

学习下如何去抓APP的数据
电子说
描述
【导语】2019亚洲杯决赛正如火如荼进行中,国足的晋级之路可谓用“惊现”二字评论。继1月16日,国足对战韩国队败北后,一名Python学习者为了一窥网友们的评论,特意爬了懂球帝App的数据。
最新喜讯是在20日国足对战泰国的比赛中,成功逆转战胜泰国晋级八强,无不惊喜。让我们来学习下本文相关技术要点。
正文:
如果你是个足球迷的话,估计或多或少都会看一下昨晚中国踢韩国的比赛,因为不管他们踢得怎样,我们还是深爱着他们,那句话说得好,“国足虐我千百遍,我待国足如初恋”。更何况他们两场都踢赢了,所以面对第三场实力有点强的韩国队也是希望能赢的,毕竟我们也在十二强赛上赢过他们!
如果你不是个足球迷,但你也可以看看,可以学习下如何去抓APP的数据。好了,废话不多说,开始抓取!
1. 抓包分析请求
手机抓包我们可以用 Fiddler 软件来抓取,如果不懂怎样抓的话,可以看看这篇文章《抓包软件 Fiddler 了解一下?》(文章链接:https://mp.weixin.qq.com/s/G7xjvoh77pwcsP1KNotxjw)
配置好之后,开始抓包。
首先找到需要爬取的文章
懂球帝app截图
文章链接为:https://m.dongqiudi.com/article_share/896482.html
在配置好抓包之后,点击下方的评论,可以看到
评论截图
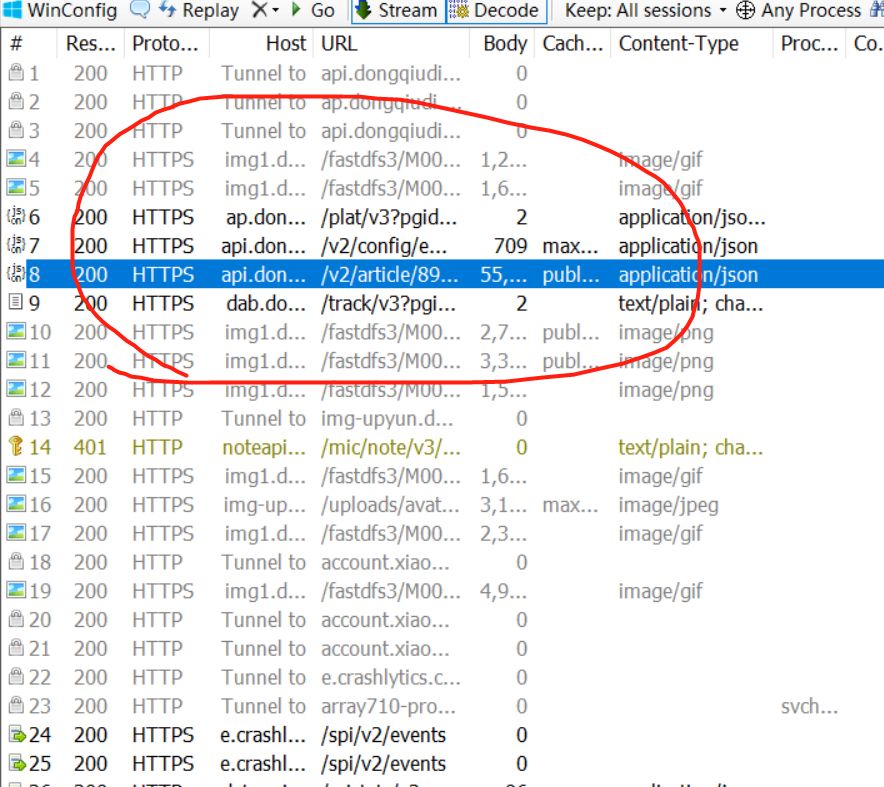
抓包截图
很容易就找到文章评论的请求,就是下面这个
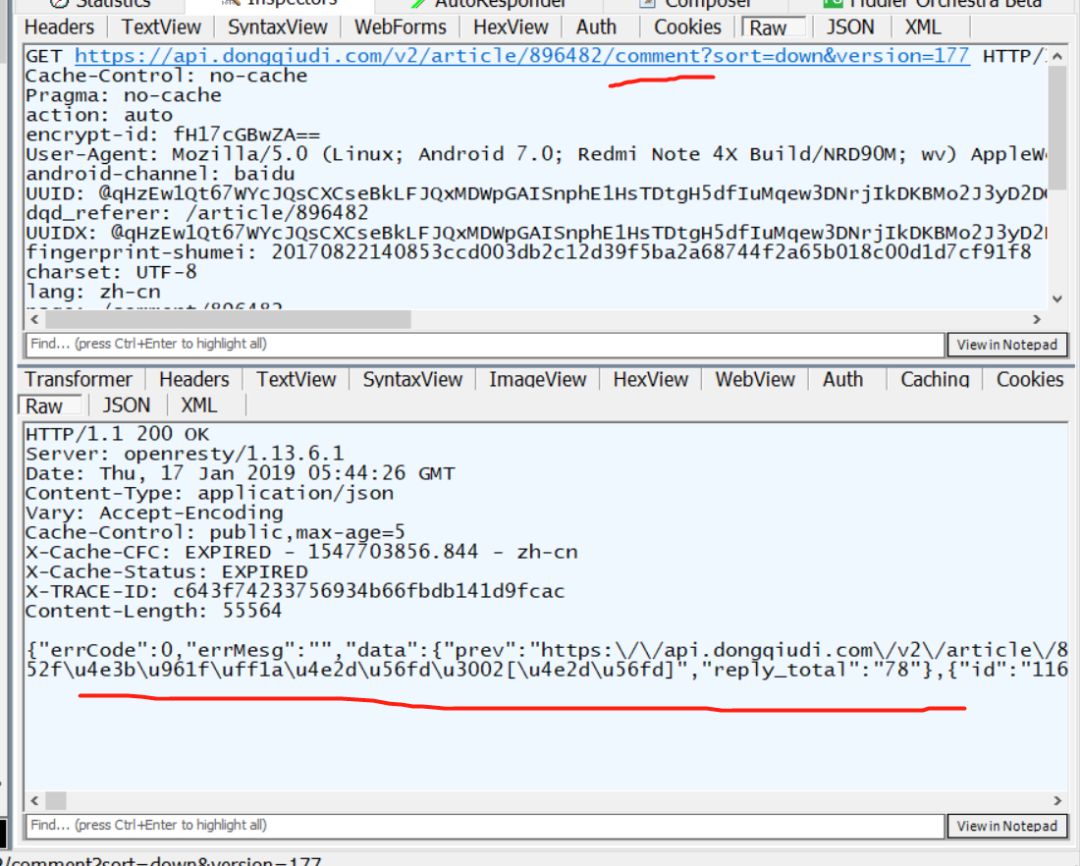
可以看到请求的链接为:https://api.dongqiudi.com/v2/article/896482/comment?sort=down&version=177 ,
