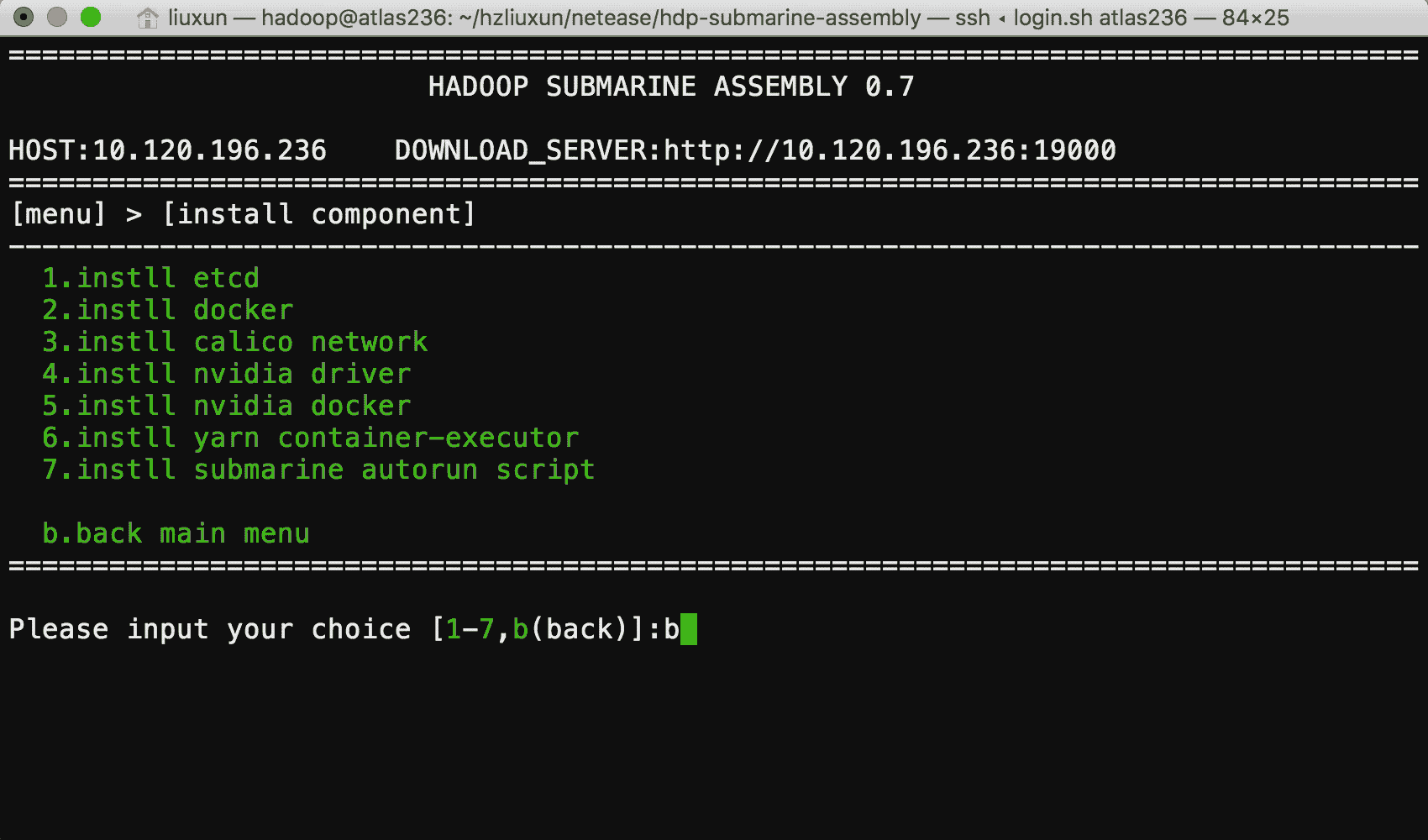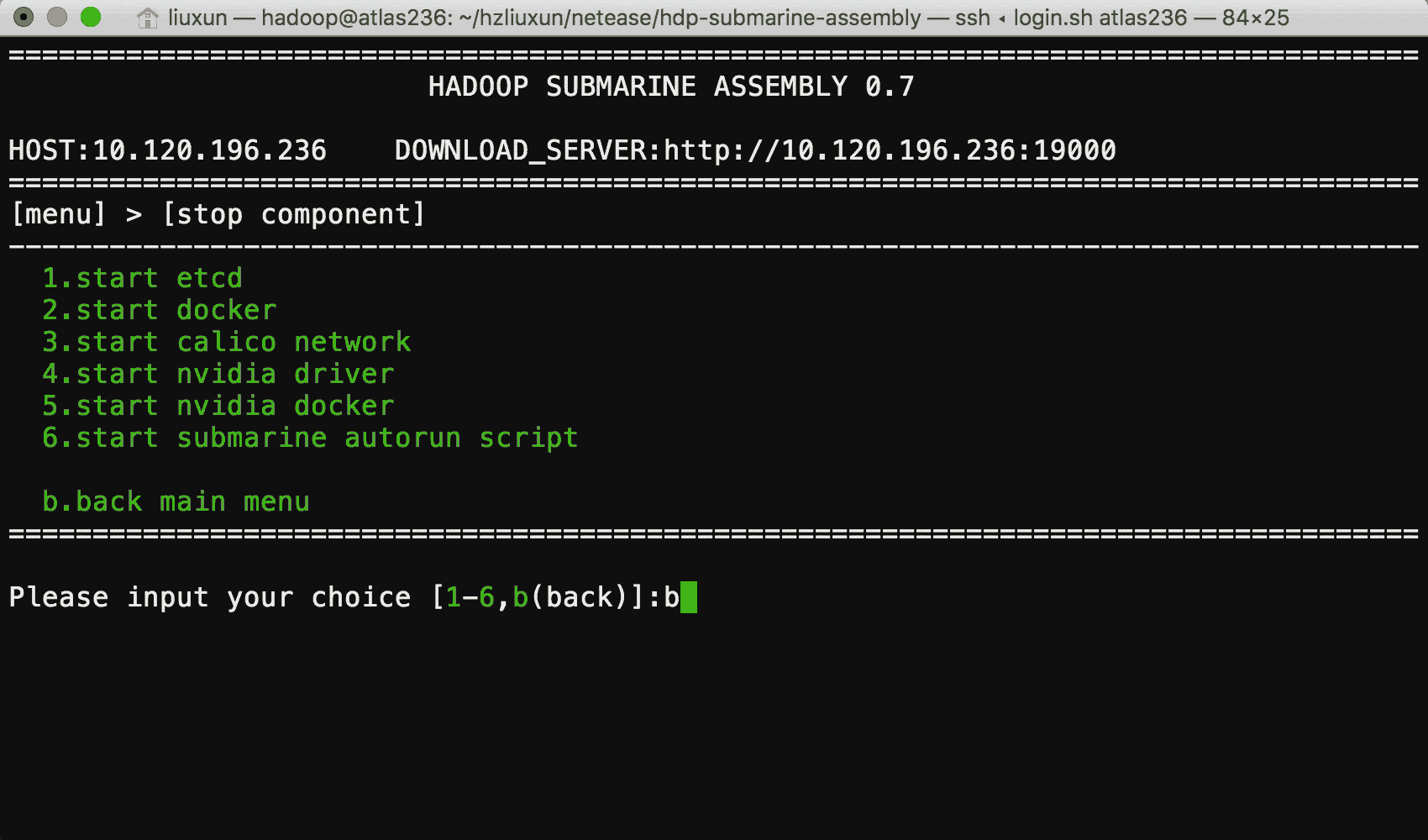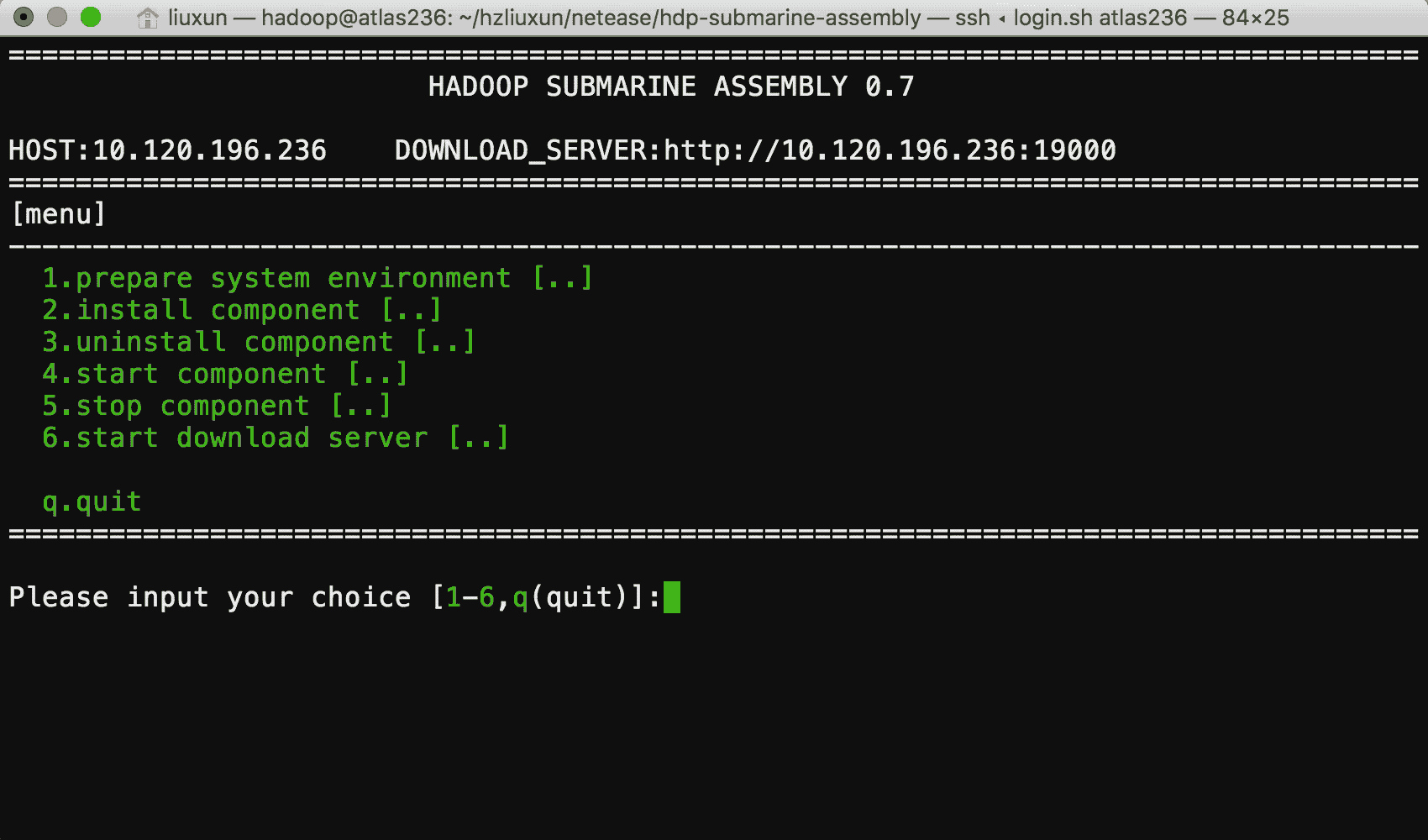
安装过程中你如果遇见问题,还可以通过我们提供的安装手册进行解决。
项目状态
Alpha 版本的解决方案已经合并到 Haodop 主干分支。 3.2.0版本的一部分仍处于活动开发/测试阶段。Umbrella JIRA: YARN-8135.
Submarine 能够运行在 Apache Hadoop 3.1+.x release 版本上,实际上你只需要安装 Apache Hadoop 3.1 的 YARN 就可以使用完整的 Submarine 的功能和服务,经过我们的实际使用, Apache Hadoop 3.1 的 YARN 可以完全无误的支持 Hadoop 2.7 + 以上的 HDFS 系统。
案例 – 网易
网易杭研大数据团队是 Submarine 项目的主要贡献者之一,主要希望通过 Submarine 来解决机器学习开发和运维过程中遇到的以下问题:
现有计算集群的状态:
