

星际争霸2顶级人工智能AlphaStar带来哪些新思路?
电子说
描述
AlphaStar再次展现了DeepMind对研究方向的精准把控和卓越的工程实力。本文根据DeepMind博文及相关资料做了推演,试图在研究论文公布前复现AlphaStar的训练过程。沿用这套方法,你也创建自己的星际2训练环境!
自AlphaGo解决围棋问题之后,《星际争霸2》就成了DeepMind公司的新目标。在2018年6月,DeepMind发表了一篇论文,展示如何运用深度强化学习,解决诸如采矿最大化这样的小游戏。
没想到仅6个月后,他们的AI就已经可以和职业选手过招了。AlphaStar在Catalyst LE地图上打神族内战(PvP),以 5:0 战胜了职业选手TLO与MaNa,只是到了现场比赛时,被MaNa找到了一个无法应对棱镜骚扰的Bug致败。DeepMind公司那批机器学习天才们,研究方向掌握之精准,工程控制能力之强大,令人印象深刻。
这样的表演赛是DeepMind常见的预热,相信不久后它就会对Serra l 和Maru这样的顶级职业选手提出挑战。后者假如迎战,大概率菊花不保。
不过,与围棋不同的是,星际争霸这类即时战略游戏还有操作技能这一环。AlphaStar有不切屏看大地图的功能,以及偶尔爆出超越人类极限的有效手速(eAPM),都被指责为不够公平。相信DeepMind在正式邀战时会解决这些问题。
很多人最关心的一个问题是,AlphaStar究竟是如何训练出来的呢?我们尝试在正式论文尚未放出之前,通过DeepMind的博客文章作一些分析解读。
玩星际争霸的AI面对的问题
星际争霸2是一个困难的即时战略游戏。玩家必须实时地在成百上千个可行的操作中作出决断。
与人类相仿,AI的控制流同样由一轮轮操作组成。在每一轮中,AI先获取当前游戏状态,据此衡量并选择一次操作,然后提交给星际争霸2环境。
AI经由Blizzard和DeepMind联合创建的PySC2接口,与星际争霸2的游戏核心进行交互。每一步中,AI能够获取的游戏信息是一个矩形网格,网格的每个位置代表地图上的一个位置。每个位置上都有若干数值,代表此地的有效信息。
另一种理解方式是,游戏信息被组织成若干个网格,每份网格代表某一项特定信息(见上图右侧)。比如说“fog-of-war”网格代表是否存在战争迷雾;“height-map”网格代表地形高度;“unit-type”网格代表建筑或者作战单位。详细说明可参考报告论文[1]的第3.2节。
在操作方面,AI定义了300多个“宏操作”,在每一轮中,AI从这个集合内选取某个宏操作执行。宏操作由一系列基本操作组成。例如,“把当前选中的单位移到A处”,可以分成三步:1) 决定移动,2) 决定是否把操作排队,3) 点击某个地图位置。而上述操作又可以进一步分解为“按m键;松开m键;决定是否按shift键;地图A处按下鼠标左键;松开鼠标左键”。
不同粒度的操作分解,会将问题焦点分配到不同抽象层面。如果操作种类特别基本,到了按键盘鼠标的程度,单个操作的意义就非常小,探索有意义的策略就很难。反之,如果宏操作非常复杂,虽然意义显著,但每一步的选择空间又变得过于宽广,选中合适的策略也很难。PySC2取了一个平衡点,每个宏操作的意义,与人类逻辑层面上感知的操作接近,比如上面移动单位的例子,它就给了一个专门的操作。
AI一旦从决策空间选定了宏操作之后,就会生成一条 (a0, a1, a2, a3, a4, ...) 形式的指令,其中“a0”指定了300多个基本操作之一,而“a1, a2…”是操作参数,比如给需要移动单位指定目的地。直观图示如下:

为什么都说星际争霸2问题难?
