

详解谷歌最强NLP模型BERT
电子说
描述
作者:李理,环信人工智能研发中心vp,十多年自然语言处理和人工智能研发经验。主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。
本文是作者正在编写的《深度学习理论与实战》的部分内容。
导语
Google BERT 模型最近横扫了各大评测任务,在多项任务中取得了最好的结果,而且很多任务比之前最好的系统都提高了非常多,可以说是深度学习最近几年在 NLP的一大突破。但它并不是凭空出现的,最近一年大家都非常关注的 UnsupervisedSentence Embedding 取得了很大的进展,包括 ELMo 和 OpenAI GPT 等模型都取得了很好的结果。而 BERT 在它们的基础上改进了语言模型单向信息流的问题,并且借助 Google 强大的工程能力和计算资源的优势,从而取得了巨大的突破。
本文从理论和编程实战角度详细的介绍 BERT 和它之前的相关的模型,包括
Transformer 模型。希望读者阅读本文之后既能理解模型的原理,同时又能很快的把模型用于解决实际问题。本文假设读者了解基本的深度学习知识包括 RNN/LSTM、Encoder-Decoder 和 Attention 等。
Sentence Embedding 简介
前面我们介绍了 Word Embedding,怎么把一个词表示成一个稠密的向量。Embedding几乎是在 NLP 任务使用深度学习的标准步骤。我们可以通过 Word2Vec、GloVe 等从未标注数据无监督的学习到词的 Embedding,然后把它用到不同的特定任务中。这种方法得到的 Embedding 叫作预训练的 (pretrained)Embedding。如果特定任务训练数据较多,那么我们可以用预训练的 Embedding 来初始化模型的 Embedding,然后用特定任务的监督数据来 fine-tuning。如果监督数据较少,我们可以固定 (fix)Embedding,只让模型学习其它的参数。这也可以看成一种 Transfer Learning。
但是 NLP 任务的输入通常是句子,比如情感分类,输入是一个句子,输出是正向或者负向的情感。我们需要一种机制表示一个句子,最常见的方法是使用 CNN 或者 RNN 对句子进行编码。用来编码的模块叫作编码器 (Encoder),编码的输出是一个向量。和词向量一样,我们期望这个向量能够很好的把一个句子映射到一个语义空间,相似的句子映射到相近的地方。编码句子比编码词更加复杂,因为词组成句子是有结构的 (我们之前的 Paring 其实就是寻找这种结构),两个句子即使词完全相同但是词的顺序不同,语义也可能相差很大。
传统的编码器都是用特定任务的监督数据训练出来的,它编码的目的是为了优化具体这个任务。因此它编码出的向量是适合这个任务的——如果这个任务很关注词序,那么它在编码的使用也会关注词序;如果这个任务关注构词法,那么学到的编码器也需要关注构词法。
但是监督数据总是很少的,获取的成本也极高。因此最近 (2018 年上半年),无监督的通用 (universal) 的句子编码器成为热点并且有了一些进展。无监督的意思是可以使用未标注的原始数据来学习编码器 (的参数),而通用的意思是学习到的编码器不需要 (太多的)fine-tuning 就可以直接用到所有 (只是是很多) 不同的任务中,并且能得到很好的效果。
评测工具
在介绍 Unsupervised Sentence Embedding 的具体算法之前我们先介绍两个评测工具(平台)。
SentEval
简介
Sentence Embedding(包括 Word Embedding) 通常有两类评价方法:intrinsic 和 ex-trinsic。前者只评价 Embedding 本身,比如让人来主观评价。而后者通过下游 (Downstream) 的任务间接的来评价 Embedding 的好坏。前一种方法耗费人力,而且我们学习 Embedding 的目的也是为了解决后面的真实问题,因此 extrinsic 的评价更加重要。但是下游的任务通常很复杂,Embedding 只是其中的一个环节,因此很难说明最终效果的提高就是由于 Embedding 带来的,也许只是某个预处理或者超参数的调节带来的提高,但是却可能被作者认为是 Embedding 的功劳。另外下游任务很多,很多文章的结果也很难比较。
为了解决这些问题,Facebook 做了 SentEval 这个工具。这是一个用于评估Universal Sentence Representation 的工具,所谓的 Universal Sentence Representation是指与特定任务无关的通用的句子表示 (Embedding) 方法。为了保证公平公正,这个工具只评价句子的 Embedding,对于具体的任务,大家都使用相同的预处理,网络结构和后处理,从而能够保证比较公平的评测。
SentEval 任务分类
SentEval 任务分为如下类别:
分类问题 (包括二分类和多分类)
Natural Language Inference
语义相似度计算
图像检索 (Image Retrieval)

图 17.1: SentEval 的分类任务
分类很简单,输入是一个字符串 (一个句子或者文章),输出是一个分类标签。所以任务如图17.1所示。包括情感分类、句子类型分类等等任务。
Natural Language Inference(NLI) 任务也叫 recognizing textual entailment(RTE),它的输入是两个句子,需要机器判断第一个句子和第二个句子的关系。它们的关系通常有 3 种:矛盾 (contradiction)、无关 (neutral) 和蕴含 (entailment)。
SNLI(https://nlp.stanford.edu/projects/snli/) 是很常用的 NLI 数据集,示例是来自这个数据集的例子。比如下面的两个句子是矛盾的:
A man inspects the uniform of a figure in some East Asian country.
The man is sleeping.
一个人不能同时在观察和睡觉。而下面两个句子的关系是无关的:
A smiling costumed woman is holding an umbrella.
A happy woman in a fairy costume holds an umbrella.
而下面两个的第一个句子蕴含了第二个句子:
A soccer game with multiple males playing.
Some men are playing a sport.
语义相似度计算的输入是两个句子,输出是它们的相似度,一般相似度会分为几个程度,所以输出也是标签。当然最简单的是分成两类——相似与不相似,比如MRPC 就是这样的任务,这个任务又叫 Paraphrase Detection,判断两个句子是否同义复写。
Image Retrieval 的输入是一幅图片和一段文字,如果文字能很好的描述图片的内容,那么输出一个高的分值,否则输出低分。
SentEval 包括的 NLI 和图像检索任务如图17.2所示。

图 17.2: SentEval 的 NLI 和 Image Retrieval 任务
SentEval 的用法
SentEval 依赖 NumPy/SciPy、PyTorch(>=0.4.0) 和 scikit-learn(>=0.18.0)。
然后从https://github.com/facebookresearch/SentEval.git clone 代码。SentEval 提供了一些baseline 系统,包括 bow、infersent 和 skipthought 等等。读者如果实现了一种新的Sentence Embedding 算法,那么可以参考 baseline 的代码用 SentEval 来评价算法的好坏。
我们这里只介绍最简单的 bow 的用法,它就是把 Pretraining 的 Word Embedding加起来得到 Sentence Embedding。
我们首先下载 fasttext 的 Embedding:

然后运行:

main 函数代码为:


首先构造 senteval.engine.SE,然后列举需要跑的 task,最后调用 se.eval 得到结果。
构造 senteval.engine.SE 需要传入 3 个参数,params_senteval, batcher 和 prepare。params_senteval 是控制 SentEval 模型训练的一些超参数。比如 bow.py 里的:

而后两个参数是函数,我们先看 prepare:

这个函数相当于初始化的回调函数,参数会传入 params 和 samples,samples 就是所有的句子,我们需要根据这些句子来做一些初始化的工作,结果存在 params 里,后面会用到。这里我们用 samples 构造 word2id——word 到 id 的映射,另外根据word2id,从预训练的词向量里提取需要的词向量 (因为预训练的词向量有很多词,但是在某个具体任务中用到的词是有限的,我们只需要提取需要的部分),另外把词向量的维度保持到 params 里。
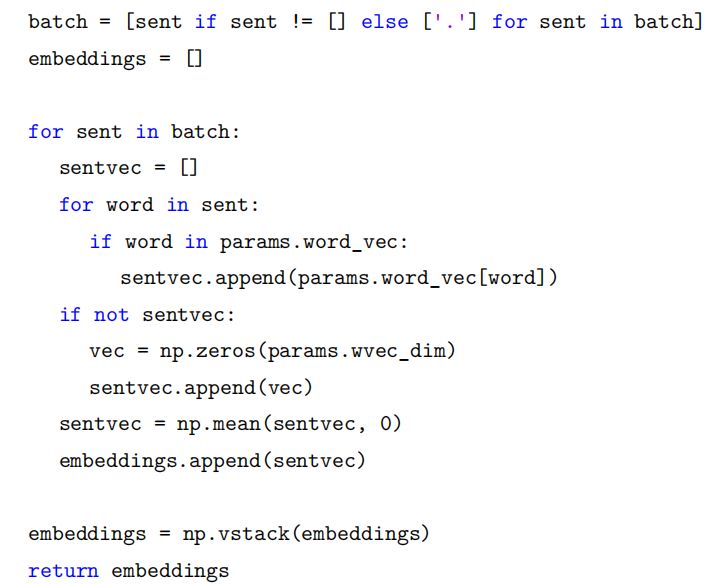
batcher 函数的输入参数是前面的 params 和 batch,batch 就是句子列表,我们需要对它做 Sentence Embedding,这里的实现很简单,就是把词向量加起来求平均值得到句子向量。

