

内存内计算的原理以及其市场前景分析
电子说
描述
最近,内存内计算成了热门关键词。今年早些时候,IBM发布了基于相变内存(PCM)的内存内计算,在此之后基于Flash内存内计算的初创公司Mythic获得了来自软银领投的高达4000万美元的B轮融资,而在中国,初创公司知存科技也在做内存内计算的尝试。本文将对内存内计算的原理以及其市场前景做一些分析。
冯诺伊曼架构之痛
冯诺伊曼架构是计算机的经典架构,同时也是目前计算机以及处理器芯片的主流架构。在冯诺伊曼架构中,计算/处理单元与内存是两个完全分离的单元:计算/处理单元根据指令从内存中读取数据,在计算/处理单元中完成计算/处理,并存回内存。
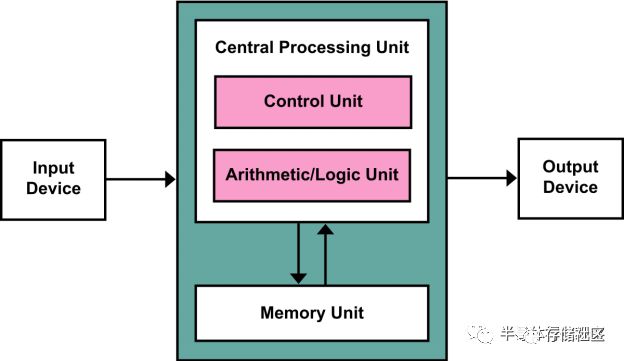
冯诺伊曼架构是经典的计算机体系架构,也构成了过去近一个世纪的计算机科学的基础。然而,冯诺伊曼架构在构建之初只是一个理论模型,在建立该模型时做了一个合理的假设就是处理器和内存的速度很接近。当然,冯诺伊曼在当时没有办法预测到未来集成电路发展对于计算机造成的深远变化。计算机处理器的性能随着摩尔定律高速发展,其性能随着晶体管特征尺寸的缩小而直接提升,因此在过去数十年中其性能提升可谓是天翻地覆,现在一颗手机中处理器的性能已经比30年前超级计算机中的处理器还要强。
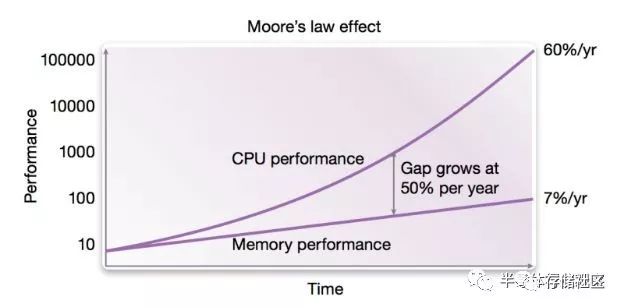
另一方面,计算机的主要内存使用的是DRAM方案,DRAM是基于电容充放电实现的高密度存储方案,其性能(速度)取决于两方面,即内存中电容充放电的读取/写入速度以及DRAM与处理器之间的接口带宽。DRAM电容充放电的读取/写入速度随着摩尔定律有一定提升,但是速度并不如处理器这么快,另一方面DRAM与处理器之间的接口属于混合信号电路,其带宽提升速度主要是受到PCB板上走线的信号完整性所限制,因此从摩尔定律晶体管尺寸缩小所获得的益处并不大。这也造成了DRAM的性能提升速度远远慢于处理器速度,目前DRAM的性能已经成为了整体计算机性能的一个重要瓶颈,即所谓阻碍性能提升的“内存墙”。
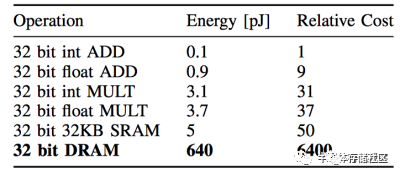
除了性能之外,内存对于能效比的限制也成了传统冯诺伊曼体系计算机的一个瓶颈。这个瓶颈在人工智能应用快速普及的今天尤其显著。这一代人工智能基于的是神经网络模型,而神经网络模型的一个重要特点就是计算量大,而且计算过程中涉及到的数据量也很大,使用传统冯诺伊曼架构会需要频繁读写内存。目前的DRAM一次读写32bit数据消耗的能量比起32bit数据计算消耗的能量要大两到三个数量级,因此成为了总体计算设备中的能效比瓶颈。如果想让人工智能应用也走入对于能效比有严格要求的移动端和嵌入式设备以实现“人工智能无处不在”,那么内存访问瓶颈就是一个不得不解决的问题。
内存内计算的原理
为了解决“内存墙”问题,一个最近得到越来越多关注的思路就是做内存内计算。2018年的国际固态半导体会议(ISSCC,全球最顶尖的芯片设计会议,发表最领先的芯片设计成果,称为“芯片界的奥林匹克”)有专门一个议程,其中的论文全部讨论内存内计算;到了2019年,根据最新发布的ISSCC 2019预览,也有5篇关于内存内计算的论文,不过分散在不同的议程中。内存计算的主要改进就是把计算嵌入到内存里面去,这样内存就不仅仅是一个存储器,还是一个计算器。这样一来,在存储/读取数据的时候就同时完成了运算,因此大大减少了计算过程中的数据存取的耗费。
