

人类和机器识别事物的方式截然不同
电子说
描述
近期,加州大学洛杉矶分校的研究人员利用深度卷积网络(DCNN)在对象分类方面取得了较大的突破,但他们还发现,AI与人类识物的方式是完全不同的:人类更倾向于根据物体的全局信息进行分类,而机器却对物体的局部信息敏感。
识别,是人类智能的重要组成部分。如果机器能够比人类更快速的做到识别,其意义将是非常深远的。
然而,人类和机器识别事物的方式截然不同。
拿上图举例,对于图(a)来说,人类能够很快分辨出是一只熊,在速度和准确性方面都远超于机器;但是对于图(b),机器算法能够将其归类为熊,而人类可能看上半天都无法识别是什么。
虽然目前在通过机器算法识别事物方面已经有了一些突破性进展,但即便是最先进的算法、技术,也可能认错事物:例如将电视机中的静态画面或者抽象的图画,误认为是真实世界中的事物。
这些困难很大程度上是难以消除的,因为我们对这些神经网络如何“看”和“识别”事物没有很好的理解。
最近,加州大学洛杉矶分校的研究人员在PLOS computing Biology上发表了一篇文章,这项研究正在测试神经网络,以了解它们的视觉极限以及计算机视觉和人类视觉之间的差异。

论文地址:
https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1006613#sec001
他们提出了一种名为VGG-19的深度卷积神经网络。这是最先进的技术,在ImageNet大规模视觉识别挑战等标准化测试中已经超越了人类。
并且还发现:人类更倾向于根据物体的全局信息进行分类,而机器却对物体的局部信息敏感。
这一结果将有助于解释为什么神经网络在图像识别中会犯人类从未犯过的错误。
识别方式不同,使得AI擅于纹理识物,弱于轮廓
在第一个实验中,训练神经网络将图像整理分类,归入1000个不同的类别。
然后呈现出只有轮廓的图像:所有的局部信息都丢失了,只留下物体的轮廓。

