

在DNN算法领域 未来FPGA与CPU的性能对比分析
可编程逻辑
描述
在最近的FPGA国际研讨会(ISFPGA)上,英特尔加速器架构实验室(AAL)的Eriko Nurvitadhi博士,分享了英特尔的最新研究。
这一研究,主要评估在DNN(深度神经网络)算法领域,两代英特尔FPGA(Intel Arria10和Intel Stratix 10),与NVIDIA TITAN X Pascal GPU相比性能如何。
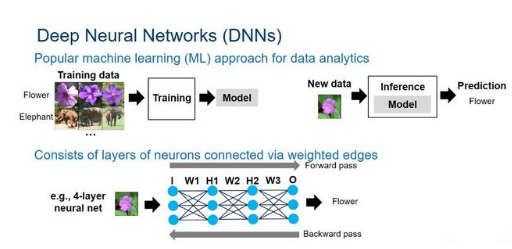
△ 深度神经网络概述
英特尔表示在应用领域,FPGA在DNN研究中表现非常出色,可用于需要分析大量数据的AI、大数据或机器学习等领域。使用经修剪或紧凑的数据类型与全32位浮点数据(FP32)时,测试的Intel Stratix 10 FPGA的性能优于GPU。
除了性能外,FPGA还具有强大的功能,因为它们具有适应性,通过重用现有的芯片可以轻松实现更改,从而让团队在六个月内从一个想法进入原型。
而构建一个ASIC需要18个月。
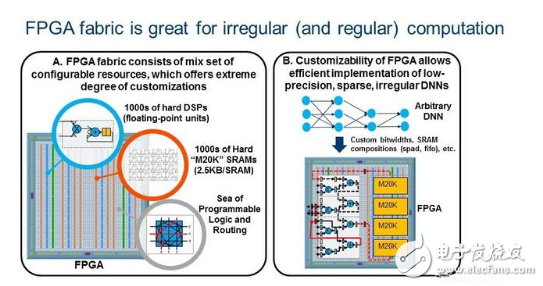
△ FPGA非常适用于DNN
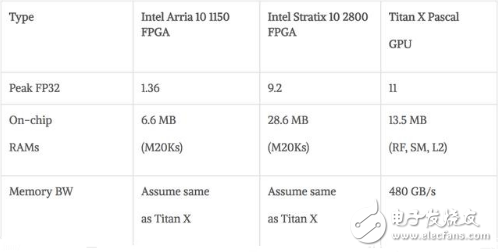
硬件:与高端GPU相比,FPGA具有卓越的能源效率(性能/瓦特),但还有不被熟知的高峰值浮点性能。FPGA技术正在迅速发展。即将推出的英特尔Stratix 10 FPGA提供超过5,000个硬件浮点单元(DSP),超过28MB的片上RAM(M20K),与高带宽内存等特性。
基于14nm工艺的英特尔Stratix 10在FP32吞吐量方面达到峰值9.2TFLOP/s。相比之下,最新的Titan X Pascal GPU的FP32吞吐量为11TFLOP/s。
新兴的DNN算法:更深的网络提高了精度,但是大大增加了参数和模型大小。这增加了对计算、带宽和存储的需求。因此,新兴趋势是采用紧凑型低精度数据类型,远低于32位。16位和8位数据类型正在成为新常态,也得到DNN软件框架(例如TensorFlow)的支持。
新兴的低精度和稀疏DNN算法比传统的密集FP32 DNN提供了数量级的算法效率改进,但是它们引入了难以处理的不规则并行度和定制数据类型。这时FPGA的优势就体现出来了。这种趋势使未来FPGA成为运行DNN,AI和ML应用的可行平台。
GPU:使用已知的库(cuBLAS)或框架(Torch with cuDNN)
FPGA:使用Quartus Early Beta版本和PowerPlay
研究一:矩阵乘法(GEMM)测试
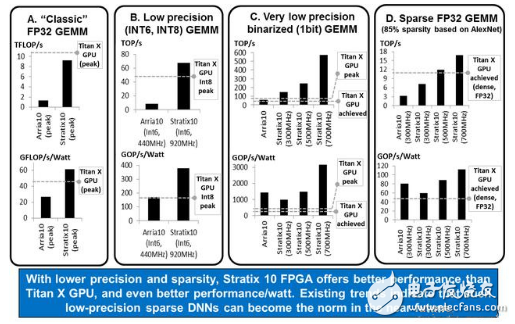
矩阵乘法(GEMM)测试的结果。GEMM是DNN中的关键操作,上述四个不同类型的测试表明,除了在FP32 Dense GEMM测试中,Stratix 10与TITAN X仍有差距。另外三项测试中新一代英特尔FPGA的表现都优于GPU。
研究二:使用三元ResNet DNNs测试
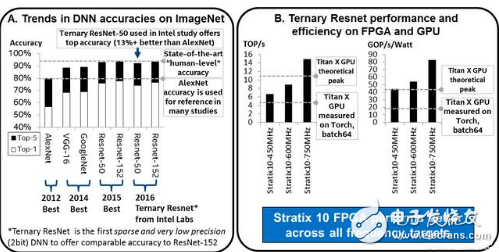
三进制DNN最近提出约束神经网络权重为+1,0或-1。这允许稀疏的2位权重,并用符号位操作代替乘法。与许多其他低精度和稀疏的DNN不同,三元DNN可以提供与现有技术DNN(即ResNet)相当的精度。
上图右半部分,显示了英特尔Stratix 10 FPGA和TITAN X GPU的ResNet-50的性能和性能/功耗比。即使对于保守的性能估计,英特尔Stratix 10 FPGA已经比实现了TITAN X GPU性能提高了约60%。在性能/功耗比方面,英特尔Stratix 10比TITAN X要好2.3倍到4.3倍。
-
TNC连接器对比分析:与其他射频连接器的性能对决2024-12-17 2148
-
新兴DNN推理领域的FPGA2023-09-15 458
-
ARM/DSP/FPGA的区别是什么?对比分析哪个好?2021-11-05 1804
-
DSP/MCU/ARM/CPLD/FPGA对比分析哪个好?2021-10-22 1696
-
工频机和高频机的性能对比分析哪个好?2021-10-21 4901
-
步进电机和交流伺服电机性能对比分析哪个好?2021-10-09 1522
-
CPLD与FPGA对比分析哪个好?2021-06-21 2826
-
LCR-TDD系统初始频偏估计算法对比分析哪个好?2021-06-02 1965
-
主流CAN收发器性能对比分析哪个最好?2021-05-20 2553
-
Arm Cortex-A35性能对比分析2021-01-19 10079
-
小型PLC对比分析2012-04-27 1032
全部0条评论

快来发表一下你的评论吧 !
