

基于神经网络的计算模型,将大脑中的脑电数据转化为语言
电子说
描述
对于有语言障碍的人来说,内心的表达只能通过纸笔或者是手语来与人沟通交流,但他们想说的话却会在脑海里时时回荡,如果能将这些脑中的信号转换为语音发出,将会给他们带来巨大的帮助。随着科技的迅猛发展,新技术有可能会造福于这些失语人群。最近,有三个研究小组进行了相关研究,他们使用基于神经网络的计算模型,将大脑中的脑电数据转化为语言,并通过计算机合成出语音,重建了可被听众理解的单词和句子。
传统语音转换
虽然目前已有基于默读时的肌肉信号来进行语音合成技术的初步研究,但这种方式更多是帮助人们在不方便说话的时候与计算机或者其他人交流。
对于语音障碍人士特别是先天障碍,这种方式无法通过通常的肌肉信号来捕捉并合成出对应的语音。如有有朝一日,新技术可以仅仅基于人们的思维过程而重建出人们脑中想表达的语言,将会造福更多的人。在中风或疾病之后失去说话能力的人可以使用眼动跟踪、联想输入和语音合成播放三个步骤达到重新表达的目的。 霍金的个人助理设备就是观测无法通过收缩他脸颊上的某块肌肉,来触发安装在眼镜上的开关,从而输入文字向世界传达他的观点和见解,但是他每分钟仅可以输入5-15个单词,无法像正常人一样流畅的表达自己的观点,思维受制于设备的速度。试想,如果霍金可以像马斯克或者老黄一样流畅的发表自己的演讲,不用花大量的时间用于输出单词,那么他很可能会为世界带来更多的巨大的贡献。
如果未来可以通过脑机接口来重构他们的语言系统,那将会为霍金一样的使用者带来巨大的帮助,他们不仅可以表达想说的话,还可以控制说话的音调,表达的速度也会大幅提升,使得残障人士实时对话和有效的表达成为可能。
已有的突破
前途是光明的,道路是曲折的。最先遇到的问题在于数据采集和数据量的限制。在不同个体之间,脑电信号转化为语音的过程存在一定的差异性,因此必须对每个人(的个性化数据)进行“训练”。