请求方法为GET,接下来就好办了,我们再看看滑下去查看更多的评论的请求。
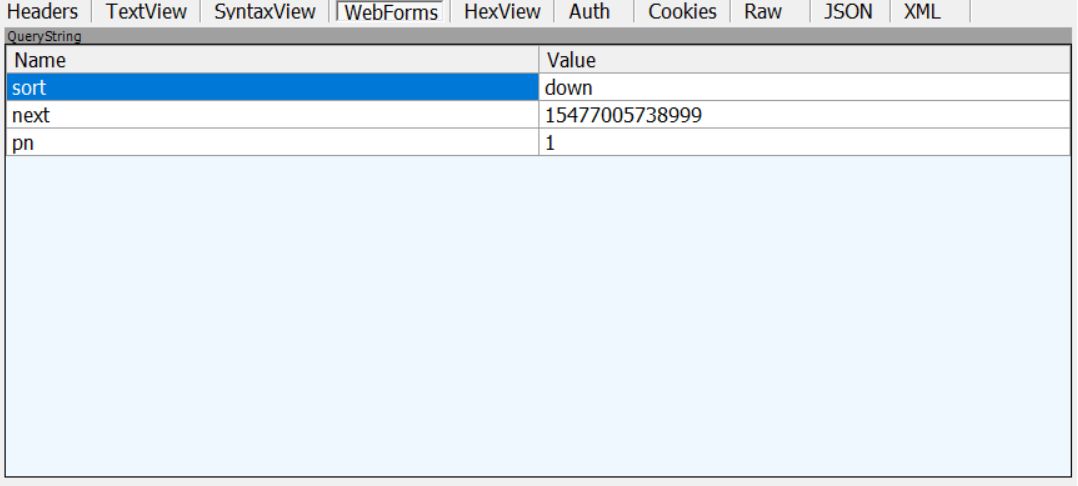
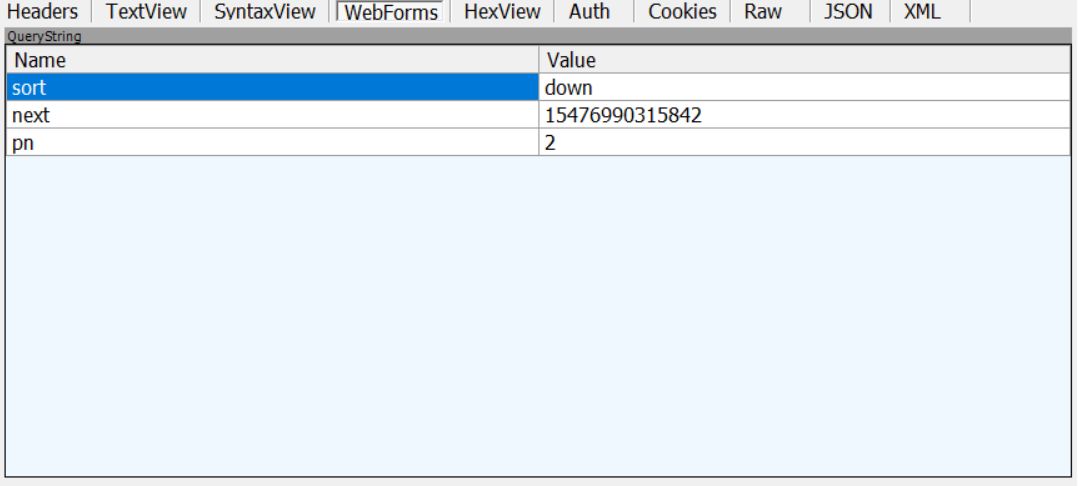
可以看到,向下翻页多了两个参数,不过容易知道,next 参数就是一个时间戳,而 pn参数就是页数吧,从 0 开始的。
但是怎样判断所有评论已经爬完了呢?我们可以看看数据的详情,下面将 json 数据格式化,在下图可以看到在 data 里面有下一页的数据,那这就容易了,哈哈
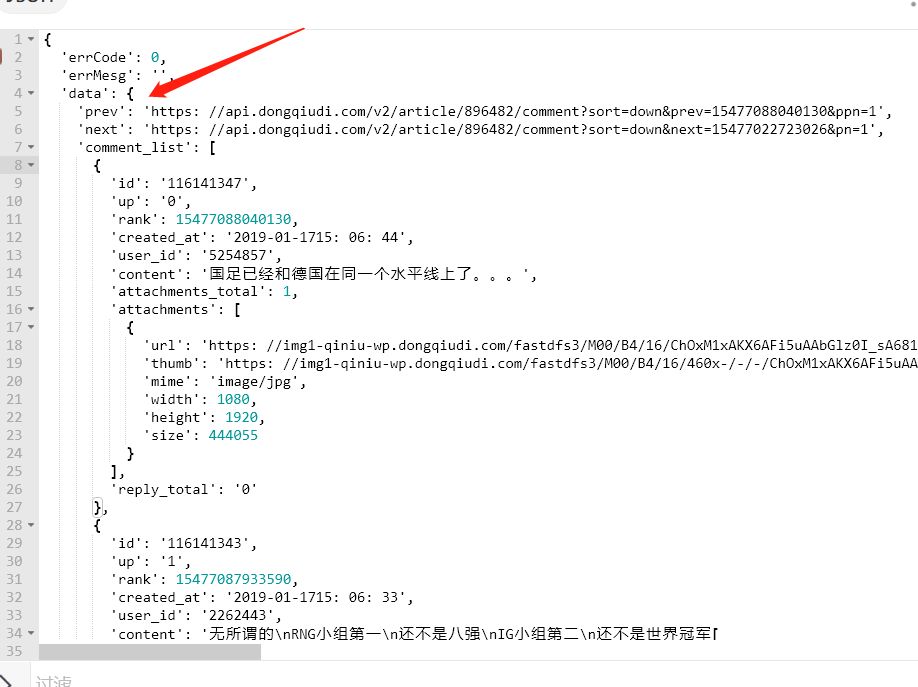
分析了,接下来就是代码部分了。
2. 代码部分
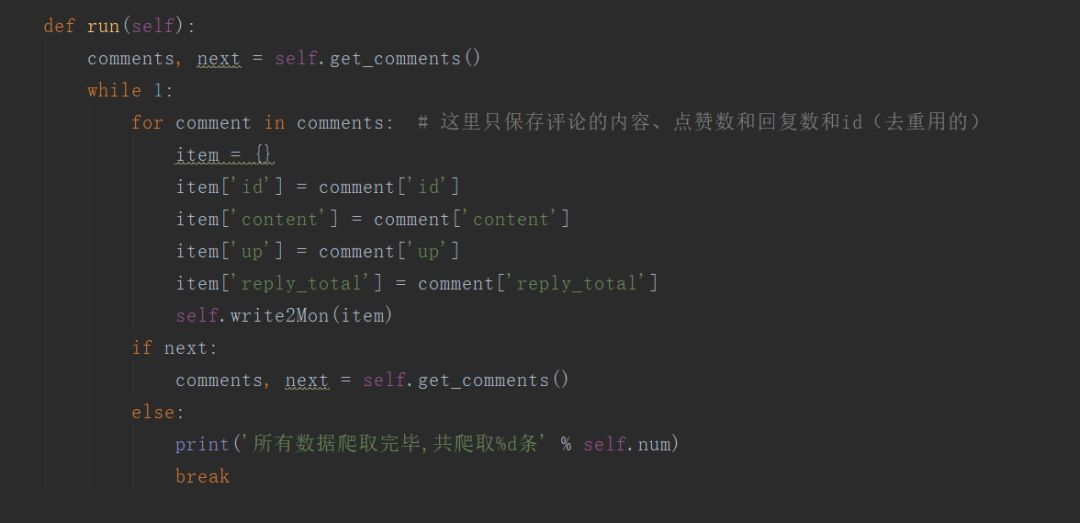
这是主体部分,先从第一个评论链接中爬取评论以及找出下一页的评论地址进而继续爬取。这里是把数据库存进 mongodb 中。
