

清华大学人工智能研究院宣布成立知识智能研究中心
电子说
描述
清华大学人工智能研究院今天宣布成立知识智能研究中心,由李涓子教授担任中心主任。中心旨在开展理论研究、促进交流合作,最终构建包含语言知识、常识知识、世界知识、认知知识的大规模知识图谱以及典型行业知识库的清华大学知识计算开放平台。
2019年1月21日,清华大学人工智能研究院在清华大学FIT楼举行知识智能研究中心成立仪式暨知识计算开放平台发布会,清华大学副校长、清华大学人工智能研究院管委会主任尤政院士,人工智能研究院院长张钹院士、常务副院长孙茂松教授出席仪式并致辞。
知识智能研究中心 (Knowledge Intelligence Research Center, KIRC)是清华人工智能研究院自2018年6月建院以来成立的首个研究中心(点击“阅读原文”访问网站),是研究院整合校内优势研究力量、推动人工智能原始创新的一个重要举措,也是人工智能研究院发展的一个新的里程碑。”尤政院士在致辞中说。
知识中心主任由我国知识计算领域专家、清华大学长聘教授李涓子担任。李涓子教授表示,知识中心将以促进清华和国家知识智能研究与发展为宗旨,打造具有广泛影响力的学术研究、知识计算平台与学术交流中心。
知识智能研究中心揭牌仪式上,清华大学人工智能研究院院长张钹院士(左),清华大学副校长、清华大学人工智能研究院管委会主任尤政院士(右),为李娟子教授颁发知识中心主任聘书。
李涓子,清华大学长聘教授,博士生导师。中国中文信息学会语言与知识计算专委会主任。研究方向为知识工程、语义Web和文本挖掘。近年来在重要国际会议和学术期刊上发表论文100余篇,编著出版《Mining User Generated Content》,《Semantic Mining in Social Networks》。主持国家自然科学基金重点课题、欧盟第七合作框架等多项国家、国际和部委项目。获得2017年北京市科技进步一等奖、2013年人工智能学会科技创新一等奖等多个奖项。
董振东先生被聘任为知识中心学术顾问(由董强先生[中]代领)
清华大学知识计算开放平台发布,让知识为AI赋能
让计算机拥有大规模高质量的知识是实现人工智能的一项重要任务。知识表示、获取、推理与计算等问题,一直处于人工智能的研究核心。
“很多人以为现在这波深度学习掀起的浪潮已经让我们进入了新一代人工智能的时代,”张钹院士:“这种看法是错误的。”
张钹院士指出,新一代人工智能指向的必须是安全可信的人工智能,深度学习技术由于数据驱动的特性,存在可解释性和鲁棒性的局限性,亟需大规模知识的支持,以实现有理解能力的人工智能,这也是清华人工智能研究院成立知识中心的初衷。
目前,中国在知识表示、知识推理方面积累不足,从最近的相关文献看,少见中国学者在这一领域发表论文,而多样化的研究和基础性研究是人工智能探索必须的。因此,“清华大学在这个时间点成立知识中心还是非常及时的”,张钹院士说。
作为清华大学人工智能研究院成立的首个研究中心,李涓子教授表示,知识智能研究中心旨在:
开展理论研究。研究支持鲁棒可解释人工智能的大规模知识的表示、获取、推理与计算的基础理论和方法,尤其是原创性研究;
构建知识平台。建设包含语言知识、常识知识、世界知识、认知知识的大规模知识图谱以及典型行业知识库,建成清华大学知识计算开放平台;
促进交流合作。举办开放的、国际化的与知识智能相关的学术活动,增进学术交流;普及知识智能技术,促进产学合作。
会上,知识中心隆重发布了清华大学知识计算开放平台(THUKC),清华大学计算机系副教授刘知远对平台做了介绍,包括中英文跨语言百科知识图谱XLORE、大规模开放语言知识库OpenHowNet、科技知识挖掘平台AMiner、清华大学人工智能技术系列报告THUAITR等。
刘知远副教授表示,深度学习 (数据) 与知识的结合是人工智能发展的必然趋势,人工智能本身也渴求世界知识、常识知识等知识智能的支撑。
刘知远告诉新智元,目前平台以清华团队为主,未来希望汇聚更多学界和产业界力量,这也是平台冠名“开放”之意义所在。
知识中心将在清华大学和人工智能研究院的支持下,以这次发布的知识计算平台为起点,坚持做好做强知识计算平台,让知识为AI赋能。
清华大学知识计算开放平台(THUKC)详介
会上,知识计算开放平台现有项目团队代表分别做了学术报告,详细介绍了清华发布的知识资源和计算平台。
知网(HowNet)知识系统共同发明人董强发表《THUKC语言与常识知识库——OpenHowNet》的学术报告。
OpenHowNet:基于义原的开放语言知识库
网址:openhownet.thunlp.org
知网HowNet是由董振东先生、董强先生父子毕三十年之功建立的一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间、以及概念所具有的属性之间的关系为基本内容的语言和常识知识库。
HowNet秉承还原论思想,认为词义概念可以用更小的语义单位来描述,这种语义单位被称为“义原”(Sememe),是最基本的、不易于再分割的意义的最小单位。在不断标注的过程中,HowNet逐渐构建出了一套精细的义原体系 (约2000个义原)。
HowNet基于该义原体系累计标注了数十万词汇/词义的语义信息,自1999年正式发布以来引起了中文信息处理领域极大的研究热情,在词汇相似度计算、文本分类、信息检索等方面探索了HowNet的重要应用价值,建立了广泛而深远的学术影响力。
2017年以来,清华大学研究团队系统探索HowNet知识库在深度学习时代的应用价值,并在词汇语义表示、句子语义表示、词典扩展等任务上均得到了验证。研究发现,HowNet通过统一的义原标注体系直接精准刻画语义信息,一方面能够突破词汇屏障,深入了解词汇背后丰富语义信息;另一方面每个义原含义明确固定,可被直接作为语义标签融入机器学习模型,使自然语言处理深度学习模型具有更好的鲁棒可解释性。相关成果均发表在AAAI、IJCAI、ACL、EMNLP等人工智能和自然语言处理领域顶级国际会议上。