GLUE
Facebook 搞了个标准,Google 也要来一个,所以就有了 GLUE(https://gluebenchmark.com/)。GLUE 是 General Language Understanding Evaluation 的缩写。它们之间很多的任务都是一样的,我们这里就不详细介绍了,感兴趣的读者可以参考论文”GLUE: A Multi-Task Benchmark and Analysis Platform for Natural LanguageUnderstanding”。
Transformer
简介
Transformer 模型来自与论文 Attention Is All You Need(https://arxiv.org/abs/1706.03762)。
这个模型最初是为了提高机器翻译的效率,它的 Self-Attention 机制和 Position Encoding 可以替代 RNN。因为 RNN 是顺序执行的,t 时刻没有处理完成就不能处理 t+1 时刻,因此很难并行。但是后来发现 Self-Attention 效果很好,在很多其它的地方也可以是 Transformer 模型。
图解
我们首先通过图的方式直观的解释 Transformer 模型的基本原理,这部分内容主要来自文章 The Illustrated Transformer(http://jalammar.github.io/illustratedtransformer/)。
模型概览
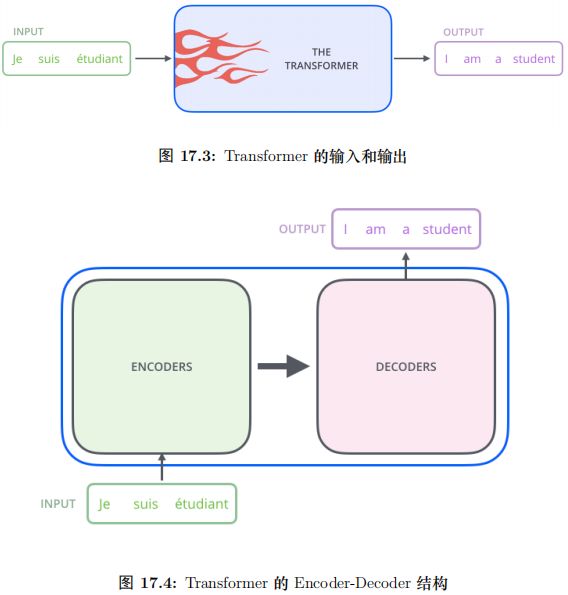
我们首先把模型看成一个黑盒子,如图15.51所示,对于机器翻译来说,它的输入是源语言 (法语) 的句子,输出是目标语言 (英语) 的句子。
把黑盒子稍微打开一点,Transformer(或者任何的 NMT 系统) 都可以分成
Encoder 和 Decoder 两个部分,如图15.52所示。
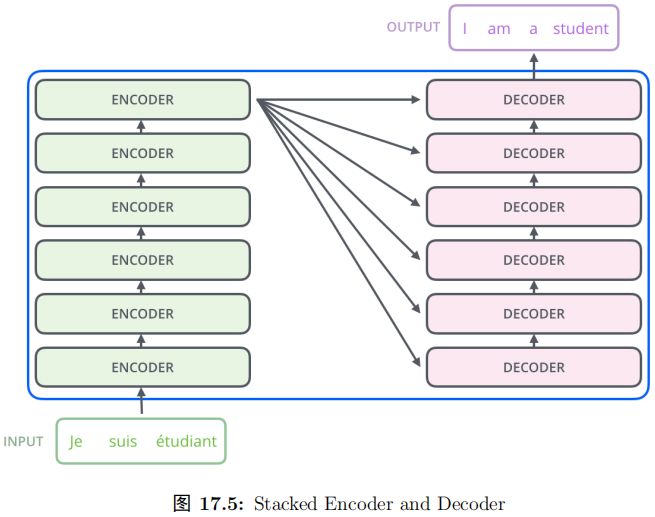
再展开一点,Encoder 由很多 (6 个) 结构一样的 Encoder 堆叠 (stack) 而成,Decoder 也是一样。如图15.53所示。注意:每一个 Encoder 的输入是下一层 Encoder输出,最底层 Encoder 的输入是原始的输入 (法语句子);Decoder 也是类似,但是最后一层 Encoder 的输出会输入给每一个 Decoder 层,这是 Attention 机制的要求。
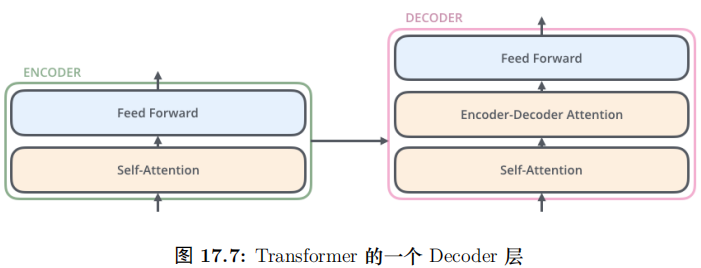
每一层的 Encoder 都是相同的结构,它有一个 Self-Attention 层和一个前馈网络(全连接网络) 组成,15.54如图所示。每一层的 Decoder 也是相同的结果,它除了 Self-Attention 层和全连接层之外还多了一个普通的 Attention 层,这个 Attention 层使得 Decoder 在解码时会考虑最后一层 Encoder 所有时刻的输出。它的结构如图17.3所示。
加入 Tensor
前面的图示只是说明了 Transformer 的模块,接下来我们加入 Tensor,了解这些模块是怎么串联起来的。
输入的句子是一个词 (ID) 的序列,我们首先通过 Embedding 把它变成一个连续稠密的向量,如图17.4所示。
Embedding 之后的序列会输入 Encoder,首先经过 Self-Attention 层然后再经过全连接层,如图17.5所示。
我们在计算 zi 是需要依赖所有时刻的输入 x1, ..., xn,不过我们可以用矩阵运算一下子把所有的 zi 计算出来 (后面介绍)。而全连接网络的计算则完全是独立的,计算 i 时刻的输出只需要输入 zi 就足够了,因此很容易并行计算。
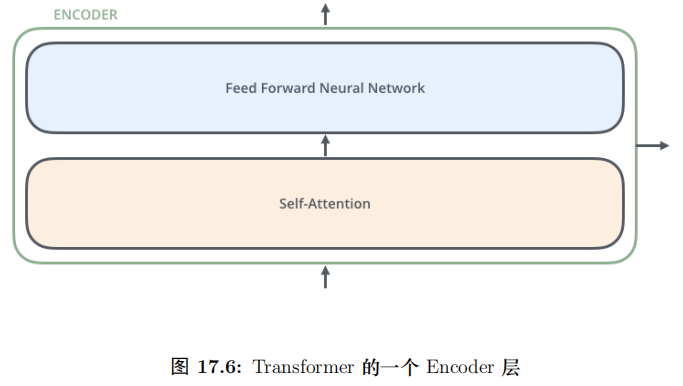
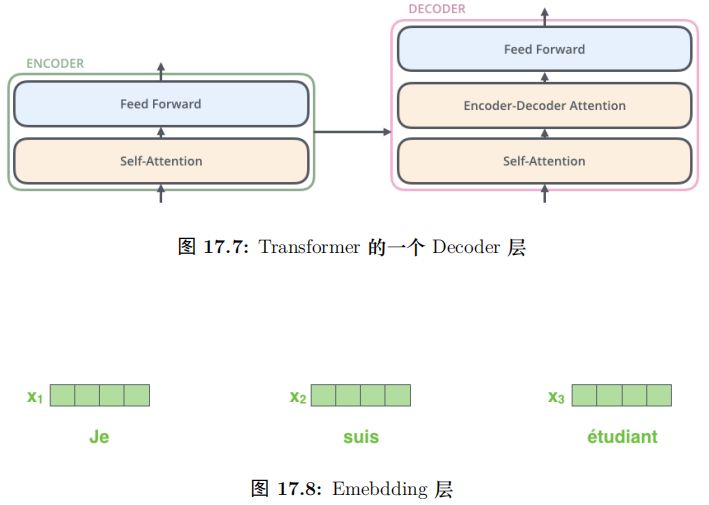
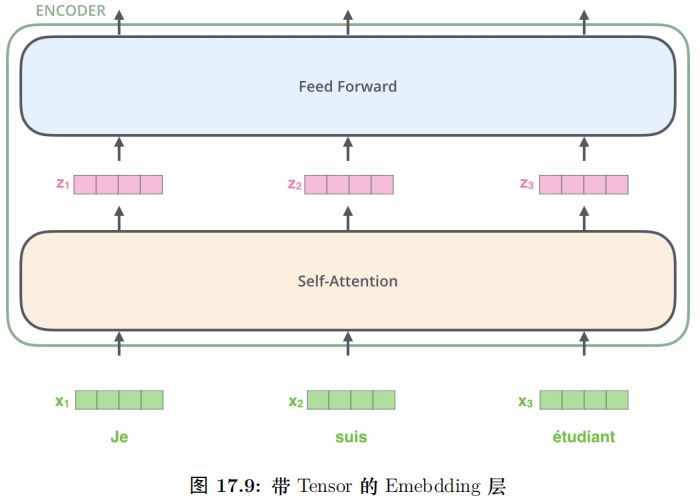
图17.6更加明确的表达了这一点。图中 Self-Attention 层是一个大的方框,表示它的输入是所有的 x1, ..., xn,输出是 z1, ..., zn。而全连接层每个时刻是一个方框,表示计算 ri 只需要 zi。此外,前一层的输出 r1, ...,rn 直接输入到下一层。
Self-Attention 简介
比如我们要翻译如下句子”The animal didn’t cross the street because it was too tired”(这个动物无法穿越马路,因为它太类了)。这里的 it 到底指代什么呢,是animal 还是 street?要知道具体的指代,我们需要在理解 it 的时候同时关注所有的单词,重点是 animal、street 和 tired,然后根据知识 (常识) 我们知道只有 animal 才能tired,而 stree 是不能 tired 的。Self-Attention 运行 Encoder 在编码一个词的时候考虑句子中所有其它的词,从而确定怎么编码当前词。如果把 tired 换成 narrow,那么it 就指代的是 street 了。
而 LSTM(即使是双向的) 是无法实现上面的逻辑的。为什么呢?比如前向的
LSTM,我们在编码 it 的时候根本没有看到后面是 tired 还是 narrow,所有它无法把it 编码成哪个词。而后向的 LSTM 呢?当然它看到了 tired,但是到 it 的时候它还没有看到 animal 和 street 这两个单词,当然就更无法编码 it 的内容了。
当然多层的 LSTM 理论上是可以编码这个语义的,它需要下层的 LSTM 同时编码了 animal 和 street 以及 tired 三个词的语义,然后由更高层的 LSTM 来把 it 编码成 animal 的语义。但是这样模型更加复杂。
下图17.7是模型的最上一层 (下标 0 是第一层,5 是第六层)Encoder 的Attention可视化图。这是 tensor2tensor 这个工具输出的内容。我们可以看到,在编码 it 的时候有一个 Attention Head(后面会讲到) 注意到了Animal,因此编码后的 it 有 Animal的语义。
Self-Attention 详细介绍
下面我们详细的介绍 Self-Attention 是怎么计算的,首先介绍向量的形式逐个时刻计算,这便于理解,接下来我们把它写出矩阵的形式一次计算所有时刻的结果。
对于输入的每一个向量 (第一层是词的 Embedding,其它层是前一层的输出),我们首先需要生成 3 个新的向量 Q、K 和 V,分别代表查询 (Query) 向量、Key 向量和 Value 向量。Q 表示为了编码当前词,需要去注意 (attend to) 其它 (其实也包括它自己) 的词,我们需要有一个查询向量。而 Key 向量可以任务是这个词的关键的用于被检索的信息,而 Value 向量是真正的内容。
我们对比一些普通的 Attention(Luong 2015),使用内积计算 energy 的情况。如图17.8所示,在这里,每个向量的 Key 和 Value 向量都是它本身,而 Q 是当前隐状态 ht,计算 energy etj 的时候我们计算 Q(ht) 和Key(barhj)。然后用 softmax 变成概率,最后把所有的 barhj 加权平均得到 context 向量。
而 Self-Attention 里的 Query 不是隐状态,并且来自当前输入向量本身,因此叫作 Self-Attention。另外 Key 和 Value 都不是输入向量,而是输入向量做了一下线性变换。
当然理论上这个线性变换矩阵可以是 Identity 矩阵,也就是使得Key=Value=输入向量。因此可以认为普通的 Attention 是这里的特例。这样做的好处是系统可以学习的,这样它可以根据数据从输入向量中提取最适合作为 Key(可以看成一种索引)和 Value 的部分。类似的,Query 也是对输入向量做一下线性变换,它让系统可以根据任务学习出最适合的 Query,从而可以注意到 (attend to) 特定的内容。
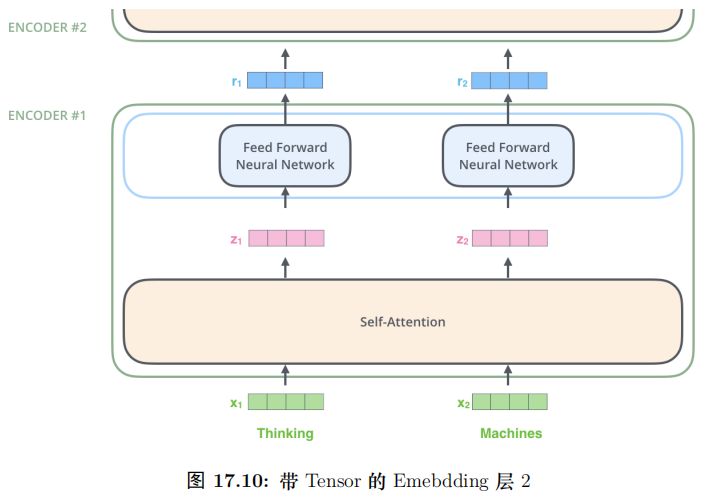
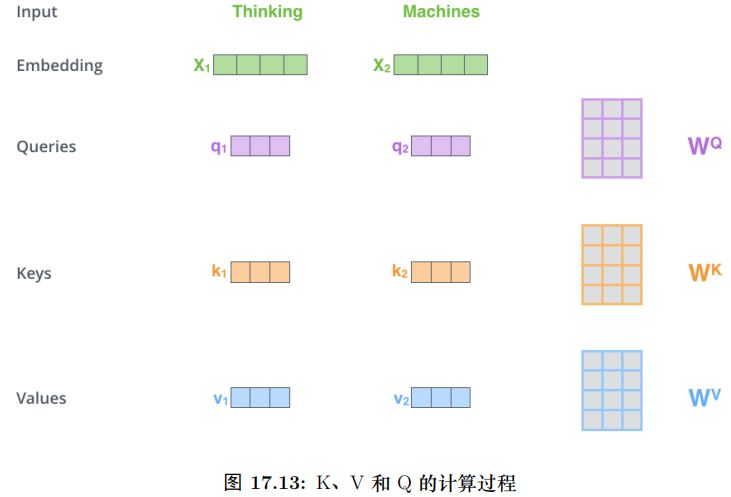
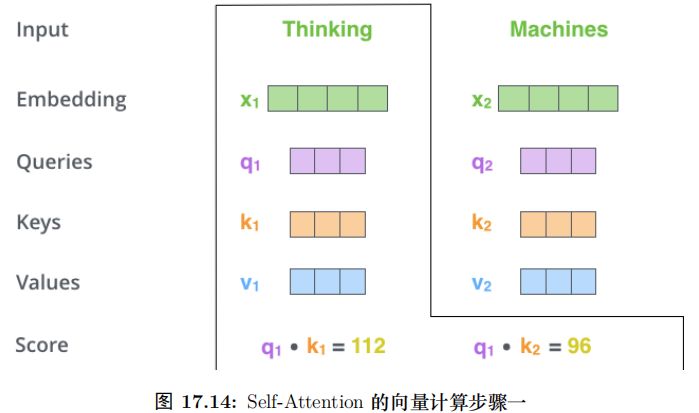
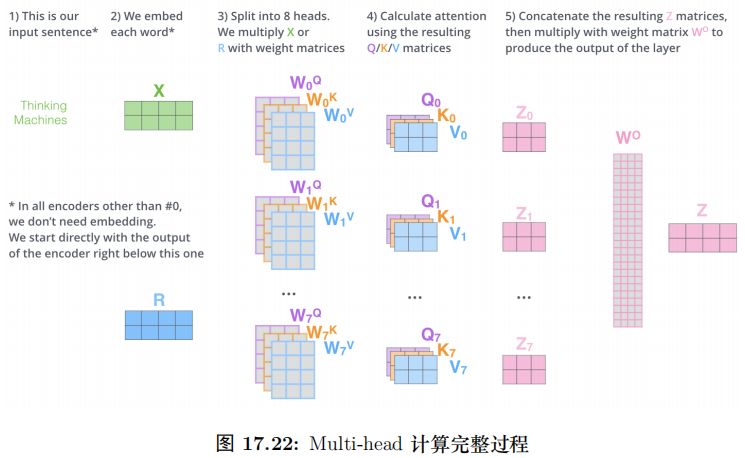
具体的计算过程如图17.9所示。比如图中的输入是两个词”thinking” 和”machines”,我们对它们进行Embedding(这是第一层,如果是后面的层,直接输入就是向量了),得到向量 x1, x2。接着我们用 3 个矩阵分别对它们进行变换,得到向量 q1, k1, v1 和q2, k2, v2。比如 q1 = x1WQ,图中 x1 的 shape 是 1x4,WQ 是 4x3,得到的 q1 是 1x3。其它的计算也是类似的,为了能够使得 Key 和 Query 可以内积,我们要求 WK 和WQ 的 shape 是一样的,但是并不要求 WV 和它们一定一样 (虽然实际论文实现是一样的)。每个时刻 t 都计算出 Qt, Kt, Vt 之后,我们就可以来计算 Self-Attention 了。以第一个时刻为了,我们首先计算 q1 和 k1, k2 的内积,得到 score,过程如图17.10所示。
接下来使用 softmax 把得分变成概率,注意这里把得分除以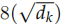 之后再计算的 softmax,根据论文的说法,这样计算梯度时会更加文档 (stable)。计算过程如图17.11所示。
之后再计算的 softmax,根据论文的说法,这样计算梯度时会更加文档 (stable)。计算过程如图17.11所示。