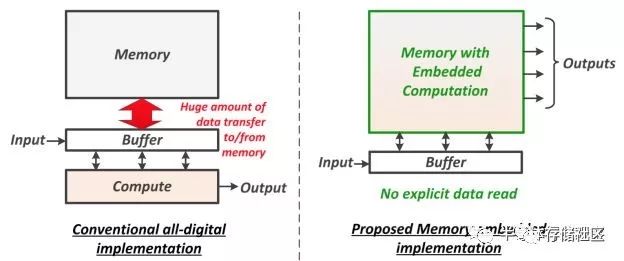
内存内计算现在还处于探索阶段,有很多种具体实现方式。举一个ISSCC 2018年论文中的例子。这个内存内计算的电路由MIT的研究组提出,主要用途是加速卷积计算。我们知道,卷积计算可以展开成带权重的累加计算,从另一个角度来看其实就是多个数的加权平均。因此,该电路实现的就是电荷域的加权平均,其中权重(1-bit)储存在SRAM中,输入数据(7-bit数字信号)经过DAC成为模拟信号,而根据SRAM中的对应权重,DAC的输出在模拟域被乘以1或者-1,然后在模拟域做平均,最后由ADC读出成为数字信号。具体来说,由于乘法的权重是1-bit(1或-1),因此可以简单地用一个开关加差分线来控制,如果是权重是1就让差分线一边的电容充电到DAC输出值,反之则让差分线另一边充到这个值。平均也很简单,几条差分线简单地连到一起就是在电荷域做了平均了。
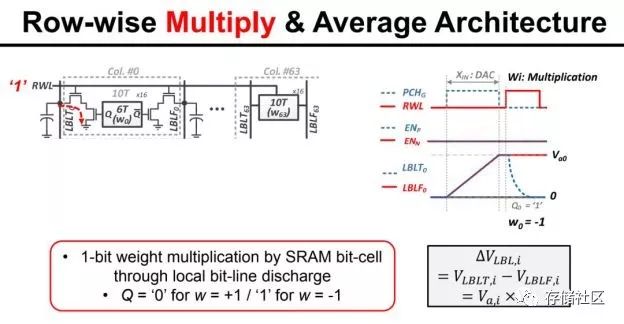
当然,内存内计算的电路并不止于一种,其计算的精度也并不限于1-bit计算。但是,从以上的例子我们可以看出内存内计算的核心思想,一般是把计算都转化为带权重加和计算,把权重存在内存单元中,然后在内存的核心电路(如读出电路)上做修改,从而让读出的过程就是输入数据和权重在模拟域做点乘的过程,相当于实现了输入的带权重累加,即卷积。因为卷积是人工智能以及其他计算的核心组成部分,因此内存内计算可以被广泛使用在这类应用中。内存内计算会使用模拟电路做计算,这也是它和传统使用数字逻辑做计算的不同之处。
内存内计算的两大推动力以及市场前景
人们十几年之前就认识到了“内存墙”的问题,但是为什么内存内计算在这两年才火起来呢?我们认为,最近内存内计算兴起的背后有两大动力。
第一个动力是基于神经网络的人工智能的兴起,尤其是人工智能希望能普及到移动端和嵌入式设备中,这样能效比很高的内存内计算就获得了关注。另外,神经网络的一个特点是对于计算精度的误差拥有较高的容忍度,因此内存内计算的模拟计算中引入的误差往往可以被神经网络所接受,也可以说内存内计算和人工智能(尤其是嵌入式人工智能)可谓是天作之合。
第二个动力是新的存储器。对于内存内计算来说,存储器的特性往往决定了内存内计算的效率,因此当带有新特性的存储器出现时,往往会带动内存内计算的发展。举例来说,最近很火的ReRAM使用电阻调制来实现数据存储,因此每一位的读出使用的是电流信号而非传统的电荷信号。这样一来,由于电流做累加运算是非常自然而然的操作(把几路电流直接组合在一起就实现了电流的加和,甚至无需额外电路),因此ReRAM非常适合内存内计算,也确实有不少研究组已经在做相关的研究并发表了论文。从存储器推广的角度,新的存储器也愿意搭上人工智能的风潮,因此新存储器厂商也乐于看到有人做基于自家存储器的内存内计算加速人工智能,也会帮助一起推广内存内计算。
因为内存内计算的两大推力是人工智能和新存储器,因此我们看到的新存储器产品在人工智能和新存储器这两个关键词上至少会有一个,也有不少内存内计算项目会同时横跨两个关键词。