因为需要探索的空间太大。
根据DeepMind的报告,考虑操作和参数的各种组合,在典型对战环境中,决策空间的大小约有10^26 (简短的介绍可参见报告论文[1]第3.3节)。如果把星际争霸想像成一盘棋局,那么
棋局的状态就是战场的全部信息,但由于战争迷雾的存在,星际2中一位弈者相当于遮挡住部分棋盘来对局;
每一步可以落子的位置对应于此步可以进行的操作,其可能性的数量级大致相当于一大瓶可乐里水分子的数量。
注意以上讨论的仅仅是AI决定单步操作时需要面对的挑战,在对战中每一步对应一个的时间节点,如果按照职业玩家的操作频率来计算,每分钟需要行棋数百步,每步都在前一步的基础上以乘数拓展一个状态空间!
学习一步的操作固然困难,但尚可算入当前最成熟的统计学习方法——监督学习——可实际解决的问题的范畴。即给机器提供大量可观测的输入,即学习样本,并提供期望产生的输出。AI从这些配对样本中,学到输入与输出的变量应该怎样对应。
监督学习方便简单,而且从工程实现的意义来说,其实是我们唯一可以成熟使用的范式。但实际应用到学习对战这种任务上立即就会呈现出局限性 。
我们想象一个最简单例子,监督学习范式可以方便地运用到单个人脸识别,单个数字识别,单个物体识别这样的任务中。但如果不是“单个”数字识别,而是识别“一串”手写数字,那么我们应当如何构建监督学习呢?
1) 可观测的输入:整个图像;期望产生的输出:类似于“02971736”这样的数字串。
假设输出的数字有个固定的长度上限,比如5位数字。那么对一副图像就可能有高达10^5种可能的输出。想训练好一个“5位数字串”识别器,就需要对每一种可能的字串,提供与其对应的图像例子,比如10000张不同的“01234”图像。那么,对所有的类别,“34567”,“34555”,“23588”…都提供10,000张用于训练的例子,其耗费将不可忍受。而每种类别10,000个例子的数量还是十分保守的估计,在典型的数字图像数据集,比如MNIST中,每个单个数字“0”,“1”,……的例子就有此数。
2) 可观测的输入:矩形图像块;期望产生的输出:“0”,……,“9”这类单个数字
在这种情况下,我们只需要针对10个数字作训练,例子数量呈指数级缩减。但它并不能直接解决“从图像中识别数字串”这个问题,因为还需面对“发现原始输入图像的哪些区域包含有意义的数字并截取”的难题。我们要仔细制定规则来确认哪些区域包含数字及其顺序,这是OCR任务中常用的方法,但恰如批评所言,这属于“人工+智能”。
3) 可观测的输入:整个图像,一个初始的矩形区域;期望产生的输出:矩形区域中的图像内容“0……9”,矩形区域在图像上的下一步移动,是否终止检测。
这就开始脱离监督学习的范式了。系统并非一次性的完成对输入的分析,产生输出,而是试图做一个决策流,每个步骤都要根据一个本步观测(输入)得到一个相应的决策(输出)。而一个步骤的决策又会影响下一个步骤的观测。如下图所示:
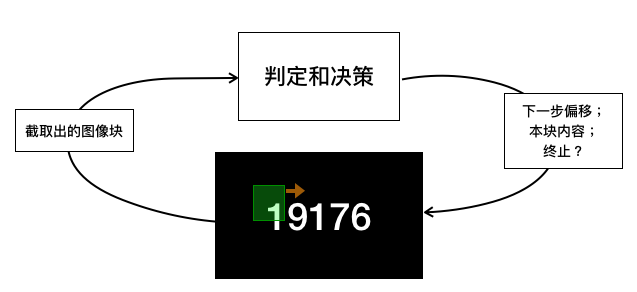
它更加符合人类智能解决实际问题的方式,而游戏环境则是这类方案天然的试炼场。这也是通过人工智能程序玩游戏,在近年来获得如此关注的原因之一。事实上:
把上面流程中的“数字串原始图像”换成“星际争霸2游戏环境”,
把判定和决策的输出结果换成上面讨论过的单步宏操作,
把“截取出的图像块”换成上面讨论过的AI的对游戏的观测,
我们就基本定义好了“玩星际争霸的AI”所面对的问题。