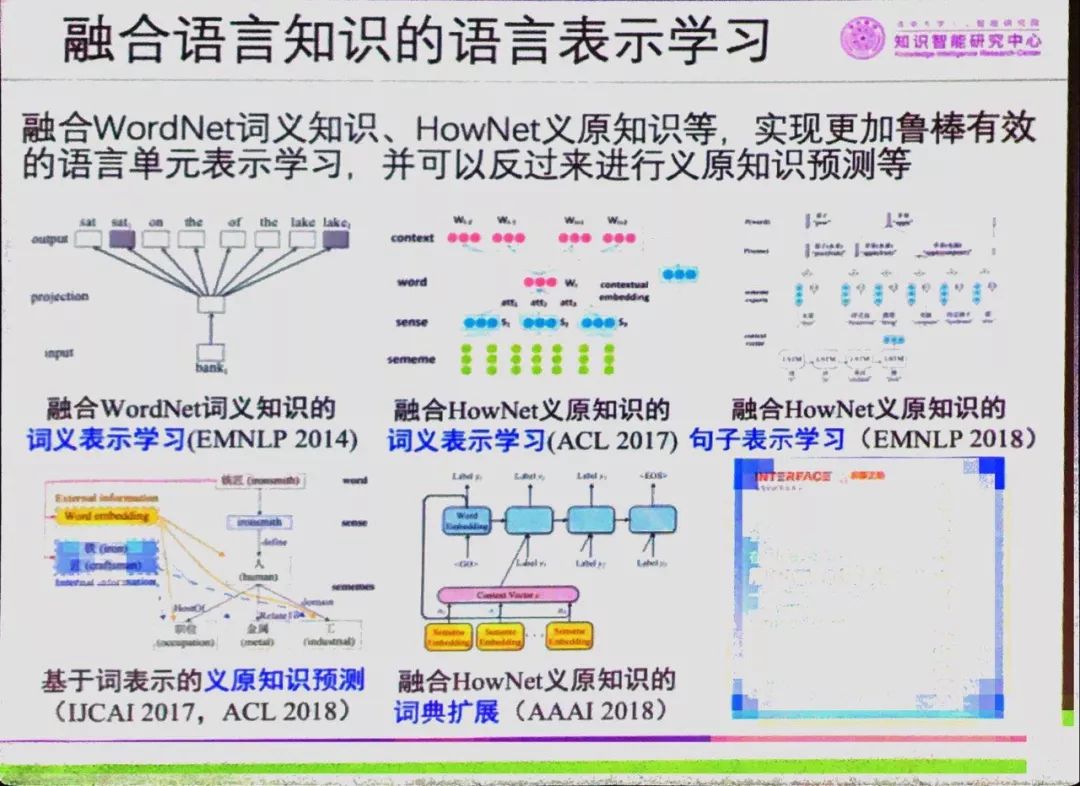
为了让HowNet知识库及其学术思想得到更广泛的应用,知识中心联合董氏父子共同开源HowNet知识库核心数据,研制了知识库的访问与计算工具包,并将在清华大学知识计算平台上持续地维护、更新和扩展。
XLORE:千万级概念实体和亿级实体大规模跨语言知识图谱
网址:https://xlore.org/
李涓子教授介绍XLORE,融合百度百科、中英文维基百科等多语言融合的知识图谱
接下来,李涓子教授介绍了THUKC世界知识图谱——XLORE。
XLORE是中英文知识规模平衡的大规模跨语言百科知识图谱。该图谱通过融合中文、英文的维基百科和百度百科,并对百科知识进行结构化和跨语言链接构建而成。
该图谱以结构化形式描述客观世界中的概念、实例、属性及其丰富语义关系。XLORE目前包含约247万概念、44.6万属性/关系、1628万实例和260万跨语言链接。XLORE作为世界知识图谱,将为包括搜索引擎、智能问答等人工智能应用提供有力支撑。现在全部内容都可以用网站下载使用。
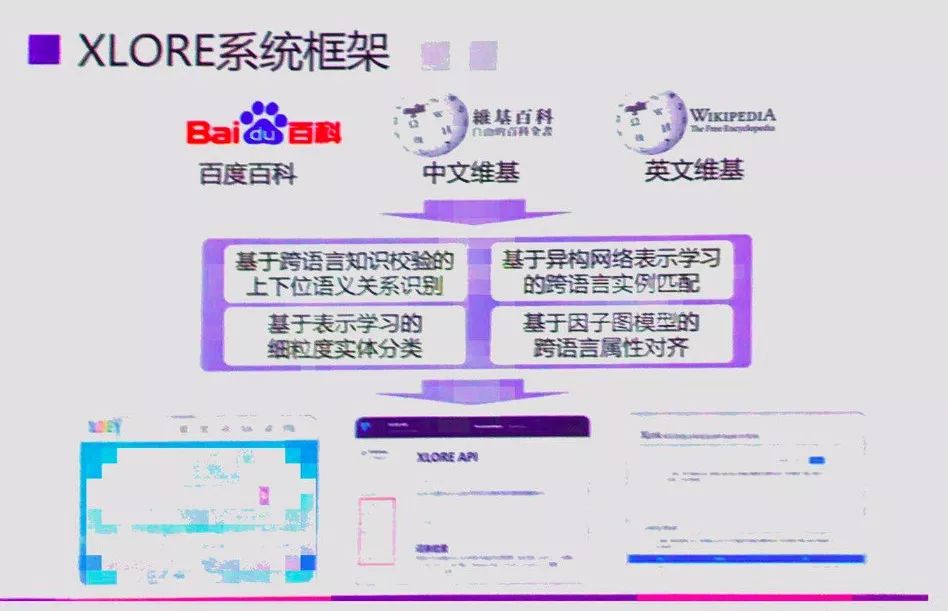
XLORE集成了多项创新研究成果:
利用基于链接因子图模型的知识链接方法,实现对不同语言知识资源之间的实体知识关联;
利用跨语言概念层次关系的验证保证生成跨语言本体中概念关系的质量,并进一步研究了跨语言知识图谱的概念层次剪枝和优化算法以规范知识分类体系;
利用因子图模型建立跨语言属性间的对应关系,减少知识图谱的冗余;
联合使用DBpedia分类树、维基分类体系、百度百科词条标签对未分类实体进行类别标注。相关成果发表在WWW、IJCAI、ACL、EMNLP等人工智能和自然语言处理领域重要国际会议上。
与著名知识图谱DBpedia相比,XLORE的中文实体数量是其的3.6倍,中英文跨语言链接增加39%。XLORE还提供多样化数据API服务,系统累计访问次数过亿次,访问来自53个不同国家或地区;2018年API响应调用160万余次。XLORE项目计划于2019年正式发布跨语言实体链接服务XLINK。
在世界知识的获取、表示与计算方面,中心还研制发布了很多开源工具和评测数据集,如知识表示学习工具包OpenKE、神经网络关系抽取工具包OpenNRE、Few shot learning关系抽取数据集FewRel等,自发布以来获得学术界与产业界广泛使用。

AMiner:大规模科技知识挖掘平台
网址:https://aminer.cn/
清华大学计算机系教授唐杰详细介绍了科技知识挖掘平台AMiner和清华大学人工智能技术系列报告THUAITR
AMiner作为科技情报网络大数据挖掘平台,包含超过2亿篇学术论文和专利以及1.36亿科研人员学术网络。该平台于2006年上线,已经累计吸引全球220个国家和地区的800多万独立IP访问,数据下载量230万次,年度访问量超过1000万,成为学术搜索和社会网络挖掘研究的重要数据和实验平台。