内存内计算的芯片产品预计会有两种形式。第一种形式是作为一种带有计算功能的存储器IP出售。这样的带内存内计算功能的存储器IP可能是传统的SRAM,也可能是eFlash,ReRAM,MRAM,PCM这样的新存储器。这样的存储器IP往往是一家做内存内计算的公司和一家做存储器的公司(如TSMC或SMIC)联合做推广。
第二种形式是直接做基于内存内计算的人工智能加速芯片。例如Mythic就计划流片做基于Flash存储器的PCIe加速卡,通过PCIe接口和主CPU做通信,Mythic的内存芯片上存储了权重数据,这样当数据送到Mythic的IPU上后就可以直接读出计算结果。这样一来就省去了权重数据的读取开销。
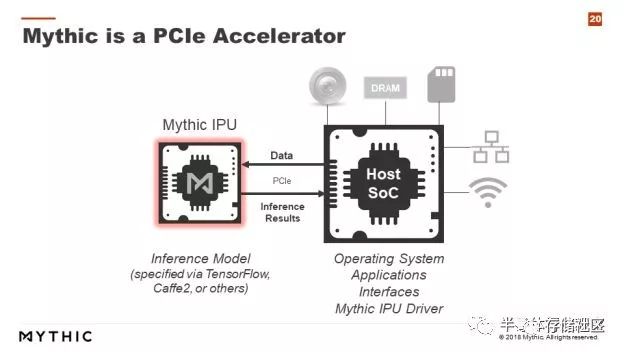
那么内存内计算对于人工智能芯片市场会有什么影响呢?首先,我们看到内存内计算本质上会使用模拟计算,因此其计算精度会受到模拟计算低信噪比的影响,通常精度上限在8bit左右,而且只能做定点数计算,难以做浮点数计算。所以,需要高计算精度的人工智能训练市场并不适合内存内计算,换句话说内存内计算的主战场是在人工智能推理市场。即使在人工智能推理市场,由于精度的限制,内存内计算对于精度要求较高的边缘服务器计算等市场也并不适合,而更适合嵌入式人工智能等对于能效比有高要求而对于精确度有一定容忍的市场。此外,内存内计算其实最适合本来就需要大存储器的场合。举例来说,Flash在IoT等场景中本来就一定需要,那么如果能让这块Flash加上内存内计算的特性就相当合适,而在那些本来存储器并不是非常重要的场合,为了引入内存内计算而加上一块大内存就未必合适。基于这样的分析,我们认为内存内计算有望成为未来嵌入式人工智能(如智能IoT)的重要组成部分。
结语
随着人工智能和新存储器的兴起,内存内计算也成为了新的热点。内存内计算利用存储器的独特特性,结合模拟计算直接在存储器中完成计算,从而大大减少人工智能计算中的内存读写操作。由于内存内计算的精度受到模拟计算的限制,因此它最适合追求能效比且能接受一定精确度损失的嵌入式人工智能应用。
-
[讨论]关于中国动力锂离子电池市场前景的探讨2009-01-12 3939
-
内存计算在DSP领域的应用前景分析2011-07-12 2443
-
VGA TO HDMI--HDMI TO AHD市场前景2018-01-30 3611
-
国内拉绳式位移传感器的市场前景2018-11-06 2363
-
低功耗WiFi市场前景如何?2021-11-11 1555
-
新型电池及其市场前景2009-11-03 972
-
无线充电方案市场前景分析2009-08-06 2149
-
新型绿色电池及其市场前景2009-11-13 1015
-
关于稳压芯片市场前景分析2018-05-31 2231
-
国产接口隔离芯片的技术优势与市场前景2024-01-19 1950
-
智能驾驶的市场前景分析2024-10-23 2797
-
NPU的市场前景与发展趋势2024-11-15 4969
-
机器学习模型市场前景如何2025-02-13 1033
-
智慧路灯的市场前景如何2025-03-30 1245
-
双轨式缆道雷达波测流系统市场前景分析2026-05-21 423
全部0条评论

快来发表一下你的评论吧 !