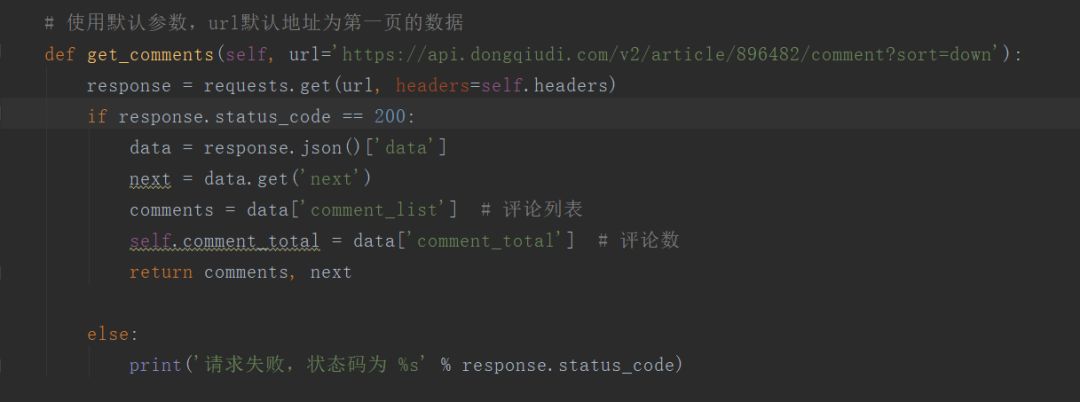
主要的爬取逻辑,可以看出来是比较简单的,因为没有涉及到什么加密参数之类的,但是有一个问题,每一次进行请求的时候,有时候是会返回带有相同的评论的,所以我们也需要在数据库简单地进行去重。
下面是入库和去重的代码部分
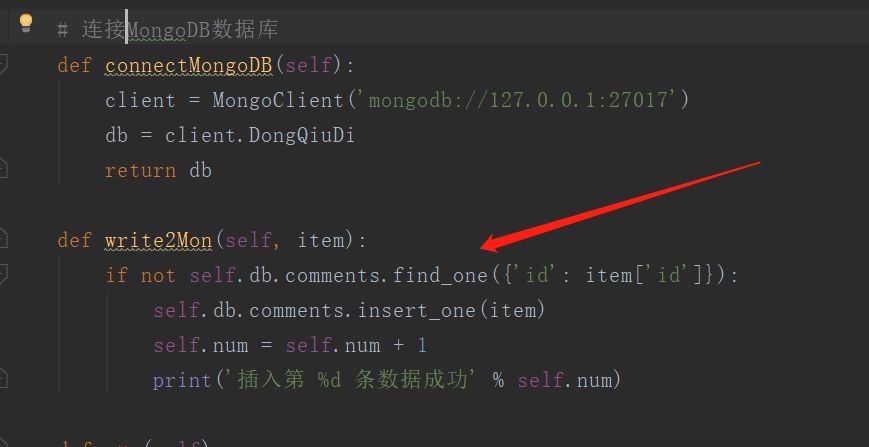
剩下的就没有了。
3. 查看所得的数据
由于数据分析还不熟悉,所以暂时只制作词云图。
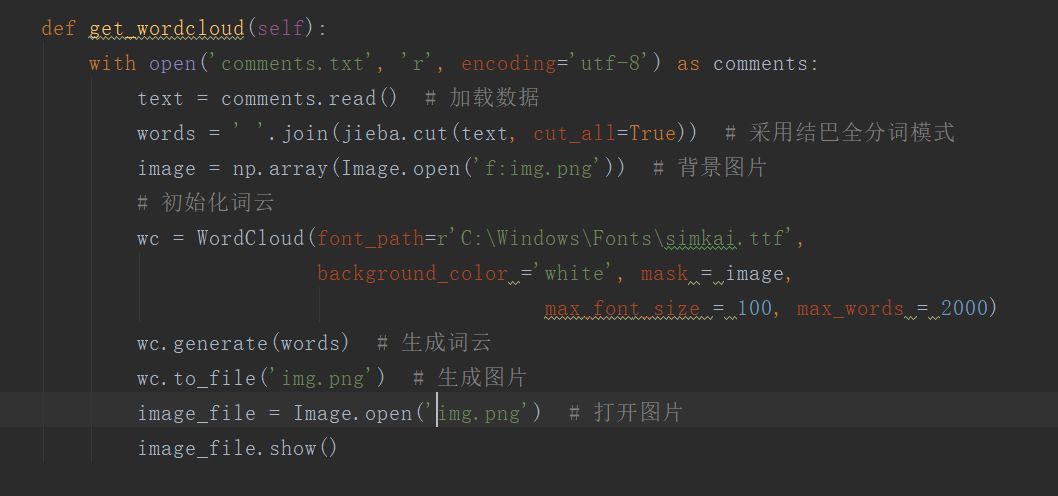
需要先将数据写到文本上
词云图是:
可以看出,昨晚国足输一场,也被很多人喷了,但是还是有很多人是一直支持的,永远都为国足加油,里面也说到了,中国和韩国是有一定差距的,而且还有点大,输了也正常不过了,没必要喷,再说我觉得昨晚的比赛已经比第一场的比赛好很多(第二次没看),还是有进步的,我对国足未来淘汰赛也是充满期望的,我相信能走得更远!
下一场踢泰国,20号,有人看吗?
-
无线学习型红外遥控器(APP蓝牙控制,有APP安装文件)2020-03-09 4616
-
wireshark抓包数据分析问题2020-04-08 1972
-
App是如何去实现重启的呢2022-02-10 1641
-
AVR入门: 如何使用App Note去实现USART通讯?2018-07-09 2822
-
Wireshark数据抓包网络协议的分析2020-10-12 1285
-
推荐六款可提高学习效率的APP2021-03-03 4462
-
USB数据抓包软件程序下载2021-09-09 1611
-
APP抓不到包?2023-08-03 2752
-
如何抓取app数据包 网络抓包原理及实现2023-08-11 5668
全部0条评论

快来发表一下你的评论吧 !
