

工业互联网时代,我们为什么需要时序数据库之二:适合的就是最好的
描述
在上周的格物汇文章中,我们给大家介绍过,目前国内外主流工业互联网平台几乎都是采用时序数据库来承接海量涌入的工业数据。那为什么强大的Oracle、PostgreSQL 等传统关系型数据库搞不定时序数据?为什么不用HBase、MongoDB、Cassandra等先进的分布式数据库来解决工业数据问题?
作为资深“杠精”,当然需要先知道要“杠”的到底是什么?就时序数据库而言,就是要“杠”两个东西:1、“杠”数据;2、“杠”数据库。
先从数据“杠”起,数据可是一个高深莫测的东西。
想当年图灵用他深邃的眼睛,看穿了世间万物的计算本质:凡是可以计算的,通过迭代,最终都可以表示为0、1的逻辑判断。图灵机需要一个无限长的纸带来表征和记录计算,这无限长的纸带上记录的0、1的组合,就是数据最原始的抽象。图灵机指出了数据的3个核心需求:1、数据存储;2、数据写入;3、数据读取。
可以说,目前所有数据库、文件系统等等,都是为了以最佳性价比来满足数据的这三个核心需求。对时序数据而言,其三个核心需求特征十分明显:
数据写入
时间是一个主坐标轴,数据通常按照时间顺序抵达
大多数测量是在观察后的几秒或几分钟内写入的,抵达的数据几乎总是作为新条目被记录
95%到99%的操作是写入,有时更高
更新几乎没有
数据读取
随机位置的单个测量读取、删除操作几乎没有
读取和删除是批量的,从某时间点开始的一段时间内
时间段内读取的数据有可能非常巨大
数据存储
数据结构简单,价值随时间推移迅速降低
通过压缩、移动、删除等手段降低存储成本
而关系数据库主要应对的数据特点:
(1)数据写入:大多数操作都是DML操作,插入、更新、删除等;
(2)数据读取:读取逻辑一般都比较复杂;
(3)数据存储:很少压缩,一般也不设置数据生命周期管理。
因此,从数据本质的角度而言,时序数据库(不变性, 唯一性以及可排序性)和关系型数据库的服务需求完全不同。
再说说数据库。数据库系统的发展从20世纪60年代中期开始到现在,经历若干代演变,造就了C.W. Bachman(巴克曼)、E.F.Codd(考特)和J. Gray(格雷)三位图灵奖得主,发展了以数据科学、数据建模和数据库管理系统(DBMS)等为核心理论、技术和产品的一个巨大的软件产业(详见下图,资料来源:https://db-engines.com/en/ranking_categories)。
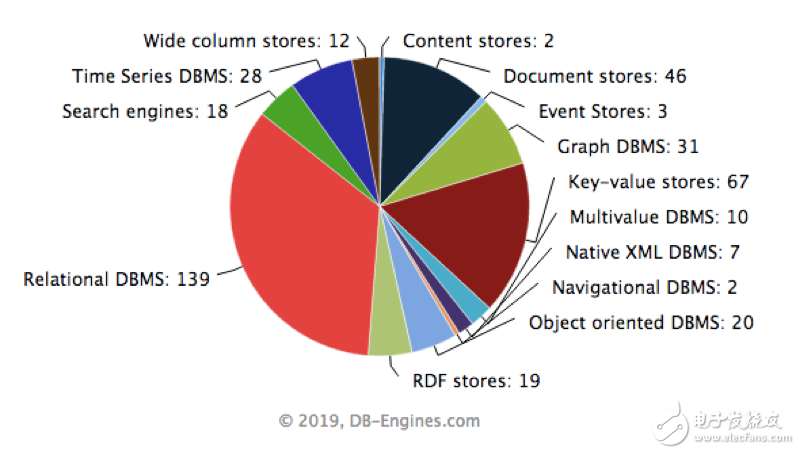
从上图可以得出一个结论,针对不同的数据需求,应该有不同的数据库系统应对之。否则,也没有必要出现这么多种的数据库系统了。
时间序列数据跟关系型数据库有太多不同,但是很多公司并不想放弃关系型数据库。于是就产生了一些特殊的用法,比如:用 MySQL 的 VividCortex, 用 Postgres 的 TimescaleDB;当然,还有人依赖K-V、NoSQL数据库或者列式数据库的,比如:OpenTSDB的HBase,而Druid则是一个不折不扣的列式存储系统;更多人觉得特殊的问题需要特殊的解决方法,于是很多时间序列数据库从头写起,不依赖任何现有的数据库, 比如: Graphite,InfluxDB。