网易通过互联网提供在线游戏/电商/音乐/新闻等服务。
YARN 集群中运行有 ~ 4k 服务器节点
每天 100k 计算任务
单独部署的 Kubernetes 集群(配备GPU)用于机器学习工作负载
每天 1000+ 计算学习任务
所有的 HDFS 数据都是通过 Spark、Hive、impala 等计算引擎进行处理
存在的问题:
用户体验不佳
没有集成的操作平台,全部通过手动编写算法,提交作业和检查运行结果,效率低,容易出错。
利用率低
无法重用现有的YARN群集资源。
无法集成现有的大数据处理系统(例如:spark,hive等)
维护成本高(需要管理分离的集群)
需要同时运维 Hadoop 和 Kubernetes 两套操作环境,增加维护成本和学习成本。
网易内部 Submarine 部署情况
积极与 Submarine 社区合作开发,已经验证 20 个 GPU 节点集群上的 Submarine 的可靠性。
计划将来将所有深度学习工作转移到Submarine上
-
如何在OpenCV中使用基于深度学习的边缘检测?2023-05-19 2813
-
从零开始学习hadoop?hadoop快速入门2018-03-13 3625
-
hadoop工作流程2018-05-11 2338
-
学习hadoop需要什么基础2018-09-13 1645
-
Hadoop基础入门之发行版本的选择2018-11-28 2926
-
hadoop和spark的区别2018-11-30 2842
-
大数据hadoop入门之hadoop家族产品详解2018-12-26 2943
-
hadoop最新发行稳定版:DKHadoop版本选择详解2018-12-28 2839
-
深度学习模型是如何创建的?2021-10-27 2292
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2036
-
如何在嵌入式设备上运行高性能Java2009-03-28 558
-
怎么样才能快速搭建Hadoop运行环境2020-04-02 900
-
如何在xWR1xxx芯片上运行mmw demo2022-11-01 475
-
如何在深度学习结构中使用纹理特征2022-10-10 1707
-
如何在DGX Spark上运行NVIDIA Omniverse2025-12-17 324
全部0条评论

快来发表一下你的评论吧 !