接下来用 softmax 得到的概率对所有时刻的 V 求加权平均,这样就可以认为得到的向量根据 Self-Attention 的概率综合考虑了所有时刻的输入信息,计算过程如图17.12所示。
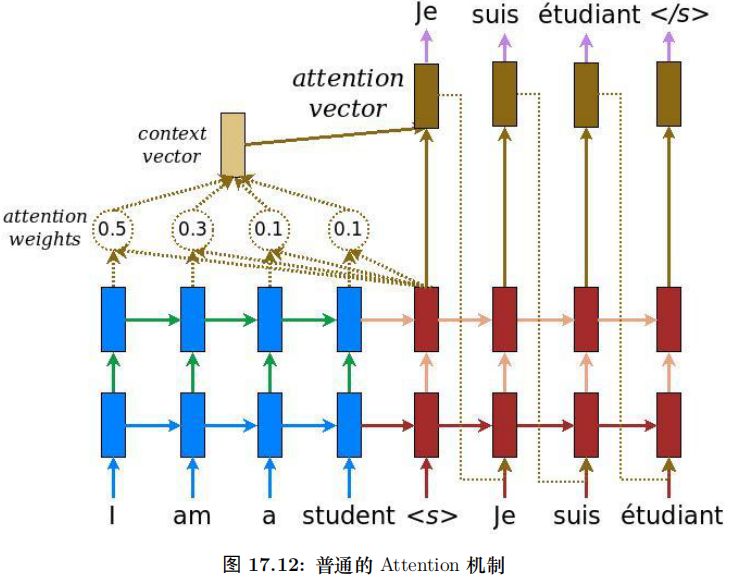
这里只是演示了计算第一个时刻的过程,计算其它时刻的过程是完全一样的。
矩阵计算
前面介绍的方法需要一个循环遍历所有的时刻 t 计算得到 zt,我们可以把上面的向量计算变成矩阵的形式,从而一次计算出所有时刻的输出,这样的矩阵运算可以充分利用硬件资源 (包括一些软件的优化),从而效率更高。
第一步还是计算 Q、K 和 V,不过不是计算某个时刻的 qt, kt, vt 了,而是一次计算所有时刻的 Q、K 和 V。
计算过程如图17.13所示。这里的输入是一个矩阵,矩阵的第 i 行表示第 i 个时刻的输入 xi。
接下来就是计算 Q 和 K 得到 score,然后除以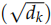 ,然后再 softmax,最后加权平均得到输出。全过程如图17.14所示。
,然后再 softmax,最后加权平均得到输出。全过程如图17.14所示。
Multi-Head Attention
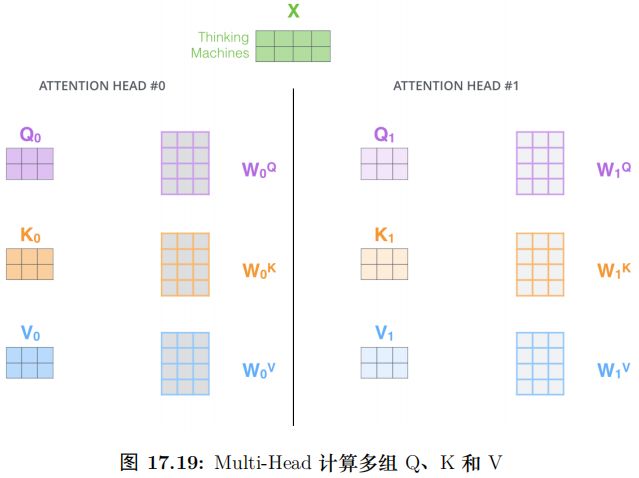
这篇论文还提出了 Multi-Head Attention 的概念。其实很简单,前面定义的一组 Q、K 和 V 可以让一个词 attend to 相关的词,我们可以定义多组 Q、K 和 V,它们分别可以关注不同的上下文。
计算 Q、K 和 V 的过程还是一样,这不过现在变换矩阵从一组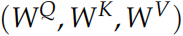
变成了多组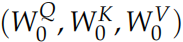 ,
,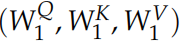 ,...。如图所示。
,...。如图所示。
对于输入矩阵 (time_step, num_input),每一组 Q、K 和 V 都可以得到一个输
出矩阵 Z(time_step, num_features)。如图17.16所示。
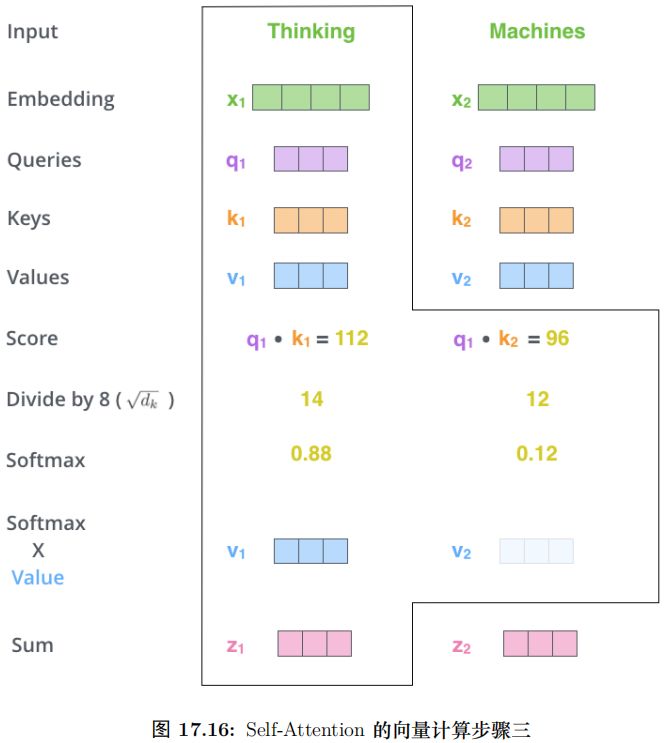
但是后面的全连接网络需要的输入是一个矩阵而不是多个矩阵,因此我们可以
把多个 head 输出的 Z 按照第二个维度拼接起来,但是这样的特征有一些多,因此Transformer 又用了一个线性变换 (矩阵 WO) 对它进行了压缩。这个过程如图17.17所示。
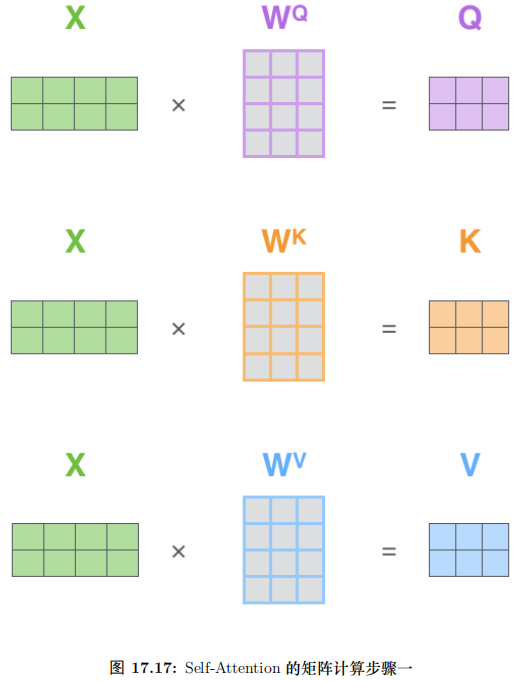
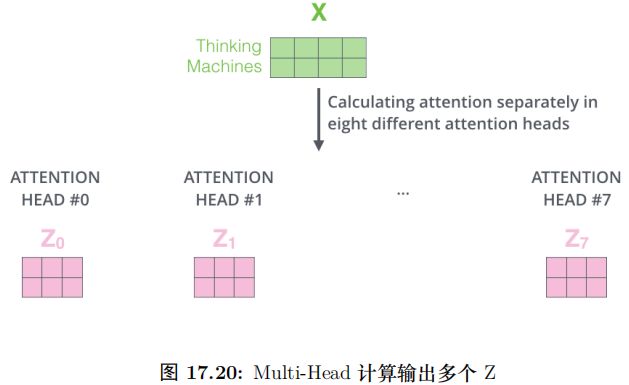
上面的步骤涉及很多步骤和矩阵运算,我们用一张大图把整个过程表示出来,如图17.18所示。我们已经学习过来 Transformer 的 Self-Attention 机制,下面我们通过一个具体的例子来看看不同的 Attention Head 到底学习到了什么样的语义。
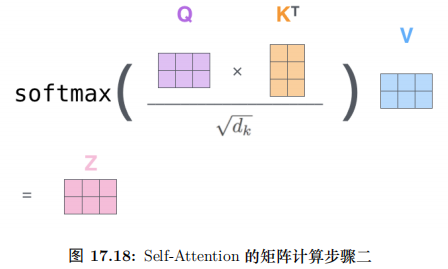
图17.19是一个 Attention Head 学习到的语义,我们可以看到对于 it 一个 Head会注意到”the animal” 而另外一个 Head 会注意到”tired”。
如果把所有的 Head 混在一起,如图17.20所示,那么就很难理解它到底注意的是什么内容。从上面两图的对比也能看出使用多个 Head 的好处——每个 Head(在数据的驱动下) 学习到不同的语义。
位置编码 (Positional Encoding)
注意:这是原始论文使用的位置编码方法,而在 BERT 模型里,使用的是简单的可以学习的 Embedding,和 Word Embedding 一样,只不过输入是位置而不是词而已。
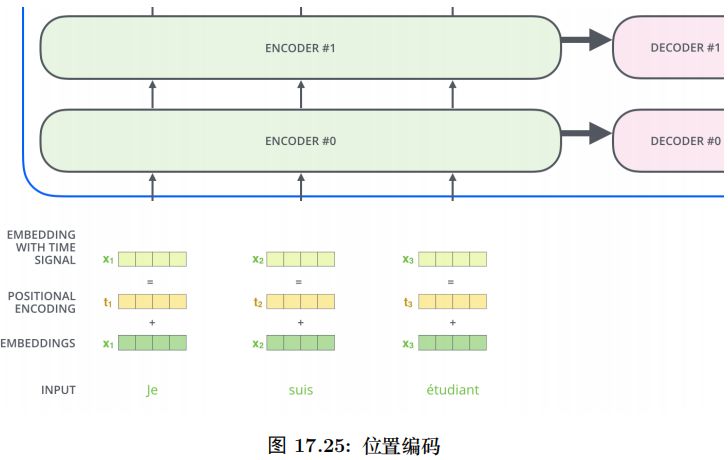
我们的目的是用 Self-Attention 替代 RNN,RNN 能够记住过去的信息,这可以通过 Self-Attention“实时”的注意相关的任何词来实现等价 (甚至更好) 的效果。RNN还有一个特定就是能考虑词的顺序 (位置) 关系,一个句子即使词完全是相同的但是语义可能完全不同,比如” 北京到上海的机票” 与” 上海到北京的机票”,它们的语义就有很大的差别。我们上面的介绍的 Self-Attention 是不考虑词的顺序的,如果模型参数固定了,上面两个句子的北京都会被编码成相同的向量。但是实际上我们可以期望这两个北京编码的结果不同,前者可能需要编码出发城市的语义,而后者需要包含目的城市的语义。而 RNN 是可以 (至少是可能) 学到这一点的。当然 RNN 为了实现这一点的代价就是顺序处理,很难并行。
为了解决这个问题,我们需要引入位置编码,也就是 t 时刻的输入,除了Embedding 之外 (这是与位置无关的),我们还引入一个向量,这个向量是与 t 有关的,我们把 Embedding 和位置编码向量加起来作为模型的输入。这样的话如果两个词在不同的位置出现了,虽然它们的 Embedding 是相同的,但是由于位置编码不同,最终得到的向量也是不同的。
位置编码有很多方法,其中需要考虑的一个重要因素就是需要它编码的是相对位置的关系。比如两个句子:” 北京到上海的机票” 和” 你好,我们要一张北京到上海的机票”。显然加入位置编码之后,两个北京的向量是不同的了,两个上海的向量也是不同的了,但是我们期望 Query(北京 1)*Key(上海 1) 却是等于 Query(北京 2)*Key(上海 2) 的。具体的编码算法我们在代码部分再介绍。
位置编码加入模型如图17.21所示。