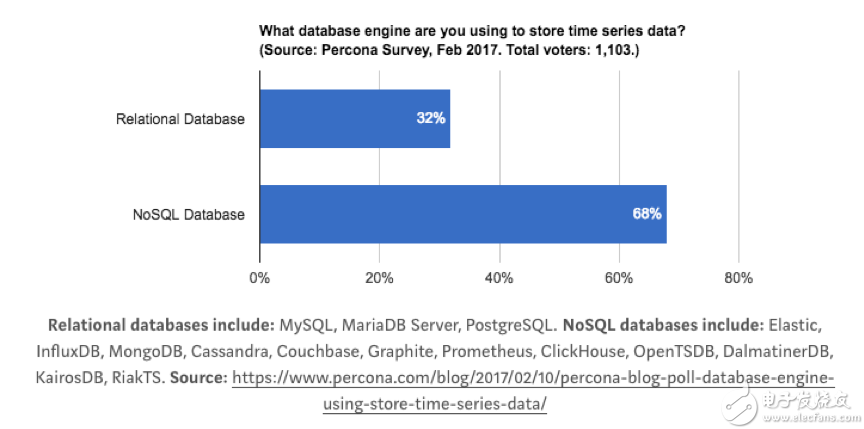
对选择数据库的开发者和使用者而言,针对时序数据库和关系型数据库之间选择,也主要考虑以下几个因素:
性能
研究过Oracle的存储结构和索引结构的都知道Oracle的ACID强一致性和B-Tree,保证强一致性导致数据持久化、可靠性、可用性实现的逻辑复杂,而加速数据访问,则需要Oracle 数据库使用 B-Tree 存储索引。
B-Tree 结构的有很多优势:在索引中从任何地方检索任何记录都大约花费相同的时间;B-Tree对大范围查询提供优秀的检索性能,包括精确匹配和访问查询;插入、更新和删除操作有效,维护键的顺序,以便快速检索;B-Tree性能对小表和大表都很好,不会随着表的增长而降低。从Tree这个名字就可以看出,这种B-Tree就是为了解决随机读写问题的。
而时序数据库,核心问题去解决批量读写,对于 95% 以上场景都是写入的时序数据库,B-Tree 很明显是不合适的,业界主流都是采用 LSM Tree(Log Structured Merge Tree)或者LSM的“升级版”TSM(Time Sort Merge Tree) 替换 B-Tree,比如 Hbase、Cassandra、InfluxDB等。LSM Tree 核心思想就是通过内存写和后续磁盘的顺序写入获得更高的写入性能,避免了随机写入。
LSM Tree 简单操作流程如下:
数据写入和更新时首先写入位于内存里的数据结构。同时,为了避免数据丢失也会先写到磁盘文件中。
内存里的数据结构会定时或者达到固定大小会刷到磁盘。
随着磁盘上积累的文件越来越多,会定时的进行合并操作,减少文件数量。
在内存or文件中,对数据进行压缩、去重等操作。
还有一个提升性能的关键点,即:分布式处理。这里以InfluxDB为例来说明。(顺便吐槽一下:InfluxDB单机版开源,集群版收费……,扔个鱼饵,“吃相”难看呀。)
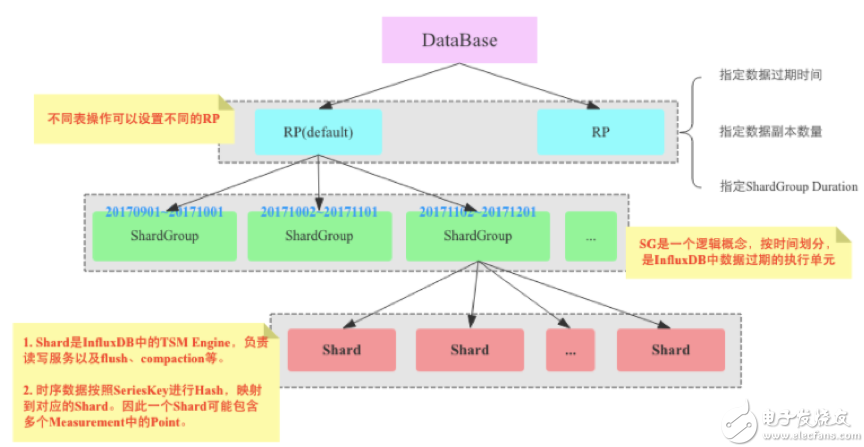
上图是InfluxDB的逻辑存储架构图,通过RP、ShardGroup、Shard的逐层分解,写入数据被尽可能的分布摊平。最后,每个Shard的TSM引擎负责对数据进行处理。Shard Group实现了数据分区,但是Shard才是InfluxDB中真正存储数据以及提供读写服务的服务。Shard是InfluxDB的TSM Engine,负责数据的编码存储、读写服务等。
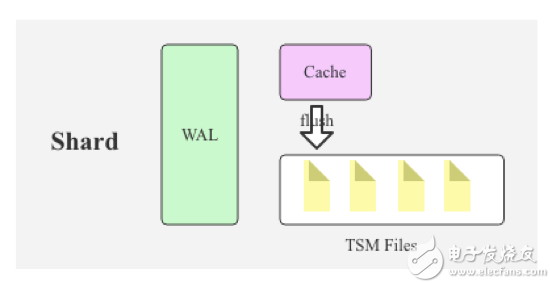
通常分布式数据库一般有两种Sharding策略:Range Sharding和Hash Sharding,前者对于基于主键的范围扫描比较高效;后者对于离散大规模写入以及随即读取相对比较友好。