AlphaStar面对的就是这样一个问题,我们从它的博客文章[2]提到的若干技术要素出发,对其训练方法进行解说与猜测。它使用的这套技术分为如下三个大类:
宏观训练策略
单个智能体强化学习策略
智能体的构造和训练的具体实现
拆解:AlphaStar的训练策略
1. 宏观的群体学习策略
简略地讲,AlphaStar 的总体训练过程,是一组多回合的“AI联赛”。在介绍联赛规则之前,我们先讲为什么要训练一群,而不是一个AI,来挑战星际争霸2。首先,星际争霸2本质上是一个对抗性游戏,玩家追求胜利需要考虑对手的活动,并无全局意义上的最优策略。其次,相比于围棋,星际争霸2对战场状态只能作不完全观测,且其状态空间更加庞大,导致一系列AI会各有偏好并相互克制。
对于一个的AI算法来说,强化学习任务中的诸要素,自然地分作两类:受控变量和外界环境。在学习的每个时间点,AI选择好的动作和观测结果,是两边交换信息的载体。
算法设计者须将外界环境视为黑箱,不能或不会在学习过程中加以控制。比如设计一个 AI 来挑战 Atari 主机中的某个游戏,算法设计者只能启动强化学习 AI 后从旁观察。对于星际争霸这类对战式的任务,被AI视为“外界环境”的元素,除游戏程序之外,对手一方同样满足:
不在AI的控制范围
对“本” AI 的行动作出反馈
影响游戏状态,从而影响“本” AI 在下一个时间节点取得的观测结果
因此解决方案中需要考虑对手,为此构建的学习环境中也需要包含一个对手。
AlphaStar从一个单一的“种子选手”启动联赛,每一轮挑选有潜力的互相挑战,对优胜AI略微变通后令其加入扩大联赛队伍。一轮接一轮地将联赛开展下去。启动的种子AI来自基础的监督学习:从Blizzard战网下载人类玩家对战数据,训练深度神经网络学习每局对战每个时刻的(游戏状态,玩家操作)的对应关系。(更详细的,我们猜测应该是若干步的游戏状态序列和操作流之间的对应关系)
获得启动种子后的联赛式训练见下图(取自Deepmind blog)
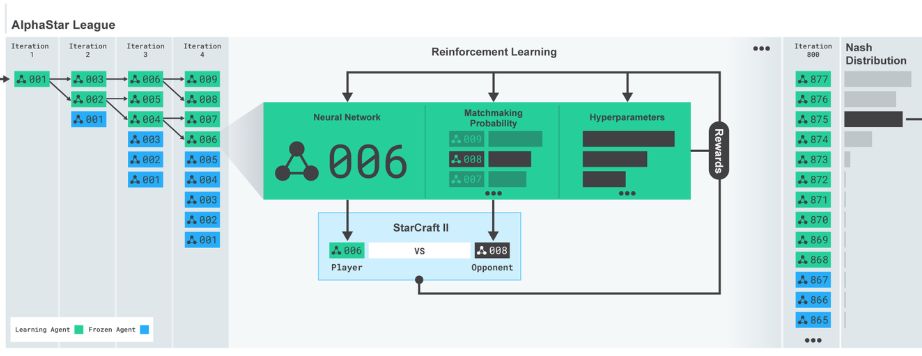
博客中详细介绍的是第四轮训练Network-006的过程。首先我们注意到这个训练过程能够进行就有两个前提条件:i) 本轮的Network-006是前一轮Network-004的两个变异后裔之一。ii)Network-006被选中参加本轮联赛的比赛,以绿色表示,而每一轮当中不参加比赛的AI选手以蓝色表示。无论是否参加比赛,一轮当中所有的AI选手都会被原封不动地拷贝到下一轮。
之后,Network-006本场比赛的对手选定为Network-008,设定好学习参数,就可以进行强化学习训练了。注意Network-008在这次训练中充当“陪练”的角色,其本身的网络参数不会获得调整。Network-006将Network-008当作靶子来训练,会习得专门对付008的方案。至于008的出场是根据“Matchmaking Probability”算法抽取的,大约是在随机分布的基础上,让高等级选手出场的机会略多,具体计算方式必须等论文出来才能确定。
“星际争霸AI大联盟”始终保留其历史上的所有会员,每个AI都有出场机会。这样可以避免学习终局的那些高等级AI,只会针对其它高等级AI,反而不懂如何应对菜鸟的事件。训练的时候还会给一些比较弱的人工指导,比如“初期鼓励出狂战士”等。这类指导策略也是随机选取的,为的是进一步提升下一轮联盟中AI选手的多样性。
从他们博文看来,联赛举行了800轮之多。最后一轮过后,“星际争霸AI大联盟”中存在高达877个训练过的AI神经网络。在测试阶段出战者的选择方式,则是从这些AI选手中以Nash Distribution采样。