如果你能选对其中一个,你就比最先进的图像识别软件强多了。
通常情况下,经过训练的神经网络能够识别这些对象,分类正确率达到90%以上。
而在研究轮廓的时候,这个数字降低到了10%。虽然人类观察者几乎总能产生正确的形状标签,但神经网络似乎对图像的整体形状几乎不敏感。
当研究人员试图让神经网络对他们已经识别出的玻璃雕像进行分类时,出现了一个特别有趣的例子:当我们很容易识别水獭或北极熊的玻璃模型时,神经网络将它们分别归类为“氧气面罩”和“开罐器”。
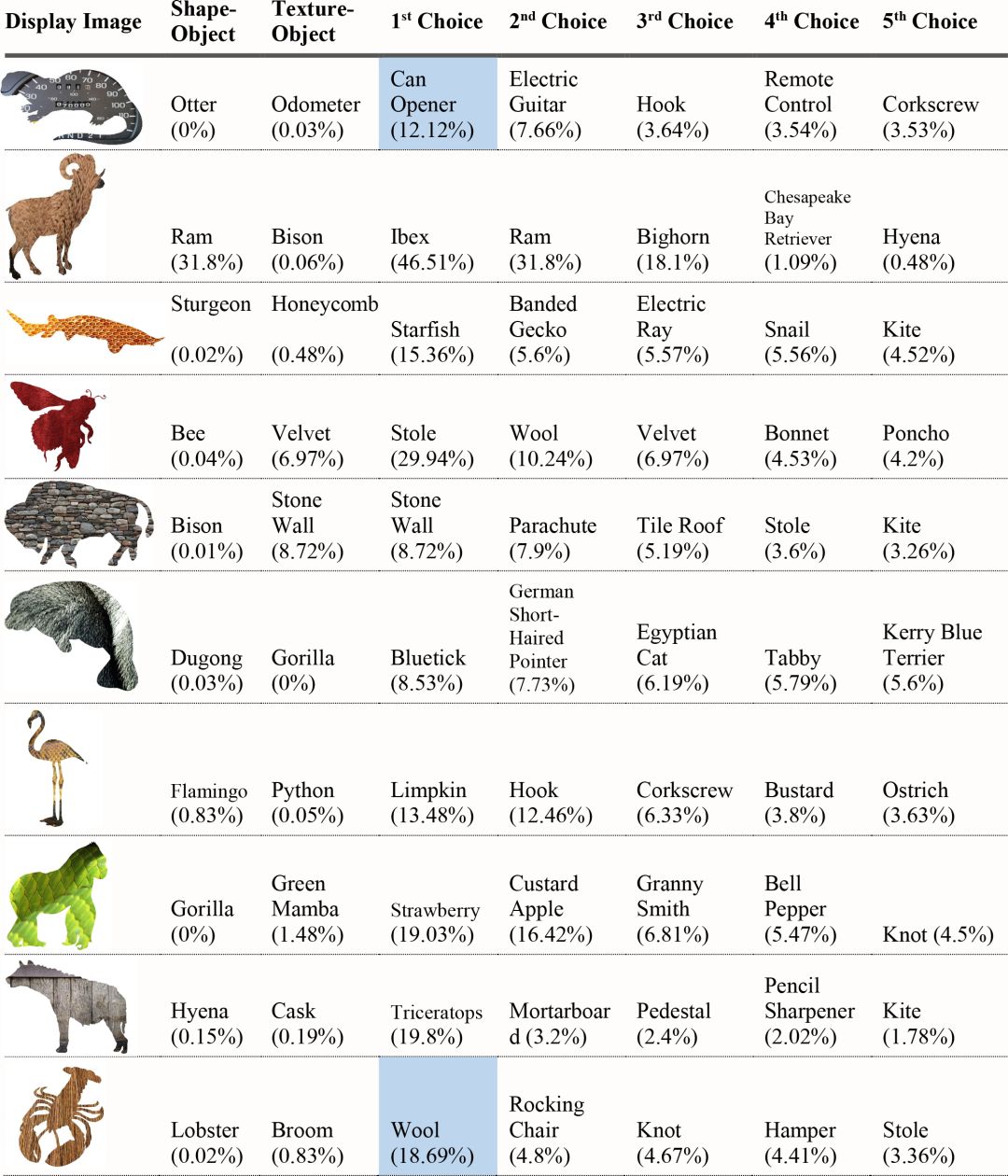
神经网络依赖于分类对象的纹理信息,而在这个例子中这些信息是丢失的,神经网络无法仅通过形状来识别对象。
研究人员发现,当神经网络明确地被训练用来识别物体轮廓的时候,图像轮廓的轻微扭曲就足以再次欺骗AI,而不会对人类的判定造成影响。
神经网络似乎对物体的整体形状不敏感,而是依赖于局部分布点之间的统计相似性,在此基础上便有了进一步的实验。
如果将图像打乱,使整体形状消失,但保留了局部特征,会有怎样的结果呢?
事实证明,神经网络在识别“乱序版本”物体方面要比只有轮廓的物体要好得多,也快得多,即使在人类“基本无法识别”的时候也是如此。学生们只能对37%的被打乱的物体进行分类,而神经网络成功的概率为83%。
更明智地使用神经网络,需先了解其运作方式
作者Kellman说:“这项研究表明,这些系统在不考虑形状的情况下,就能从训练过的图像中得到正确的答案。对人类来说,整体形状是物体识别的首要条件,而通过整体形状识别图像似乎根本不在这些深度学习系统考虑范畴当中。”
人们可能天真地认为,由于神经网络的许多层都是基于大脑神经元之间的连接建立的模型,而且与视觉皮层的结构非常相似,因此计算机视觉的运作方式必然与人类视觉相似。
但是这种研究表明,虽然基本架构可能类似于人类大脑,但由此产生的“思维”运作方式却截然不同。
研究人员目前可以渐渐地了解到神经网络中的“神经元”在受到刺激时是如何运作的,并将其与生物系统对相同刺激的反应进行比较。也许有一天,我们可以利用这些对比来了解神经网络是如何“思考”的,以及这些反应与人类的不同之处。
但是,到目前为止,还需要更多的实验心理学来探索神经网络和人工智能算法是如何感知世界的。
针对神经网络的测试更接近于科学家如何尝试理解动物的感官或幼儿发育中的大脑,而不仅仅是开发一款软件。通过将这种实验心理学与新的神经网络设计技术相结合,可能会使它们更加可靠。
然而,这项研究表明,对于我们正在创造和使用的算法,仍有很多不解之处:
它们是如何运作的;
它们是如何做出决策的;
它们与我们有何不同。
随着神经网络在社会、科技发展中扮演着越来越重要的角色,如果我们想要明智而有效地使用它们,深入理解神经网络将是至关重要的——而不是只见树木不见森林。
-
利用超快成像技术观测到两种截然不同的全息图案2025-02-07 533
-
opa695用示波器探头与sma转bnc线观察出现截然不同的结果,为什么?2024-08-26 720
-
WISDome武器识别系统圆顶开源2022-12-28 660
-
用Raspberry Pi的视觉识别事物2022-12-26 653
-
机器识别技术光学照明建模方法2022-11-21 1844
-
如何比较两种截然不同的编程语言的性能2021-09-02 2582
-
镜面媒体上的信息流动方式与当前的移动互联网传播截然不同2020-09-02 450
-
智能显示屏镜面媒体上的信息流动方式与互联网截然不同2020-08-19 403
-
为何对人脸识别技术态度截然不同2019-07-20 1740
-
韩国的两家公司对于投资动力电池截然不同的想法2019-05-31 3719
-
测试:人类看待事物会倾向于与AI机器达成一致2019-03-27 2000
-
人类与机器人有感情产生吗?2017-11-10 5018
-
看台积电、三星7纳米截然不同的观点2017-02-10 1242
-
扫描器识别二维码2016-02-23 3484
全部0条评论

快来发表一下你的评论吧 !