而且众所周知:使用的数据越精确,模型的运行效果就越好,但是精准的模型需要开颅手术后才能获得,这样严苛的条件大大限制了数据的获取,研究人员只能在极少数的情况下进行。一种情况是在移除脑肿瘤的手术期间,另一种情况是在癫痫患者脑内植入电极,来诊断癫痫发作的起因。但是,每次留给研究者们的数据收集最多只有二三十分钟。数据量非常有限。
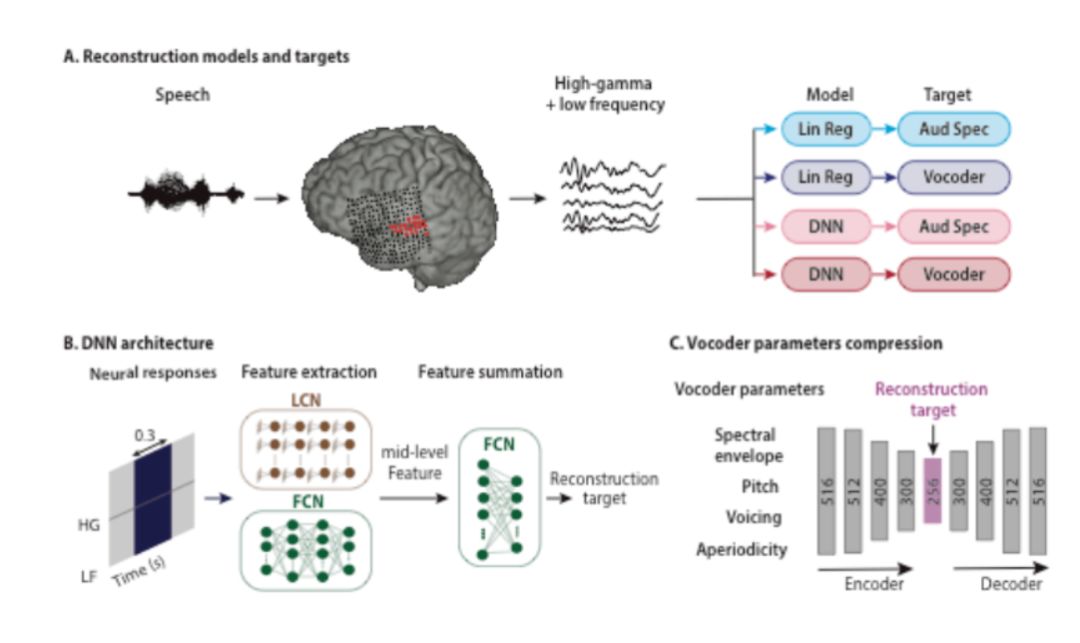
研究人员目前正在致力于寻找出可替代的有效的数据获取方式。其中一部分研究人员利用听觉区域的植入电极来获取大脑的信号,并试图找出在不同时间点的神经元模型推断出对应的语音。神经网络的计算模型过将信息传递到计算“节点”层来处理复杂模式。网络通过调整节点之间的连接来学习。
在实验中研究人员使用了两种回归模型一种用于生产听觉频谱,一种用于生成声音信息的向量编码。网络的监督信号和输入信息分别是一个人产生或听到的语音记录和同时期的大脑活动数据中。一个团队使用了来自五名癫痫患者的数据。他们的网络分析了当病人听到了故事和从0到9的数字的录音时听觉皮层(在语音和听力过程中都很活跃)的活动状况,然后利用计算机,以采集到的神经数据为依据,重建口述的数字。合成后的语音,准确率达到了75%。
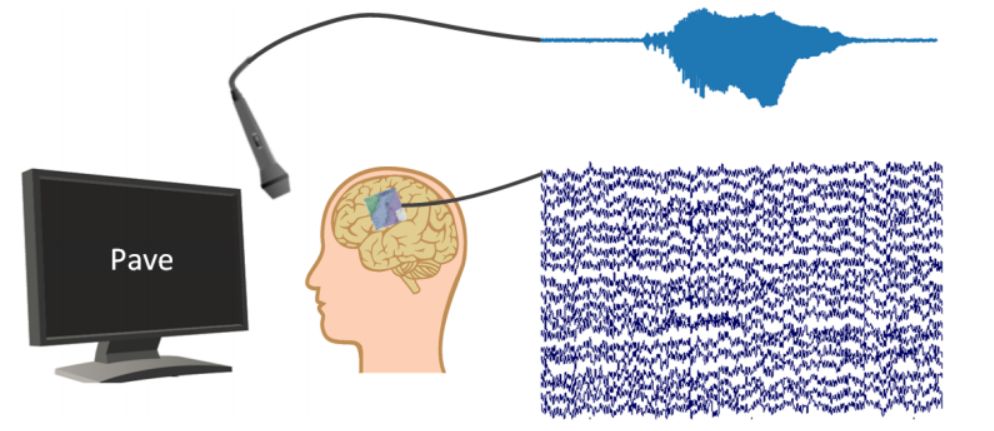
另外一支由德国不来梅大学的神经科学家和荷兰马斯特里赫特大学的学者组成的团队,他们使用来源于六名接受脑瘤手术患者的数据。首先,患者被要求重复屏幕上出现的词语,同时通过麦克风来捕捉音频信息。同时研究者们还需捕捉从大脑的语音规划区域和运动区域获取的信号,这些信号向声道发送命令,并使得人们能清楚说出单词。
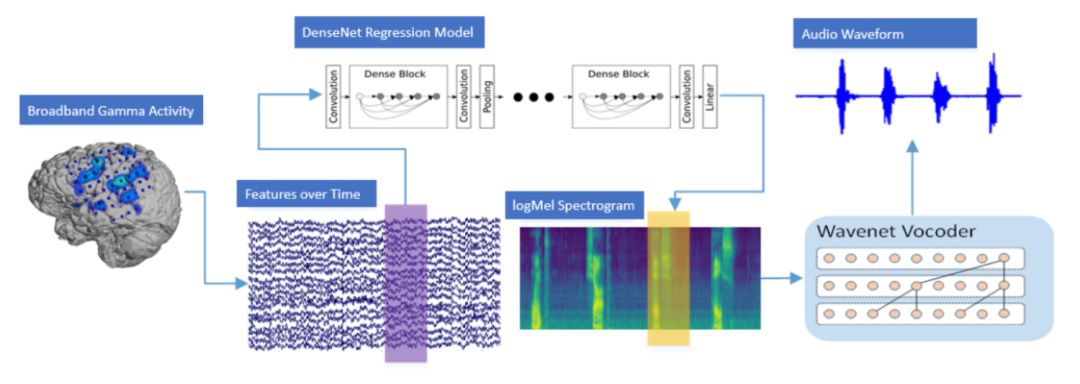
最后,利用神经网络模型将脑电信号映射到音频记录,然后从数据中重建单词。研究结果表明:大约40%的计算机生成的单词是可以理解的。研究人员主要使用了下图所示的densenet模型来实现电信号的音频信号的重建:

此外自于加州大学旧金山分校的团队通过从语言和运动区域捕获的大脑活动来重建整个句子,他们所使用的数据采集于三名癫痫的患者大声朗读的过程中。为了验证重建句子的有效性,邀请了166名受试者进行了在线测试。实验结果表明,对于某些句子,达到了超过80%的识别准确率。