2. 单个 AI 的训练
下面我们分析特定轮比赛中AI个体的学习问题。这是一个强化学习任务。
在“强化学习”中,AI 自行尝试输出不同的决策,训练者反馈给 AI 激励和新的数据。这些配对数据用于后期的“监督学习”,从机器在探索中得到的数据对,来学习环境输入与操作输出这两大要素之间的联系,在星际争霸2单个AI训练中,我们将这两个层面称作“强化学习探索”和“构建 AI 模型本体来学习样本数据中的关联”。
从“种子”选手开始,每个 AI 模型就继承了以前的模型从它们对战经验数据中学习到的决策策略。而首个种子选手继承的是人类选手的经验。一旦启动学习,AI 就立即面临强化学习领域经典的“守成探索不能得兼”(exploitation-vs-exploration)的问题。
根据 Deepmind 的介绍,AlphaStar 强化学习的骨干算法选用了“实干家-批评家”方法(Actor-Critic,AC)。为了加速训练以及取得稳定和可靠的效果,AlphaStar 使用了大规模并行的 AC 实现,另外结合了若干节约和利用有效经验的技巧来对付星际争霸2任务中学习远期回报的挑战。
AlphaStar 具体使用的 AC 算法是2018 年 DeepMind提出的 IMPALA 算法[5]。其设计目的是解决高度并行的大规模学习问题。运行星际争霸2这样的大型游戏环境,令 AI 与之互动产生数据,是一个昂贵的计算任务。由于在 AC 算法框架下对模型参数的求导是一个伴随剧烈波动的随机性操作,用这种方法估计出来的导数来优化策略模型,只能让策略大致上变得越来越好。这个所谓“大致”的靠谱程度,就取决于我们能不能把导数的“剧烈波动”处理得不是那么剧烈。
一个自然的想法是:把策略多跑几遍,导数多求几次,求平均值。并行 AC 学习算法[6]就是对上述思路的直接实现—— 由于在 AC 架构中实际产生数据,探索环境的乃是“实干家”。我们在分配计算资源时偏向它,多雇佣实干家(多分配一些相应的策略执行进程),同时生成多条执行轨迹,并通过一个中心学习者从这些多线历史中估算策略参数的导数,结果会更准确,这些实干家相当于中心学习者的分身。IMPALA 框架则更进一步,所有分身实干家都只是“傀儡执行者”,既不需要优化策略参数,也不需要计算导数,只是负责执行生来所继承的策略,把经验数据忠实地记载下来,传回中心学习算法。

即便不考虑对稳定导数计算的作用,这种做法也极大缓解了高并行复杂模型学习中的节点通讯问题。“傀儡执行者”和学习核心的关系,见上图,它们之间的通信频率比起频繁传递网络参数要少得多(可以完成一个 episode 才更新一次策略参数)。而执行策略的历史数据往往比大型网络的导数(大小约为整个网络参数集)来得经济很多。
AlphaStar 还采用了几项对 AC算法的补充措施。其中重要的一项是,每个 AI 选手在训练期间,都会把自己的对战历史保存下来,供 AC 算法在估计参数导数时使用,即模仿自己的优秀历史。这种在学习者“脑海”里面重放历史经验(Experience Replay)的做法,之前在估值方法与深度神经网络结合的工作中采用过(Deep Q-Learning,DQN),并首次实现了AI在视频游戏上的突破。在直接学习策略参数的方案中,一般来说,这样做会导致估计偏差——因为 AC 算法“期望”它见到的数据是执行“本”策略得来。单采用参考历史数据的方案算出的模型改进方向,其出发点就有一点过时了。但由于从少量样本估计的模型参数的导数往往会有巨大波动。为更稳定地标定正确的学习方向,可以牺牲终点的最优特性。