一个具体的位置编码的例子如图17.22所示。
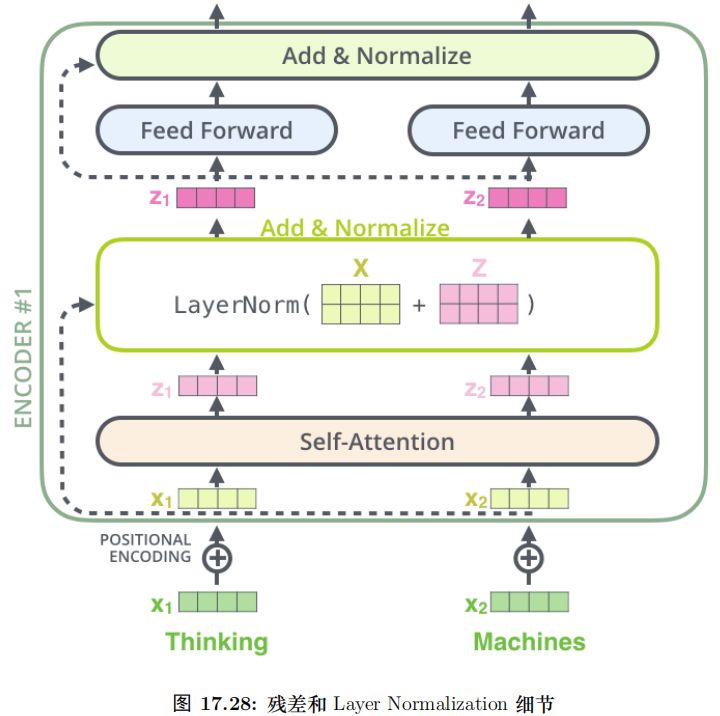
残差连接
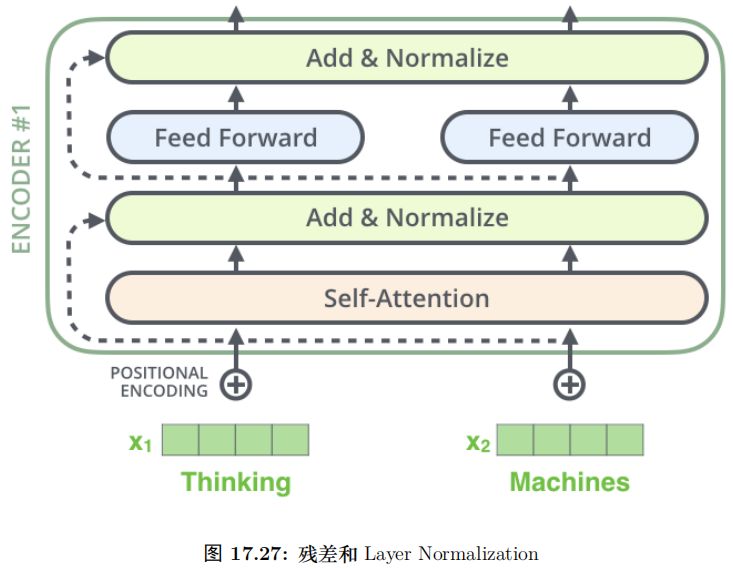
每个 Self-Attention 层都会加一个残差连接,然后是一个 LayerNorm 层,如图17.23所示。


图17.24展示了更多细节:输入 x1, x2 经 self-attention 层之后变成 z1, z2,然后和残差连接的输入 x1, x2 加起来,然后经过 LayerNorm 层输出给全连接层。全连接层也是有一个残差连接和一个 LayerNorm 层,最后再输出给上一层。
Decoder 和 Encoder 是类似的,如图17.25所示,区别在于它多了一个EncoderDecoder Attention 层,这个层的输入除了来自 Self-Attention 之外还有 Encoder 最后一层的所有时刻的输出。
Encoder-Decoder Attention 层的 Query 来自下一层,而 Key 和 Value 则来自Encoder 的输出。
代码
本节内容来自
http://nlp.seas.harvard.edu/2018/04/03/attention.html。读者可以从https://github.com/harvardnlp/annotated-transformer.git 下载代码。这篇文章原名叫作《The Annotated Transformer》。相当于原始论文的读书笔记,但是不同之处在于它不但详细的解释论文,而且还用代码实现了论文的模型。
注意:本书并不没有完全翻译这篇文章,而是根据作者自己的理解来分析和阅读其源代码。而 Transformer 的原来在前面的图解部分已经分析的很详细了,因此这里关注的重点是代码。网上有很多 Transformer 的源代码,也有一些比较大的库包含了Transformer 的实现,比如 Tensor2Tensor 和 OpenNMT 等等。作者选择这个实现的原因是它是一个单独的 ipynb 文件,如果我们要实际使用非常简单,复制粘贴代码就行了。而 Tensor2Tensor 或者 OpenNMT 包含了太多其它的东西,做了过多的抽象。
虽然代码质量和重用性更好,但是对于理解论文来说这是不必要的,并且增加了理解的难度。
运行
这里的代码需要 PyTorch-0.3.0,所以建议读者使用 virtualenv 安装。另外为了在Jupyter notebook 里使用这个 virtualenv,需要执行如下命令:

背景介绍
前面提到过 RNN 等模型的缺点是需要顺序计算,从而很难并行。因此出现了Extended Neural GPU、ByteNet 和 ConvS2S 等网络模型。这些模型都是以 CNN 为基础,这比较容易并行。但是和 RNN 相比,它较难学习到长距离的依赖关系。
本文的 Transformer 使用了 Self-Attention 机制,它在编码每一词的时候都能够注意 (attend to) 整个句子,从而可以解决长距离依赖的问题,同时计算 Self-Attention可以用矩阵乘法一次计算所有的时刻,因此可以充分利用计算资源 (CPU/GPU 上的矩阵运算都是充分优化和高度并行的)。
模型结构
目前的主流神经序列转换 (neural sequence transduction) 模型都是基于 EncoderDecoder 结构的。所谓的序列转换模型就是把一个输入序列转换成另外一个输出序列,它们的长度很可能是不同的。比如基于神经网络的机器翻译,输入是法语句子,输出是英语句子,这就是一个序列转换模型。类似的包括文本摘要、对话等问题都可以看成序列转换问题。我们这里主要关注机器翻译,但是任何输入是一个序列输出是另外一个序列的问题都可以考虑使用 Encoder-Decoder 模型。
Encoder 讲输入序列 (x1, ..., xn) 映射 (编码) 成一个连续的序列 z = (z1, ..., zn)。而Decoder 根据 z 来解码得到输出序列 y1, ..., ym。Decoder 是自回归的 (auto-regressive)——它会把前一个时刻的输出作为当前时刻的输入。
Encoder-Decoder 结构模型的代码如下:


EncoderDecoder 定义了一种通用的 Encoder-Decoder 架构,具体的 Encoder、Decoder、src_embed、target_embed 和 generator 都是构造函数传入的参数。这样我们做实验更换不同的组件就会更加方便。

注意:Generator 返回的是 softmax 的 log 值。在 PyTorch 里为了计算交叉熵损失,有两种方法。第一种方法是使用 nn.CrossEntropyLoss(),一种是使用 NLLLoss()。第一种方法更加容易懂,但是在很多开源代码里第二种更常见,原因可能是它后来才有,大家都习惯了使用 NLLLoss。
我们先看 CrossEntropyLoss,它就是计算交叉熵损失函数,比如:

比如上面的代码,假设是 5 分类问题,x 表示模型的输出 logits(batch=1),而 y 是真实分类的下标 (0-4)。
实际的计算过程为:
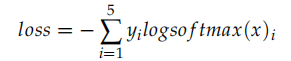
比如 logits 是 [0,1,2,3,4],真实分类是 3,那么上式就是:
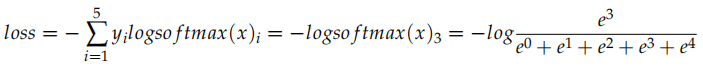
因此我们也可以使用 NLLLoss() 配合 F.log_softmax 函数 (或者nn.LogSoftmax,这不是一个函数而是一个 Module 了) 来实现一样的效果:

NLLLoss(Negative Log Likelihood Loss) 是计算负 log 似然损失。它输入的 x 是log_softmax 之后的结果 (长度为 5 的数组),y 是真实分类 (0-4),输出就是 x[y]。因此上面的代码
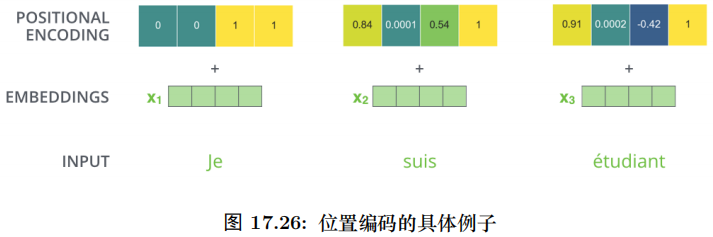
Transformer 模型也是遵循上面的架构,只不过它的 Encoder 是 N(6) 个 EncoderLayer 组成,每个 EncoderLayer 包含一个 Self-Attention SubLayer 层和一个全连接SubLayer 层。而它的 Decoder 也是 N(6) 个 DecoderLayer 组成,每个 DecoderLayer包含一个 Self-Attention SubLayer 层、Attention SubLayer 层和全连接 SubLayer 层。如图17.26所示。
Encoder 和 Decoder Stack
前面说了 Encoder 和 Decoder 都是由 N 个相同结构的 Layer 堆积 (stack) 而成。因此我们首先定义 clones 函数,用于克隆相同的 SubLayer。

这里使用了 nn.ModuleList,ModuleList 就像一个普通的 Python 的 List,我们可以使用下标来访问它,它的好处是传入的 ModuleList 的所有 Module 都会注册的PyTorch 里,这样 Optimizer 就能找到这里面的参数,从而能够用梯度下降更新这些参数。但是 nn.ModuleList 并不是 Module(的子类),因此它没有 forward 等方法,我们通常把它放到某个 Module 里。
接下来我们定义 Encoder:
class Encoder(nn.Module):
"Encoder是N个EncoderLayer的stack"
def __init__(self, layer, N):
super(Encoder, self).__init__()
# layer是一个SubLayer,我们clone N个
self.layers = clones(layer, N)
# 再加一个LayerNorm层
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"逐层进行处理"
for layer in self.layers:
x = layer(x, mask)
# 最后进行LayerNorm,后面会解释为什么最后还有一个LayerNorm。
return self.norm(x)
Encoder 就是 N 个 SubLayer 的 stack,最后加上一个 LayerNorm。我们来看 Layer-Norm:
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
LayerNorm 我们以前介绍过,代码也很简单,这里就不详细介绍了。注意 LayerNormalization 不是 Batch Normalization。
如图17.26所示,原始论文的模型为:
x -> attention(x) -> x+self-attention(x) -> layernorm(x+self-attention(x))
=> y
y -> dense(y) -> y+dense(y) -> layernorm(y+dense(y)) => z(输入下一层)
这里稍微做了一点修改,在 self-attention 和 dense 之后加了一个 dropout 层。另外一个不同支持就是把 layernorm 层放到前面了。这里的模型为:
x -> layernorm(x) -> attention(layernorm(x)) -> x + attention(layernorm(x))=> y
y -> layernorm(y) -> dense(layernorm(y)) -> y+dense(layernorm(y))
原始论文的 layernorm 放在最后;而这里把它放在最前面并且在 Encoder 的最后一层再加了一个 layernorm,因此这里的实现和论文的实现基本是一致的,只是给最底层的输入 x 多做了一个 layernorm,而原始论文是没有的。下面是 Encoder 的forward 方法,这样对比读者可能会比较清楚为什么 N 个EncoderLayer 处理完成之后还需要一个 LayerNorm。
def forward(self, x, mask):
"逐层进行处理"
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
不管是 Self-Attention 还是全连接层,都首先是 LayerNorm,然后是 Self-Attention/Dense,然后是 Dropout,最好是残差连接。这里面有很多可以重用的代码,我们把它封装成 SublayerConnection。
class SublayerConnection(nn.Module):
"""
LayerNorm + sublayer(Self-Attenion/Dense) + dropout + 残差连接
为了简单,把LayerNorm放到了前面,这和原始论文稍有不同,原始论文LayerNorm在最后。
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"sublayer是传入的参数,参考DecoderLayer,它可以当成函数调用,这个函数的有一个输入参数"
return x + self.dropout(sublayer(self.norm(x)))
这个类会构造 LayerNorm 和 Dropout,但是 Self-Attention 或者 Dense 并不在这里构造,还是放在了 EncoderLayer 里,在 forward 的时候由 EncoderLayer 传入。这样的好处是更加通用,比如 Decoder 也是类似的需要在 Self-Attention、Attention 或者 Dense 前面后加上 LayerNorm 和 Dropout 以及残差连接,我们就可以复用代码。但是这里要求传入的 sublayer 可以使用一个参数来调用的函数 (或者有 __call__)。
有了这些代码之后,EncoderLayer 就很简单了:
class EncoderLayer(nn.Module):
"EncoderLayer由self-attn和feed forward组成"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
为了复用,这里的 self_attn 层和 feed_forward 层也是传入的参数,这里只构造两个 SublayerConnection。forward 调用 sublayer[0](SublayerConnection) 的 __call__方法,最终会调到它的 forward 方法,而这个方法需要两个参数,一个是输入 Tensor,一个是一个 callable,并且这个 callable 可以用一个参数来调用。而 self_attn 函数需要 4 个参数 (Query 的输入,Key 的输入,Value 的输入和 Mask),因此这里我们使用lambda 的技巧把它变成一个参数 x 的函数 (mask 可以看成已知的数)。因为 lambda的形参也叫 x,读者可能难以理解,我们改写一下:
def forward(self, x, mask):
z = lambda y: self.self_attn(y, y, y, mask)
x = self.sublayer[0](x, z)
return self.sublayer[1](x, self.feed_forward)
self_attn 有 4 个参数,但是我们知道在 Encoder 里,前三个参数都是输入 y,第四个参数是 mask。这里 mask 是已知的,因此我们可以用 lambda 的技巧它变成一个参数的函数 z = lambda y: self.self_attn(y, y, y, mask),这个函数的输入是 y。
self.sublayer[0] 是个 callable,self.sublayer[0](x, z) 会调用 self.sublayer[0].__call__(x,z),然后会调用 SublayerConnection.forward(x, z),然后会调用 sublayer(self.norm(x)),sublayer 就是传入的参数 z,因此就是 z(self.norm(x))。z 是一个 lambda,我们可以先简单的看成一个函数,显然这里要求函数 z 的输入是一个参数。
理解了 Encoder 之后,Decoder 就很简单了。
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
Decoder 也是 N 个 DecoderLayer 的 stack,参数 layer 是 DecoderLayer,它也是一个callable,最终 __call__ 会调用 DecoderLayer.forward 方法,这个方法 (后面会介绍)需要 4 个参数,输入 x,Encoder 层的输出 memory,输入 Encoder 的 Mask(src_mask)和输入 Decoder 的 Mask(tgt_mask)。所有这里的 Decoder 的 forward 也需要这 4 个参数。
class DecoderLayer(nn.Module):
"Decoder包括self-attn, src-attn, 和feed forward "
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
DecoderLayer 比 EncoderLayer 多了一个 src-attn 层,这是 Decoder 时 attend toEncoder 的输出 (memory)。src-attn 和 self-attn 的实现是一样的,只不过使用的Query,Key 和 Value 的输入不同。普通的 Attention(src-attn) 的 Query 是下层输入进来的 (来自 self-attn 的输出),Key 和 Value 是 Encoder 最后一层的输出 memory;而 Self-Attention 的 Query,Key 和 Value 都是来自下层输入进来的。
Decoder 和 Encoder 有一个关键的不同:Decoder 在解码第 t 个时刻的时候只能使用 1...t 时刻的输入,而不能使用 t+1 时刻及其之后的输入。因此我们需要一个函数来产生一个 Mask 矩阵,代码如下:
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
我们阅读代码之前先看它的输出:
print(subsequent_mask(5))
# 输出
1 0 0 0 0
1 1 0 0 0
1 1 1 0 0
1 1 1 1 0
1 1 1 1 1
我们发现它输出的是一个方阵,对角线和下面都是 1。第一行只有第一列是 1,它的意思是时刻 1 只能 attend to 输入 1,第三行说明时刻 3 可以 attend to 1,2,3 而不能attend to4,5 的输入,因为在真正 Decoder 的时候这是属于 Future 的信息。知道了这个函数的用途之后,上面的代码就很容易理解了。代码首先使用 triu 产生一个上三角阵:
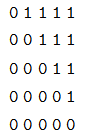
然后需要把 0 变成 1,把 1 变成 0,这可以使用 matrix == 0 来实现。
###MultiHeadedAttention
Attention(包括 Self-Attention 和普通的 Attention) 可以看成一个函数,它的输入是Query,Key,Value 和 Mask,输出是一个 Tensor。其中输出是 Value 的加权平均,而权重来自 Query 和 Key 的计算。
具体的计算如图17.27所示,计算公式为:
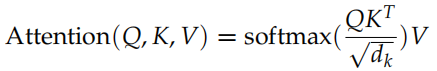
代码为:
def attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
我们使用一个实际的例子跟踪一些不同 Tensor 的 shape,然后对照公式就很容易理解。比如 Q 是 (30,8,33,64),其中 30 是 batch,8 是 head 个数,33 是序列长度,64 是每个时刻的特征数。K 和 Q 的 shape 必须相同的,而 V 可以不同,但是这里的实现 shape 也是相同的。
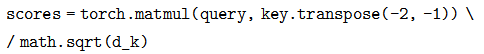
上面的代码实现 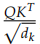 ,和公式里稍微不同的是,这里的 Q 和 K 都是 4d 的 Tensor,包括 batch 和 head 维度。matmul 会把 query 和 key 的最后两维进行矩阵乘法,这样效率更高,如果我们要用标准的矩阵 (二维 Tensor) 乘法来实现,那么需要遍历 batch维和 head 维:
,和公式里稍微不同的是,这里的 Q 和 K 都是 4d 的 Tensor,包括 batch 和 head 维度。matmul 会把 query 和 key 的最后两维进行矩阵乘法,这样效率更高,如果我们要用标准的矩阵 (二维 Tensor) 乘法来实现,那么需要遍历 batch维和 head 维:

而上面的写法一次完成所有这些循环,效率更高。输出的 score 是 (30, 8, 33, 33),前面两维不看,那么是一个 (33, 33) 的 attention 矩阵 a,aij 表示时刻 i attend to j 的得分 (还没有经过 softmax 变成概率)。
接下来是 scores.masked_fill(mask == 0, -1e9),用于把 mask 是 0 的变成一个很小的数,这样后面经过 softmax 之后的概率就很接近零 (但是理论上还是用来很少一点点未来的信息)。
这里 mask 是 (30, 1, 1, 33) 的 tensor,因为 8 个 head 的 mask 都是一样的,所有第二维是 1,masked_fill 时使用 broadcasting 就可以了。这里是 self-attention 的mask,所以每个时刻都可以 attend 到所有其它时刻,所有第三维也是 1,也使用broadcasting。如果是普通的 mask,那么 mask 的 shape 是 (30, 1, 33, 33)。这样讲有点抽象,我们可以举一个例子,为了简单,我们假设 batch=2, head=8。
第一个序列长度为 3,第二个为 4,那么 self-attention 的 mask 为 (2, 1, 1, 4),我们可以用两个向量表示:
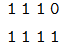
它的意思是在 self-attention 里,第一个序列的任一时刻可以 attend to 前 3 个时刻(因为第 4 个时刻是 padding 的);而第二个序列的可以 attend to 所有时刻的输入。而 Decoder 的 src-attention 的 mask 为 (2, 1, 4, 4),我们需要用 2 个矩阵表示:
第一个序列的mask矩阵
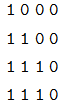
第二个序列的mask矩阵
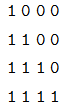
接下来对 score 求 softmax,把得分变成概率 p_attn,如果有 dropout 还对p_attn 进行 Dropout(这也是原始论文没有的)。最后把 p_attn 和 value 相乘。p_attn是 (30, 8, 33, 33),value 是 (30, 8, 33, 64),我们只看后两维,(33x33) x (33x64) 最终得到 33x64。
接下来就是输入怎么变成 Q,K 和 V 了,我们之前介绍过,对于每一个 Head,都使用三个矩阵 WQ, WK, WV 把输入转换成 Q,K 和 V。然后分别用每一个 Head 进行 Self-Attention 的计算,最后把 N 个 Head 的输出拼接起来,最后用一个矩阵 WO把输出压缩一下。具体计算过程为:
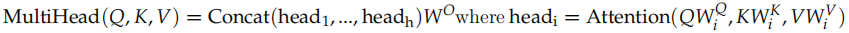
其中,
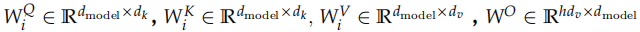
在这里,我们的 Head 个数 h=8,dk = dv = dmodel/h = 64。
详细结构如图17.28所示,输入 Q,K 和 V 经过多个线性变换后得到 N(8) 组Query,Key 和 Value,然后使用 Self-Attention 计算得到 N 个向量,然后拼接起来,最后使用一个线性变换进行降维。
代码如下:
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
# 所有h个head的mask都是相同的
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1)
首先使用线性变换,然后把d_model分配给h个Head,每个head为d_k=d_model/h
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for l, x
in zip(self.linears, (query, key, value))]
# 2) 使用attention函数计算
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3)
把8个head的64维向量拼接成一个512的向量。然后再使用一个线性变换(512,521),shape不变。
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
我们先看构造函数,这里 d_model(512) 是 Multi-Head 的输出大小,因为有 h(8)个 head,因此每个 head 的 d_k=512/8=64。接着我们构造 4 个 (d_model x d_model)的矩阵,后面我们会看到它的用处。最后是构造一个 Dropout 层。
然后我们来看 forward 方法。输入的 mask 是 (batch, 1, time) 的,因为每个 head的 mask 都是一样的,所以先用 unsqueeze(1) 变成 (batch, 1, 1, time),mask 我们前面已经详细分析过了。
接下来是根据输入 query,key 和 value 计算变换后的 Multi-Head 的 query,key和 value。这是通过下面的语句来实现的:
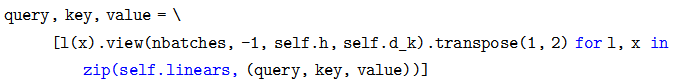
zip(self.linears, (query, key, value)) 是把(self.linears[0],self.linears[1],self.linears[2])和 (query, key, value) 放到一起然后遍历。
我们只看一个 self.linears[0](query)。根据构造函数的定义self.linears[0] 是一个 (512, 512) 的矩阵,而 query 是 (batch, time,512),相乘之后得到的新 query 还是 512(d_model) 维的向量,然后用 view 把它变成(batch, time, 8, 64)。然后 transponse 成 (batch, 8,time,64),这是 attention 函数要求的 shape。分别对应 8 个 Head,每个 Head 的 Query 都是 64 维。
Key 和 Value 的运算完全相同,因此我们也分别得到 8 个 Head 的 64 维的 Key和 64 维的 Value。
接下来调用 attention 函数,得到 x 和 self.attn。其中 x 的 shape 是 (batch, 8,time, 64),而 attn 是 (batch, 8, time, time)。
x.transpose(1, 2) 把 x 变成 (batch, time, 8, 64),然后把它 view 成 (batch, time,512),其实就是把最后 8 个 64 维的向量拼接成 512 的向量。
最后使用 self.linears[-1] 对 x 进行线性变换,因为 self.linears[-1] 是 (512, 512) 的,因此最终的输出还是 (batch, time, 512)。
我们最初构造了 4 个 (512, 512) 的矩阵,前 3 个用于对 query,key 和 value 进行变换,而最后一个对 8 个 head 拼接后的向量再做一次变换。
##MultiHeadedAttention 的应用
在 Transformer 里,有 3 个地方用到了 MultiHeadedAttention:
Encoder 的 Self-Attention 层里,query,key 和 value 都是相同的值,来自下层
的输入。Mask 都是 1(当然 padding 的不算)。
Decoder 的 Self-Attention 层,query,key 和 value 都是相同的值,来自下层的输入。但是 Mask 使得它不能访问未来的输入。
Encoder-Decoder 的普通 Attention,query 来自下层的输入,而 key 和 value 相同,是 Encoder 最后一层的输出,而 Mask 都是 1。
##全连接 SubLayer
除了 Attention 这个 SubLayer 之外,我们还有全连接的 SubLayer,每个时刻的全连接层是可以独立并行计算的 (当然参数是共享的)。全连接层有两个线性变换以及它们之间的 ReLU 激活组成:
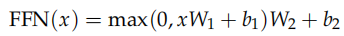
全连接层的输入和输出都是 d_model(512) 维的,中间隐单元的个数是 d_ff(2048)。代码实现非常简单:
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
在两个线性变换之间除了 ReLu 还使用了一个 Dropout。
##Embedding 和 Softmax
输入的词序列都是 ID 序列,我们需要 Embedding。源语言和目标语言都需要Embedding,此外我们需要一个线性变换把隐变量变成输出概率,这可以通过前面的类 Generator 来实现。我们这里实现 Embedding:

代码非常简单,唯一需要注意的就是 forward 处理使用 nn.Embedding 对输入 x 进行Embedding 之外,还除以了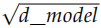 。
。
##Positional Encoding
位置编码的公式为:
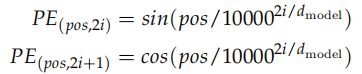
假设输入是 ID 序列长度为 10,如果输入 Embedding 之后是 (10, 512),那么位置编码的输出也是 (10, 512)。上式中 pos 就是位置 (0-9),512 维的偶数维使用 sin 函数,而奇数维使用 cos 函数。这种位置编码的好处是: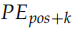 可以表示成 PEpos 的线性函数,这样网络就能容易的学到相对位置的关系。代码为:
可以表示成 PEpos 的线性函数,这样网络就能容易的学到相对位置的关系。代码为:
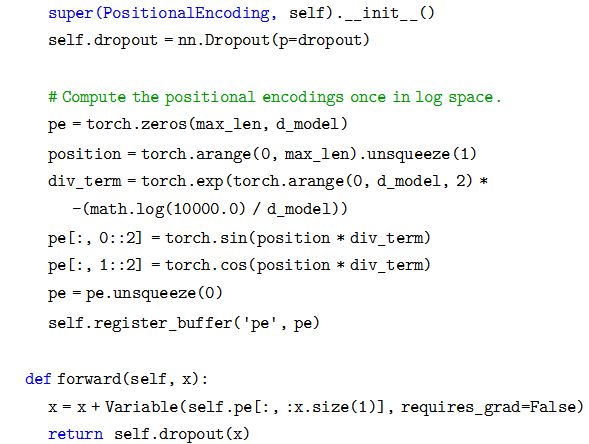
代码细节请读者对照公式,这里值得注意的是调用了 Module.register_buffer 函数。这个函数的作用是创建一个 buffer,比如这里把 pi 保存下来。
register_buffer通常用于保存一些模型参数之外的值,比如在 BatchNorm 中,我们需要保存 running_mean(Moving Average),它不是模型的参数 (不用梯度下降),但是模型会修改它,而且在预测的时候也要使用它。这里也是类似的,pe 是一个提前计算好的常量,我们在 forward 要用到它。我们在构造函数里并没有把 pe 保存到 self 里,但是在forward 的时候我们却可以直接使用它 (self.pe)。如果我们保存 (序列化) 模型到磁盘的话,PyTorch 框架也会帮我们保存 buffer 里的数据到磁盘,这样反序列化的时候能恢复它们。
完整模型
构造完整模型的函数代码如下:


首先把 copy.deepcopy 命名为 c,这样使下面的代码简洁一点。然后构造 MultiHeadedAttention,PositionwiseFeedForward 和 PositionalEncoding 对象。接着就是构造 EncoderDecoder 对象。它需要 5 个参数:Encoder、Decoder、src-embed、tgt-embed和 Generator。
我们首先后面三个简单的参数,Generator 直接构造就行了,它的作用是把模型的隐单元变成输出词的概率。而 src-embed 是一个 Embeddings 层和一个位置编码层c(position),tgt-embed 也是类似的。
最后我们来看 Decoder(Encoder 和 Decoder 类似的)。Decoder 由 N 个 DecoderLayer 组成,而 DecoderLayer 需要传入 self-attn, src-attn,全连接层和 Dropout。因为所有的 MultiHeadedAttention 都是一样的,因此我们直接 deepcopy 就行;同理所有的 PositionwiseFeedForward 也是一样的网络结果,我们可以 deepcopy 而不要再构造一个。
训练
在介绍训练代码前我们介绍一些Batch类。