AMiner项目团队与中国工程科技知识中心、微软学术搜索、ACM、IEEE、DBLP、美国艾伦研究所、英国南安普顿大学等机构建立了良好的合作关系,项目成果及核心技术应用于中国工程院、科技部、国家自然科学基金委、华为、腾讯、阿里巴巴等国内外20多家企事业单位,为各单位的专家系统建设及产品升级提供了重要数据及技术支撑。
唐杰教授还介绍了清华大学人工智能技术系列报告THUAITR,并新发布了“知识图谱研究报告”和“数据挖掘研究报告”两份新报告。
THUAITR:清华大学人工智能技术系列报告
网站:https://reports.aminer.cn/
THUAITR以AMiner全球科技情报大数据挖掘服务平台为基础,聘请领域专家作为顾问,结合人工智能自动生成技术,以严谨、严肃、负责的态度制作发布的人工智能技术评论及人才分析。报告内容涵盖技术趋势、前沿预测、人才分布、实力对比、以及洞察情报等。
2018年,THUAITR共发布14份技术报告,主题包括:自动驾驶(基础版)、机器人、区块链、行为经济学、机器翻译、通信与人工智能、自动驾驶、自然语言处理、计算机图形学、超级计算机、3D打印、智能机器人、人脸识别、人工智能芯片,累计阅读量超过120万人次。
此外,清华大学计算机系副教授黄民烈还在会上做了报告《知识计算典型案例——常识知识感知的语言生成初探》,主要介绍了两项工作:一是结合常识进行对话生成,一是符合逻辑的故事结局的生成。
-
百度深度学习研究院科学家深度讲解人工智能2018-07-19 0
-
捷通华声与清华海峡研究院联合成立人工智能研究中心2018-06-11 4403
-
清华大学成立人工智能研究院2018-07-02 3703
-
清华人工智能研究院成立,人工智能研究增添新成员2018-07-05 3281
-
清华AI研究院成立知识智能研究中心,知识计算开放平台重磅发布2019-01-26 4381
-
清华成立视觉智能研究中心,邓志东任中心主任2019-06-25 3175
-
清华成立NLP与社会人文计算研究中心 开源机器翻译系统等三项成果2019-07-05 2998
-
上海交通大学人工智能研究院数学基础研究中心正式成立2020-01-02 4014
-
人工智能全球女性榜单 美国学者数量最多2020-03-09 695
-
清华大学在人工智能与国际治理方面的已有积累和跨学科优势2020-07-02 2056
-
清华大学战略与安全研究中心的人工智能小组提出六原则2020-08-06 980
-
越疆科技与清华大学人工智能研究院智能机器人中心签署全面战略合作协议2020-09-21 2753
-
厦门大学人工智能研究院揭牌设立2020-10-30 2277
-
字节跳动与清华AIR成立联合研究中心2024-10-12 409
-
博世与清华大学续签人工智能研究合作协议2024-11-20 365
全部0条评论

快来发表一下你的评论吧 !