还有一个措施,是把学习过的 AI 的策略精髓抽取出来,转移到正在学习的 AI 模型中(Policy Distillation)[7]。这个方法可以使用更紧凑的模型(参数小一个数量级)来逼近更大更复杂的模型的表现;可以合并多个策略来形成一个比其中每个个体都更可靠的策略——注意由于优秀策略的分布不是连续的,这不是一个简单平均的问题。比如考虑超级玛丽兄弟:策略A是跳起来踩扁蘑菇,策略B是发射火球然后直接前进,如何在A和B之间折衷相当困难;还可以在策略学习这个层面形成迭代:每一轮的学习都把上一轮学习到策略的精髓转移出来,在此基础上开始。由于Deepmind语焉不详,目前还不清楚这个方法是如何用于AlphaStar训练上的。
3. 神经网络模型和训练
强化学习AI算法。最终落实到具体的调整策略/模型的单个学习步骤上,也就是训练迭代的最内层循环中,还是要回归到监督学习范式,变成“针对这样的输入,鼓励(惩罚)模型产生如此的输出”的优化操作。在传统强化学习研究历史上,建立策略或者估值是理论重点。系统的状态往往被少数几个变量完美的描述,比如一个牛顿力学系统中各个刚体的位置和速度。但是在任何稍微复杂一点的问题中,数据表示问题仍然是一个挑战:即使强化学习算法非常有效,AI也必须知道当前观察到的状态与之前经历过的状态之间的联系。星际争霸游戏这类问题,其观测是十分复杂的对象(序列),于是我们也就要面对统计学习中的典型问题:通过分析数据,建立(输入,输出)之间的联系。
目前大家的共识是,这个问题的核心是把输入的数据转换成一种有效的表示,这个“有效”是从期望产生的输出结果的角度来评判的。具体一点说,如果我们的训练数据中有两个样本(输入A,输出A)和(输入B,输出B),后来又观测到了(输入C)。一个好的输入数据的表达应当能帮助我们估计想要的“输出C”。比如我们做完“输入A->表达A”,“输入B->表达B”和“输入C->表达C”,然后比一比相似度(表达C,表达A)和(表达C,表达B),然后从A和B当中挑选更相似的那个,用它的输出来预估C的输出。如果这种估计方式真的能得到对于C来说合适的输出,我们说这个表达方式对于这个数据分析任务来说是好的。如果能完美的完成这个相似度辨别的任务,那么很多问题就可以简化成“查询一下现在遇到的状况跟训练时碰到的哪个情况类似,照当初的经验办理”。从另一方面说,如果能将每一个原始数据样本变换到一个多维向量,这些向量之间可以用简单的做差算距离来衡量相似度,那么这个变换也算解决了衡量数据样本之间的相似度的问题。这个任务有个术语叫做“数据表示”。
注意从上面的讨论我们可以看出,没有绝对“好”的数据表示,我们根据对某个特定的任务是否有效来衡量一种表示方法的好坏。数据表达的质量可不仅仅取决于输入数据的形式,而是跟整个数据分析的任务密切相关。比方说输入的对象是自然人,人当然是个十分复杂的对象,如果要量化描述之,那么对于“预估此人能否成为优秀的篮球队员”这个任务,“身高、摸高、100米跑时间”这些量化的指标就比较合理;而对于“预估此人会不会去观看某部电影”的任务,“票价与此人月收入的对比、前一年上映的每部电影此人是否观看过……”这些量化指标就显得合适。
深度学习的兴起的最大功臣是在随这类模型而得到的有效数据表示:从输入到输出之间架构好深度神经网络之后,我们就自然而然地把输入数据的转换,预测输出的数据模型,模型产生的输出与真实样例之间的对比,这三者统一到了同一个训练过程中。神经网络的结构也就同时规定了“怎样整理转换输入数据”和“怎样用整理过的输入数据预测所需的输出”这两个在数据分析中的关键步骤。