Batch构造函数的输入是src和trg,后者可以为None,因为再预测的时候是没有tgt的。我们用一个例子来说明Batch的代码,这是训练阶段的一个Batch,src是(48,20),48是batch大小,而20是最长的句子长度,其它的不够长的都padding成20了。而trg是(48,25),表示翻译后的最长句子是25个词,不足的也 padding过了。
我们首先看src_mask怎么得到,(src!=pad)把src中大于0的时刻置为1,这
样表示它可以 attendto的范围。然后 unsqueeze(-2)把把src_mask变成(48/batch,1,20/time)。它的用法参考前面的attention函数。
对于训练来说 (TeachingForcing模式),Decoder 有一个输入和一个输出。比如句子”
最终得到的 trg_mask 的 shape 是 (48/batch, 24, 24),表示 24 个时刻的 Mask矩阵,这是一个对角线以及之下都是1的矩阵,前面已经介绍过了。
注意src_mask的shape是(batch,1,time),而trg_mask是(batch,time,time)。
因为src_mask的每一个时刻都能attendto所有时刻(padding的除外),一次只需要一个向量就行了,而trg_mask需要一个矩阵。
训练的代码就非常简单了,下面是训练一个Epoch的代码:


它遍历一个 epoch 的数据,然后调用 forward,接着用 loss_compute 函数计算梯度,更新参数并且返回 loss。这里的 loss_compute 是一个函数,它的输入是模型的预测 out,真实的标签序列 batch.trg_y 和 batch 的词个数。实际的实现是MultiGPULossCompute 类,这是一个 callable。本来计算损失和更新参数比较简单,但是这里为了实现多 GPU 的训练,这个类就比较复杂了。
MultiGPULossCompute
这里介绍了 Transformer 最核心的算法,这个代码还包含了 Label Smoothing,BPE等技巧,有兴趣的读者可以自行阅读,本书就不介绍了。
Skip Thought Vector
简介
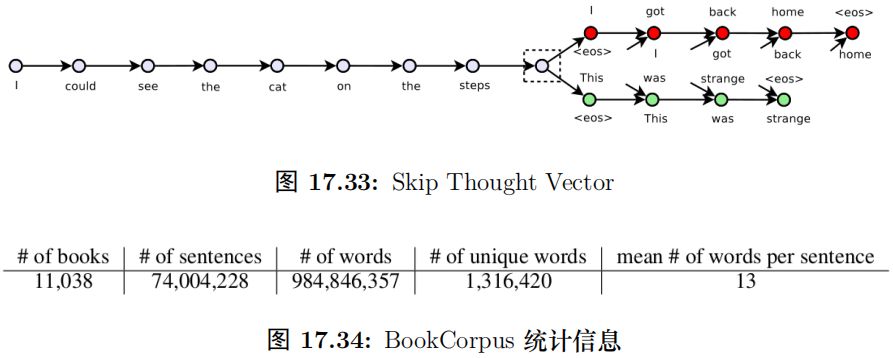
我们之前学习过 word2vec,其中一种模型是 Skip-Gram 模型,根据中心词预测周围的 (context) 词,这样我们可以学到词向量。那怎么学习到句子向量呢?一种很自然想法就是用一个句子预测它周围的句子,这就是 Skip Thought Vector 的思路。它需要有连续语义相关性的句子,比如论文中使用的书籍。一本书由很多句子组成,前后的句子是有关联的。那么我们怎么用一个句子预测另一个句子呢?这可以使用Encoder-Decoder,类似于机器翻译。比如一本书里有 3 个句子”I got back home”、”I could see the cat on the steps”和”This was strange”。我们想用中间的句子”I could see the cat on the steps.” 来预测前后两个句子。
如图15.83所示,输入是句子”I could see the cat on the steps.”,输出是两个句子”Igot back home.” 和”This was strange.”。
我们首先用一个 Encoder(比如 LSTM 或者 GRU) 把输入句子编码成一个向量。而右边是两个 Decoder(我们任务前后是不对称的,因此用两个 Decoder)。因为我们不需要预测 (像机器翻译那样生成一个句子),所以我们只考虑 Decoder 的训练。Decoder 的输入是”
经过训练之后,我们就得到了一个 Encoder(Decoder 不需要了)。给定一个新的句子,我们可以把它编码成一个向量。这个向量可以用于下游 (down stream) 的任务,比如情感分类,语义相似度计算等等。
数据集
和训练 Word2Vec 不同,Word2Vec 只需要提供句子,而 Skip Thought Vector 需要文章 (至少是段落)。论文使用的数据集是 BookCorpus(http://yknzhu.wixsite.com/mbweb),目前网站已经不提供下载链接了!
BookCorpus 的统计信息如图15.84所示,有一万多本书,七千多万个句子。
模型
接下来我们介绍一些论文中使用的模型,注意这是 2015 年的论文,过去好几年了,其实我们是可以使用更新的模型。但是基本的思想还是一样的。Encoder 是一个 GRU。假设句子 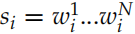 ,t 时刻的隐状态是
,t 时刻的隐状态是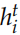 认为编码了字符串
认为编码了字符串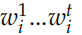 的语义,因此
的语义,因此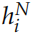 可以看成对整个句子语义的编码。t 时刻 GRU 的计算公式为:
可以看成对整个句子语义的编码。t 时刻 GRU 的计算公式为:
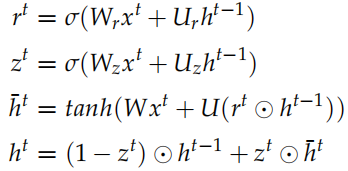
这就是标准的 GRU,其中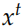 是
是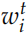 的Embedding 向量,
的Embedding 向量,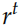 是重置 (reset) 门,
是重置 (reset) 门,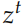 是更新 (update) 门,⊙ 是 element-wise 的乘法。
是更新 (update) 门,⊙ 是 element-wise 的乘法。
Decoder 是一个神经网络语言模型。
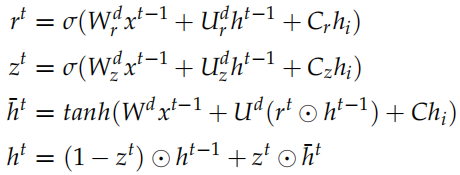
和之前我们在机器翻译里介绍的稍微有一些区别。标准 Encoder-Decoder 里Decoder 每个时刻的输入是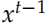 和
和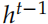 ,Decoder 的初始状态设置为 Encoder 的输出
,Decoder 的初始状态设置为 Encoder 的输出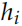 。而这里 Decodert 时刻的输入除了
。而这里 Decodert 时刻的输入除了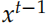 和
和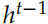
,还有 Encoder 的输出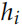 。
。
计算出 Decoder 每个时刻的隐状态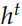 之后,我们在用一个矩阵 V 把它投影到词的空间,输出的是预测每个词的概率分布。注意:预测前一个句子和后一个句子是两个 GRU 模型,它们的参数是不共享的,但是投影矩阵 V 是共享的。当然输入
之后,我们在用一个矩阵 V 把它投影到词的空间,输出的是预测每个词的概率分布。注意:预测前一个句子和后一个句子是两个 GRU 模型,它们的参数是不共享的,但是投影矩阵 V 是共享的。当然输入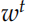 到
到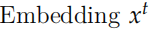 的 Embedding 矩阵也是共享的。和 Word2Vec 对比的话,V 是输出向量 (矩阵) 而这个 Embedding(这里没有起名字) 是输入向量 (矩阵)。
的 Embedding 矩阵也是共享的。和 Word2Vec 对比的话,V 是输出向量 (矩阵) 而这个 Embedding(这里没有起名字) 是输入向量 (矩阵)。
词汇扩展
这篇论文还有一个比较重要的方法就是词汇扩展。因为 BookCorpus 相对于训练Word2Vec 等的语料来说还是太小,很多的词都根本没有在这个语料中出现,因此直接使用的话效果肯定不好。
本文使用了词汇扩展的办法。具体来说我们可以先用海量的语料训练一个
Word2Vec,这样可以把一个词映射到一个语义空间,我们把这个向量叫作 Vw2v。而我们之前训练的得到的输入向量也是把一个词映射到另外一个语义空间,我们记作Vrnn。
我们假设它们之间存在一个线性变换 f :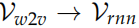 。这个线性变换的参数是矩阵 W,使得
。这个线性变换的参数是矩阵 W,使得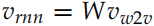 。那怎么求这个变换矩阵 W 呢?因为两个训练语料会有公共的词 (通常训练 word2vec 的语料比 skip vector 大得多,从而词也多得多)。因此我们可以用这些公共的词来寻找 W。寻找的依据是:遍历所有可能的 W,使得Wvw2v 和 vrnn 尽量接近。用数学语言描述就是:
。那怎么求这个变换矩阵 W 呢?因为两个训练语料会有公共的词 (通常训练 word2vec 的语料比 skip vector 大得多,从而词也多得多)。因此我们可以用这些公共的词来寻找 W。寻找的依据是:遍历所有可能的 W,使得Wvw2v 和 vrnn 尽量接近。用数学语言描述就是:
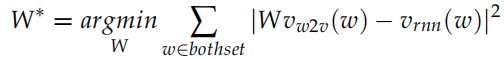
训练细节
首先训练了单向的 GRU,向量的维度是 2400,我们把它叫作 uni-skip 向量。此外还训练了 bi-skip 向量,它是这样得到的:首先训练 1200 维的 uni-skip,然后句子倒过来,比如原来是”aa bb”、”cc dd” 和”ee ff”,我们是用”cc dd” 来预测”aa bb” 以及”eeff”,现在反过来变成”ff ee”、”dd cc” 和”bb aa”。这样也可以训练一个模型,当然也