InfluxDB的Sharding策略是典型的两层Sharding,上层使用Range Sharding,下层使用Hash Sharding。对于时序数据库来说,基于时间的Range Sharding是最合理的考虑,但如果仅仅使用Time Range Sharding,会存在一个很严重的问题,即写入会存在热点,基于TimeRange Sharding的时序数据库写入必然会落到最新的Shard上,其他老Shard不会接收写入请求。对写入性能要求很高的时序数据库来说,热点写入肯定不是最优的方案。解决这个问题最自然的思路就是再使用Hash进行一次分区,基于Key的Hash分区方案可以通过散列很好地解决热点写入的问题。
Shard分区好了,就可以采用分布式集群架构予以支撑,分摊压力,提高并行度。
成本和功能
很多时间序列数据都没有多大用处,特别是当系统长时间正常运行时,完整的历史数据意义并不大。而这些低价值数据,占据大量高价值存储空间,会让企业“抓狂”。因此,一些共通的对时间序列数据分析的功能和操作:数据压缩、数据保留策略、连续查询、灵活的时间聚合等,都是为了解决时序数据库的性价比问题的。同时,有些数据库比如 RDDTool 和 Graphite 会自动删除高精度的数据,只保留低精度的。而这些“功能”对关系型数据库而言,简直是不可想象的。
还有一些成本很多人会忘记考虑,比如:License,用需要License的关系型数据库来存储时序数据,成本根本没法承受。
至此,我们得出的结论就一个:选择到底用什么数据库来支持时序数据,还是需要对时序数据的需求进行透彻的分析,然后根据时序数据的特点,来选择适合的数据库。
启用名言作为本文结尾:适合的,就是最好的。
本文作者:格创东智首席架构师王锦博士。格创东智是由智能产品制造及互联网应用服务领军企业TCL孵化的创新型科技公司,致力于深度融合人工智能(AI)、大数据、云计算等前沿技术与制造行业经验,打造行业领先的“制造x”工业互联网平台,同时为各类制造业企业提供优质、安全、高效的管理IT服务,助力传统制造业智能化转型升级。(转载请注明作者及来源)
-
时序数据库是什么?时序数据库的特点2024-04-26 1745
-
涂鸦推出NekoDB时序数据库,助力全球客户实现低成本部署2023-07-24 2882
-
华为PB级时序数据库Gauss DB,助力海量数据处理2022-10-15 1933
-
华为时序数据库为智慧健康养老行业贡献应用之道2021-11-07 6771
-
深圳数研院:工业互联网来了,你可能更需要时序数据库2021-09-08 2533
-
关于时序数据库的内容2021-07-12 1523
-
工业互联网时代:我们为什么需要时序数据库之二2020-12-25 1423
-
时序数据库的前世今生2020-12-17 4547
-
时序数据库HiTSDB的深度解析!2019-07-22 1512
-
工业互联网时代,我们为什么需要一个时序数据库?2019-01-28 6952
-
互联网与工业物联网之间的区别与联系2017-06-14 5707
-
诚征自动化(硬件、嵌入式)、互联网、 数据库、数据安全技术合伙人2016-05-31 2739
-
工业互联网2016-01-25 3771
全部0条评论

快来发表一下你的评论吧 !