•序列转换模型
根据Deepmind的说法,AlphaStar 采用了基于注意力机制的序列转换的表示模型。这种数据表达方法的起源是在自然语言处理领域,我们能够想象,这种方法擅长于表示成序列出现的数据样本。具体地说,transformer模型来自于自然语言处理中的翻译任务,把一句话——即一串单词和标点(语言的基本单位,tokens)——转换成另一种语言的基本单位。Deepmind同样没有详述这个模型在 AlphaStar 中的具体使用方法。不过据上文提到的使用人类对战数据预训练作为“种子AI”的做法来看,有可能预训练的任务被制定成了学习从输入“游戏状态序列”到输出“操作指令序列”之间的联系。
•策略模型
基于注意力机制的序列转换目前已经发展成为一个大的模型家族(刚刚在自然语言处理领域大放异彩的BERT也是其中一员),Deepmind 提到 AlphaStar 的输出策略的计算模型是一种产生“指针”来“引用”自己的输入序列从而构建输出序列的自回归(auto-regression)模型。
•基于多智能体的批评家
AlphaStar 的强化学习核心是“实干家-批评者”(AC)算法族。其具体的选择是引入一种更加适应多个AI共同学习,但每个AI的观测受限的学习环境的估值方法。其基本原理是采用“要不然”式估值(原名为Counterfactual Multiagent,直译为“反事实多智能体”),批评家在评判AI之前做的一项决策的价值时,使用“要是当时不这么做”的话平均下来会有若干回报,那么当初这么做的优势(劣势)也就相应得出。
以上大致是我们从目前已有的知识所能推测的AlphaStar的详细训练方案。在Deepmind正式论文发表之后,补足其中少量细节,我们就可以沿用这套方法,创建自己的星际争霸2训练环境。
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5641
-
人工智能芯片是人工智能发展的2021-07-27 6413
-
【书籍评测活动NO.16】 通用人工智能:初心与未来2023-06-21 10746
-
看后有点感动 让人惊艳!4K版《星际争霸》配置要求公布:亲民2017-07-03 954
-
AlphaStar横空出世 星际争霸2人类1:10输给AI2019-01-25 3717
-
一天等于两百年?人工智能在星际争霸2上向人类发出挑战2019-07-29 1187
-
为什么DeepMind的科学家们对星际争霸如此痴迷2019-01-29 4465
-
DeepMind在伦敦向世界展示了他们的最新成果——星际争霸2人工智能AlphaStar2019-01-30 6022
-
企业怎样利用人工智能术取得跨越式发展?人工智能领域还有哪些创业机会2019-03-18 3052
-
人工智能告诉我们未来需要更深入地探索人类创造力的本质2019-03-31 1050
-
扫脸支付已经成为现实 人工智能离我们越来越近2019-06-27 1517
-
深度强化学习最有可能实现通用人工智能 但还需依托脑科学的发展2019-12-04 1729
-
如何理解人工智能核心及应用2020-08-22 2425
-
一项新的研究发现,人类不可能控制超级人工智能2021-01-28 2323
全部0条评论

快来发表一下你的评论吧 !