就得到一个 encoder(两个 decoder 不需要了),给定一个句子我们把它倒过来然后也编码成 1200 为的向量,最后把这个两个 1200 维的向量拼接成 2400 维的向量。模型训练完成之后还需要进行词汇扩展。通过 BookCorpus 学习到了 20,000 个词,而 word2vec 共选择了 930,911 词,通过它们共同的词学习出变换矩阵 W,从而使得我们的 Skip Thought Vector 可以处理 930,911 个词。
实验
为了验证效果,本文把 Sentence Embedding 作为下游任务的输入特征,任务包括分类 (情感分类),SNI(RTE) 等。前者的输入是一个句子,而后者的输入是两个句子。
Semantic relatedness 任务
这里使用了 SICK(SemEval 2014 Task 1,给定两个句子,输出它们的语义相关性 1-5五个分类) 和 Microsoft Paraphrase Corpus(给定两个句子,判断它们是否一个意思/两分类)。
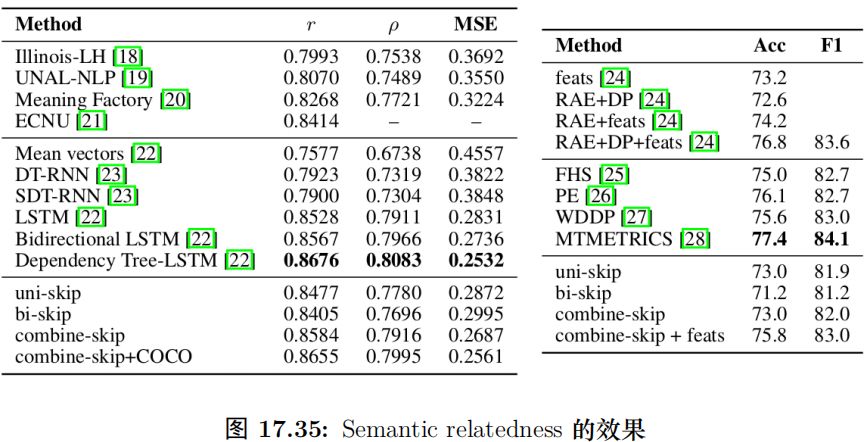
它们的输入是两个句子,输出是分类数。对于输入的两个句子,我们用 SkipThought Vector 把它们编码成两个向量 u 和 v,然后计算 u · v 与 |u − v|,然后把它们拼接起来,最后接一个 logistic regression 层 (全连接加 softmax)。使用这么简单的分类模型的原因是想看看 Sentence Embedding 是否能够学习到复杂的非线性的语义关系。使用结果如图15.85所示。可以看到效果还是非常不错的,和 (当时) 最好的结果差别不大,而那些结果都是使用非常复杂的模型得到结果,而这里只使用了简单的逻辑回归模型。
COCO 图像检索任务
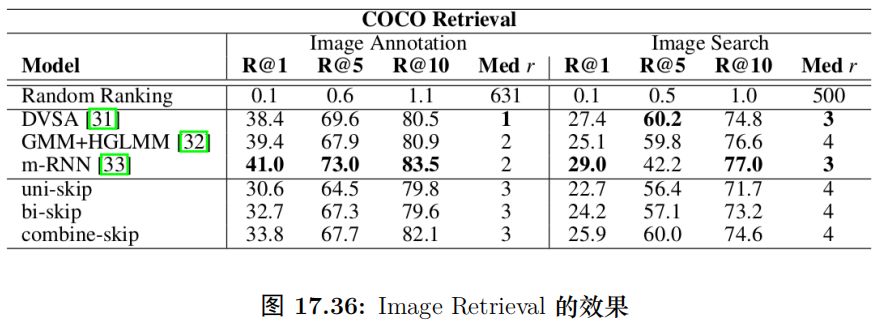
这个任务的输入是一幅图片和一个句子,模型输出的是它们的相关性 (句子是否描述了图片的内容)。句子我们可以用 Skip Thought Vector 编码成一个向量;而图片也可以用预训练的 CNN 编码成一个向量。模型细节这里不再赘述了,最终的结果如图15.86所示。
分类任务
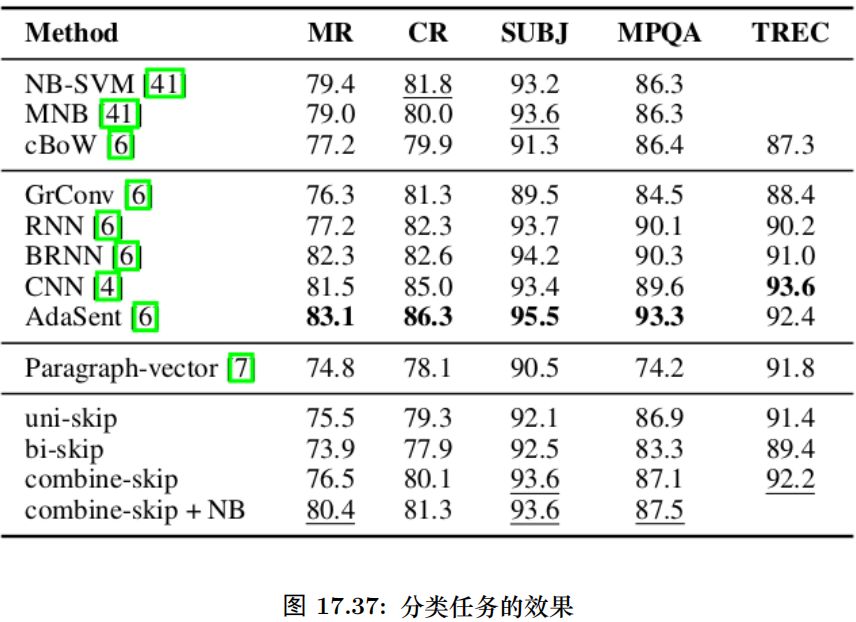
这里比较了 5 个分类任务:电影评论情感分类 (MR), 商品评论情感分类 (CR) [37],主观/客观分类 (SUBJ) [38], 意见分类 (MPQA) 和 TREC 问题类型分类。结果如图15.87所示。
ELMo
简介
ELMo 是 Embeddings from Language Models 的缩写,意思就是语言模型得到的 (句子)Embedding。另外 Elmo 是美国儿童教育电视节目芝麻街 (Sesame Street) 里的小怪兽15.88的名字。原始论文叫做《Deep contextualized word representations》。
这篇论文的想法其实非常非常简单,但是取得了非常好的效果。它的思路是用深度的双向 RNN(LSTM) 在大量未标注数据上训练语言模型,如图15.89所示。然后在实际的任务中,对于输入的句子,我们使用这个语言模型来对它处理,得到输出的向量,因此这可以看成是一种特征提取。但是和普通的 Word2Vec 或者 GloVe 的pretraining 不同,ELMo 得到的 Embedding 是有上下文的。比如我们使用 Word2Vec也可以得到词”bank” 的 Embedding,我们可以认为这个 Embedding 包含了 bank 的语义。但是 bank 有很多意思,可以是银行也可以是水边,使用普通的 Word2Vec 作
为 Pretraining 的 Embedding,只能同时把这两种语义都编码进向量里,然后靠后面的模型比如 RNN 来根据上下文选择合适的语义——比如上下文有 money,那么它更可能是银行;而如果上下文是 river,那么更可能是水边的意思。但是 RNN 要学到这种上下文的关系,需要这个任务有大量相关的标注数据,这在很多时候是没有的。而ELMo 的特征提取可以看成是上下文相关的,如果输入句子有 money,那么它就 (或者我们期望) 应该能知道 bank 更可能的语义,从而帮我们选择更加合适的编码。
无监督的预训练
给定一个长度为 N 的句子,假设为 t1, t2, ..., tN,语言模型会计算给定 t1, ..., tk−1 的条件下出现 tk 的概率:
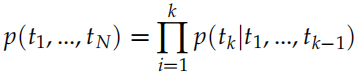
传统的 N-gram 语言模型不能考虑很长的历史,因此现在的主流是使用多层双向的RNN(LSTM/GRU) 来实现语言模型。在每个时刻 k,RNN 的第 j 层会输出一个隐状态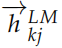 ,其中 j = 1, 2, ..., L,L 是 RNN 的层数。最上层是
,其中 j = 1, 2, ..., L,L 是 RNN 的层数。最上层是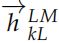 ,对它进行 softmax之后就可以预测输出词的概率。类似的,我们可以用一个反向的 RNN 来计算概率:
,对它进行 softmax之后就可以预测输出词的概率。类似的,我们可以用一个反向的 RNN 来计算概率:
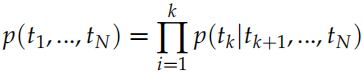
通过这个 RNN,我们可以得到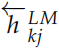 。我们把这两个方向的 RNN 合并起来就得到 Bi-LSTM。我们优化的损失函数是两个 LSTM 的交叉熵加起来是最小的:
。我们把这两个方向的 RNN 合并起来就得到 Bi-LSTM。我们优化的损失函数是两个 LSTM 的交叉熵加起来是最小的:
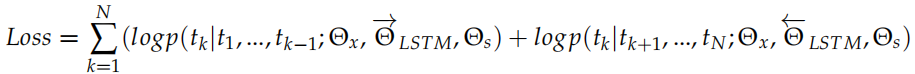
这两个 LSTM 有各自的参数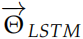 和
和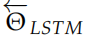 ,但是 word embedding 参数
,但是 word embedding 参数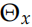 和 softmax 参数
和 softmax 参数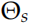 是共享的。
是共享的。
ELMo
ELMo 会根据不同的任务,把上面得到的双向的 LSTM 的不同层的隐状态组合起来。对于输入的词 tk,我们可以得到 2L+1 个向量,分别是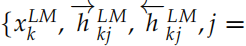 =1, 2, ..., L},我们把它记作
=1, 2, ..., L},我们把它记作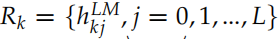 。其中
。其中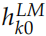 是词的 Embedding,它与上下文无关,而其它的
是词的 Embedding,它与上下文无关,而其它的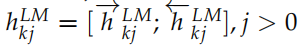 是把双向的 LSTM 的输出拼接起来的,它们与上下文相关的。
是把双向的 LSTM 的输出拼接起来的,它们与上下文相关的。
为了进行下游 (downstream) 的特定任务,我们会把不同层的隐状态组合起来,组合的参数是根据特定任务学习出来的,公式如下:
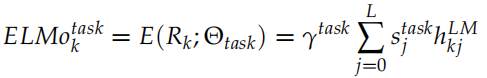
这里的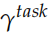 是一个缩放因子,而
是一个缩放因子,而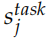 用于把不同层的输出加权组合出来。在实际的任务中,RNN 的参数
用于把不同层的输出加权组合出来。在实际的任务中,RNN 的参数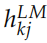 都是固定的,可以调的参数只是
都是固定的,可以调的参数只是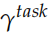
和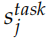 。当然这里 ELMo 只是一个特征提取,实际任务会再加上一些其它的网络结构,那么那些参数也是一起调整的。
。当然这里 ELMo 只是一个特征提取,实际任务会再加上一些其它的网络结构,那么那些参数也是一起调整的。
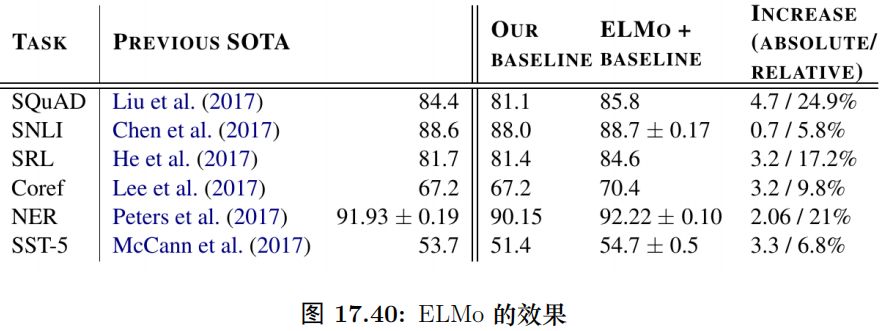
实验结果
图15.90是 ELMo 在 SQuAD、SNLI 等常见任务上的效果,相对于 Baseline 系统都有不小的提高。
-
谷歌模型训练软件有哪些功能和作用2024-02-29 1699
-
NLP入门之Bert的前世今生2023-02-22 1701
-
参天生长大模型:昇腾AI如何强壮模型开发与创新之根?2022-08-11 2380
-
如何使用BERT模型进行抽取式摘要2022-03-12 5998
-
基于BERT的中文科技NLP预训练模型2021-05-07 1185
-
图解BERT预训练模型!2020-11-24 4879
-
BERT原理详解2019-07-02 1428
-
谷歌大脑CMU联手推出XLNet,20项任务全面超越BERT2019-06-22 3977
-
史上最强通用NLP模型诞生2019-02-18 5063
-
图解2018年领先的两大NLP模型:BERT和ELMo2019-01-03 2765
-
用图解的方式,生动易懂地讲解了BERT和ELMo等模型2018-12-16 12029
-
BERT模型的PyTorch实现2018-11-13 14729
-
Google最强模型BERT出炉2018-10-27 5713
-
NLP领域取得最重大突破!BERT模型开启了NLP的新时代!2018-10-18 5263
全部0条评论

快来发表一下你的评论吧 !