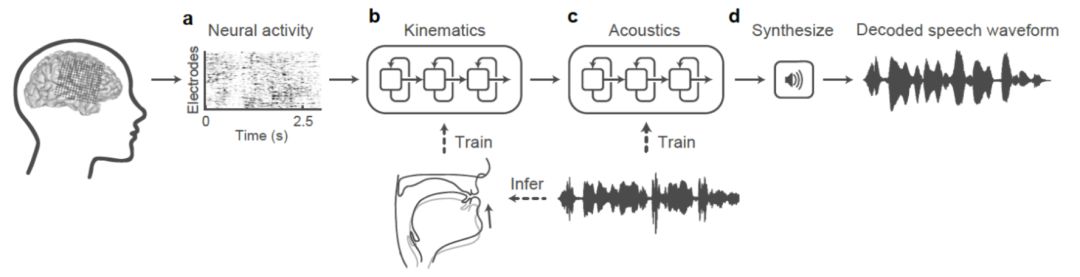
研究人员还进一步改进了模型:他们使用该模型来基于默念采集到的信息来重建句子。该研究使得人们基于脑中思维过程而重建出脑中想表达的内容的目标又更进一步。
未来展望
未来,我们期望的是患者不用说话,仅仅通过脑中的思维过程来进行语音合成。当一个人默念和感知到某种语言时,大脑的反应与真正说出和听到声音时的信号不同。如果没有外部声音来匹配大脑活动,计算机甚至可能很难理清内部语音的开始和结束位置。解码”想象中的语言” 需要利用脑机接口向用户提供反馈——他们能够实时听到计算机的语音解释,给出计算机反馈,以获得他们想要的结果。通过对用户和神经网络的充分训练,未来的某一天,大脑和计算机也许能找到更好的配合方法。
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+神经形态计算、类脑芯片2025-09-17 2989
-
人工神经网络的原理和多种神经网络架构方法2025-01-09 3067
-
基于神经网络的语言模型有哪些2024-07-10 2571
-
人工神经网络模型的分类有哪些2024-07-05 4045
-
神经网络模型的工作原理和作用2023-08-28 3151
-
卷积神经网络模型原理 卷积神经网络模型结构2023-08-21 3045
-
神经网络模型用于解决什么样的问题 神经网络模型有哪些2023-08-03 8297
-
什么是神经网络?为什么说神经网络很重要?神经网络如何工作?2023-07-26 5809
-
卷积神经网络模型发展及应用2022-08-02 13409
-
如何构建神经网络?2021-07-12 2041
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 3998
全部0条评论

快来发表一下你的评论吧 !
